Recognition: unknown
MAny: Merge Anything for Multimodal Continual Instruction Tuning
Pith reviewed 2026-05-10 13:52 UTC · model grok-4.3
The pith
Merging cross-modal projections and low-rank parameters prevents dual forgetting in multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
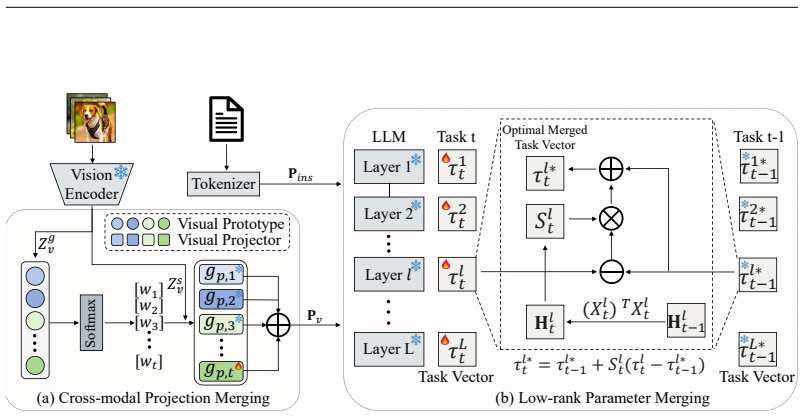
MAny resolves the dual-forgetting phenomenon in MCIT by merging task-specific knowledge through Cross-modal Projection Merging (CPM) and Low-rank Parameter Merging (LPM). CPM adaptively merges visual representations using visual-prototype guidance to recover perceptual alignment during inference. LPM recursively merges low-rank weight matrices via recursive least squares to provide a closed-form optimal fusion that eliminates interference and ensures reasoning stability. The entire process is training-free and relies on efficient CPU-based operations, leading to superior performance across multiple MLLMs and benchmarks including leads of up to 8.57% in final average accuracy on the UCIT.
What carries the argument
Cross-modal Projection Merging guided by visual prototypes combined with recursive least-squares Low-rank Parameter Merging, which together fuse task knowledge without further training or interference.
If this is right
- Models retain both perceptual and reasoning capabilities across arbitrary task sequences.
- No additional gradient-based optimization is needed after initial task tuning.
- The approach delivers accuracy gains of up to 8.57% and 2.85% over prior methods on the UCIT benchmark for two MLLMs.
- Merging occurs via closed-form algebraic operations executable on CPU.
Where Pith is reading between the lines
- Similar merging techniques might apply to other forms of continual learning in non-multimodal settings.
- The closed-form nature of the fusion could allow for provable bounds on forgetting rates in future theoretical work.
- This could lower barriers to deploying adaptable multimodal systems in dynamic environments like robotics or personalized assistants.
- Testing on even longer task sequences would reveal if the interference-free property holds indefinitely.
Load-bearing premise
That the visual-prototype guided merging of projections and the recursive least-squares merging of low-rank matrices will recover alignment and stability for any task sequence without new interference or task-specific tuning.
What would settle it
A direct test would be to apply MAny to a sequence of 10 or more diverse multimodal tasks and measure if average accuracy across all tasks remains higher than baselines or if feature similarity metrics show no drift in projections.
Figures




read the original abstract
Multimodal Continual Instruction Tuning (MCIT) is essential for sequential task adaptation of Multimodal Large Language Models (MLLMs) but is severely restricted by catastrophic forgetting. While existing literature focuses on the reasoning language backbone, in this work, we expose a critical yet neglected dual-forgetting phenomenon across both perception drift in Cross-modal Projection Space and reasoning collapse in Low-rank Parameter Space. To resolve this, we present \textbf{MAny} (\textbf{M}erge \textbf{Any}thing), a framework that merges task-specific knowledge through \textbf{C}ross-modal \textbf{P}rojection \textbf{M}erging (\textbf{CPM}) and \textbf{L}ow-rank \textbf{P}arameter \textbf{M}erging (\textbf{LPM}). Specifically, CPM recovers perceptual alignment by adaptively merging cross-modal visual representations via visual-prototype guidance, ensuring accurate feature recovery during inference. Simultaneously, LPM eliminates mutual interference among task-specific low-rank modules by recursively merging low-rank weight matrices. By leveraging recursive least squares, LPM provides a closed-form solution that mathematically guarantees an optimal fusion trajectory for reasoning stability. Notably, MAny operates as a training-free paradigm that achieves knowledge merging via efficient CPU-based algebraic operations, eliminating additional gradient-based optimization beyond initial tuning. Our extensive evaluations confirm the superior performance and robustness of MAny across multiple MLLMs and benchmarks. Specifically, on the UCIT benchmark, MAny achieves significant leads of up to 8.57\% and 2.85\% in final average accuracy over state-of-the-art methods across two different MLLMs, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAny, a training-free framework for Multimodal Continual Instruction Tuning (MCIT) of MLLMs that addresses dual-forgetting (perception drift in cross-modal projection space and reasoning collapse in low-rank parameter space) via two merging operations: Cross-modal Projection Merging (CPM) using visual-prototype guidance for adaptive feature recovery, and Low-rank Parameter Merging (LPM) that recursively fuses task-specific low-rank matrices with recursive least squares to yield a closed-form optimal fusion trajectory claimed to guarantee reasoning stability. It reports empirical leads of up to 8.57% and 2.85% final average accuracy on the UCIT benchmark over SOTA methods for two MLLMs, operating entirely via CPU-based algebraic operations after initial tuning.
