Recognition: unknown
From Synchrony to Sequence: Exo-to-Ego Generation via Interpolation
Pith reviewed 2026-05-10 13:19 UTC · model grok-4.3
The pith
Interpolating exo and ego videos into one continuous sequence lets diffusion models generate coherent first-person views by removing synchronization jumps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
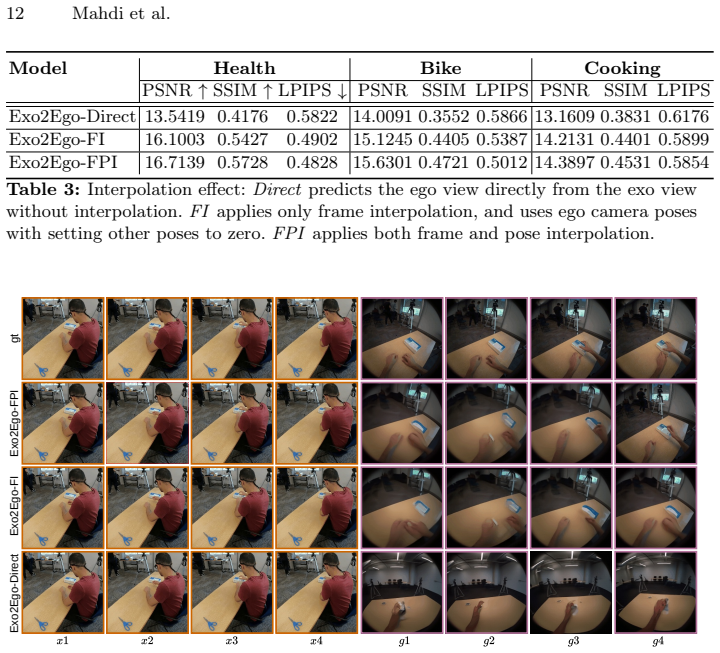
We identify the synchronization-induced jump as the central challenge in exo-to-ego video generation and propose Syn2Seq-Forcing, a sequential formulation that interpolates between the source and target videos to form a single continuous signal. By reframing the task as sequential signal modeling rather than a conventional condition-output task, our approach enables diffusion-based sequence models to capture coherent transitions across frames more effectively. Empirically, interpolating only the videos, without performing pose interpolation, already produces significant improvements, showing that the dominant difficulty arises from spatio-temporal discontinuities.
What carries the argument
Syn2Seq-Forcing, the interpolation of exo and ego videos into one continuous sequence that turns the generation task into sequential signal modeling for diffusion transformers.
If this is right
- Interpolating only the videos produces significant improvements in generated video quality.
- The same continuous-sequence formulation unifies exo-to-ego and ego-to-exo generation inside one model.
- Diffusion-based sequence models become directly applicable to cross-view video tasks once discontinuities are removed by interpolation.
- The approach provides a general framework for future work on cross-view video synthesis without requiring separate geometric handling at inference.
Where Pith is reading between the lines
- Similar interpolation steps could help other video tasks that cross camera views or modalities where raw inputs contain abrupt jumps.
- The result suggests that apparent failures in video generation often trace back to input continuity rather than model architecture or data volume.
- Testing the method with sequence models other than Diffusion Forcing Transformers would show how general the continuity benefit is.
- The framework may reduce reliance on accurate pose estimation during training by letting the model focus on learning smooth frame transitions.
Load-bearing premise
That the synchronization-induced spatio-temporal discontinuities are the main obstacle and that simple video interpolation alone creates a signal whose transitions existing diffusion sequence models can learn without new artifacts or pose interpolation.
What would settle it
Train the same diffusion sequence model on the original discontinuous synchronized pairs versus the interpolated continuous versions and check whether the non-interpolated version matches or exceeds the interpolated performance on standard generation metrics.
