Recognition: unknown
Stochastic Trust-Region Methods for Over-parameterized Models
Pith reviewed 2026-05-10 12:28 UTC · model grok-4.3
The pith
A stochastic trust-region method reaches ε-stationary points with O(ε^{-2} log(1/ε)) complexity under interpolation assumptions without manual step-size tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
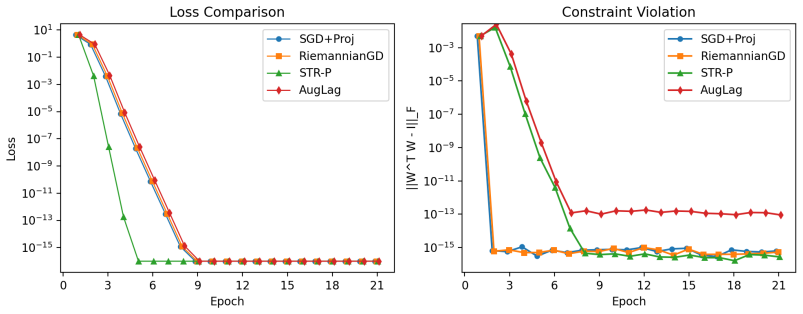
Under the strong growth condition, the first-order stochastic trust-region algorithm achieves an iteration and stochastic first-order oracle complexity of O(ε^{-2} log(1/ε)) for finding an ε-stationary point. For equality-constrained problems, the quadratic-penalty-based stochastic trust-region method with penalty parameter μ establishes an iteration and oracle complexity of O(ε^{-4} log(1/ε)) to reach an ε-stationary point of the penalized problem, corresponding to an O(ε)-approximate KKT point of the original constrained problem.
What carries the argument
The stochastic trust-region framework, which adaptively adjusts step sizes via trust-region radii instead of fixed learning rates, extended by a quadratic-penalty formulation for equality constraints.
Load-bearing premise
The strong growth condition or similar interpolation-type assumptions must hold for the objective functions.
What would settle it
A concrete numerical test in which the algorithm requires substantially more than O(ε^{-2} log(1/ε)) iterations to reach an ε-stationary point while the strong growth condition is satisfied would falsify the complexity claim.
Figures

read the original abstract
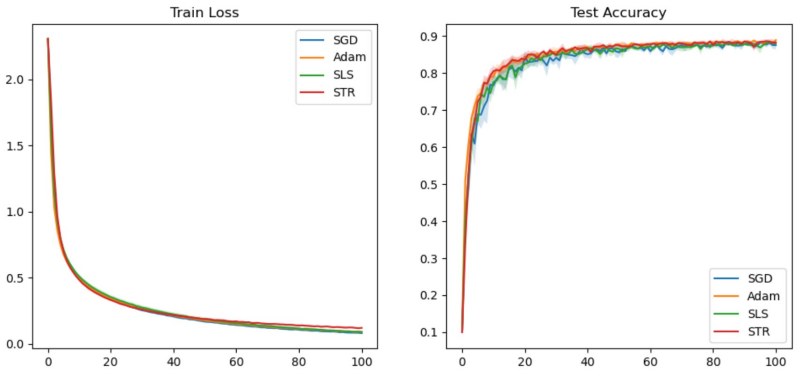
Under interpolation-type assumptions such as the strong growth condition, stochastic optimization methods can attain convergence rates comparable to full-batch methods, but their performance, particularly for SGD, remains highly sensitive to step-size selection. To address this issue, we propose a unified stochastic trust-region framework that eliminates manual step-size tuning and extends naturally to equality-constrained problems. For unconstrained optimization, we develop a first-order stochastic trust-region algorithm and show that, under the strong growth condition, it achieves an iteration and stochastic first-order oracle complexity of $O(\varepsilon^{-2} \log(1/\varepsilon))$ for finding an $\varepsilon$-stationary point. For equality-constrained problems, we introduce a quadratic-penalty-based stochastic trust-region method with penalty parameter $\mu$, and establish an iteration and oracle complexity of $O(\varepsilon^{-4} \log(1/\varepsilon))$ to reach an $\varepsilon$-stationary point of the penalized problem, corresponding to an $O(\varepsilon)$-approximate KKT point of the original constrained problem. Numerical experiments on deep neural network training and orthogonally constrained subspace fitting demonstrate that the proposed methods achieve performance comparable to well-tuned stochastic baselines, while exhibiting stable optimization behavior and effectively handling hard constraints without manual learning-rate scheduling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a unified stochastic trust-region framework for over-parameterized models. Under the strong growth condition, the first-order stochastic trust-region algorithm achieves an iteration and stochastic first-order oracle complexity of O(ε^{-2} log(1/ε)) for ε-stationary points in the unconstrained case. For equality-constrained problems, the quadratic-penalty stochastic trust-region method attains O(ε^{-4} log(1/ε)) complexity for an ε-approximate KKT point. The methods are demonstrated on deep neural network training and orthogonally constrained subspace fitting tasks, showing performance comparable to tuned stochastic baselines with stable behavior.
