Recognition: unknown
MedRCube: A Multidimensional Framework for Fine-Grained and In-Depth Evaluation of MLLMs in Medical Imaging
Pith reviewed 2026-05-10 12:43 UTC · model grok-4.3
The pith
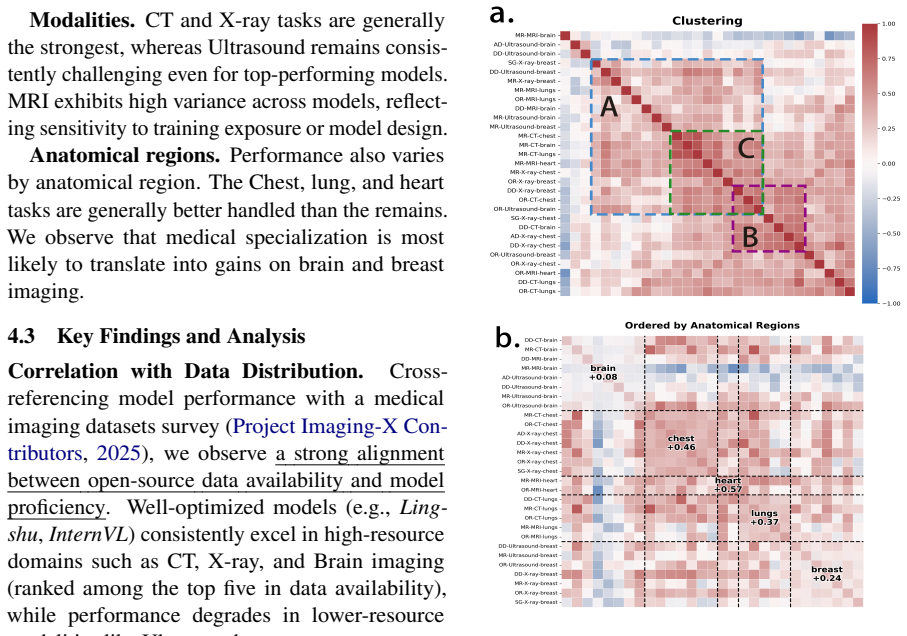
MedRCube is a multidimensional evaluation framework for MLLMs in medical imaging that reveals previously hidden insights and a strong link between shortcut reasoning and higher diagnostic scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
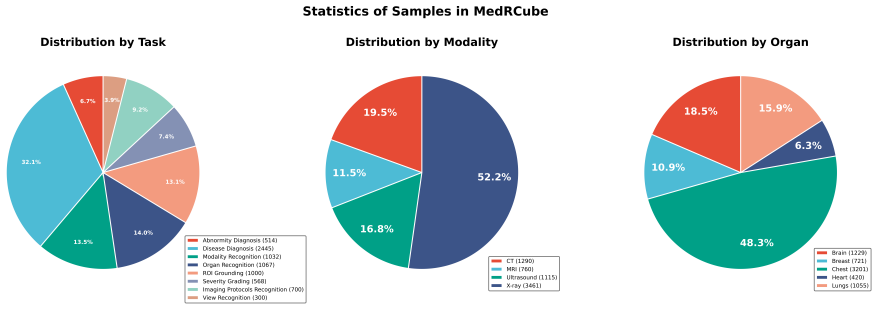
MedRCube is a multidimensional framework for fine-grained evaluation of MLLMs in medical imaging, constructed via a two-stage systematic pipeline. It benchmarks 33 models with Lingshu-32B achieving top-tier results across dimensions, exposes insights unavailable under prior coarse-grained metrics, and through its credibility evaluation subset demonstrates a highly significant positive association between shortcut behavior and diagnostic task performance.
What carries the argument
The two-stage systematic construction pipeline that generates aligned evaluation dimensions and a credibility subset to quantify reasoning reliability.
If this is right
- Coarse single-metric evaluations fail to capture critical aspects of model behavior needed for clinical support.
- Shortcut behavior shows a highly significant positive association with diagnostic task performance.
- Lingshu-32B ranks highest across the fine-grained dimensions of the framework.
- Credibility checks are required to assess reliability for trustworthy clinical deployment.
- Multidimensional evaluation uncovers reasoning patterns that prior methods could not detect.