Figures





read the original abstract
Exo-to-Ego video generation aims to synthesize a first-person video from a synchronized third-person view and corresponding camera poses. While paired supervision is available, synchronized exo-ego data inherently introduces substantial spatio-temporal and geometric discontinuities, violating the smooth-motion assumptions of standard video generation benchmarks. We identify this synchronization-induced jump as the central challenge and propose Syn2Seq-Forcing, a sequential formulation that interpolates between the source and target videos to form a single continuous signal. By reframing Exo2Ego as sequential signal modeling rather than a conventional condition-output task, our approach enables diffusion-based sequence models, e.g. Diffusion Forcing Transformers (DFoT), to capture coherent transitions across frames more effectively. Empirically, we show that interpolating only the videos, without performing pose interpolation already produces significant improvements, emphasizing that the dominant difficulty arises from spatio-temporal discontinuities. Beyond immediate performance gains, this formulation establishes a general and flexible framework capable of unifying both Exo2Ego and Ego2Exo generation within a single continuous sequence model, providing a principled foundation for future research in cross-view video synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Syn2Seq-Forcing, a reformulation of exo-to-ego video generation as a sequential interpolation task. By interpolating between synchronized third-person (exo) and first-person (ego) videos to create a single continuous signal, the approach enables diffusion sequence models (e.g., DFoT) to model coherent transitions. The central claim is that video interpolation alone—without pose interpolation—already yields significant empirical gains, indicating that synchronization-induced spatio-temporal discontinuities are the dominant obstacle. The method is presented as a general framework that also unifies exo-to-ego and ego-to-exo generation.
Significance. If the empirical results and artifact analysis hold, the work offers a principled reframing of cross-view synthesis as sequence modeling rather than direct conditional generation. This could simplify training with existing diffusion models and provide a flexible template for other discontinuous paired-video tasks.
major comments (2)
- [Abstract] Abstract: The assertion that 'interpolating only the videos, without performing pose interpolation already produces significant improvements' is load-bearing for the central claim, yet the abstract (and by extension the manuscript's experimental section) must supply concrete metrics, baselines, dataset details, and ablations to demonstrate that gains arise from continuity rather than other modeling choices.
- [Method] Method section (interpolation procedure): The description of how exo and ego frames are interpolated (pixel space, latent space, or flow-based) is essential; without it, the claim that the resulting sequence forms a learnable continuous signal cannot be evaluated against the risk of new geometric artifacts such as inconsistent object scales, parallax violations, or lighting mismatches between viewpoints.
minor comments (1)
- [Introduction] The acronym Syn2Seq-Forcing and its precise relation to Diffusion Forcing Transformers should be defined on first use in the introduction for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments. We agree that greater specificity is required in both the abstract and method sections to fully substantiate the central claims. We address each major comment below and will implement the indicated revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'interpolating only the videos, without performing pose interpolation already produces significant improvements' is load-bearing for the central claim, yet the abstract (and by extension the manuscript's experimental section) must supply concrete metrics, baselines, dataset details, and ablations to demonstrate that gains arise from continuity rather than other modeling choices.
Authors: We agree that the abstract would benefit from explicit quantitative support. The experimental section already reports comparisons against direct-conditioning baselines together with ablations that isolate the contribution of video interpolation (as opposed to other modeling choices) on the datasets described in Section 4. We will revise the abstract to reference the key metrics and ablation outcomes that demonstrate the continuity effect. revision: yes
-
Referee: [Method] Method section (interpolation procedure): The description of how exo and ego frames are interpolated (pixel space, latent space, or flow-based) is essential; without it, the claim that the resulting sequence forms a learnable continuous signal cannot be evaluated against the risk of new geometric artifacts such as inconsistent object scales, parallax violations, or lighting mismatches between viewpoints.
