Recognition: unknown
Mamba Sequence Modeling meets Model Predictive Control
Pith reviewed 2026-05-10 12:28 UTC · model grok-4.3
The pith
Mamba neural networks can serve as accurate multi-step predictors for model predictive control, enabling stable reference tracking in SISO and MIMO systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adjusting the Mamba network to a decoder-only form and deriving an input-output formulation for dynamical systems, Mamba-MPC delivers multi-step predictions of unknown dynamics that suffice for stabilizing and tracking references in both simulated SISO and MIMO plants and on real hardware, with consistent advantages over LSTM-MPC in accuracy and speed.
What carries the argument
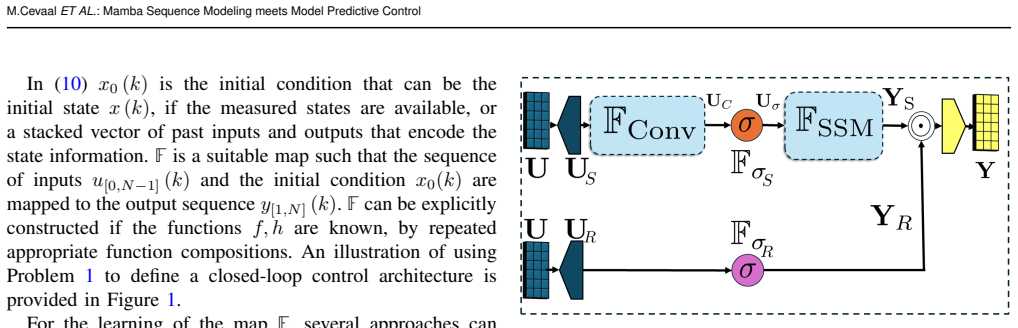
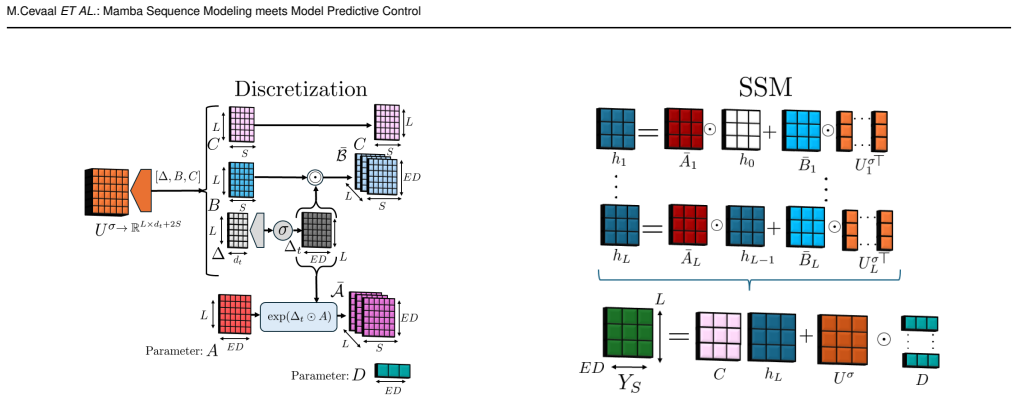
The decoder-only Mamba multi-step predictor, which models sequence-to-sequence dynamics of the system to replace the traditional model in the MPC optimization.
Load-bearing premise
The trained Mamba predictor must generate sufficiently accurate forecasts of future states or outputs so that the MPC optimization produces a stabilizing feedback law.
What would settle it
Running the physical experiment on the Quanser Aero2 where the closed-loop system with Mamba-MPC becomes unstable or fails to track the reference while the LSTM version succeeds would disprove the claim.
