Recognition: unknown
ESCAPE: Episodic Spatial Memory and Adaptive Execution Policy for Long-Horizon Mobile Manipulation
Pith reviewed 2026-05-10 13:04 UTC · model grok-4.3
The pith
ESCAPE couples a persistent 3D spatial memory with an adaptive navigation-manipulation policy to reach 65 percent success on long-horizon household tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
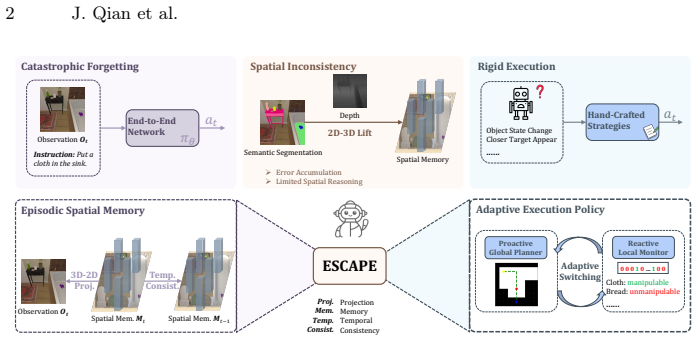
ESCAPE operates through a tightly coupled perception-grounding-execution workflow in which a Spatio-Temporal Fusion Mapping module autoregressively constructs a depth-free persistent 3D spatial memory, a Memory-Driven Target Grounding module produces interaction masks from that memory, and an Adaptive Execution Policy dynamically interleaves proactive global navigation with reactive local manipulation, yielding state-of-the-art success rates of 65.09 percent and 60.79 percent on the ALFRED test-seen and test-unseen splits with step-by-step instructions.
What carries the argument
The Spatio-Temporal Fusion Mapping module, which autoregressively assembles a depth-free persistent 3D spatial memory to support accurate target grounding across long horizons.
If this is right
- Reduces redundant exploration and raises path-length-weighted success metrics.
- Preserves performance when detailed step-by-step instructions are withheld.
- Generalizes more reliably to unseen indoor layouts through consistent memory.
- Tightens the loop among perception, grounding, and execution for fewer failures.
Where Pith is reading between the lines
- The memory construction may prove useful on physical robots where depth sensors are unavailable or noisy.
- Explicit spatial memory could become a practical route to scaling tasks well beyond the length of current benchmarks.
- The adaptive policy suggests a template for other embodied systems that must interleave locomotion and interaction.
Load-bearing premise
The fusion mapping can maintain spatial consistency and avoid cumulative drift from visual inputs alone over extended sequences of movement and manipulation.
What would settle it
A trial in which the agent must return to an earlier location after dozens of intervening steps and the success rate collapses because the stored 3D map no longer aligns with current observations.
Figures






read the original abstract
Coordinating navigation and manipulation with robust performance is essential for embodied AI in complex indoor environments. However, as tasks extend over long horizons, existing methods often struggle due to catastrophic forgetting, spatial inconsistency, and rigid execution. To address these issues, we propose ESCAPE (Episodic Spatial Memory Coupled with an Adaptive Policy for Execution), operating through a tightly coupled perception-grounding-execution workflow. For robust perception, ESCAPE features a Spatio-Temporal Fusion Mapping module to autoregressively construct a depth-free, persistent 3D spatial memory, alongside a Memory-Driven Target Grounding module for precise interaction mask generation. To achieve flexible action, our Adaptive Execution Policy dynamically orchestrates proactive global navigation and reactive local manipulation to seize opportunistic targets. ESCAPE achieves state-of-the-art performance on the ALFRED benchmark, reaching 65.09% and 60.79% success rates in test seen and unseen environments with step-by-step instructions. By reducing redundant exploration, our ESCAPE attains substantial improvements in path-length-weighted metrics and maintains robust performance (61.24% / 56.04%) even without detailed guidance for long-horizon tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ESCAPE, a tightly coupled perception-grounding-execution framework for long-horizon mobile manipulation. It introduces a Spatio-Temporal Fusion Mapping module that autoregressively builds a depth-free persistent 3D spatial memory, a Memory-Driven Target Grounding module for generating interaction masks, and an Adaptive Execution Policy that dynamically switches between proactive global navigation and reactive local manipulation. On the ALFRED benchmark with step-by-step instructions, the method reports state-of-the-art success rates of 65.09% (test seen) and 60.79% (test unseen), plus gains in path-length-weighted metrics and robustness (61.24%/56.04%) even without detailed guidance.
