Recognition: unknown
Do We Still Need Humans in the Loop? Comparing Human and LLM Annotation in Active Learning for Hostility Detection
Pith reviewed 2026-05-10 13:33 UTC · model grok-4.3
The pith
LLM-generated labels train hostility detectors to the same F1-Macro level as human labels but at far lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
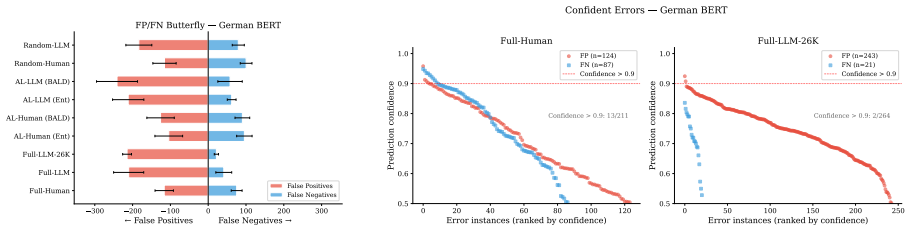
The central claim is that LLM labels can replace human labels inside the active learning loop for hostility detection without loss of aggregate performance and at substantially reduced cost. In the reported experiments, full LLM annotation outperforms both human-only and hybrid active learning strategies on the same budget. The work further shows that this performance parity does not extend to error structure: LLM-trained models systematically over-predict hostility in cases where the boundary between anti-immigrant hostility and legitimate policy discussion is subtle.
What carries the argument
The side-by-side comparison of seven annotation strategies (human, LLM, and active learning variants) on a fixed pre-enriched pool of TikTok comments, evaluated by both aggregate F1-Macro and per-class error profiles.
If this is right
- Full LLM labeling of large corpora becomes feasible at costs low enough to replace selective human annotation for many classification tasks.
- Annotation strategy should be chosen according to the error profile required by the downstream application rather than aggregate F1 alone.
- Active learning offers diminishing returns once the initial pool has already been enriched for the target class.
- Hybrid human-LLM pipelines may still be needed when the distinction between classes is subtle and context-dependent.
Where Pith is reading between the lines
- The observed cost advantage could make continuous monitoring of hostility feasible across many more languages and platforms than human-only annotation allows.
- Similar divergences in error structure are likely to appear in other subjective labeling tasks such as misinformation or sentiment detection.
- Developers should test LLM-trained models on domain-specific ambiguous examples before deployment rather than relying on overall accuracy figures.
Load-bearing premise
The 5,000 human-annotated comments function as an unbiased gold standard and the pre-enriched comment pool does not artificially restrict the possible gains from active learning.
What would settle it
A follow-up experiment on a fresh, non-enriched corpus of comments or a different platform in which classifiers trained on LLM labels fall significantly below the F1-Macro of human-trained classifiers, or in which the over-prediction of the positive class disappears.
Figures









read the original abstract
Instruction-tuned LLMs can annotate thousands of instances from a short prompt at negligible cost. This raises two questions for active learning (AL): can LLM labels replace human labels within the AL loop, and does AL remain necessary when entire corpora can be labelled at once? We investigate both questions on a new dataset of 277,902 German political TikTok comments (25,974 LLM-labelled, 5,000 human-annotated), comparing seven annotation strategies across four encoders to detect anti-immigrant hostility. A classifier trained on 25,974 GPT-5.2 labels (\$43) achieves comparable F1-Macro to one trained on 3,800 human annotations (\$316). Active learning offers little advantage over random sampling in our pre-enriched pool and delivers lower F1 than full LLM annotation at the same cost. However, comparable aggregate F1 masks a systematic difference in error structure: LLM-trained classifiers over-predict the positive class relative to the human gold standard. This divergence concentrates in topically ambiguous discussions where the distinction between anti-immigrant hostility and policy critique is most subtle, suggesting that annotation strategy should be guided not by aggregate F1 alone but by the error profile acceptable for the target application.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-based annotation (specifically 25,974 GPT-5.2 labels at $43) can produce classifiers with F1-Macro comparable to those trained on 3,800 human annotations ($316) for anti-immigrant hostility detection in a corpus of 277,902 German TikTok comments. It further finds that active learning provides little benefit over random sampling within the pre-enriched pool and that full LLM annotation outperforms AL at equivalent cost, while noting systematic differences in error profiles where LLM models over-predict the positive class, particularly in topically ambiguous cases.