Authors: We acknowledge that the current description of the interpolation procedure is insufficiently detailed for reproducibility and artifact analysis. We will expand the Method section to specify that linear interpolation is performed directly in pixel space between temporally aligned exo and ego frames, and we will add qualitative examples and discussion evaluating potential geometric inconsistencies arising from viewpoint differences. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper reframes Exo-to-Ego generation as Syn2Seq-Forcing by interpolating source and target videos into a continuous sequence for diffusion models like DFoT. This is an explicit modeling choice justified by the observation that synchronization creates spatio-temporal jumps, with the empirical claim that video-only interpolation yields gains. No equations, fitted parameters, or self-citations are shown that reduce the central result to a tautology or input by construction. The approach is self-contained against external benchmarks and does not invoke uniqueness theorems or rename known patterns as new derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion-based sequence models perform better on continuous interpolated signals than on discontinuous synchronized pairs.
Reference graph
Works this paper leans on
-
[1]
AIGC-Apps: Videox-fun: A flexible framework for video generation.https:// github.com/aigc-apps/VideoX-Fun(2024), accessed: 2026-03-05 14 Mahdi et al
2024
-
[2]
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H., Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. arXiv preprint arXiv:2503.11647 (2025)
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review arXiv 2023
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion mod- els. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22563–22575 (2023)
2023
-
[5]
arXiv preprint arXiv:2510.02283 (2025)
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y., Hsieh, C.J.: Self-forcing++: Towards minute-scale high-quality video generation. arXiv preprint arXiv:2510.02283 (2025)
-
[6]
Fu, Y., Wang, R., Fu, Y., Paudel, D.P., Van Gool, L.: Cross-view multi-modal segmentation @ ego-exo4d challenges 2025 (2025), ego-Exo4D Challenge
2025
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Fu, Y., Wang, R., Ren, B., Sun, G., Gong, B., Fu, Y., Paudel, D.P., Huang, X., Van Gool, L.: Objectrelator: Enabling cross-view object relation understanding across ego-centric and exo-centric perspectives. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6530–6540 (2025)
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19383–19400 (2024)
2024
-
[9]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
work page internal anchor Pith review arXiv 2023
-
[10]
LTX-2: Efficient Joint Audio-Visual Foundation Model
HaCohen, Y., Brazowski, B., Chiprut, N., Bitterman, Y., Kvochko, A., Berkowitz, A., Shalem, D., Lifschitz, D., Moshe, D., Porat, E., et al.: Ltx-2: Efficient joint audio-visual foundation model. arXiv preprint arXiv:2601.03233 (2026)
work page Pith review arXiv 2026
-
[11]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024)
work page internal anchor Pith review arXiv 2024
-
[12]
arXiv preprint arXiv:2507.18342 (2025)
He, Y., Huang, Y., Chen, G., Pei, B., Xu, J., Lu, T., Pang, J.: Egoexobench: A benchmark for first-and third-person view video understanding in mllms. arXiv preprint arXiv:2507.18342 (2025)
-
[13]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
work page internal anchor Pith review arXiv 2022
-
[14]
Advances in neural information processing systems35, 8633– 8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in neural information processing systems35, 8633– 8646 (2022)
2022
- [15]
-
[16]
arXiv preprint arXiv:2508.10934 (2025)
Huang, J., Zhou, Q., Rabeti, H., Korovko, A., Ling, H., Ren, X., Shen, T., Gao, J., Slepichev,D.,Lin,C.H.,etal.:Vipe:Videoposeenginefor3dgeometricperception. arXiv preprint arXiv:2508.10934 (2025)
-
[17]