Significance. If the empirical claims hold under rigorous verification, the work would be significant for embodied AI, offering a practical approach to mitigating catastrophic forgetting and spatial inconsistency in extended indoor tasks while improving efficiency through opportunistic target seizing. The depth-free memory construction, if reliable, could reduce sensor requirements in real-world deployments.
major comments (2)
- [Abstract] Abstract: The headline SOTA success rates (65.09% seen / 60.79% unseen) and path-length improvements are stated without any description of the baselines, ablation studies, error bars, statistical tests, or train/test splits used. This absence directly undermines verification of the central performance claims and the attribution of gains to the proposed modules.
- [Method] Spatio-Temporal Fusion Mapping module (method description): The claim that this module constructs a reliable, drift-free, depth-free persistent 3D memory supporting precise target grounding over long horizons is load-bearing for the reported results, yet the manuscript provides no quantitative fidelity metrics (e.g., 3D reconstruction error vs. ground-truth depth, grounding mask IoU decay as a function of episode length, or pose drift accumulation in unseen cluttered scenes). Without such evidence or an ablation isolating the fusion module, the performance attribution cannot be assessed.
minor comments (2)
- [Abstract] Abstract: The phrase 'substantial improvements in path-length-weighted metrics' is used without naming the exact metric or reporting the numerical deltas.
- [Abstract] The abstract mentions 'even without detailed guidance' but does not clarify whether this refers to a specific ablation condition or a variant of the ALFRED task.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will incorporate to strengthen the presentation of our results and the supporting evidence for the proposed modules.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline SOTA success rates (65.09% seen / 60.79% unseen) and path-length improvements are stated without any description of the baselines, ablation studies, error bars, statistical tests, or train/test splits used. This absence directly undermines verification of the central performance claims and the attribution of gains to the proposed modules.
Authors: We agree that the abstract, being a concise summary, does not explicitly detail the experimental context. The full manuscript reports comparisons against multiple state-of-the-art baselines on the ALFRED benchmark using the standard train/validation/test-seen/test-unseen splits, with ablation studies in Section 4 and results presented as means with standard deviations across runs. Formal statistical significance tests were not conducted. To improve immediate verifiability, we will revise the abstract to briefly note the primary baselines and direct readers to the experiments section for ablations, error bars, and split details. revision: yes
-
Referee: [Method] Spatio-Temporal Fusion Mapping module (method description): The claim that this module constructs a reliable, drift-free, depth-free persistent 3D memory supporting precise target grounding over long horizons is load-bearing for the reported results, yet the manuscript provides no quantitative fidelity metrics (e.g., 3D reconstruction error vs. ground-truth depth, grounding mask IoU decay as a function of episode length, or pose drift accumulation in unseen cluttered scenes). Without such evidence or an ablation isolating the fusion module, the performance attribution cannot be assessed.
