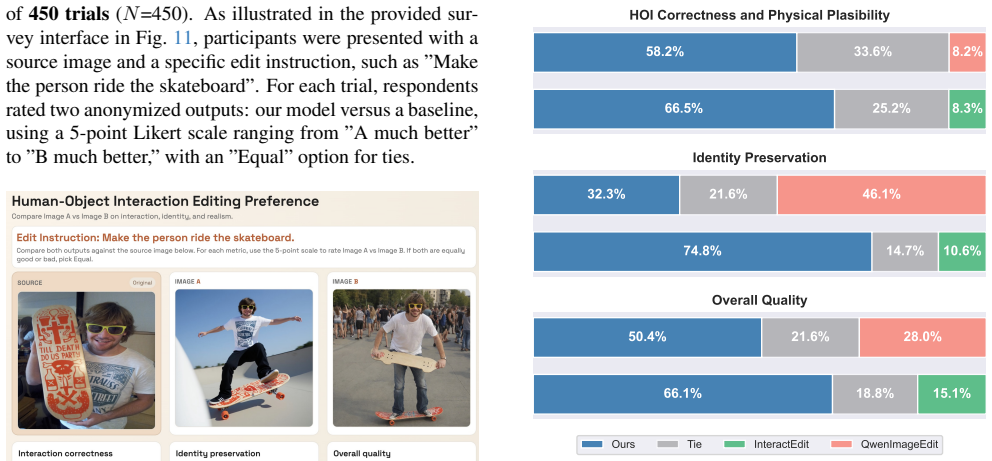
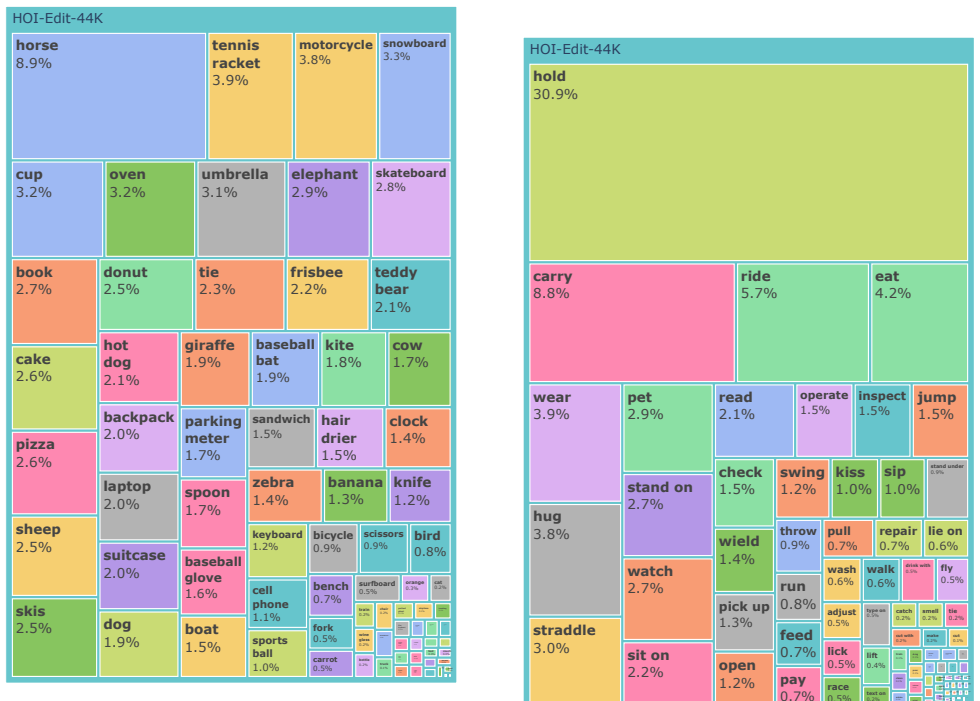
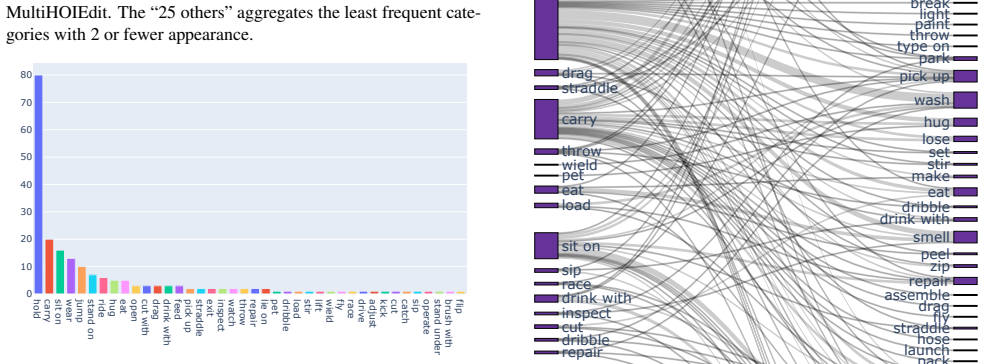
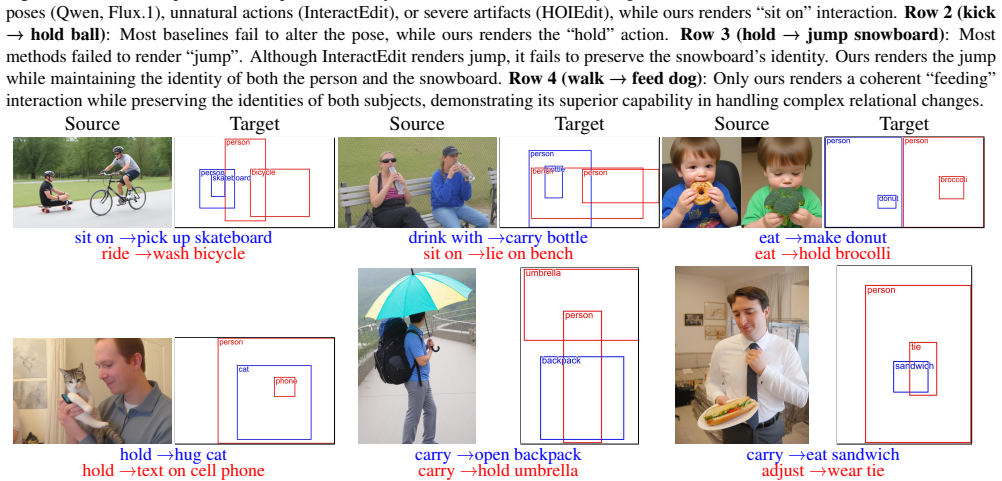
Recognition: unknown
OneHOI: Unifying Human-Object Interaction Generation and Editing
Pith reviewed 2026-05-10 14:18 UTC · model grok-4.3
The pith
OneHOI unifies human-object interaction generation and editing in a single diffusion transformer using shared structured representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce OneHOI, a unified diffusion transformer framework that consolidates HOI generation and editing into a single conditional denoising process driven by shared structured interaction representations. At its core, the Relational Diffusion Transformer models verb-mediated relations through role- and instance-aware HOI tokens, layout-based spatial Action Grounding, a Structured HOI Attention to enforce interaction topology, and HOI RoPE to disentangle multi-HOI scenes. Trained jointly with modality dropout on HOI-Edit-44K along with HOI and object-centric datasets, OneHOI supports layout-guided, layout-free, arbitrary-mask, and mixed-condition control.
What carries the argument
The Relational Diffusion Transformer (R-DiT), which processes verb-mediated relations via role- and instance-aware HOI tokens, layout-based Action Grounding, Structured HOI Attention for topology, and HOI RoPE for multi-interaction disentanglement within one conditional denoising process.
If this is right
- The model supports layout-guided, layout-free, arbitrary-mask, and mixed-condition inputs in one process.