Figures








read the original abstract
In this paper, we consider the design of Model Predictive Control (MPC) algorithms based on Mamba neural networks. Mamba is a neural network architecture capable of sub-quadratic computational scaling in sequence length with state-of-the-art modeling capabilities. We provide a consistent and complete mathematical description of the Mamba neural network is provided. Then, adjustments and optimizations are made to construct a decoder-only Mamba multi-step predictor for MPC and an input-output formulation is given for sequence-to-sequence modeling of dynamical systems. The performance of Mamba-MPC is evaluated on several numerical examples and compared to a Long-Short-Term-Memory based MPC (LSTM-MPC) equivalent. First, a Single-Input-Single-Output (SISO) Van der Pol oscillator is considered, where stability, reference tracking, and noise robustness are evaluated. Then, a MIMO Four Tank setup is introduced where Multiple-Input-Multiple-Output (MIMO) reference tracking is evaluated. Lastly, Mamba-MPC is implemented on a physical Quanser Aero2 setup for closed-loop reference tracking. The results demonstrate that Mamba-MPC is able to stabilize and track a reference for SISO and MIMO systems, both in simulation and on a physical setup. Moreover, Mamba-MPC consistently outperforms LSTM-MPC in predictive control and is significantly computationally faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mamba-based Model Predictive Control by giving a mathematical description of the Mamba architecture, adapting it into a decoder-only form for multi-step ahead prediction of unknown dynamics via an input-output sequence-to-sequence model, and testing the resulting Mamba-MPC controller on a SISO Van der Pol oscillator (stability, tracking, noise robustness), a MIMO four-tank system (reference tracking), and a physical Quanser Aero2 setup (closed-loop tracking). It claims that Mamba-MPC achieves the desired closed-loop behavior, consistently outperforms an equivalent LSTM-MPC baseline, and runs significantly faster.
Significance. If the empirical results can be supported by quantitative open-loop prediction metrics and reproducibility details, the work would be significant for introducing an efficient sequence-modeling alternative to LSTM in data-driven MPC, exploiting Mamba's sub-quadratic scaling for potentially longer horizons or real-time hardware use. The hardware experiment is a positive practical element.
major comments (2)
- [Abstract and Evaluation sections] Abstract and Evaluation sections: the claims of stabilization, reference tracking, and outperformance versus LSTM-MPC rest entirely on closed-loop experiments, yet no open-loop multi-step prediction metrics (horizon-dependent MSE or similar on held-out trajectories) are reported for the trained Mamba model. Without these numbers the observed closed-loop success cannot be confidently attributed to superior dynamics modeling rather than cost tuning or plant simplicity.
- [Numerical examples] Numerical examples (Van der Pol, Four Tank, Quanser Aero2): no training details, dataset generation procedure, hyperparameter values, or ablation studies are supplied for the Mamba or LSTM models. This prevents assessment of whether the reported superiority and speed advantage arise from the architecture itself.
minor comments (1)
- [Abstract] Abstract contains a grammatical error: 'We provide a consistent and complete mathematical description of the Mamba neural network is provided.'
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We appreciate the positive note on the hardware experiment and the potential significance of the work. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and Evaluation sections] Abstract and Evaluation sections: the claims of stabilization, reference tracking, and outperformance versus LSTM-MPC rest entirely on closed-loop experiments, yet no open-loop multi-step prediction metrics (horizon-dependent MSE or similar on held-out trajectories) are reported for the trained Mamba model. Without these numbers the observed closed-loop success cannot be confidently attributed to superior dynamics modeling rather than cost tuning or plant simplicity.
Authors: We agree that open-loop multi-step prediction metrics would strengthen the attribution of closed-loop performance to the quality of the learned model. The manuscript currently emphasizes closed-loop results because that is the ultimate objective of MPC, but we recognize the value of isolating modeling accuracy. In the revised version we will add a dedicated subsection reporting horizon-dependent MSE (and similar metrics) on held-out trajectories for both Mamba and LSTM predictors. These results will be presented alongside the existing closed-loop experiments to allow readers to assess whether performance differences arise from superior dynamics modeling. revision: yes
-
Referee: [Numerical examples] Numerical examples (Van der Pol, Four Tank, Quanser Aero2): no training details, dataset generation procedure, hyperparameter values, or ablation studies are supplied for the Mamba or LSTM models. This prevents assessment of whether the reported superiority and speed advantage arise from the architecture itself.