Authors: The Spatio-Temporal Fusion Mapping module's role is validated through ablations that remove or alter its fusion components, resulting in measurable drops in long-horizon success and increased forgetting, as shown in the experiments. Because the module is explicitly depth-free and relies on RGB-based spatio-temporal fusion, direct 3D reconstruction error versus ground-truth depth is not applicable. We will add quantitative plots of grounding mask IoU as a function of episode length and analysis of pose drift accumulation in the revised manuscript, along with additional qualitative memory visualizations. The existing ablations already isolate the fusion module's contribution, which we will highlight more explicitly. revision: partial
Circularity Check
No significant circularity; empirical results on external benchmark
full rationale
The paper presents a modular architecture (Spatio-Temporal Fusion Mapping, Memory-Driven Target Grounding, Adaptive Execution Policy) whose efficacy is demonstrated solely through empirical success rates on the external ALFRED benchmark (65.09%/60.79% seen/unseen). No equations, fitted parameters, or derivation steps are shown that reduce by construction to their own inputs. Central claims are benchmark numbers, not quantities forced by self-definition or self-citation chains. The method is self-contained against the independent ALFRED evaluation protocol.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Batra, D., Gokaslan, A., Kembhavi, A., Maksymets, O., Mottaghi, R., Savva, M., Toshev, A., Wijmans, E.: Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171 (2020)
-
[2]
In: Conference on Robot Learning
Blukis, V., Paxton, C., Fox, D., Garg, A., Artzi, Y.: A persistent spatial semantic representation for high-level natural language instruction execution. In: Conference on Robot Learning. pp. 706–717. PMLR (2022)
2022
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2022)
work page internal anchor Pith review arXiv 2022
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Can, Y.B., Liniger, A., Paudel, D.P., Van Gool, L.: Structured bird’s-eye-view traf- fic scene understanding from onboard images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15661–15670 (2021)
2021
-
[5]
A Survey on 3D Gaussian Splatting
Chen, G., Wang, W.: A survey on 3d gaussian splatting. arXiv preprint arXiv:2401.03890 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents.arXiv preprint arXiv:2501.11858, 2025
Cheng, Z., Tu, Y., Li, R., Dai, S., Hu, J., Hu, S., Li, J., Shi, Y., Yu, T., Chen, W., et al.: Embodiedeval: Evaluate multimodal llms as embodied agents. arXiv preprint arXiv:2501.11858 (2025)
-
[7]
The International Journal of Robotics Research44(10-11), 1684–1704 (2025)
Chi,C.,Xu,Z.,Feng,S.,Cousineau,E.,Du,Y.,Burchfiel,B.,Tedrake,R.,Song,S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research44(10-11), 1684–1704 (2025)
2025
-
[8]
Ehsani, K., Gupta, T., Hendrix, R., Salvador, J., Weihs, L., Zeng, K.H., Singh, K.P., Kim, Y., Han, W., Herrasti, A., et al.: Spoc: Imitating shortest paths in sim- ulationenableseffectivenavigationandmanipulationintherealworld.In:Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16238–16250 (2024)
2024
-
[9]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[10]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Huang, J., Huang, G., Zhu, Z., Ye, Y., Du, D.: Bevdet: High-performance multi- camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790 (2021)
work page internal anchor Pith review arXiv 2021
-
[11]
arXiv preprint arXiv:2211.03267 (2022)
Inoue, Y., Ohashi, H.: Prompter: Utilizing large language model prompting for a data efficient embodied instruction following. arXiv preprint arXiv:2211.03267 (2022)