Where Pith is reading between the lines
- If the shortcut association holds across more models, training objectives may need explicit penalties against shortcut learning to improve reliability.
- Medical deployment decisions should prioritize models that pass credibility tests over those with high diagnostic scores alone.
- The framework could be adapted to test whether the same shortcut-performance link appears in non-medical multimodal tasks.
Load-bearing premise
The two-stage pipeline produces evaluation dimensions that accurately reflect real-world medical imaging practice and the credibility subset measures reasoning without its own biases.
What would settle it
Re-running the credibility subset on a new set of MLLMs and finding no significant correlation between shortcut behavior and diagnostic performance would undermine the reported association.
Figures





read the original abstract
The potential of Multimodal Large Language Models (MLLMs) in domain of medical imaging raise the demands of systematic and rigorous evaluation frameworks that are aligned with the real-world medical imaging practice. Existing practices that report single or coarse-grained metrics are lack the granularity required for specialized clinical support and fail to assess the reliability of reasoning mechanisms. To address this, we propose a paradigm shift toward multidimensional, fine-grained and in-depth evaluation. Based on a two-stage systematic construction pipeline designed for this paradigm, we instantiate it with MedRCube. We benchmark 33 MLLMs, \textit{Lingshu-32B} achieve top-tier performance. Crucially, MedRCube exposes a series of pronounced insights inaccessible under prior evaluation settings. Furthermore, we introduce a credibility evaluation subset to quantify reasoning credibility, uncover a highly significant positive association between shortcut behavior and diagnostic task performance, raising concerns for clinically trustworthy deployment. The resources of this work can be found at https://github.com/F1mc/MedRCube.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MedRCube, a multidimensional framework for fine-grained evaluation of MLLMs in medical imaging, constructed via a two-stage systematic pipeline. It benchmarks 33 MLLMs (with Lingshu-32B achieving top performance), claims to expose insights inaccessible under prior coarse metrics, and introduces a credibility evaluation subset that reveals a highly significant positive association between shortcut behavior and diagnostic task performance.
Significance. If the framework alignment and the reported association are substantiated, the work could meaningfully advance evaluation practices for medical MLLMs by moving beyond single or coarse metrics toward reliability-focused, granular analysis. The broad benchmarking of 33 models provides a useful empirical reference, and the association finding would highlight risks for clinical deployment if confirmed. The contribution is limited by the absence of validation evidence for the pipeline and subset.
major comments (3)
- [Credibility evaluation subset] Credibility evaluation subset: The subset used to quantify reasoning credibility and the headline finding of a highly significant positive association between shortcut behavior and diagnostic performance lack any reported details on construction criteria, proxy measures (e.g., attention patterns or error types), inter-rater reliability, or external validation against clinical ground truth. This association is load-bearing for the central claim of new insights inaccessible to prior settings.
- [Two-stage systematic construction pipeline] Two-stage systematic construction pipeline: The assertion that the pipeline yields dimensions aligned with real-world medical imaging practice is presented without supporting evidence such as expert review, alignment metrics, or comparison to clinical workflows. This alignment is foundational to the framework's claimed advantages over existing practices.
- [Benchmarking results] Benchmarking and statistical analysis: The results from evaluating 33 MLLMs and the statistical controls for the association are stated without specifics on data splits, metric validation procedures, confounder controls (e.g., model scale or training data overlap), or error analysis, leaving the empirical findings unverified.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments on our manuscript. We address each of the major comments in detail below, providing clarifications and outlining planned revisions to enhance the rigor and transparency of the work.
read point-by-point responses
-
Referee: Credibility evaluation subset: The subset used to quantify reasoning credibility and the headline finding of a highly significant positive association between shortcut behavior and diagnostic performance lack any reported details on construction criteria, proxy measures (e.g., attention patterns or error types), inter-rater reliability, or external validation against clinical ground truth. This association is load-bearing for the central claim of new insights inaccessible to prior settings.