Authors: We acknowledge the omission of these details in the original submission. The revised manuscript will include a new section (or expanded appendix) that provides: (i) the exact dataset generation procedure for each example, including excitation signals, number and length of trajectories, and train/validation/test splits; (ii) all hyperparameter values and architectural choices for both the Mamba and LSTM models; (iii) training settings (optimizer, learning rate schedule, epochs, loss, hardware); and (iv) ablation studies on key Mamba parameters (e.g., state dimension, number of layers) and their effect on prediction accuracy and inference speed. We will also release code and datasets to support reproducibility. These additions will make clear that the observed advantages are due to Mamba's architecture and scaling properties. revision: yes
Circularity Check
No circularity: empirical performance claims rest on direct experiments, not self-referential derivations
full rationale
The paper supplies a mathematical description of the Mamba architecture, decoder-only adjustments, and an input-output sequence-to-sequence formulation for dynamical systems, then reports closed-loop results on Van der Pol, Four Tank, and Quanser Aero2 plants. These results are obtained by training the network and running MPC experiments; no equation or claim reduces by construction to a fitted parameter, self-citation, or ansatz imported from the authors' prior work. The central assertions (stabilization, reference tracking, outperformance of LSTM-MPC) are falsifiable empirical statements rather than tautological predictions. This matches the default expectation that most papers contain no circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- Mamba network weights
axioms (1)
- domain assumption Mamba architecture can be modified into a decoder-only multi-step predictor while retaining its computational scaling advantages for dynamical system modeling.
Reference graph
Works this paper leans on
-
[1]
Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its applica- tion to dynamical systems,
T. Chen and H. Chen, “Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its applica- tion to dynamical systems,”IEEE Transactions on Neural Networks, vol. 6, pp. 911–917, 1995
1995
-
[2]
A neural predictive controller for non- linear systems,
M. Lazar and O. Pastravanu, “A neural predictive controller for non- linear systems,”Mathematics and Computers in Simulation, vol. 60, pp. 315–324, 2002
2002
-
[3]
Model predictive control for nonlinear affine systems based on the simplified dual neural network,
Y . Pan and J. Wang, “Model predictive control for nonlinear affine systems based on the simplified dual neural network,” inIEEE Con- ference on Control Applications (CCA) & Intelligent Control (ISIC), 2009, pp. 683–688
2009
-
[4]
Computationally efficient predictive control based on ANN state-space models,
J. H. Hoekstra, B. Cseppento, G. I. Beintema, M. Schoukens, Z. Kollr, and R. Tth, “Computationally efficient predictive control based on ANN state-space models,” inProceedings of the IEEE Conference on Decision and Control. Institute of Electrical and Electronics Engineers Inc., 2023, pp. 6336–6341
2023
-
[5]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, pp. 1735–1780, nov 1997
1997
-
[6]
Multistep Prediction of Dynamic Systems With Recurrent Neural Networks,
N. Mohajerin and S. L. Waslander, “Multistep Prediction of Dynamic Systems With Recurrent Neural Networks,” vol. 30, no. 11, pp. 3370–3383. [Online]. Available: https://ieeexplore.ieee.org/document/ 8630673/
-
[7]
Learning Phrase Representations using RNN EncoderDecoder for Statistical Machine Translation,
K. Cho, B. Van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning Phrase Representations using RNN EncoderDecoder for Statistical Machine Translation,” inProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, pp. 1724–1734. [Online]. ...
2014
-
[8]
Nonlinear MPC for offset-free tracking of systems learned by GRU neural networks,
F. Bonassi, C. F. O. da Silva, and R. Scattolini, “Nonlinear MPC for offset-free tracking of systems learned by GRU neural networks,” 2021
2021
-
[9]
Attention is All you Need
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, . Kaiser, and I. Polosukhin, “Attention is All you Need.”
