Recognition: unknown
Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
Pith reviewed 2026-05-10 12:38 UTC · model grok-4.3
The pith
Cross-domain memory improves coding agent performance by 3.7% by sharing high-level meta-knowledge instead of specific code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
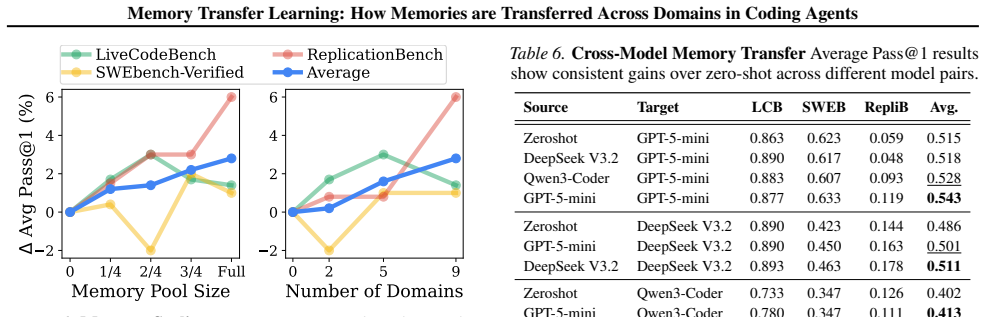
Agents that draw on a single shared memory pool collected from multiple coding domains improve their performance on each individual domain. The improvement comes from transferring abstract meta-knowledge such as validation routines, while low-level execution traces frequently cause negative transfer because they are too tied to their original task.
What carries the argument
Memory Transfer Learning (MTL) using a unified memory pool across heterogeneous domains and four graded memory representations that vary in abstraction level.
If this is right
- Gains grow larger when the shared memory pool is expanded.
- Memories collected by one model can still help a different model.
- Memory design should favor high-level abstractions over raw traces to avoid negative transfer.
- Single-domain memory systems leave performance on the table by ignoring cross-domain commonalities.
Where Pith is reading between the lines
- The same abstraction-transfer pattern may appear in other agent domains such as scientific code or automated theorem proving where meta-strategies recur.
- Agents could be trained to convert their own experiences into abstract form before storing them, increasing future transfer value.
- Memory-pool scaling suggests that very large multi-domain collections could produce larger gains than the modest average reported here.
Load-bearing premise
The six chosen benchmarks cover enough variety of real coding problems and the four memory formats represent the range from concrete to abstract without selection bias in the observed transfer effects.
What would settle it
Repeating the full set of transfer experiments on a new coding benchmark whose problem type is absent from the original six would show whether the 3.7% gain and the advantage of abstract over concrete memories still hold.
Figures











read the original abstract
Memory-based self-evolution has emerged as a promising paradigm for coding agents. However, existing approaches typically restrict memory utilization to homogeneous task domains, failing to leverage the shared infrastructural foundations, such as runtime environments and programming languages, that exist across diverse real-world coding problems. To address this limitation, we investigate \textbf{Memory Transfer Learning} (MTL) by harnessing a unified memory pool from heterogeneous domains. We evaluate performance across 6 coding benchmarks using four memory representations, ranging from concrete traces to abstract insights. Our experiments demonstrate that cross-domain memory improves average performance by 3.7\%, primarily by transferring meta-knowledge, such as validation routines, rather than task-specific code. Importantly, we find that abstraction dictates transferability; high-level insights generalize well, whereas low-level traces often induce negative transfer due to excessive specificity. Furthermore, we show that transfer effectiveness scales with the size of the memory pool, and memory can be transferred even between different models. Our work establishes empirical design principles for expanding memory utilization beyond single-domain silos. Project page: https://memorytransfer.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Memory Transfer Learning (MTL) for coding agents, in which a unified memory pool drawn from heterogeneous domains is used to improve performance over single-domain baselines. Experiments across 6 coding benchmarks and 4 memory representations (spanning concrete traces to abstract insights) report a 3.7% average gain, attributed mainly to transfer of meta-knowledge such as validation routines; high-level abstractions transfer positively while low-level traces often produce negative transfer. The work also reports that transfer effectiveness scales with memory-pool size and that memories can be transferred across different models, yielding empirical design principles for cross-domain memory use.