Authors: We recognize the importance of providing comprehensive details on the credibility evaluation subset to support the association finding. In the revised manuscript, we will add a new subsection detailing the construction criteria, including how the subset was selected from the broader dataset. We will specify the proxy measures for shortcut behavior, such as reliance on superficial patterns in image descriptions or error types in reasoning chains. Inter-rater reliability will be reported based on the agreement among annotators. For the statistical analysis, we will include more details on controls for confounders like model size. However, external validation against clinical ground truth was beyond the scope of this study and would require additional expert input; we will explicitly state this limitation and its implications for the findings. revision: partial
-
Referee: Two-stage systematic construction pipeline: The assertion that the pipeline yields dimensions aligned with real-world medical imaging practice is presented without supporting evidence such as expert review, alignment metrics, or comparison to clinical workflows. This alignment is foundational to the framework's claimed advantages over existing practices.
Authors: The two-stage pipeline was designed based on a systematic review of medical imaging evaluation literature and clinical practice guidelines to ensure relevance. To substantiate the alignment claim, we will include in the revision additional justification, such as mappings to standard clinical workflows and any quantitative alignment metrics computed during development. If formal expert review was not conducted, we will note this and discuss how the dimensions were validated internally. This will better support the framework's advantages. revision: yes
-
Referee: Benchmarking and statistical analysis: The results from evaluating 33 MLLMs and the statistical controls for the association are stated without specifics on data splits, metric validation procedures, confounder controls (e.g., model scale or training data overlap), or error analysis, leaving the empirical findings unverified.
Authors: We agree that more specifics are needed for the benchmarking results to allow full verification. The revised version will include explicit information on the data splits (e.g., train/test proportions if applicable, though evaluation is zero-shot in many cases), metric validation procedures, confounder controls including model scale and training data considerations, and a detailed error analysis. These elements will be presented in an expanded results section with supplementary tables if necessary. revision: yes
- External validation of the credibility evaluation subset against clinical ground truth
- Formal expert review or quantitative alignment metrics for the two-stage pipeline construction
Circularity Check
No significant circularity detected in MedRCube derivation or findings
full rationale
The paper constructs MedRCube via an independent two-stage systematic pipeline for multidimensional evaluation aligned with medical practice. The credibility evaluation subset is introduced separately to quantify reasoning credibility, and the reported highly significant positive association between shortcut behavior and diagnostic task performance is presented as an empirical result obtained by benchmarking 33 MLLMs. No equations, self-citations, or definitional steps are shown that reduce any claim to its own inputs by construction. The framework and association remain self-contained as construction plus external benchmarking rather than tautological or fitted outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing practices that report single or coarse-grained metrics lack the granularity required for specialized clinical support and fail to assess the reliability of reasoning mechanisms.
- ad hoc to paper A two-stage systematic construction pipeline produces a framework aligned with real-world medical imaging practice.
invented entities (2)
-
MedRCube framework
no independent evidence
-
Credibility evaluation subset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Marah Abdin and 1 others. 2024. https://arxiv.org/abs/2404.14219 Phi-3 technical report: A highly capable language model locally on your phone . Preprint, arXiv:2404.14219. Updated version covers Phi-3.5 Vision
work page internal anchor Pith review arXiv 2024
-
[2]
Walid Al-Dhabyani, Mohammed Gomaa, Hussien Khaled, and Aly Fahmy. 2020. https://doi.org/10.1016/j.dib.2019.104863 Dataset of breast ultrasound images . Data in Brief, 28:104863
-
[3]
Anthropic. 2025. https://www.anthropic.com/news/claude-opus-4-5 Claude opus 4.5
2025
-
[4]
Amanullah Asraf and Zabirul Islam. 2021. https://doi.org/10.17632/jctsfj2sfn.1 COVID19 , pneumonia and normal chest X -ray PA dataset . https://doi.org/10.17632/jctsfj2sfn.1
-
[5]
Seongsu Bae, Daeun Kyung, Jaehee Ryu, Eunbyeol Cho, Gyubok Lee, Sunjun Kweon, Jungwoo Oh, Lei Ji, Eric Chang, Tackeun Kim, and 1 others. 2024. Ehrxqa: A multi-modal question answering dataset for electronic health records with chest x-ray images. Advances in Neural Information Processing Systems, 36
2024
-
[6]
Spyridon Bakas, Hamed Akbari, Aristeidis Sotiras, Michel Bilello, Martin Rozycki, Justin S Kirby, John B Freymann, Keyvan Farahani, and Christos Davatzikos. 2017. Advancing the cancer genome atlas glioma mri collections with expert segmentation labels and radiomic features. Scientific data, 4(1):1--13
2017
-
[7]
Spyridon Bakas, Mauricio Reyes, Andras Jakab, Stefan Bauer, Markus Rempfler, Alessandro Crimi, Russell Takeshi Shinohara, Christoph Berger, Sung Min Ha, Martin Rozycki, and 1 others. 2018. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the brats challenge. arXiv pre...
