Recognition: unknown
Any3DAvatar: Fast and High-Quality Full-Head 3D Avatar Reconstruction from Single Portrait Image
Pith reviewed 2026-05-10 14:17 UTC · model grok-4.3
The pith
A single portrait can be turned into a full 3D head avatar with high-fidelity geometry and texture in under one second.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Any3DAvatar reconstructs a complete 3D head avatar from a single portrait by initializing a Plücker-aware structured 3D Gaussian scaffold and running one-step conditional denoising, while adding auxiliary view-conditioned appearance supervision on the same latent tokens to sharpen novel-view texture without raising inference cost. The model is trained on the AnyHead data suite that supplies broad identity coverage, dense multi-view images, and realistic accessories.
What carries the argument
Plücker-aware structured 3D Gaussian scaffold with one-step conditional denoising that converts full-head reconstruction into a single forward pass while keeping geometry and appearance fidelity.
Load-bearing premise
The AnyHead data suite gives enough identity variety, multi-view supervision, and accessory realism for the trained model to handle new portraits without extra per-person steps.
What would settle it
Run the model on portraits showing hairstyles, headwear, or lighting conditions absent from AnyHead and check whether geometry becomes incomplete or textures turn blurry in novel views.
Figures


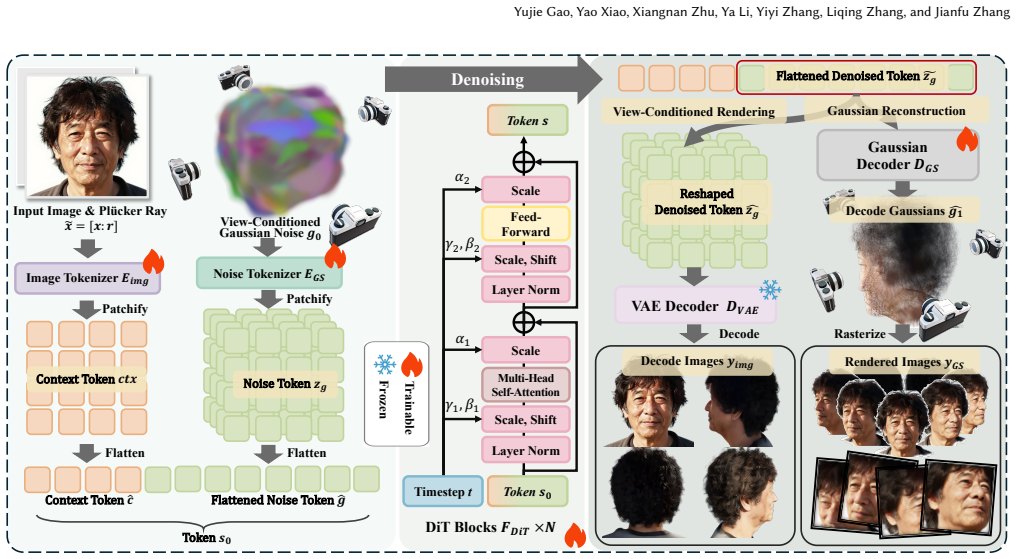












read the original abstract
Reconstructing a complete 3D head from a single portrait remains challenging because existing methods still face a sharp quality-speed trade-off: high-fidelity pipelines often rely on multi-stage processing and per-subject optimization, while fast feed-forward models struggle with complete geometry and fine appearance details. To bridge this gap, we propose Any3DAvatar, a fast and high-quality method for single-image 3D Gaussian head avatar generation, whose fastest setting reconstructs a full head in under one second while preserving high-fidelity geometry and texture. First, we build AnyHead, a unified data suite that combines identity diversity, dense multi-view supervision, and realistic accessories, filling the main gaps of existing head data in coverage, full-head geometry, and complex appearance. Second, rather than sampling unstructured noise, we initialize from a Pl\"ucker-aware structured 3D Gaussian scaffold and perform one-step conditional denoising, formulating full-head reconstruction into a single forward pass while retaining high fidelity. Third, we introduce auxiliary view-conditioned appearance supervision on the same latent tokens alongside 3D Gaussian reconstruction, improving novel-view texture details at zero extra inference cost. Experiments show that Any3DAvatar outperforms prior single-image full-head reconstruction methods in rendering fidelity while remaining substantially faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Any3DAvatar for single-portrait full-head 3D Gaussian avatar reconstruction. It constructs the AnyHead dataset to supply identity diversity, dense multi-view geometry, and accessory variation; initializes a Plücker-aware structured 3D Gaussian scaffold and performs one-step conditional denoising to enable a single forward pass; and adds auxiliary view-conditioned appearance supervision on the same latent tokens. The method is claimed to deliver higher rendering fidelity than prior single-image full-head approaches while reconstructing a complete head in under one second.