Significance. If the central empirical findings hold after addressing controls, the paper supplies concrete evidence that abstraction level governs cross-domain memory transfer in coding agents and that meta-knowledge generalizes more readily than task-specific traces. This could inform the design of more scalable, less domain-siloed memory systems for LLM-based agents and provides a reproducible benchmark suite for future memory-transfer studies.
major comments (2)
- [§4 (main experimental results)] §4 (main experimental results): The 3.7% average improvement is attributed to cross-domain meta-knowledge transfer enabled by abstraction, yet the unified heterogeneous pool necessarily increases total memory volume and candidate diversity relative to single-domain baselines. The manuscript itself states that transfer effectiveness scales with pool size, but no control experiment matches pool size, example count, and retrieval budget across conditions; without it the observed benefit cannot be unambiguously ascribed to domain heterogeneity or the concrete-to-abstract spectrum rather than simply having more retrieval candidates.
- [§5 (analysis of transferred content)] §5 (analysis of transferred content): The claim that gains arise 'primarily by transferring meta-knowledge, such as validation routines, rather than task-specific code' is central to the interpretation of why abstraction helps, yet the manuscript provides no quantitative breakdown (e.g., fraction of retrieved memories classified as meta vs. task-specific, or ablation removing meta-memories) that would support the 'primarily' qualifier.
minor comments (3)
- [Methods] The four memory representations are described only at a high level; a concise table listing their exact formats, token budgets, and retrieval mechanisms would improve reproducibility.
- [Results] Statistical significance of the 3.7% average gain and of per-benchmark differences is not reported; adding p-values or confidence intervals would strengthen the results section.
- [Abstract / Conclusion] The project page URL is given but the manuscript does not indicate whether code, prompts, and raw logs are released there; explicit data-availability statement is needed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of experimental controls and quantitative support for our claims. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: §4 (main experimental results): The 3.7% average improvement is attributed to cross-domain meta-knowledge transfer enabled by abstraction, yet the unified heterogeneous pool necessarily increases total memory volume and candidate diversity relative to single-domain baselines. The manuscript itself states that transfer effectiveness scales with pool size, but no control experiment matches pool size, example count, and retrieval budget across conditions; without it the observed benefit cannot be unambiguously ascribed to domain heterogeneity or the concrete-to-abstract spectrum rather than simply having more retrieval candidates.
Authors: We agree that matching pool size, example count, and retrieval budget is essential to isolate the contribution of domain heterogeneity from mere increases in memory volume. The revised manuscript will include a new control experiment in which single-domain baselines are augmented with additional in-domain memories (drawn from the same source distributions) to equalize total pool size and retrieval budget with the heterogeneous condition. This will allow direct comparison and clarify whether the observed gains stem from cross-domain transfer or pool scale. revision: yes
-
Referee: §5 (analysis of transferred content): The claim that gains arise 'primarily by transferring meta-knowledge, such as validation routines, rather than task-specific code' is central to the interpretation of why abstraction helps, yet the manuscript provides no quantitative breakdown (e.g., fraction of retrieved memories classified as meta vs. task-specific, or ablation removing meta-memories) that would support the 'primarily' qualifier.
Authors: We acknowledge that the current version lacks the requested quantitative breakdown and ablation to substantiate the 'primarily' qualifier. In the revision, we will expand §5 with an automated classification of retrieved memories into meta-knowledge categories (e.g., validation routines, error-handling patterns, abstraction principles) versus task-specific code, reporting the proportions of each type across the six benchmarks. We will also add an ablation study that removes meta-memories from the pool and measures the resulting change in performance gains to quantify their contribution. revision: yes
Circularity Check
No circularity: purely empirical study with direct benchmark measurements
full rationale
The paper reports experimental results from running coding agents on six benchmarks with four memory representations. Performance deltas (e.g., the 3.7% average improvement) are obtained by direct execution and comparison rather than any derivation, fitted parameter, or self-referential definition. No equations, uniqueness theorems, or ansatzes appear; claims about abstraction and meta-knowledge transfer rest on observed outcomes, not on a chain that reduces to its own inputs. Self-citations, if present, are not load-bearing for any derivation. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coding tasks across domains share infrastructural foundations such as runtime environments and programming languages that enable memory transfer.
Reference graph
Works this paper leans on
-
[1]
A survey on in-context learning
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.64. URL https:// aclanthology.org/2024.emnlp-main.64/. Fang, J., Peng, Y ., Zhang, X., Wang, Y ., Yi, X., Zhang, G., Xu, Y ., Wu, B., Liu, S., Li, Z., et al. A comprehensive sur- vey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems...