work page Pith review arXiv 2018
-
[8]
Hasan, and Henning M\"uller
Asma Ben Abacha , Mourad Sarrouti, Dina Demner-Fushman, Sadid A. Hasan, and Henning M\"uller. 2021. Overview of the vqa-med task at imageclef 2021: Visual question answering and generation in the medical domain. In CLEF 2021 Working Notes, CEUR Workshop Proceedings, Bucharest, Romania. CEUR-WS.org
2021
-
[9]
Christian Bluethgen, Dave Van Veen, Cyril Zakka, Katherine E Link, Aaron Hunter Fanous, Roxana Daneshjou, Thomas Frauenfelder, Curtis P Langlotz, Sergios Gatidis, and Akshay Chaudhari. 2025. Best practices for large language models in radiology. Radiology, 315(1):e240528
2025
-
[10]
Victor M Campello, Polyxeni Gkontra, Cristian Izquierdo, Carlos Martin-Isla, Alireza Sojoudi, Peter M Full, Klaus Maier-Hein, Yao Zhang, Zhiqiang He, Jun Ma, and 1 others. 2021. Multi-centre, multi-vendor and multi-disease cardiac segmentation: the m&ms challenge. IEEE Transactions on Medical Imaging, 40(12):3543--3554
2021
-
[11]
Sema Candemir, Stefan Jaeger, Kannappan Palaniappan, Jonathan P Musco, Rahul K Singh, Zhiyun Xue, Alexandros Karargyris, Sameer Antani, George Thoma, and Clement J McDonald. 2013. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration. IEEE transactions on medical imaging, 33(2):577--590
2013
-
[12]
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, and 1 others. 2024 a . Towards injecting medical visual knowledge into multimodal llms at scale. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 7346--7370
2024
- [13]
-
[14]
Muhammad EH Chowdhury, Tawsifur Rahman, Amith Khandakar, Rashid Mazhar, Muhammad Abdul Kadir, Zaid Bin Mahbub, Khandakar Reajul Islam, Muhammad Salman Khan, Atif Iqbal, Nasser Al Emadi, and 1 others. 2020. Can ai help in screening viral and covid-19 pneumonia? Ieee Access, 8:132665--132676
2020
- [15]
-
[16]
Google Deepmind. 2025. https://deepmind.google/models/gemini/pro/ Gemini 3 pro
2025
-
[17]
Aysen Degerli, Mete Ahishali, Mehmet Yamac, Serkan Kiranyaz, Muhammad EH Chowdhury, Khalid Hameed, Tahir Hamid, Rashid Mazhar, and Moncef Gabbouj. 2021. Covid-19 infection map generation and detection from chest x-ray images. Health information science and systems, 9(1):15
2021
-
[18]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, and 1 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Mengjie Fang, Zipei Wang, Sitian Pan, Xin Feng, Yunpeng Zhao, Dongzhi Hou, Ling Wu, Xuebin Xie, Xu-Yao Zhang, Jie Tian, and 1 others. 2025. Large models in medical imaging: Advances and prospects. Chinese Medical Journal, pages 10--1097
2025
-
[20]
Praveen Govi. 2020. CoronaHack -chest X -ray-dataset. https://www.kaggle.com/datasets/praveengovi/coronahack-chest-xraydataset
2020
-
[21]
Gowthaman Gunabushanam, Caroline R Taylor, Mahan Mathur, Jamal Bokhari, and Leslie M Scoutt. 2019. Automated test-item generation system for retrieval practice in radiology education. Academic Radiology, 26(6):851--859
2019
-
[22]
Alessa Hering, Lasse Hansen, Tony CW Mok, Albert CS Chung, Hanna Siebert, Stephanie H \"a ger, Annkristin Lange, Sven Kuckertz, Stefan Heldmann, Wei Shao, and 1 others. 2022. Learn2reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning. IEEE Transactions on Medical Imaging, 42(3):697--712
2022
-
[23]
Benjamin Hou, Pritam Mukherjee, Vivek Batheja, Kenneth C Wang, Ronald M Summers, and Zhiyong Lu. 2025. One year on: assessing progress of multimodal large language model performance on rsna 2024 case of the day questions. Radiology, 316(2):e250617