Significance. If the quantitative results and generalization claims hold, the work would meaningfully advance practical 3D avatar pipelines by removing per-subject optimization while preserving geometry and texture quality. The structured-scaffold one-step formulation and zero-cost auxiliary supervision are technically interesting contributions to efficient feed-forward 3D generation. The AnyHead dataset, if released with the promised coverage, could become a useful resource for the community.
major comments (2)
- [§3 (AnyHead Dataset)] §3 (AnyHead Dataset): the central generalization claim—that training on AnyHead enables feed-forward reconstruction on unseen portraits without per-subject optimization—rests on the dataset supplying sufficient identity variety, accurate dense multi-view labels, and accessory diversity. No subject counts, views-per-subject statistics, accessory category breakdown, collection protocol, or held-out validation metrics are supplied, preventing assessment of whether the data actually closes the stated gaps.
- [§5 (Experiments)] §5 (Experiments): the abstract asserts outperformance in rendering fidelity and substantial speed gains, yet the manuscript provides no quantitative tables, error bars, ablation results on the one-step denoising step, or direct comparisons of geometry accuracy. Without these, the high-fidelity claim cannot be verified and the speed-quality trade-off resolution remains unproven.
minor comments (2)
- [§4 (Method)] The integration of Plücker coordinates into the Gaussian scaffold initialization is only sketched; a short diagram or explicit coordinate transformation equation would improve clarity.
- [§4.3 (Auxiliary Supervision)] Notation for the auxiliary view supervision loss is introduced without an explicit equation number; cross-referencing it to the main reconstruction loss would aid readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We appreciate the opportunity to clarify and strengthen our manuscript. Below, we address each major comment point by point. We will revise the paper to incorporate the suggested improvements where appropriate.
read point-by-point responses
-
Referee: [§3 (AnyHead Dataset)] §3 (AnyHead Dataset): the central generalization claim—that training on AnyHead enables feed-forward reconstruction on unseen portraits without per-subject optimization—rests on the dataset supplying sufficient identity variety, accurate dense multi-view labels, and accessory diversity. No subject counts, views-per-subject statistics, accessory category breakdown, collection protocol, or held-out validation metrics are supplied, preventing assessment of whether the data actually closes the stated gaps.
Authors: We agree that providing these details is essential for validating the dataset's role in enabling generalization. In the revised manuscript, we will expand Section 3 to include comprehensive statistics on the AnyHead dataset, such as the total number of subjects, average views per subject, breakdown of accessory categories, the data collection protocol, and results from held-out validation sets. This will allow readers to better assess how the dataset addresses the gaps in existing head data. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments): the abstract asserts outperformance in rendering fidelity and substantial speed gains, yet the manuscript provides no quantitative tables, error bars, ablation results on the one-step denoising step, or direct comparisons of geometry accuracy. Without these, the high-fidelity claim cannot be verified and the speed-quality trade-off resolution remains unproven.