Significance. If the results hold, this work is significant for providing automatic step-size adaptation via trust regions in stochastic settings, achieving rates that match or improve upon standard methods under interpolation assumptions common in over-parameterized models. The extension to constrained problems is particularly valuable, and the empirical results suggest practical applicability without extensive hyperparameter tuning. Strengths include the explicit complexity bounds and the handling of hard constraints.
minor comments (3)
- Clarify in the introduction or algorithm description how the trust-region parameters (e.g., initial radius and acceptance thresholds) are set in practice, as this could still involve some user choice despite the claim of eliminating manual step-size tuning.
- The description of the numerical experiments would benefit from specifying the number of independent runs or random seeds used and any statistical measures of variability, to better support the claims of stable optimization behavior and comparability to baselines.
- Ensure the strong growth condition is formally defined with its equation number in the main text before its use in complexity statements, for improved readability.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation for minor revision. The referee's summary accurately captures the key contributions of our work on the stochastic trust-region framework for over-parameterized models, including the complexity bounds under the strong growth condition and the empirical demonstrations on DNN training and constrained subspace fitting. No specific major comments were raised in the report.
Circularity Check
No circularity in derivation of complexity bounds under explicit assumptions.
full rationale
The paper presents a theoretical analysis deriving iteration and stochastic first-order oracle complexity bounds for a stochastic trust-region algorithm and its quadratic-penalty extension. These bounds (O(ε^{-2} log(1/ε)) and O(ε^{-4} log(1/ε))) are obtained by applying standard trust-region analysis steps to the strong growth condition (SGC) as an input assumption, without any reduction of the claimed results to fitted parameters, self-definitions, or self-citation chains. No load-bearing steps equate outputs to inputs by construction, and the derivation remains self-contained once SGC and other stated assumptions are granted. This is the typical non-circular outcome for complexity proofs in optimization theory.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption strong growth condition (interpolation-type assumption)
Reference graph
Works this paper leans on
-
[1]
Belkin, D
M. Belkin, D. Hsu, S. Ma, and S. Mandal,Reconciling modern machine-learning practice and the classical bias–variance trade-off, Proceedings of the National Academy of Sciences 116 (2019), pp. 15849–15854
2019
-
[2]
Bellavia, B
S. Bellavia, B. Morini, and S. Rebegoldi,On the convergence properties of a stochastic trust-region method with inexact restoration, Axioms 12 (2023), p. 38
2023
-
[3]
Bertsekas,Nonlinear programming, Journal of the Operational Research Society 48 (1997), pp
D.P. Bertsekas,Nonlinear programming, Journal of the Operational Research Society 48 (1997), pp. 334–334
1997
-
[4]
Bertsekas,Constrained Optimization and Lagrange Multiplier Methods, Academic Press, 2014
D.P. Bertsekas,Constrained Optimization and Lagrange Multiplier Methods, Academic Press, 2014
2014
-
[5]
Birgin and J.M
E.G. Birgin and J.M. Mart´ ınez,Practical Augmented Lagrangian Methods for Constrained Optimization, SIAM, 2014
2014
-
[6]