-
[12]
In: RSS 2024 Workshop: Data Generation for Robotics (2024)
Jaafar, A., Raman, S.S., Wei, Y., Juliani, S.E., Wernerfelt, A., Idrees, I., Liu, J.X., Tellex, S.: LaNMP: A multifaceted mobile manipulation benchmark for robots. In: RSS 2024 Workshop: Data Generation for Robotics (2024)
2024
-
[13]
ACM Transactions on Graphics42(4) (July 2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023)
2023
-
[14]
In: Embodied AI Workshop CVPR
Kim, B., Bhambri, S., Singh, K.P., Mottaghi, R., Choi, J.: Agent with the big picture: Perceiving surroundings for interactive instruction following. In: Embodied AI Workshop CVPR. vol. 2, p. 12 (2021)
2021
-
[15]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Kim, B., Kim, J., Kim, Y., Min, C., Choi, J.: Context-aware planning and environment-aware memory for instruction following embodied agents. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10936–10946 (2023) 16 J. Qian et al
2023
-
[16]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review arXiv 2024
-
[17]
AI2-THOR: An Interactive 3D Environment for Visual AI
Kolve, E., Mottaghi, R., Han, W., VanderBilt, E., Weihs, L., Herrasti, A., Deitke, M.,Ehsani,K.,Gordon,D.,Zhu,Y.,etal.:Ai2-thor:Aninteractive3denvironment for visual ai. arXiv preprint arXiv:1712.05474 (2017)
work page internal anchor Pith review arXiv 2017
-
[18]
The International journal of robotics research37(4-5), 421–436 (2018)
Levine, S., Pastor, P., Krizhevsky, A., Ibarz, J., Quillen, D.: Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. The International journal of robotics research37(4-5), 421–436 (2018)
2018
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(3), 2020–2036 (2024)
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q., Dai, J.: Bevformer: learningbird’s-eye-viewrepresentationfromlidar-cameraviaspatiotemporaltrans- formers. IEEE Transactions on Pattern Analysis and Machine Intelligence47(3), 2020–2036 (2024)
2020
-
[20]
In: Advances in Neural Information Processing Systems 35: Annual Conference on Neural Infor- mation Processing Systems 2022, NeurIPS (2022)
Liang, T., Xie, H., Yu, K., Xia, Z., Lin, Z., Wang, Y., Tang, T., Wang, B., Tang, Z.: Bevfusion: A simple and robust lidar-camera fusion framework. In: Advances in Neural Information Processing Systems 35: Annual Conference on Neural Infor- mation Processing Systems 2022, NeurIPS (2022)
2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, F., Zhang, C., Zheng, Y., Duan, Y.: Semantic ray: Learning a generalizable semantic field with cross-reprojection attention. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17386–17396 (2023)
2023
-
[22]
In: Computer Vision - ECCV 2022 - 17th European Conference, Proceedings, Part XXVII
Liu, Y., Wang, T., Zhang, X., Sun, J.: PETR: position embedding transforma- tion for multi-view 3d object detection. In: Computer Vision - ECCV 2022 - 17th European Conference, Proceedings, Part XXVII. pp. 531–548 (2022)
2022
-
[23]
In: The Thirteenth International Conference on Learning Representations (2025)
Lu, G., Wang, Z., Liu, C., Lu, J., Tang, Y.: Thinkbot: Embodied instruction fol- lowing with thought chain reasoning. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[24]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[25]
In: The Tenth International Conference on Learning Representations, ICLR (2022)
Min, S.Y., Chaplot, D.S., Ravikumar, P., Bisk, Y., Salakhutdinov, R.: Film: Fol- lowing instructions in language with modular methods. In: The Tenth International Conference on Learning Representations, ICLR (2022)
2022
-
[26]
IEEE Robotics and Automation Letters7(3), 6870–6877 (2022)