Authors: We acknowledge that the current version of the manuscript does not include explicit quantitative tables or the requested ablations and comparisons. To address this, we will add detailed quantitative results in Section 5, including tables with metrics for rendering fidelity (e.g., PSNR, SSIM, LPIPS), speed measurements, error bars where applicable, ablation studies specifically on the one-step denoising component, and direct comparisons of geometry accuracy against prior methods. These additions will substantiate the claims made in the abstract and provide a clearer view of the speed-quality trade-off. revision: yes
Circularity Check
No significant circularity: new dataset and pipeline are independent of prior self-defined quantities
full rationale
The paper introduces AnyHead as a new unified data suite and proposes a novel pipeline (Plücker-aware 3D Gaussian scaffold + one-step conditional denoising + auxiliary view supervision) for single-image reconstruction. No equations, fitted parameters, or self-citations are shown that would reduce the claimed reconstruction quality or speed to quantities defined by the authors' own inputs or prior work. The central claims rest on the empirical performance of this new combination rather than any self-referential derivation or renaming of known results, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D Gaussian splatting can represent full-head geometry and appearance at high fidelity when initialized from a Plücker-aware scaffold
invented entities (2)
-
AnyHead data suite
no independent evidence
-
Plücker-aware structured 3D Gaussian scaffold
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Ümit Y. Ogras, and Linjie Luo. 2023. PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360°. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. IEEE, 20950–20959. doi:10.1109/CVPR52729.2023.02007
-
[2]
2023.A Morphable Model For The Synthesis Of 3D Faces(1 ed.)
Volker Blanz and Thomas Vetter. 2023.A Morphable Model For The Synthesis Of 3D Faces(1 ed.). Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3596711.3596730
-
[3]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, and Robin Rombach. 2023. Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets.CoRRabs/2311.15127 (2023). arXiv:2311.15127 doi:10.48550/ARXIV.2311.15127
work page internal anchor Pith review doi:10.48550/arxiv.2311.15127 2023
-
[4]
In: SIGGRAPH Asia 2024 Conference Papers
Marcel C. Bühler, Gengyan Li, Erroll Wood, Leonhard Helminger, Xu Chen, Tan- may Shah, Daoye Wang, Stephan J. Garbin, Sergio Orts-Escolano, Otmar Hilliges, Dmitry Lagun, Jérémy Riviere, Paulo F. U. Gotardo, Thabo Beeler, Abhimitra Meka, and Kripasindhu Sarkar. 2024. Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures...
-
[5]
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. 2025. Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699(2025)
work page internal anchor Pith review arXiv 2025
-
[6]
Yuanhao Cai, He Zhang, Kai Zhang, Yixun Liang, Mengwei Ren, Fujun Luan, Qing Liu, Soo Ye Kim, Jianming Zhang, Zhifei Zhang, et al. 2025. Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-Stage Image-to- 3D Generation and Reconstruction. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025. 25062–25072
2025
-
[7]
Yuanhao Cai, He Zhang, Kai Zhang, Yixun Liang, Mengwei Ren, Fujun Luan, Qing Liu, Soo Ye Kim, Jianming Zhang, Zhifei Zhang, Yuqian Zhou, Yulun Zhang, Xiaokang Yang, Zhe Lin, and Alan Yuille. 2025. Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation and Reconstruction. InIEEE/CVF International Confere...
2025
-
[8]
Xuangeng Chu and Tatsuya Harada. 2024. Generalizable and Animat- able Gaussian Head Avatar. InAnnual Conference on Neural Informa- tion Processing Systems (NeurIPS), 2024, Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang (Eds.). http://papers.nips.cc/paper_files/paper/2024/hash/ 6a14c7f9fb3f42...
2024
-
[9]
Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, and Tatsuya Harada. 2024. GPAvatar: Generalizable and Precise Head Avatar from Image(s). InInternational Conference on Learning Representations (ICLR), 2024. OpenReview.net. https://openreview.net/forum?id=hgehGq2bDv
2024
-
[10]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. Computer Vision Foundation / IEEE, 4690–4699. doi:10.1109/CVPR.2019.00482
-
[11]
Yao Feng, Haiwen Feng, Michael J Black, and Timo Bolkart. 2021. Learning an animatable detailed 3D face model from in-the-wild images.ACM Transactions on Graphics (ToG)40, 4 (2021), 1–13
2021
-
[12]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. 2023. DreamSim: Learning New Dimen- sions of Human Visual Similarity using Synthetic Data. InAnnual Con- ference on Neural Information Processing Systems (NeurIPS), 2023, Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey ...