2025
-
[24]
Murtadha Hssayeni, M Croock, A Salman, H Al-khafaji, Z Yahya, and B Ghoraani. 2020. Computed tomography images for intracranial hemorrhage detection and segmentation. Intracranial hemorrhage segmentation using a deep convolutional model. Data, 5(1):14
2020
-
[25]
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. 2024. Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170--22183
2024
-
[26]
Stefan Jaeger, Sema Candemir, Sameer Antani, Y \` -Xi \'a ng J W \'a ng, Pu-Xuan Lu, and George Thoma. 2014. Two public chest x-ray datasets for computer-aided screening of pulmonary diseases. Quantitative imaging in medicine and surgery, 4(6):475
2014
-
[27]
Stefan Jaeger, Alexandros Karargyris, Sema Candemir, Les Folio, Jenifer Siegelman, Fiona Callaghan, Zhiyun Xue, Kannappan Palaniappan, Rahul K Singh, Sameer Antani, and 1 others. 2013. Automatic tuberculosis screening using chest radiographs. IEEE transactions on medical imaging, 33(2):233--245
2013
-
[28]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421
2021
-
[29]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. Pubmedqa: A dataset for biomedical research question answering. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567--2577
2019
-
[30]
Daniel Kermany. 2018. Labeled optical coherence tomography (oct) and chest x-ray images for classification. Mendeley data
2018
-
[31]
Daniel S Kermany, Michael Goldbaum, Wenjia Cai, Carolina CS Valentim, Huiying Liang, Sally L Baxter, Alex McKeown, Ge Yang, Xiaokang Wu, Fangbing Yan, and 1 others. 2018. Identifying medical diagnoses and treatable diseases by image-based deep learning. cell, 172(5):1122--1131
2018
-
[32]
Sebastian K \"o hler, Michael Gargano, Nicolas Matentzoglu, Leigh C Carmody, David Lewis-Smith, Nicole A Vasilevsky, Daniel Danis, Ganna Balagura, Gareth Baynam, Amy M Brower, and 1 others. 2021. The human phenotype ontology in 2021. Nucleic acids research, 49(D1):D1207--D1217
2021
-
[33]
Zo \'e Lambert, Caroline Petitjean, Bernard Dubray, and Su Kuan. 2020. Segthor: Segmentation of thoracic organs at risk in ct images. In 2020 Tenth International Conference on Image Processing Theory, Tools and Applications (IPTA), pages 1--6. Ieee
2020
-
[34]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. 2018. A dataset of clinically generated visual questions and answers about radiology images. Scientific data, 5(1):1--10
2018
-
[35]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2024. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. In Advances in Neural Information Processing Systems (NeurIPS)
2024
- [36]
-
[37]
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Fang Yang, and Xiao-Ming Wu. 2021. https://api.semanticscholar.org/CorpusID:231951663 Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering . 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pages 1650--1654
2021
-
[38]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. In CVPR. LLaVA-v1.5
2024
- [39]
-
[40]
Kevin Mader. 2017. Finding and measuring lungs in CT data. https://www.kaggle.com/datasets/kmader/finding-lungs-in-ct-data
2017
-
[41]
Carlos Mart \' n-Isla, V \' ctor M Campello, Cristian Izquierdo, Kaisar Kushibar, Carla Sendra-Balcells, Polyxeni Gkontra, Alireza Sojoudi, Mitchell J Fulton, Tewodros Weldebirhan Arega, Kumaradevan Punithakumar, and 1 others. 2023. Deep learning segmentation of the right ventricle in cardiac mri: the m&ms challenge. IEEE Journal of Biomedical and Health ...