-
[10]
Simultaneous multistep Transformer architecture for model predictive control,
J. Park, M. R. Babaei, S. A. Munoz, A. N. Venkat, and J. D. Heden- gren, “Simultaneous multistep Transformer architecture for model predictive control,”Computers and Chemical Engineering, vol. 178, oct 2023
2023
-
[11]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752, dec 2023. [Online]. Available: http://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Efficiently Modeling Long Sequences with Structured State Spaces
A. Gu, K. Goel, and C. R, “Efficiently modeling long sequences with structured state spaces,” arXiv preprint arXiv:2111.00396, oct 2021. [Online]. Available: http://arxiv.org/abs/2111.00396
work page internal anchor Pith review arXiv 2021
-
[13]
Canrecurrentneuralnetworkswarptime? arXiv:1804.11188,
C. Tallec and Y . Ollivier, “Can recurrent neural networks warp time?” arXiv preprint arXiv:1804.11188, mar 2018. [Online]. Available: http://arxiv.org/abs/1804.11188
-
[14]
DeepONet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators,
L. Lu, P. Jin, and G. E. Karniadakis, “DeepONet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators,”Nature Machine Intelligence, vol. 3, pp. 218–229, mar 2021. 12 VOLUME
2021
-
[15]
Z. Hu, N. A. Daryakenari, Q. Shen, K. Kawaguchi, and G. E. Karniadakis. State-Space Models are Accurate and Efficient Neural Operators for Dynamical Systems. [Online]. Available: https: //www.ssrn.com/abstract=4990229
-
[16]
MamKO: Mamba-based koopman operator for modeling and predictive control,
Z. Li, M. Han, and X. Yin, “MamKO: Mamba-based koopman operator for modeling and predictive control,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=hNjCVVm0EQ
2025
-
[17]
Deep Operator Neural Network Model Predictive Control,
T. O. De Jong, K. Shukla, and M. Lazar, “Deep Operator Neural Network Model Predictive Control,” vol. 4, pp. 501–517. [Online]. Available: https://ieeexplore.ieee.org/document/11181185/
-
[18]
GLU Variants Improve Transformer
N. Shazeer, “GLU variants improve Transformer,” arXiv preprint arXiv:2002.05202, feb 2020. [Online]. Available: http://arxiv.org/abs/ 2002.05202
work page internal anchor Pith review arXiv 2002
-
[20]
[Online]. Available: http://arxiv.org/abs/1901.08428
-
[21]
Beyond BatchNorm: Towards a unified understanding of normalization in deep learning,
E. S. Lubana, R. P. Dick, and H. Tanaka, “Beyond BatchNorm: Towards a unified understanding of normalization in deep learning,” arXiv preprint arXiv:2106.05956, oct 2021. [Online]. Available: http://arxiv.org/abs/2106.05956
-
[22]
Root Mean Square Layer Normalization
B. Zhang and R. Sennrich, “Root Mean Square Layer Normalization.” [Online]. Available: https://www.zora.uzh.ch/id/eprint/177483
-
[23]
LSTM and GRU type recurrent neural networks in model predictive control: A review,
M. awryczuk and K. Zarzycki, “LSTM and GRU type recurrent neural networks in model predictive control: A review,”Neurocomputing, vol. 632, jun 2025
2025
-
[24]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization.” [Online]. Available: http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear program- ming,
A. Wchter and L. T. Biegler, “On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear program- ming,”Mathematical Programming, vol. 106, pp. 25–57, may 2006
2006
-
[26]
Four MPC implementations compared on the Quadruple Tank Process benchmark: pros and cons of neural MPC,
P. C. Blaud, P. Chevrel, F. Claveau, P. Haurant, and A. Mouraud, “Four MPC implementations compared on the Quadruple Tank Process benchmark: pros and cons of neural MPC,” inIFAC-PapersOnLine, vol. 55. Elsevier B.V ., jul 2022, pp. 344–349. Michiel Cevaalreceived the B.S. degree in Elec- trical Engineering from Eindhoven University of Technology, Eindhoven...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.