2023
-
[13]
Dimitrios Gerogiannis, Foivos Paraperas Papantoniou, Rolandos Alexandros Potamias, Alexandros Lattas, and Stefanos Zafeiriou. 2025. Arc2Avatar: Generat- ing Expressive 3D Avatars from a Single Image via ID Guidance. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Computer Vision Foundation / IEEE, 10770–10782. doi:10.1109/CV...
- [14]
-
[15]
Yuming Gu, Phong Tran, Yujian Zheng, Hongyi Xu, Heyuan Li, Adilbek Kar- manov, and Hao Li. 2025. DiffPortrait360: Consistent Portrait Diffusion for 360 View Synthesis. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Computer Vision Foundation / IEEE, 26263–26273. doi:10.1109/CVPR52734.2025.02446
-
[16]
Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei, and Stan Z. Li
-
[17]
Towards Fast, Accurate and Stable 3D Dense Face Alignment. InEuropean Conference on Computer Vision (ECCV), 2020 (Lecture Notes in Computer Science), Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm (Eds.). Springer, 152–168. doi:10.1007/978-3-030-58529-7_10
-
[18]
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Chengjie Wang, and Lizhuang Ma. 2025. ID-Sculpt: ID-aware 3D Head Generation from Single In-the-wild Portrait Image. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025, Toby Walsh, Julie Shah, and Zico Kolter (Eds.). AAAI Press, 3383...
-
[19]
Yisheng He, Xiaodong Gu, Xiaodan Ye, Chao Xu, Zhengyi Zhao, Yuan Dong, Weihao Yuan, Zilong Dong, and Liefeng Bo. 2025. LAM: Large Avatar Model for One-shot Animatable Gaussian Head. InACM SIGGRAPH Conference (SIG- GRAPH), 2025. 1–13
2025
-
[20]
Xinya Ji, Sebastian Weiss, Manuel Kansy, Jacek Naruniec, Xun Cao, Barbara So- lenthaler, and Derek Bradley. 2026. FastGHA: Generalized Few-Shot 3D Gaussian Head Avatars with Real-Time Animation. InInternational Conference on Learning Representations (ICLR), 2026. https://arxiv.org/abs/2601.13837
-
[21]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
-
[22]
https://doi.org/10.1145/3592433 Xiaonan Kong and Riley G
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Trans. Graph.42, 4 (2023), 139:1–139:14. doi:10.1145/3592433
-
[23]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In International Conference on Learning Representations (ICLR), 2014, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[24]
Tobias Kirschstein, Shenhan Qian, Simon Giebenhain, Tim Walter, and Matthias Nießner. 2023. NeRSemble: Multi-View Radiance Field Reconstruction of Human Heads.ACM Trans. Graph.42, 4, Article 161 (jul 2023), 14 pages. doi:10.1145/ 3592455
2023
-
[25]
Heyuan Li, Ce Chen, Tianhao Shi, Yuda Qiu, Sizhe An, Guanying Chen, and Xiaoguang Han. 2024. SphereHead: Stable 3D Full-Head Synthesis with Spherical Tri-Plane Representation. InEuropean Conference on Computer Vision (ECCV), 2024 (Lecture Notes in Computer Science), Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol...
-
[26]
Peng Li, Yisheng He, Yingdong Hu, Yuan Dong, Weihao Yuan, Yuan Liu, Zilong Dong, and Yike Guo. 2025. PanoLAM: Large Avatar Model for Gaussian Full- Head Synthesis from One-shot Unposed Image.CoRRabs/2509.07552 (2025). arXiv:2509.07552 doi:10.48550/ARXIV.2509.07552
-
[27]
Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. 2017. Learning a model of facial shape and expression from 4D scans.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)36, 6 (2017). https://doi.org/10.1145/3130800. 3130813
-
[28]
Xuanchen Li, Yuhao Cheng, Xingyu Ren, Haozhe Jia, Di Xu, Wenhan Zhu, and Yichao Yan. 2024. Topo4D: Topology-Preserving Gaussian Splatting for High- fidelity 4D Head Capture. InEuropean Conference on Computer Vision (ECCV), 2024 (Lecture Notes in Computer Science), Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol (...