-
[2]
Universal language model fine-tuning for text classification
PMLR, 2019. Howard, J. and Ruder, S. Universal language model fine-tuning for text classification.arXiv preprint arXiv:1801.06146, 2018. Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024. 10 Memory Transfer Learning: How Memories are Tr...
-
[3]
URL https://openreview.net/forum? id=VTF8yNQM66. Kim, K., Park, G., Lee, Y ., Yeo, W., and Hwang, S. J. Videoicl: Confidence-based iterative in-context learning for out-of-distribution video understanding. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pp. 3295–3305, 2025. Kim, K., Yang, Y ., Kim, S., Yeo, W., Lee, Y ., Ren, M....
-
[4]
- Context: Used when memories reinforced the pattern of making small changes and checking them immediately (e.g., ”edit-test-repeat” loop)
Iterative Workflow Discipline - Definition: Guiding the agent to follow a structured, step-by-step development process (e.g., inspect edit run verify) rather than attempting risky one-shot solutions. - Context: Used when memories reinforced the pattern of making small changes and checking them immediately (e.g., ”edit-test-repeat” loop)
-
[5]
Algorithmic Strategy Transfer - Definition: Providing specific algorithmic approaches or data structures suitable for the problem class. - Context: Used when the agent recalled mathematical formulas, dynamic programming approaches, combinatorial logic, or specific heuristics (e.g., ”O(n) single-pass,” ”backtracking with pruning”)
-
[6]
- Context: Used when memories prompted the agent to write repro.py, use assert, or create local checks to validate logic before submission
Test Driven Verification - Definition: Encouraging the creation of reproduction scripts, smoke tests, or minimal harnesses when official tests are missing or too heavy. - Context: Used when memories prompted the agent to write repro.py, use assert, or create local checks to validate logic before submission
-
[7]
- Context: Used when dealing with missing packages, compilation flags, bash vs sh differences, or cross-compilation toolchains
Environmental Adaptation - Definition: Helping the agent navigate specific system constraints, build tools, or OS-level idiosyncrasies. - Context: Used when dealing with missing packages, compilation flags, bash vs sh differences, or cross-compilation toolchains
-
[8]
- Context: Used when the agent explicitly avoided actions that caused failures in retrieved memories (e.g., ”avoid blind text patching,” ”do not guess outputs”)
Anti-Pattern Avoidance - Definition: Acting as a cautionary guardrail against known failure modes or brittle approaches. - Context: Used when the agent explicitly avoided actions that caused failures in retrieved memories (e.g., ”avoid blind text patching,” ”do not guess outputs”)
-
[9]
- Context: Used when memories guided the agent to handle empty inputs, normalize heterogeneous data types, or enforce strict input sanitization
Input Validation and Robustness - Definition: Ensuring the solution correctly handles edge cases, data normalization, and defensive parsing. - Context: Used when memories guided the agent to handle empty inputs, normalize heterogeneous data types, or enforce strict input sanitization
-
[10]
- Context: Used when the agent needed to preserve legacy behavior, match specific output schemas (JSON/Y AML), or integrate correctly with a framework like Django or React
API and Interface Compliance - Definition: Ensuring the code adheres to existing function signatures, class structures, or external library contracts. - Context: Used when the agent needed to preserve legacy behavior, match specific output schemas (JSON/Y AML), or integrate correctly with a framework like Django or React
-
[11]
- Context: Used when memories reinforced using specific completion tokens (e.g., ”COMPLETETASK...”), single-command constraints, or specific output formats
Interaction Protocol Adherence - Definition: Ensuring the agent complies with the specific formatting and submission rules of the benchmark environment. - Context: Used when memories reinforced using specific completion tokens (e.g., ”COMPLETETASK...”), single-command constraints, or specific output formats
-
[12]
- Context: Used when the agent utilized robust heredoc patterns, correct quoting to avoid shell interpolation, or atomic file writes
File and Syntax Management - Definition: Providing safe techniques for file manipulation and code injection to prevent syntax errors during generation. - Context: Used when the agent utilized robust heredoc patterns, correct quoting to avoid shell interpolation, or atomic file writes
-
[13]
goal": "Describe when this workflow can be applied
Repository Exploration Tactics - Definition: Guiding the agent on how to effectively locate relevant code or resources within a large codebase. - Context: Used when memories suggested using grep, find, or inspecting specific asset files (like package.json or paper abstracts) before writing code. 15 Memory Transfer Learning: How Memories are Transferred Ac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.