- Joint training on HOI-Edit-44K and related datasets yields state-of-the-art results on both generation and editing tasks.
- Shared structured representations eliminate the need for separate models when switching between creation and modification.
- Modality dropout enables the system to handle incomplete or mixed conditions such as object-only entities alongside full interactions.
Where Pith is reading between the lines
- The unification approach could reduce overall model count and training overhead when building broader scene-understanding systems that combine multiple interaction types.
- Interactive applications might now allow seamless generation followed by immediate editing within the same trained network rather than model switching.
- Similar token-and-attention designs could be tested on related tasks such as human-human interactions or scene-graph-conditioned synthesis.
Load-bearing premise
The assumption that the Relational Diffusion Transformer components together with modality dropout in joint training can support mixed conditions and deliver strong performance on both generation and editing without hidden trade-offs.
What would settle it
A direct comparison where the unified model produces measurably worse generation quality or editing accuracy than specialized models on standard benchmarks, or fails to correctly integrate mixed inputs such as an HOI triplet plus an independent object mask.
Figures
















read the original abstract
Human-Object Interaction (HOI) modelling captures how humans act upon and relate to objects, typically expressed as <person, action, object> triplets. Existing approaches split into two disjoint families: HOI generation synthesises scenes from structured triplets and layout, but fails to integrate mixed conditions like HOI and object-only entities; and HOI editing modifies interactions via text, yet struggles to decouple pose from physical contact and scale to multiple interactions. We introduce OneHOI, a unified diffusion transformer framework that consolidates HOI generation and editing into a single conditional denoising process driven by shared structured interaction representations. At its core, the Relational Diffusion Transformer (R-DiT) models verb-mediated relations through role- and instance-aware HOI tokens, layout-based spatial Action Grounding, a Structured HOI Attention to enforce interaction topology, and HOI RoPE to disentangle multi-HOI scenes. Trained jointly with modality dropout on our HOI-Edit-44K, along with HOI and object-centric datasets, OneHOI supports layout-guided, layout-free, arbitrary-mask, and mixed-condition control, achieving state-of-the-art results across both HOI generation and editing. Code is available at https://jiuntian.github.io/OneHOI/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OneHOI, a unified diffusion transformer framework that consolidates HOI generation and editing into a single conditional denoising process. The core Relational Diffusion Transformer (R-DiT) uses role- and instance-aware HOI tokens, layout-based spatial Action Grounding, Structured HOI Attention to enforce interaction topology, and HOI RoPE to disentangle multi-HOI scenes. It is trained jointly with modality dropout on HOI-Edit-44K plus HOI and object-centric datasets to support layout-guided, layout-free, arbitrary-mask, and mixed-condition control, claiming state-of-the-art results on both tasks.
Significance. If the unification holds without performance trade-offs, this would be a meaningful advance in HOI modeling by replacing separate generation and editing pipelines with one model supporting flexible mixed conditions. The public code release at the provided URL is a clear strength that supports reproducibility and community validation.
major comments (2)
- [Abstract] Abstract: The assertion of achieving 'state-of-the-art results across both HOI generation and editing' supplies no quantitative metrics, benchmark tables, or specific comparisons. This is load-bearing for the central unification claim, as the abstract provides no evidence that joint training maintains or exceeds specialized models on pure generation or editing benchmarks.
- [Experimental evaluation] The manuscript lacks any ablation isolating the effect of joint training with modality dropout versus task-specific training on the R-DiT components. This directly tests the assumption that the shared structured representations support arbitrary mixed conditions without hidden trade-offs on generation (e.g., layout-conditioned synthesis) or editing benchmarks.
minor comments (1)
- [Method] The description of HOI RoPE would benefit from an explicit equation or diagram contrasting it with standard rotary position embeddings to clarify the disentanglement mechanism for multi-HOI scenes.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive suggestions. Below, we provide detailed responses to the major comments, outlining the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of achieving 'state-of-the-art results across both HOI generation and editing' supplies no quantitative metrics, benchmark tables, or specific comparisons. This is load-bearing for the central unification claim, as the abstract provides no evidence that joint training maintains or exceeds specialized models on pure generation or editing benchmarks.