2023
-
[42]
Bjoern H Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy-Cramer, Keyvan Farahani, Justin Kirby, Yuliya Burren, Nicole Porz, Johannes Slotboom, Roland Wiest, and 1 others. 2014. The multimodal brain tumor image segmentation benchmark (brats). IEEE transactions on medical imaging, 34(10):1993--2024
2014
-
[43]
National Board of Medical Examiners . 2024. https://www.nbme.org/sites/default/files/2021-02/NBME_Item Philadelphia, PA. Accessed: 2025-10-08
2024
-
[44]
OpenAI. 2025. https://platform.openai.com/docs/models/gpt-5.1 Gpt-5.1
2025
-
[45]
OpenGVLab. 2025. https://arxiv.org/abs/2508.18265 Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency . Preprint, arXiv:2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
-
[47]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on health, inference, and learning, pages 248--260. PMLR
2022
- [48]
-
[49]
Hieu H Pham, Ngoc H Nguyen, Thanh T Tran, Tuan NM Nguyen, and Ha Q Nguyen. 2023. Pedicxr: an open, large-scale chest radiograph dataset for interpretation of common thoracic diseases in children. Scientific Data, 10(1):240
2023
-
[50]
Project Imaging-X Contributors . 2025. https://github.com/uni-medical/Project-Imaging-X Project imaging-x: A survey of 1000+ open-access medical imaging datasets for foundation model development
2025
-
[51]
Radiological Society of North America . 2018. RSNA pneumonia detection challenge. https://www.kaggle.com/c/rsna-pneumonia-detection-challenge
2018
-
[52]
Radiological Society of North America . 2024. http://radlex.org/ Radlex radiology lexicon . Accessed: 2025-10-08
2024
-
[53]
Tawsifur Rahman, Amith Khandakar, Yazan Qiblawey, Anas Tahir, Serkan Kiranyaz, Saad Bin Abul Kashem, Mohammad Tariqul Islam, Somaya Al Maadeed, Susu M Zughaier, Muhammad Salman Khan, and 1 others. 2021. Exploring the effect of image enhancement techniques on covid-19 detection using chest x-ray images. Computers in biology and medicine, 132:104319
2021
-
[54]
Pranav Raikokte. 2020. Covid-19 image dataset, 3 way classification- covid-19, viral pneumonia, normal . https://www.kaggle.com/datasets/pranavraikokte/covid19-image-dataset
2020
-
[55]
Alvin Rajkomar, Sneha Lingam, Andrew G Taylor, Michael Blum, and John Mongan. 2017. High-throughput classification of radiographs using deep convolutional neural networks. Journal of digital imaging, 30(1):95--101
2017
-
[56]
Holger R Roth, Ziyue Xu, Carlos Tor-D \' ez, Ramon Sanchez Jacob, Jonathan Zember, Jose Molto, Wenqi Li, Sheng Xu, Baris Turkbey, Evrim Turkbey, and 1 others. 2022. Rapid artificial intelligence solutions in a pandemic—the covid-19-20 lung ct lesion segmentation challenge. Medical image analysis, 82:102605
2022
-
[57]
u ckert, Louise Bloch, Raphael Br \
Johannes R \"u ckert, Louise Bloch, Raphael Br \"u ngel, Ahmad Idrissi-Yaghir, Henning Sch \"a fer, Cynthia S Schmidt, Sven Koitka, Obioma Pelka, Asma Ben Abacha, Alba G. Seco de Herrera, and 1 others. 2024. Rocov2: Radiology objects in context version 2, an updated multimodal image dataset. Scientific Data, 11(1):688
2024
-
[58]
Rebecca Sawyer-Lee, Francisco Gimenez, Assaf Hoogi, and Daniel Rubin. 2016. Curated breast imaging subset of digital database for screening mammography (cbis-ddsm). (No Title)
2016
-
[59]
German Gonzalez Serrano. 2019. https://doi.org/10.21227/9bw7-6823 Cad-pe
-
[60]
Junji Shiraishi, Shigehiko Katsuragawa, Junpei Ikezoe, Tsuneo Matsumoto, Takeshi Kobayashi, Ken-ichi Komatsu, Mitate Matsui, Hiroshi Fujita, Yoshie Kodera, and Kunio Doi. 2000. Development of a digital image database for chest radiographs with and without a lung nodule: receiver operating characteristic analysis of radiologists' detection of pulmonary nod...