D. Boob, Q. Deng, and G. Lan,Stochastic first-order methods for convex and nonconvex functional constrained optimization, Mathematical Programming 197 (2023), pp. 215–279
2023
-
[7]
Bottou,Large-scale machine learning with stochastic gradient descent, Proceedings of COMPSTAT (2010), pp
L. Bottou,Large-scale machine learning with stochastic gradient descent, Proceedings of COMPSTAT (2010), pp. 177–186
2010
-
[8]
Bottou, F.E
L. Bottou, F.E. Curtis, and J. Nocedal,Optimization methods for large-scale machine learning, SIAM Review 60 (2018), pp. 223–311
2018
-
[9]
Cartis and K
C. Cartis and K. Scheinberg,Global convergence rate analysis of unconstrained optimiza- tion methods based on probabilistic models, Mathematical Programming 169 (2018), pp. 337–375
2018
-
[10]
R. Chen, M. Menickelly, and K. Scheinberg,Stochastic optimization using a trust-region method and random models, Mathematical Programming 169 (2018), pp. 447–487
2018
-
[11]
Conn, N.I
A.R. Conn, N.I. Gould, and P.L. Toint,Trust region methods, SIAM, 2000
2000
-
[12]
Curtis, D.P
F.E. Curtis, D.P. Robinson, and M. Samadi,A stochastic sequential quadratic optimization algorithm for nonlinear equality constrained optimization, Mathematical Programming 188 (2021), pp. 235–292
2021
-
[13]
Curtis and R
F.E. Curtis and R. Shi,A fully stochastic second-order trust region method, Optimization Methods and Software 37 (2022), pp. 844–877
2022
-
[14]
Y. Dar, P. Mayer, L. Luzi, and R. Baraniuk,Subspace fitting meets regression: The effects of supervision and orthonormality constraints on double descent of generalization errors, inInternational Conference on Machine Learning. PMLR, 2020, pp. 2366–2375
2020
-
[15]
Dzahini and S.M
K.J. Dzahini and S.M. Wild,Stochastic trust-region algorithm in random subspaces with convergence and expected complexity analyses(2022). arXiv preprint
2022
-
[16]
Ghadimi and G
S. Ghadimi and G. Lan,Stochastic first- and zeroth-order methods for nonconvex stochas- tic programming, SIAM Journal on Optimization 23 (2013), pp. 2341–2368
2013
-
[17]
Gratton, C.W
S. Gratton, C.W. Royer, L.N. Vicente, and Z. Zhang,Complexity and global rates of trust-region methods based on probabilistic models, IMA Journal of Numerical Analysis 36 (2015), pp. 1662–1695
2015
-
[18]
Y. Ha, S. Shashaani, and R. Pasupathy,Complexity of zeroth- and first-order stochastic trust-region algorithms(2024). arXiv preprint
2024
-
[19]
K. He, X. Zhang, S. Ren, and J. Sun,Deep Residual Learning for Image Recognition, 24 inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016, pp. 770–778
2016
-
[20]
T. Lin, C. Jin, and M.I. Jordan,Near-optimal algorithms for minimax optimization, in Conference on Learning Theory (COLT). 2020, pp. 2738–2779
2020
-
[21]
Nemirovski, A
A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro,Robust stochastic approximation approach to stochastic programming, SIAM Journal on Optimization 19 (2009), pp. 1574– 1609
2009
-
[22]
Nocedal and S.J
J. Nocedal and S.J. Wright,Numerical Optimization, 2nd ed., Springer, 2006
2006
-
[23]
Nouiehed, M
M. Nouiehed, M. Sanjabi, T. Huang, J.D. Lee, and M. Razaviyayn,Solving a class of nonconvex min–max games using iterative first-order methods, SIAM Journal on Opti- mization 29 (2019), pp. 3011–3040
2019
-
[24]
Paquette and K
C. Paquette and K. Scheinberg,Stochastic cubic regularization with variance reduction, Mathematical Programming 179 (2020), pp. 67–99
2020
-
[25]
Rafique, M
H. Rafique, M. Liu, Q. Lin, and T. Yang,Weakly-convex concave minimax optimization: provable algorithms and applications in machine learning, Journal of Machine Learning Research 22 (2021), pp. 1–45
2021
-
[26]
Recht and C