Murray, M., Cakmak, M.: Following natural language instructions for household tasks with landmark guided search and reinforced pose adjustment. IEEE Robotics and Automation Letters7(3), 6870–6877 (2022)
2022
-
[27]
IEEE Robotics and Automation Letters 5(3), 4867–4873 (2020)
Pan, B., Sun, J., Leung, H.Y.T., Andonian, A., Zhou, B.: Cross-view semantic segmentation for sensing surroundings. IEEE Robotics and Automation Letters 5(3), 4867–4873 (2020)
2020
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision
Pashevich, A., Schmid, C., Sun, C.: Episodic transformer for vision-and-language navigation. In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision. pp. 15942–15952 (2021)
2021
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Peng, S., Genova, K., Jiang, C., Tagliasacchi, A., Pollefeys, M., Funkhouser, T., et al.: Openscene: 3d scene understanding with open vocabularies. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 815– 824 (2023)
2023
-
[30]
In: European conference on computer vision
Philion, J., Fidler, S.: Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: European conference on computer vision. pp. 194–210. Springer (2020)
2020
-
[31]
In: Pro- ESCAPE 17 ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Prabhudesai, M., Tung, H.Y.F., Javed, S.A., Sieb, M., Harley, A.W., Fragkiadaki, K.: Embodied language grounding with 3d visual feature representations. In: Pro- ESCAPE 17 ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 2220–2229 (2020)
2020
-
[32]
In: 2023 IEEE Inter- national Conference on Robotics and Automation (ICRA)
Schult, J., Engelmann, F., Hermans, A., Litany, O., Tang, S., Leibe, B.: Mask3d: Mask transformer for 3d semantic instance segmentation. In: 2023 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 8216–8223. IEEE (2023)
2023
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shridhar, M., Thomason, J., Gordon, D., Bisk, Y., Han, W., Mottaghi, R., Zettle- moyer, L., Fox, D.: Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10740–10749 (2020)
2020
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Singh, K.P., Bhambri, S., Kim, B., Mottaghi, R., Choi, J.: Factorizing perception and policy for interactive instruction following. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1888–1897 (2021)
2021
-
[35]
In: Proceedings of the IEEE/CVF international conference on computer vision
Song, C.H., Wu, J., Washington, C., Sadler, B.M., Chao, W.L., Su, Y.: Llm- planner: Few-shot grounded planning for embodied agents with large language models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2998–3009 (2023)
2023
-
[36]
In: Conference on robot learning
Srivastava, S., Li, C., Lingelbach, M., Martín-Martín, R., Xia, F., Vainio, K.E., Lian, Z., Gokmen, C., Buch, S., Liu, K., et al.: Behavior: Benchmark for every- day household activities in virtual, interactive, and ecological environments. In: Conference on robot learning. pp. 477–490. PMLR (2022)
2022
-
[37]
Advances in Neural Information Processing Systems33, 13139–13150 (2020)
Stepputtis, S., Campbell, J., Phielipp, M., Lee, S., Baral, C., Ben Amor, H.: Language-conditioned imitation learning for robot manipulation tasks. Advances in Neural Information Processing Systems33, 13139–13150 (2020)
2020
-
[38]
In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
Szot, A., Clegg, A., Undersander, E., Wijmans, E., Zhao, Y., Turner, J., Maestre, N.,Mukadam,M.,Chaplot,D.,Maksymets,O.,Gokaslan,A.,Vondrus,V.,Dharur, S., Meier, F., Galuba, W., Chang, A., Kira, Z., Koltun, V., Malik, J., Savva, M., Batra, D.: Habitat 2.0: Training home assistants to rearrange their habitat. In: Advances in Neural Information Processing S...