2000
-
[61]
Amber L Simpson, Michela Antonelli, Spyridon Bakas, Michel Bilello, Keyvan Farahani, Bram Van Ginneken, Annette Kopp-Schneider, Bennett A Landman, Geert Litjens, Bjoern Menze, and 1 others. 2019. A large annotated medical image dataset for the development and evaluation of segmentation algorithms. arXiv preprint arXiv:1902.09063
-
[62]
John Suckling, J Parker, D Dance, S Astley, I Hutt, C Boggis, I Ricketts, E Stamatakis, N Cerneaz, S Kok, and 1 others. 2015. Mammographic image analysis society (mias) database v1. 21. (No Title)
2015
- [63]
-
[64]
Siham Tabik, Anabel G \'o mez-R \' os, Jos \'e Luis Mart \' n-Rodr \' guez, Iv \'a n Sevillano-Garc \' a, Manuel Rey-Area, David Charte, Emilio Guirado, Juan-Luis Su \'a rez, Juli \'a n Luengo, MA Valero-Gonz \'a lez, and 1 others. 2020. Covidgr dataset and covid-sdnet methodology for predicting covid-19 based on chest x-ray images. IEEE journal of biomed...
2020
-
[65]
Anas M. Tahir, Muhammad E. H. Chowdhury, Yazan Qiblawey, Amith Khandakar, Tawsifur Rahman, Serkan Kiranyaz, Uzair Khurshid, Nabil Ibtehaz, Sakib Mahmud, and Maymouna Ezeddin. 2021 a . https://doi.org/10.34740/kaggle/dsv/3122958 COVID-QU-Ex dataset . https://www.kaggle.com/datasets/anasmohammedtahir/covidqu
-
[66]
Anas M Tahir, Muhammad EH Chowdhury, Amith Khandakar, Tawsifur Rahman, Yazan Qiblawey, Uzair Khurshid, Serkan Kiranyaz, Nabil Ibtehaz, M Sohel Rahman, Somaya Al-Maadeed, and 1 others. 2021 b . Covid-19 infection localization and severity grading from chest x-ray images. Computers in biology and medicine, 139:105002
2021
- [67]
- [68]
-
[70]
Qwen Team. 2025 b . Qwen3-vl technical report. Technical Report. See also Qwen2.5-VL arXiv:2409.12191 if Qwen3 specific paper is unavailable
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Catalina Tobon-Gomez, Arjan J Geers, Jochen Peters, J \"u rgen Weese, Karen Pinto, Rashed Karim, Mohammed Ammar, Abdelaziz Daoudi, Jan Margeta, Zulma Sandoval, and 1 others. 2015. Benchmark for algorithms segmenting the left atrium from 3d ct and mri datasets. IEEE transactions on medical imaging, 34(7):1460--1473
2015
-
[72]
KAY H VYDARENY, CAROLINE E BLANE, and JUDITH G CALHOUN. 1986. Guidelines for writing multiple-choice questions in radiology courses. Investigative Radiology, 21(11):871--876
1986
-
[73]
Akihiko Wada, Yuya Tanaka, Mitsuo Nishizawa, Akira Yamamoto, Toshiaki Akashi, Akifumi Hagiwara, Yayoi Hayakawa, Junko Kikuta, Keigo Shimoji, Katsuhiro Sano, and 1 others. 2025. Retrieval-augmented generation elevates local llm quality in radiology contrast media consultation. npj Digital Medicine, 8(1):395
2025
-
[74]
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. 2017. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2097--2106
2017
-
[75]
World Health Organization . 2022. https://icd.who.int/en International Statistical Classification of Diseases and Related Health Problems (11th ed.) . World Health Organization. Released in 2018; officially in effect as of January 2022
2022
- [76]
- [77]
-
[78]
Yiming Xiao, Hassan Rivaz, Matthieu Chabanas, Maryse Fortin, Ines Machado, Yangming Ou, Mattias P Heinrich, Julia A Schnabel, Xia Zhong, Andreas Maier, and 1 others. 2019. Evaluation of mri to ultrasound registration methods for brain shift correction: the curious2018 challenge. IEEE transactions on medical imaging, 39(3):777--786
2019
- [79]
- [80]
-
[81]
Yuan Yao, Tianyu Yu, Ao Zhang, and 1 others. 2024. https://arxiv.org/abs/2408.01800 Minicpm-v: A gpt-4v level mllm on your phone . Preprint, arXiv:2408.01800. Covers MiniCPM-V 2.6 and MiniCPM-o series
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.