Significance. If the mathematical guarantee and empirical robustness hold, the work would be significant for enabling efficient, gradient-free continual adaptation of multimodal models at scale, directly tackling both perceptual and reasoning interference without task-specific hyperparameters or retraining. The training-free algebraic merging paradigm, if reproducible and generalizable, could reduce compute barriers in sequential MLLM deployment.
major comments (3)
- [Abstract] Abstract: The assertion that LPM via recursive least squares 'provides a closed-form solution that mathematically guarantees an optimal fusion trajectory for reasoning stability' is load-bearing for the central claim but lacks any derivation, normal-equation expansion, or proof sketch showing how the RLS quadratic loss on low-rank updates corresponds to the MCIT objective of preserving prior-task performance and perceptual alignment across arbitrary sequences; without this, the guarantee does not follow from standard RLS properties.
- [Abstract] Abstract and evaluation sections: The reported gains of 8.57% and 2.85% on UCIT are presented without error bars, standard deviations across runs, or ablation studies isolating CPM vs. LPM contributions, making it impossible to verify robustness or rule out benchmark-specific artifacts in the post-hoc selection of tasks and MLLMs.
- [Method (LPM)] Method description (LPM): The claim that recursive merging eliminates mutual interference assumes low-rank modules remain sufficiently orthogonal or that merging order introduces no bias, yet no analysis or counterexample test is provided to confirm the fused matrix preserves earlier-task performance when these conditions are violated.
minor comments (2)
- [Method] Notation for visual prototypes and low-rank matrices should be defined explicitly with dimensions before use in the merging equations.
- [Experiments] The manuscript would benefit from a clear statement of the exact UCIT task sequence and MLLM architectures used for the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that LPM via recursive least squares 'provides a closed-form solution that mathematically guarantees an optimal fusion trajectory for reasoning stability' is load-bearing for the central claim but lacks any derivation, normal-equation expansion, or proof sketch showing how the RLS quadratic loss on low-rank updates corresponds to the MCIT objective of preserving prior-task performance and perceptual alignment across arbitrary sequences; without this, the guarantee does not follow from standard RLS properties.
Authors: We acknowledge that the current manuscript does not provide an explicit derivation or proof sketch linking the RLS quadratic loss to the MCIT objectives. While recursive least squares yields a closed-form solution by solving the normal equations for the minimum of the quadratic objective, we agree that explicitly showing how this preserves prior-task performance and perceptual alignment would better support the claim. In the revised version, we will add a proof sketch in the appendix that expands the normal equations and connects the fusion trajectory to the dual-forgetting mitigation in MCIT. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: The reported gains of 8.57% and 2.85% on UCIT are presented without error bars, standard deviations across runs, or ablation studies isolating CPM vs. LPM contributions, making it impossible to verify robustness or rule out benchmark-specific artifacts in the post-hoc selection of tasks and MLLMs.
Authors: We agree that error bars, standard deviations, and isolating ablations are necessary to demonstrate robustness. The full experimental results were obtained over multiple random seeds, but these statistics were not reported in the abstract or highlighted in the evaluation. We will revise the abstract to include error bars on the reported gains and add ablation studies in the experiments section that isolate the contributions of CPM and LPM. revision: yes
-
Referee: [Method (LPM)] Method description (LPM): The claim that recursive merging eliminates mutual interference assumes low-rank modules remain sufficiently orthogonal or that merging order introduces no bias, yet no analysis or counterexample test is provided to confirm the fused matrix preserves earlier-task performance when these conditions are violated.
Authors: The recursive least squares update in LPM is formulated to minimize the combined quadratic loss over all prior low-rank matrices at each step, which by design reduces mutual interference without requiring strict orthogonality. However, we recognize that additional analysis on merging order and potential biases would strengthen the presentation. In the revision, we will include a discussion of these assumptions along with empirical tests that vary task order and provide counterexample checks to confirm preservation of earlier-task performance. revision: yes
Circularity Check
No significant circularity; derivations rely on independent algebraic procedures
full rationale
The paper introduces CPM via visual-prototype guidance and LPM via recursive least-squares fusion of low-rank matrices as new merging operations. These are presented as training-free algebraic steps whose optimality is defined with respect to standard RLS normal equations rather than any quantity fitted from the target continual-learning objective or prior self-citations. No load-bearing self-citation chains, self-definitional loops, or renamings of known results appear in the abstract or high-level claims. Empirical gains on UCIT are reported separately from the algebraic construction, leaving the central derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and J Qwen-VL Zhou. A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 6:3, 2023a. Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Ji...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Zijian Gao, Kele Xu, Huiping Zhuang, Li Liu, Xinjun Mao, Bo Ding, Dawei Feng, and Huaimin Wang. Less confidence, less forgetting: Learning with a humbler teacher in exemplar-free class- incremental learning.Neural Networks, 179:106513, 2024a. ISSN 0893-6080. Zijian Gao, Xingxing Zhang, Kele Xu, Xinjun Mao, and Huaimin Wang. Stabilizing zero-shot predictio...