B. Recht and C. R´ e,Parallel stochastic gradient algorithms for large-scale matrix com- pletion, Mathematical Programming Computation 5 (2013), pp. 201–226
2013
-
[27]
Robbins and S
H. Robbins and S. Monro,A stochastic approximation method, Annals of Mathematical Statistics 22 (1951), pp. 400–407
1951
-
[28]
arXiv preprint arXiv:1308.6370 , year=
M. Schmidt and N.L. Roux,Fast convergence of stochastic gradient descent under a strong growth condition(2013). Available at https://arxiv.org/abs/1308.6370
-
[29]
Schmidt, N.L
M. Schmidt, N.L. Roux, and F. Bach,Minimizing finite sums with the stochastic average gradient, Mathematical Programming 162 (2017), pp. 83–112
2017
-
[30]
Shalev-Shwartz and S
S. Shalev-Shwartz and S. Ben-David,Understanding Machine Learning: From Theory to Algorithms, Cambridge University Press, 2014
2014
-
[31]
Z. Shen, P. Zhou, C. Fang, J. Xie, and A. Ribeiro,A stochastic trust region method for non-convex minimization(2020). ICLR 2020, revised 2025
2020
-
[32]
Vapnik,An overview of statistical learning theory, IEEE transactions on neural networks 10 (1999), pp
V.N. Vapnik,An overview of statistical learning theory, IEEE transactions on neural networks 10 (1999), pp. 988–999
1999
-
[33]
Vaswani, F
S. Vaswani, F. Bach, and M. Schmidt,Fast and Faster Convergence of SGD for Over- Parameterized Models and an Accelerated Perceptron, inProceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, K. Chaudhuri and M. Sugiyama, eds., Proceedings of Machine Learning Research Vol. 89, 16–18 Apr. PMLR, 2019, pp. 1195–1204
2019
-
[34]
Vaswani, K
S. Vaswani, K. Mishchenko, I. Laradji, M. Schmidt, and L. Bottou,Fast and faster conver- gence of SGD for over-parameterized models and an accelerated perceptron, inAdvances in Neural Information Processing Systems. 2019
2019
-
[35]
Vaswani, A
S. Vaswani, A. Mishkin, I. Laradji, M. Schmidt, G. Gidel, and S. Lacoste-Julien,Painless stochastic gradient: Interpolation, line-search, and convergence rates, Advances in neural information processing systems 32 (2019)
2019
-
[36]
X. Wang and Y.x. Yuan,Stochastic trust region methods with trust region radius depending on probabilistic models, arXiv preprint arXiv:1904.03342 (2019)
-
[37]
Z. Wang, K. Balasubramanian, S. Ma, and M. Razaviyayn,Zeroth-order algorithms for nonconvex–strongly-concave minimax problems with improved complexities, Journal of Global Optimization 87 (2023), pp. 709–740
2023
-
[38]
Wen and W
Z. Wen and W. Yin,A feasible method for optimization with orthogonality constraints, Mathematical Programming 142 (2013), pp. 397–434
2013
-
[39]
C. Xie, C. Li, C. Zhang, Q. Deng, D. Ge, and Y. Ye,Trust Region Methods For Nonconvex Stochastic Optimization Beyond Lipschitz Smoothness, inAAAI. 2024. arXiv preprint
2024
-
[40]
Xu,First-order methods for constrained convex programming based on linearized aug- mented lagrangian function, INFORMS Journal on Optimization 3 (2021), pp
Y. Xu,First-order methods for constrained convex programming based on linearized aug- mented lagrangian function, INFORMS Journal on Optimization 3 (2021), pp. 89–117
2021
-
[41]
Understanding deep learning requires rethinking generalization
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals,Understanding deep learning requires rethinking generalization, arXiv preprint arXiv:1611.03530 (2016). 25
work page internal anchor Pith review arXiv 2016
-
[42]
Zheng,Trust-region stochastic optimization with variance reduction technique(2024)
X. Zheng,Trust-region stochastic optimization with variance reduction technique(2024). arXiv preprint
2024
- [43]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.