Significance. If the central empirical comparisons hold, the work has clear practical significance for scaling annotation in applied NLP tasks by quantifying cost savings and emphasizing error-profile analysis over aggregate metrics alone. It contributes concrete evidence to the human-in-the-loop debate through multi-encoder comparisons and qualitative discussion of ambiguity, with strengths in the scale of the dataset and the direct cost-F1 trade-off analysis.
major comments (2)
- [Dataset] Dataset section: The 5,000 human-annotated instances are used as the gold standard for all F1-Macro evaluations of LLM-trained classifiers. The manuscript does not specify the sampling procedure (random, uncertainty-based, or stratified) used to select these 5,000 from the pre-enriched pool of 277,902 comments. This detail is load-bearing for the comparability claim, because any over-representation of borderline or positive cases would directly affect measured F1 and could explain the reported LLM over-prediction of the positive class in ambiguous discussions.
- [Methods] Methods and Experimental Protocol: The abstract and results lack the exact prompt template used for GPT-5.2, inter-annotator agreement statistics for the human labels, and the full specification of the seven annotation strategies (including how active learning uncertainty was operationalized). These omissions undermine assessment of whether the $43 vs. $316 cost comparison is reproducible and whether the 'comparable F1' result is robust to prompt variation or label noise.
minor comments (1)
- [Abstract] Abstract: The claim of 'comparable F1-Macro' would be more informative if the actual F1 values, standard deviations, and any statistical test results were reported directly in the abstract rather than left to the full text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the clarity and reproducibility of the work. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Dataset] Dataset section: The 5,000 human-annotated instances are used as the gold standard for all F1-Macro evaluations of LLM-trained classifiers. The manuscript does not specify the sampling procedure (random, uncertainty-based, or stratified) used to select these 5,000 from the pre-enriched pool of 277,902 comments. This detail is load-bearing for the comparability claim, because any over-representation of borderline or positive cases would directly affect measured F1 and could explain the reported LLM over-prediction of the positive class in ambiguous discussions.
Authors: We agree that the sampling procedure for the 5,000-instance gold standard must be stated explicitly, as it bears on the validity of the F1 comparisons and error analysis. This information was omitted from the submitted manuscript. We will revise the Dataset section to describe the procedure used (a stratified random sample drawn from the pre-enriched pool to balance topical coverage while preserving the overall class distribution). This addition directly addresses the concern about potential bias in the evaluation set and the observed differences in positive-class predictions. revision: yes
-
Referee: [Methods] Methods and Experimental Protocol: The abstract and results lack the exact prompt template used for GPT-5.2, inter-annotator agreement statistics for the human labels, and the full specification of the seven annotation strategies (including how active learning uncertainty was operationalized). These omissions undermine assessment of whether the $43 vs. $316 cost comparison is reproducible and whether the 'comparable F1' result is robust to prompt variation or label noise.
Authors: We acknowledge that full reproducibility requires the prompt template, IAA statistics, and precise operationalization of each annotation strategy. These elements were not included in the submitted version. In the revision we will (1) place the complete GPT-5.2 prompt template in an appendix, (2) report inter-annotator agreement for the human annotations in the Methods section, and (3) expand the description of all seven strategies, including the exact uncertainty measure (entropy over the positive-class probability) used for active learning. These changes will allow readers to evaluate both the cost-F1 trade-offs and robustness to prompt or label variation. revision: yes
Circularity Check
No circularity: purely empirical comparisons without derivations or self-referential logic
full rationale
The paper conducts an empirical study comparing human and LLM annotation strategies for training hostility classifiers on a fixed dataset of TikTok comments. All claims rest on direct experimental results (F1-Macro scores from classifiers trained on varying label sets), with no equations, fitted parameters, uniqueness theorems, or ansatzes. The central result—that 25,974 GPT-5.2 labels yield comparable aggregate F1 to 3,800 human labels—is a straightforward performance comparison against the human-annotated subset, not a reduction to its own inputs by construction. No self-citations are load-bearing for the methodology or conclusions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human annotations represent the ground truth for model evaluation
- domain assumption The pre-enriched pool is representative for testing AL effectiveness
Reference graph
Works this paper leans on
-
[1]
InProceedings of The 18th Linguistic Annotation Workshop (LAW-XVIII), pages 77–86
Class balancing for efficient active learning in imbalanced datasets. InProceedings of The 18th Linguistic Annotation Workshop (LAW-XVIII), pages 77–86. Jan Fillies, Esther Theisen, Michael Hoffmann, Robert Jung, Elena Jung, Nele Fischer, and Adrian Paschke
-
[2]
Paula Fortuna and Sérgio Nunes
A novel german tiktok hate speech dataset: far-right comments against politicians, women, and others.Discover Data, 3(1):4. Paula Fortuna and Sérgio Nunes. 2018. A survey on automatic detection of hate speech in text.ACM Comput. Surv., 51(4):85:1–85:30. Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncertai...