-
[3]
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286,
-
[4]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089,
work page internal anchor Pith review arXiv
-
[5]
Dataless knowl- edge fusion by merging weights of language models,
Xisen Jin, Xiang Ren, Daniel Preotiuc-Pietro, and Pengxiang Cheng. Dataless knowledge fusion by merging weights of language models.arXiv preprint arXiv:2212.09849,
-
[6]
Minjae Lee, Minhyuk Seo, Tingyu Qu, Tinne Tuytelaars, and Jonghyun Choi. Oasis: Online sample selection for continual visual instruction tuning.arXiv preprint arXiv:2506.02011,
-
[7]
Songze Li, Mingyu Gao, Tonghua Su, Xu-Yao Zhang, and Zhongjie Wang. Multimodal continual instruction tuning with dynamic gradient guidance.arXiv preprint arXiv:2511.15164,
-
[8]
Clevr-math: A dataset for compositional lan- guage, visual and mathematical reasoning
Adam Dahlgren Lindström and Savitha Sam Abraham. Clevr-math: A dataset for compositional language, visual and mathematical reasoning.arXiv preprint arXiv:2208.05358,
-
[9]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 26296–26306, 2024a. Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is yo...
-
[10]
Iconqa: A new benchmark for abstract diagram under- standing and visual language reasoning
Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning.arXiv preprint arXiv:2110.13214,
-
[11]
Wenju Sun, Qingyong Li, Yangli-ao Geng, and Boyang Li. Cat merging: A training-free approach for resolving conflicts in model merging.arXiv preprint arXiv:2505.06977, 2025a. Wenju Sun, Qingyong Li, Wen Wang, Yangliao Geng, and Boyang Li. Task arithmetic in trust region: A training-free model merging approach to navigate knowledge conflicts. InProceedings ...
-
[12]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Orthogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan- Jing Huang. Orthogonal subspace learning for language model continual learning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 10658–10671, 2023a. Ziao Wang, Yuhang Li, Junda Wu, Jaehyeon Soon, and Xiaofeng Zhang. Finvis-gpt: A multi...
-
[14]
Progressive lora for multimodal continual instruction tuning
Yahan Yu, Duzhen Zhang, Yong Ren, Xuanle Zhao, Xiuyi Chen, and Chenhui Chu. Progressive lora for multimodal continual instruction tuning. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 2779–2796,
2025
-
[15]
Modalprompt: Towards efficient multimodal continual instruction tuning with dual-modality guided prompt
Fanhu Zeng, Fei Zhu, Haiyang Guo, Xu-Yao Zhang, and Cheng-Lin Liu. Modalprompt: Towards efficient multimodal continual instruction tuning with dual-modality guided prompt. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 12137–12152,
2025
-
[16]
, L} 3:fort= 1tondo 4:1
13 Algorithm 1The Proposed MAny Method Input: Pre-trained weights{W l pre,Φ v}, Task sequence{T t}n t=1, Scaling factorλ, Temperatureη Output: Merged task vectors {τ l∗ n }L l=1, Task-specific Projectors {Pi}n i=1, and Prototypes {µi}n i=1 1:Training Phase: 2: Initialize cumulative covariance Hl 0 =0 and global task vector τ l∗ 0 =0 for each layer l∈ {1, ...
2024
-
[17]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention.arXiv preprint arXiv:2303.16199,
-
[18]
Hongbo Zhao, Fei Zhu, Haiyang Guo, Meng Wang, Rundong Wang, Gaofeng Meng, and Zhaoxiang Zhang. Mllm-cl: Continual learning for multimodal large language models.arXiv preprint arXiv:2506.05453, 2025a. Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, and Maosong Sun. Chart- coder: Advancing multimodal large language model for chart-to-co...
-
[19]
(20) Worst case (Fully collinear features).Conversely, we consider the opposite extreme where all task features share an identical set of right singular vectors, i.e., Vl i =V l for all i∈ {1, . . . , t} . This scenario represents a state of maximum interference, where tasks compete for the same parameter directions. Under this highly overlapping conditio...
-
[20]
The learning rates for LLaV A and InternVL are set to 2e-4 and 1e-4, respectively. On the MLLM-DCL benchmark, the batch size is reduced to 8, with learning rates of 2e-5 for LLaV A and 1e-4 for InternVL. Training epochs for this benchmark are task-specific: 3 epochs for the Medicine task, 2 epochs for the Science task, and 1 epoch for all remaining tasks....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.