-
[29]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. 2023. Zero-1-to-3: Zero-shot One Image to 3D Object. In Yujie Gao, Yao Xiao, Xiangnan Zhu, Ya Li, Yiyi Zhang, Liqing Zhang, and Jianfu Zhang IEEE/CVF International Conference on Computer Vision (ICCV), 2023. IEEE, 9264–
2023
-
[30]
doi:10.1109/ICCV51070.2023.00853
-
[31]
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. 2024. Wonder3D: Single Image to 3D Using Cross-Domain Diffusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. IEEE, 9970–9980. doi:10.1109/CVPR52733.2024.00951
- [32]
-
[33]
Bagautdinov, Shunsuke Saito, Shoou-I Yu, Stuart Anderson, Michael Zollhöfer, Te-Li Wang, Shaojie Bai, Chenghui Li, Shih-En Wei, Rohan Joshi, Wyatt Borsos, Tomas Simon, Jason M
Julieta Martinez, Emily Kim, Javier Romero, Timur M. Bagautdinov, Shunsuke Saito, Shoou-I Yu, Stuart Anderson, Michael Zollhöfer, Te-Li Wang, Shaojie Bai, Chenghui Li, Shih-En Wei, Rohan Joshi, Wyatt Borsos, Tomas Simon, Jason M. Saragih, Paul Theodosis, Alexander Greene, Anjani Josyula, Silvio Maeta, Andrew Jewett, Simion Venshtain, Christopher Heilman, ...
2024
-
[34]
Dongwei Pan, Long Zhuo, Jingtan Piao, Huiwen Luo, Wei Cheng, Yuxin Wang, Siming Fan, Shengqi Liu, Lei Yang, Bo Dai, Ziwei Liu, Chen Change Loy, Chen Qian, Wayne Wu, Dahua Lin, and Kwan-Yee Lin. 2023. RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars. InAnnual Conference on Neural Information Processing Systems (...
2023
-
[35]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Trans- formers. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023. IEEE, 4172–4182. doi:10.1109/ICCV51070.2023.00387
- [36]
-
[37]
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. 2024. MVDream: Multi-view Diffusion for 3D Generation. InInternational Conference on Learning Representations (ICLR), 2024. OpenReview.net. https://openreview. net/forum?id=FUgrjq2pbB
2024
-
[39]
Qwen Team. 2025. Qwen3-VL Technical Report.CoRRabs/2511.21631 (2025). arXiv:2511.21631 doi:10.48550/ARXIV.2511.21631
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[40]
Vikram Voleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. 2024. SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image Using Latent Video Diffusion. InEuropean Conference on Computer Vision (ECCV), 2024 (Lecture Notes in Computer Science, Vol. 15059), Ales Leo...
-
[41]
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rup- precht, and David Novotný. 2025. VGGT: Visual Geometry Grounded Trans- former. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Computer Vision Foundation / IEEE, 5294–5306. doi:10.1109/ CVPR52734.2025.00499
-
[42]
Peng Wang and Yichun Shi. 2023. ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation.CoRRabs/2312.02201 (2023). arXiv:2312.02201 doi:10.48550/ARXIV.2312.02201
-
[43]
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jérôme Revaud. 2024. DUSt3R: Geometric 3D Vision Made Easy. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. IEEE, 20697–20709. doi:10.1109/CVPR52733.2024.01956
-
[44]
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. 2026. 𝜋3: Scalable Permutation-Equivariant Visual Geometry Learning. InInternational Conference on Learning Representations (ICLR), 2026. https://doi.org/10.48550/arXiv.2507. 13347
-
[45]
Zidu Wang, Xiangyu Zhu, Tianshuo Zhang, Baiqin Wang, and Zhen Lei. 2024. 3D Face Reconstruction with the Geometric Guidance of Facial Part Segmentation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. IEEE, 1672–1682. doi:10.1109/CVPR52733.2024.00165
-
[46]
Kailu Wu, Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan, and Kaisheng Ma. 2024. Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image. InAnnual Conference on Neu- ral Information Processing Systems (NeurIPS), 2024, Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak...