In: Proceedings Syn2Seq-Forcing 15 of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, S., Gong, B., Feng, Y., Chen, X., Fu, Y., Liu, Y., Wang, D.: Learning disen- tangled identifiers for action-customized text-to-image generation. In: Proceedings Syn2Seq-Forcing 15 of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7797–7806 (2024)
2024
-
[18]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
work page internal anchor Pith review arXiv 2025
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Y., Chen, G., Xu, J., Zhang, M., Yang, L., Pei, B., Zhang, H., Dong, L., Wang, Y., Wang, L., et al.: Egoexolearn: A dataset for bridging asynchronous ego- and exo-centric view of procedural activities in real world. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22072– 22086 (2024)
2024
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025)
2025
-
[21]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Advances in neural information processing systems25 (2012)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep con- volutional neural networks. Advances in neural information processing systems25 (2012)
2012
-
[23]
arXiv preprint arXiv:2505.21955 (2025)
Lee, I., Park, W., Jang, J., Noh, M., Shim, K., Shim, B.: Towards comprehen- sive scene understanding: Integrating first and third-person views for lvlms. arXiv preprint arXiv:2505.21955 (2025)
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, R., Torr, P., Vedaldi, A., Jakab, T.: Vmem: Consistent interactive video scene generation with surfel-indexed view memory. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 25690–25699 (2025)
2025
-
[25]
In: Eu- ropean Conference on Computer Vision
Li, Y.M., Huang, W.J., Wang, A.L., Zeng, L.A., Meng, J.K., Zheng, W.S.: Egoexo- fitness: Towards egocentric and exocentric full-body action understanding. In: Eu- ropean Conference on Computer Vision. pp. 363–382. Springer (2024)
2024
-
[26]
In: ICASSP 2020-2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP)
Liu, G., Tang, H., Latapie, H., Yan, Y.: Exocentric to egocentric image generation via parallel generative adversarial network. In: ICASSP 2020-2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1843–1847. IEEE (2020)
2020
-
[27]
Liu, J.W., Mao, W., Xu, Z., Keppo, J., Shou, M.Z.: Exocentric-to-egocentric video generation.AdvancesinNeuralInformationProcessingSystems37,136149–136172 (2024)
2024
-
[28]
IEEE Geoscience and Remote Sensing Letters (2025)
Liu, Y., Pan, J., Yang, J., Chen, T., Zhou, P., Zhang, B.: Diverse instance genera- tion via diffusion models for enhanced few-shot object detection in remote sensing images. IEEE Geoscience and Remote Sensing Letters (2025)
2025
-
[29]
arXiv preprint arXiv:2507.21816 (2025)
Liu, Y., Pan, J., Zhang, B.: Control copy-paste: Controllable diffusion-based aug- mentation method for remote sensing few-shot object detection. arXiv preprint arXiv:2507.21816 (2025)
-
[30]
arXiv preprint arXiv:2403.09194 (2024)
Luo, H., Zhu, K., Zhai, W., Cao, Y.: Intention-driven ego-to-exo video generation. arXiv preprint arXiv:2403.09194 (2024)
-
[31]
In: European Conference on Computer Vision
Luo, M., Xue, Z., Dimakis, A., Grauman, K.: Put myself in your shoes: Lifting the egocentric perspective from exocentric videos. In: European Conference on Computer Vision. pp. 407–425. Springer (2024)
2024
-
[32]
arXiv preprint arXiv:2511.20186 (2025) 16 Mahdi et al
Mahdi, M., Fu, Y., Savov, N., Pan, J., Paudel, D.P., Van Gool, L.: Exo2egosyn: Unlocking foundation video generation models for exocentric-to-egocentric video synthesis. arXiv preprint arXiv:2511.20186 (2025) 16 Mahdi et al
-
[33]
In: ICCV (2025)
Mur-Labadia, L., Santos-Villafranca, M., Bermudez-Cameo, J., Perez-Yus, A., Martinez-Cantin, R., Guerrero, J.J.: O-mama: Learning object mask matching between egocentric and exocentric views. In: ICCV (2025)
2025
-
[34]
arXiv preprint arXiv:2505.12108 (2025)
Pan, J., Lei, S., Fu, Y., Li, J., Liu, Y., Sun, Y., He, X., Peng, L., Huang, X., Zhao, B.: Earthsynth: Generating informative earth observation with diffusion models. arXiv preprint arXiv:2505.12108 (2025)