2018
-
[3]
Chatgpt outperforms crowd-workers for text-annotation tasks
Chatgpt outperforms crowd-workers for text- annotation tasks.CoRR, abs/2303.15056. Maarten Grootendorst. 2022. Bertopic: Neural topic modeling with a class-based TF-IDF procedure. CoRR, abs/2203.05794. Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, and Weizhu Chen. 2024. Annollm: Making large lan...
-
[4]
Bayesian active learning for classification and preferenc e learning,
Large language models as a substitute for human experts in annotating political text.Research & Politics, 11(1):20531680241236239. Neil Houlsby, Ferenc Huszar, Zoubin Ghahramani, and Máté Lengyel. 2011. Bayesian active learning for classification and preference learning.CoRR, abs/1112.5745. Amir Hossein Kargaran, Ayyoob Imani, François Yvon, and Hinrich S...
-
[5]
InMachine Learning and Knowledge Discovery in Databases
Llms in the loop: Leveraging large language model annotations for active learning in low-resource languages. InMachine Learning and Knowledge Discovery in Databases. Applied Data Science Track - European Conference, ECML PKDD 2024, Vilnius, Lithuania, September 9-13, 2024, Proceedings, Part X, Lecture Notes in Computer Science, pages 397–
2024
-
[6]
Aida Kostikova, Dominik Beese, Benjamin Paassen, Ole Pütz, Gregor Wiedemann, and Steffen Eger
Springer. Aida Kostikova, Dominik Beese, Benjamin Paassen, Ole Pütz, Gregor Wiedemann, and Steffen Eger. 2024. Fine-grained detection of solidarity for women and migrants in 155 years of german parliamentary de- bates. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024...
2024
-
[7]
Association for Computational Linguistics. Jingwei Ni, Yu Fan, Vilém Zouhar, Donya Rooein, Alexander Miserlis Hoyle, Mrinmaya Sachan, Markus Leippold, Dirk Hovy, and Elliott Ash. 2025. Can large language models capture human annotator disagreements?CoRR, abs/2506.19467. Nicholas Pangakis, Samuel Wolken, and Neil Fasching
-
[8]
Automated annotation with generative AI re- quires validation.CoRR, abs/2306.00176. Barbara Plank. 2022. The "problem" of human label variation: On ground truth in data, modeling and eval- uation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, De- cember 7-11, 2022, pa...
-
[9]
Measuring the reliability of hate speech an- notations: The case of the european refugee crisis. CoRR, abs/1701.08118. Paul Röttger, Bertie Vidgen, Dirk Hovy, and Janet B. Pierrehumbert. 2022. Two contrasting data annota- tion paradigms for subjective NLP tasks. InProceed- ings of the 2022 Conference of the North American Chapter of the Association for Co...
-
[10]
wann kommen die Grenzkontrollen?
wir vergessen nicht” (‘Merkel 2015. . . we don’t forget’). The remainder (6/18) demand bor- der controls without referencing any group: “wann kommen die Grenzkontrollen?” (‘When are the bor- der controls coming?’), “Diese Grenze war vorher auch geschützt” (‘This border was protected before too’). In all 18 cases, the negativity targets political actors or...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.