2024
-
[47]
Yue Wu, Xuanhong Chen, Yufan Wu, Wen Li, Yuxi Lu, and Kairui Feng. [n. d.]. FastAvatar: Towards Unified and Fast 3D Avatar Reconstruction with Large Gaussian Reconstruction Transformers. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[48]
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. 2025. Structured 3D Latents for Scalable and Versatile 3D Generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Computer Vision Foundation / IEEE, 21469– 21480. doi:10.1109/CVPR52734.2025.02000
-
[49]
Yuelang Xu, Bengwang Chen, Zhe Li, Hongwen Zhang, Lizhen Wang, Zerong Zheng, and Yebin Liu. 2024. Gaussian Head Avatar: Ultra High-Fidelity Head Avatar via Dynamic Gaussians. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. IEEE, 1931–1941. doi:10.1109/CVPR52733.2024. 00189
-
[50]
Haibo Yang, Yang Chen, Yingwei Pan, Ting Yao, Zhineng Chen, Chong-Wah Ngo, and Tao Mei. 2024. Hi3D: Pursuing High-Resolution Image-to-3D Generation with Video Diffusion Models. InACM International Conference on Multimedia (ACM MM), 2024, Jianfei Cai, Mohan S. Kankanhalli, Balakrishnan Prabhakaran, Susanne Boll, Ramanathan Subramanian, Liang Zheng, Vivek K...
-
[51]
What’s in the image? a deep-dive into the vision of vision language models
Jianing Yang, Alexander Sax, Kevin J. Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. 2025. Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Computer Vision Foundation / IEEE, 21924–21935. doi:10.1109/CVPR52734.2025.02042
-
[52]
R, Chun-Han Yao, Rafal Mantiuk, and Varun Jampani
Fei Yin, Mallikarjun B. R, Chun-Han Yao, Rafal Mantiuk, and Varun Jampani
-
[53]
InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
FaceCraft4D: Animated 3D Facial Avatar Generation from a Single Image. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025. https: //arxiv.org/abs/2504.15179
-
[54]
Bowen Zhang, Yiji Cheng, Chunyu Wang, Ting Zhang, Jiaolong Yang, Yansong Tang, Feng Zhao, Dong Chen, and Baining Guo. 2024. RodinHD: High-Fidelity 3D Avatar Generation with Diffusion Models. InEuropean Conference on Com- puter Vision (ECCV), 2024 (Lecture Notes in Computer Science), Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattl...
- [55]
-
[56]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang
-
[57]
In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018. Computer Vision Foundation / IEEE Computer Society, 586–595. doi:10.1109/ CVPR.2018.00068
-
[58]
Shangchen Zhou, Kelvin C. K. Chan, Chongyi Li, and Chen Change Loy
-
[59]
InAnnual Conference on Neural Information Processing Systems (NeurIPS), 2022, Sanmi Koyejo, S
Towards Robust Blind Face Restoration with Codebook Lookup Transformer. InAnnual Conference on Neural Information Processing Systems (NeurIPS), 2022, Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (Eds.). http://papers.nips.cc/paper_files/paper/2022/hash/ c573258c38d0a3919d8c1364053c45df-Abstract-Conference.html
2022
-
[60]
Hao Zhu, Haotian Yang, Longwei Guo, Yidi Zhang, Yanru Wang, Mingkai Huang, Menghua Wu, Qiu Shen, Ruigang Yang, and Xun Cao. 2023. FaceScape: 3D Facial Dataset and Benchmark for Single-View 3D Face Reconstruction.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)(2023)
2023
-
[61]
Wojciech Zielonka, Timo Bolkart, and Justus Thies. 2022. Towards Metrical Reconstruction of Human Faces. InEuropean Conference on Computer Vision (ECCV), 2022 (Lecture Notes in Computer Science), Shai Avidan, Gabriel J. Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner (Eds.). Springer, 250–269. doi:10.1007/978-3-031-19778-9_15 Any3DAvat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.