2021
-
[39]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[40]
In: Conference on robot learning
Wang, Y., Guizilini, V.C., Zhang, T., Wang, Y., Zhao, H., Solomon, J.: Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In: Conference on robot learning. pp. 180–191. PMLR (2022)
2022
-
[41]
arXiv preprint arXiv:2406.11818 (2024)
Wu, Z., Wang, Z., Xu, X., Lu, J., Yan, H.: Embodied instruction following in unknown environments. arXiv preprint arXiv:2406.11818 (2024)
-
[42]
In: European Conference on Computer Vision
Xu, X., Luo, S., Yang, Y., Li, Y.L., Lu, C.: Disco: Embodied navigation and in- teraction via differentiable scene semantics and dual-level control. In: European Conference on Computer Vision. pp. 108–125. Springer (2024)
2024
-
[43]
Yang, R., Chen, H., Zhang, J., Zhao, M., Qian, C., Wang, K., Wang, Q., Koripella, T.V., Movahedi, M., Li, M., et al.: Embodiedbench: Comprehensive benchmark- ing multi-modal large language models for vision-driven embodied agents. arXiv preprint arXiv:2502.09560 (2025)
-
[44]
In: Conference on Robot Learning (2023)
Yenamandra, S., Ramachandran, A., Yadav, K., Wang, A., Khanna, M., Gervet, T., Yang, T.Y., Jain, V., Clegg, A.W., Turner, J., Kira, Z., Savva, M., Chang, A., Chaplot, D.S., Batra, D., Mottaghi, R., Bisk, Y., Paxton, C.: Homerobot: Open vocab mobile manipulation. In: Conference on Robot Learning (2023)
2023
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition
Yu, Z., Chen, A., Huang, B., Sattler, T., Geiger, A.: Mip-splatting: Alias-free 3d gaussian splatting. In: Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition. pp. 19447–19456 (2024) 18 J. Qian et al
2024
-
[46]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Zhang, S., Song, X., Yu, X., Bai, Y., Guo, X., Li, W., Jiang, S.: Hoz++: Versa- tile hierarchical object-to-zone graph for object navigation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[47]
The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2024)
Zhao, Q., Fu, H., Sun, C., Konidaris, G.: Epo: Hierarchical llm agents with envi- ronment preference optimization. The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2024)
2024
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhu, F., Liang, X., Zhu, Y., Yu, Q., Chang, X., Liang, X.: Soon: Scenario oriented object navigation with graph-based exploration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12689–12699 (2021)
2021
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhu, J., Huo, Y., Ye, Q., Luan, F., Li, J., Xi, D., Wang, L., Tang, R., Hua, W., Bao, H., et al.: I2-sdf: Intrinsic indoor scene reconstruction and editing via raytracing in neural sdfs. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12489–12498 (2023)
2023
-
[50]
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable detr: Deformable transformers for end-to-end object detection. In: 9th International Conference on Learning Representations, ICLR (2021) ESCAPE 19 A Introduction of ALFRED Benchmark ALFRED [33] is a large scale dataset which includes 25,726 language directives for embodied mobile manipulation ...
2021
-
[51]
Examine an object under the light (e.g
Look & Examine. Examine an object under the light (e.g. examine an apple under the lamp)
-
[52]
Pick an object and place it in a receptacle (e.g
Pick & Place. Pick an object and place it in a receptacle (e.g. pick a bowl and place it on the counter)
-
[53]
Place two object instances in the same receptacle (e.g
Pick & Place Two. Place two object instances in the same receptacle (e.g. throw two apples into the garbage bin)
-
[54]
Place an object in a movable container then place the movable con- tainer in a receptacle (e.g
Stack. Place an object in a movable container then place the movable con- tainer in a receptacle (e.g. place a fork in a plate then put the plate on the counter)
-
[55]
Place a heated object in a receptacle (e.g
Heat & Place. Place a heated object in a receptacle (e.g. place a heated egg on the dining table)
-
[56]
Place a cooled object in a receptacle (e.g
Cool & Place. Place a cooled object in a receptacle (e.g. place a chilled potato on the dinning table)
-
[57]
Heat and Place
Clean & Place. Place a cleaned object in a receptacle (e.g. place a cleaned towel in the sinkbasin). A.2 Sub-tasks All tasks mentioned above can be divided into eight sub-tasks: (1) GotoLocation; (2) PickUp; (3) Put; (4) Slice; (5) Toggle; (6) Heat; (7) Cool; (8) Clean. Each sub-task is a pair of action and target object (e.g. (PickUp, Apple)). A.3 Action...
-
[58]
Language misunderstanding errors constitute the largest proportion of 24 J
ESCAPE achieves 62.32% success rate on seen environments and 61.27% on unseen environments, demonstrating consistent performance across different sce- narios. Language misunderstanding errors constitute the largest proportion of 24 J. Qian et al. failures, accounting for approximately 18-19% in both settings. This suggests the necessity of more robust lan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.