-
[35]
arXiv preprint arXiv:2506.05856 (2025)
Pan, J., Wang, R., Qian, T., Mahdi, M., Fu, Y., Xue, X., Huang, X., Van Gool, L., Paudel, D.P., Fu, Y.: V²-sam: Marrying sam2 with multi-prompt experts for cross-view object correspondence. arXiv preprint arXiv:2506.05856 (2025)
-
[36]
arXiv preprint arXiv:2506.17896 (2025)
Park, J., Ye, A.S., Kwon, T.: Egoworld: Translating exocentric view to egocentric view using rich exocentric observations. arXiv preprint arXiv:2506.17896 (2025)
-
[37]
URL https://deepmind
Parker-Holder, J., Fruchter, S.: Genie 3: A new frontier for world models. URL https://deepmind. google/discover/blog/genie-3-a-new-frontier-for-world- models/. Blog post (2025)
2025
-
[38]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ren,X.,Shen,T.,Huang,J.,Ling,H.,Lu,Y.,Nimier-David,M.,Müller,T.,Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video generation with precise camera control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6121–6132 (2025)
2025
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
- [41]
-
[42]
History-guided video diffusion.arXiv preprint arXiv:2502.06764, 2025
Song, K., Chen, B., Simchowitz, M., Du, Y., Tedrake, R., Sitzmann, V.: History- guided video diffusion. arXiv preprint arXiv:2502.06764 (2025)
-
[43]
Sun, W., Zhang, H., Wang, H., Wu, J., Wang, Z., Wang, Z., Wang, Y., Zhang, J., Wang, T., Guo, C.: Worldplay: Towards long-term geometric consistency for real-time interactive world modeling. arXiv preprint arXiv:2512.14614 (2025)
-
[44]
Advancing open-source world models,
Team, R., Gao, Z., Wang, Q., Zeng, Y., Zhu, J., Cheng, K.L., Li, Y., Wang, H., Xu, Y., Ma, S., et al.: Advancing open-source world models. arXiv preprint arXiv:2601.20540 (2026)
-
[45]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[47]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wu, J.Z., Ge, Y., Wang, X., Lei, S.W., Gu, Y., Shi, Y., Hsu, W., Shan, Y., Qie, X., Shou, M.Z.: Tune-a-video: One-shot tuning of image diffusion models for text- to-video generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7623–7633 (2023)
2023
-
[48]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284,
Wu, T., Yang, S., Po, R., Xu, Y., Liu, Z., Lin, D., Wetzstein, G.: Video world models with long-term spatial memory. arXiv preprint arXiv:2506.05284 (2025)
-
[49]
arXiv preprint arXiv:2504.11732 (2025) Syn2Seq-Forcing 17
Xu, J., Huang, Y., Pei, B., Hou, J., Li, Q., Chen, G., Zhang, Y., Feng, R., Xie, W.: Egoexo-gen: Ego-centric video prediction by watching exo-centric videos. arXiv preprint arXiv:2504.11732 (2025) Syn2Seq-Forcing 17
-
[50]
In: ACM SIGGRAPH 2024 Conference Papers
Yang, S., Hou, L., Huang, H., Ma, C., Wan, P., Zhang, D., Chen, X., Liao, J.: Direct-a-video: Customized video generation with user-directed camera movement and object motion. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–12 (2024)
2024
-
[51]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review arXiv 2024
-
[52]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yu, M., Hu, W., Xing, J., Shan, Y.: Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 100–111 (2025)
2025
-
[53]
International Journal of Computer Vision133(4), 1879–1893 (2025)
Zhang, D.J., Wu, J.Z., Liu, J.W., Zhao, R., Ran, L., Gu, Y., Gao, D., Shou, M.Z.: Show-1: Marrying pixel and latent diffusion models for text-to-video generation. International Journal of Computer Vision133(4), 1879–1893 (2025)
2025
-
[54]
Magicvideo: Efficient video generation with latent diffusion models
Zhou, D., Wang, W., Yan, H., Lv, W., Zhu, Y., Feng, J.: Magicvideo: Efficient video generation with latent diffusion models. arXiv preprint arXiv:2211.11018 (2022) Supplementary Materials From Synchrony to Sequence: Exo-to-Ego Generation via Interpolation Mohammad Mahdi1 Nedko Savov1 Danda Pani Paudel1⋆ Luc Van Gool1 1 INSAIT, Sofia University “St. Klimen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.