Authors: We agree that providing quantitative metrics in the abstract would better support the central unification claim. In the revised manuscript, we will update the abstract to include specific performance metrics and comparisons from our experimental results, such as key improvements on generation and editing benchmarks. This will offer immediate evidence while keeping the abstract concise, with full details remaining in the main text and tables. revision: yes
-
Referee: [Experimental evaluation] The manuscript lacks any ablation isolating the effect of joint training with modality dropout versus task-specific training on the R-DiT components. This directly tests the assumption that the shared structured representations support arbitrary mixed conditions without hidden trade-offs on generation (e.g., layout-conditioned synthesis) or editing benchmarks.
Authors: We acknowledge the importance of this ablation to validate that joint training does not introduce trade-offs. We will add a dedicated ablation study in the revised manuscript that compares the jointly trained model with modality dropout against separately trained task-specific models on both HOI generation and editing benchmarks. This will provide direct evidence regarding the effectiveness of the shared representations for mixed conditions. revision: yes
Circularity Check
No significant circularity; novel architecture stands on independent design and training
full rationale
The paper introduces OneHOI as a new diffusion transformer with R-DiT components (role/instance-aware tokens, Action Grounding, Structured HOI Attention, HOI RoPE) trained jointly via modality dropout on HOI-Edit-44K and other datasets. No equations, predictions, or first-principles results are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The unification of generation and editing is claimed through architectural choices and empirical SOTA results rather than any renaming or redefinition of known quantities. Self-citations, if present for prior HOI work, are not load-bearing for the core contribution, which remains a self-contained model proposal against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Diffusion process assumptions for conditional denoising
invented entities (3)
-
Relational Diffusion Transformer (R-DiT)
no independent evidence
-
Structured HOI Attention
no independent evidence
-
HOI RoPE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. In- structpix2pix: Learning to follow image editing instructions. InCVPR, 2023. 6
2023
-
[2]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. InICCV, pages 22560–22570, 2023. 6
2023
-
[3]
Yichao Cao, Qingfei Tang, Xiu Su, Song Chen, Shan You, Xiaobo Lu, and Chang Xu. Detecting any human-object interaction relationship: Universal hoi detector with spatial prompt learning on foundation models.Advances in Neural Information Processing Systems, 36:739–751, 2023. 1
2023
-
[4]
Verbdiff: Text-only diffusion models with enhanced interaction awareness
SeungJu Cha, Kwanyoung Lee, Ye-Chan Kim, Hyunwoo Oh, and Dong-Jin Kim. Verbdiff: Text-only diffusion models with enhanced interaction awareness. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8041–8050, 2025. 1
2025
-
[5]
Learning to detect human-object interactions
Yu-Wei Chao, Yunfan Liu, Xieyang Liu, Huayi Zeng, and Jia Deng. Learning to detect human-object interactions. In2018 ieee winter conference on applications of computer vision (wacv), pages 381–389. IEEE, 2018. 5
2018
-
[6]
Qahoi: Query-based anchors for human-object interaction detection
Junwen Chen and Keiji Yanai. Qahoi: Query-based anchors for human-object interaction detection. In2023 18th In- ternational Conference on Machine Vision and Applications (MVA), pages 1–5. IEEE, 2023. 1
2023
-
[7]
Fireflow: Fast inversion of rectified flow for image semantic editing
Yingying Deng, Xiangyu He, Changwang Mei, Peisong Wang, and Fan Tang. Fireflow: Fast inversion of rectified flow for image semantic editing. InICML, 2025. 6
2025
-
[8]
Turboedit: Text-based image editing using few-step diffusion models
Gilad Deutch, Rinon Gal, Daniel Garibi, Or Patashnik, and Daniel Cohen-Or. Turboedit: Text-based image editing using few-step diffusion models. InSIGGRAPH Asia 2024 Con- ference Papers, pages 1–12, 2024. 6
2024
-
[9]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[10]
Prompt-to-prompt image editing with cross attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. InICLR, 2023. 6
2023
-
[11]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[12]
Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.NeurIPS, 33:6840–6851, 2020. 2
2020
-
[13]
Interactdiffusion: Interaction control in text-to-image diffusion models
Jiun Tian Hoe, Xudong Jiang, Chee Seng Chan, Yap-Peng Tan, and Weipeng Hu. Interactdiffusion: Interaction control in text-to-image diffusion models. InCVPR, pages 6180– 6189, 2024. 1, 2, 3, 6, 7
2024
-
[14]
Jiun Tian Hoe, Weipeng Hu, Wei Zhou, Chao Xie, Ziwei Wang, Chee Seng Chan, Xudong Jiang, and Yap-Peng Tan. Interactedit: Zero-shot editing of human-object interactions in images.arXiv preprint arXiv:2503.09130, 2025. 1, 2, 5, 6
-
[15]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In ICLR, 2022. 5, 1
2022
-
[16]
An edit friendly DDPM noise space: Inversion and manipulations
Inbar Huberman-Spiegelglas, Vladimir Kulikov, and Tomer Michaeli. An edit friendly DDPM noise space: Inversion and manipulations. InCVPR, pages 12469–12478, 2024. 6
2024
-
[17]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. 5
2015
-
[18]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InICCV, pages 4015–4026, 2023. 5, 2
2023
-
[19]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Ad- vances in neural information processing systems, 36:36652– 36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Ma- tiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Ad- vances in neural information processing systems, 36:36652– 36663, 2023. 5
2023
-
[20]
Flux, 2024
Black Forest Labs. Flux, 2024. GitHub repository. 1
2024
-
[21]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review arXiv
-
[22]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. In CVPR, pages 22511–22521, 2023. 2, 6
2023
-
[23]
Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. Llm- grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models. InarXiv preprint arXiv:2305.13655, 2023. 2, 5
-
[24]
Flow matching for genera- tive modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matthew Le. Flow matching for genera- tive modeling. InThe Eleventh International Conference on Learning Representations, 2023. 3, 5
2023
-
[25]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection.ECCV, 2024
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.ECCV, 2024. 2
2024
-
[26]
Discovering syntactic interaction clues for human-object interaction detection
Jinguo Luo, Weihong Ren, Weibo Jiang, Xi’ai Chen, Qiang Wang, Zhi Han, and Honghai Liu. Discovering syntactic interaction clues for human-object interaction detection. In CVPR, pages 28212–28222, 2024. 1
2024
-
[27]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: representing scenes as neural radiance fields for view synthe- sis.Communications of the ACM, 65:99–106, 2022. 4
2022
-
[28]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InCVPR, pages 6038–6047,
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 5, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Scalable diffusion mod- els with transformers
William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 2, 3
2023
-
[31]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learn- ing Research, 21(140):1–67, 2020. 3
2020
-
[32]
C. J. Van Rijsbergen.Information Retrieval. Butterworth- Heinemann, USA, 2nd edition, 1979. 2
1979
-
[33]
High-resolution image syn- thesis with latent diffusion models, 2021
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models, 2021. 3
2021
-
[34]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015. 3
2015
-
[35]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InICLR, 2021. 2
2021
-
[36]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[37]
Instancediffusion: Instance- level control for image generation
Xudong Wang, Trevor Darrell, Sai Saketh Rambhatla, Ro- hit Girdhar, and Ishan Misra. Instancediffusion: Instance- level control for image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6232–6242, 2024. 6
2024
-
[38]
Qwen-image technical report,
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, De- qing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
-
[39]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Jun- jie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jia- hao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omni- gen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.1887...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review arXiv
-
[41]
Omnigen: Unified image genera- tion
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xin- grun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image genera- tion. InCVPR, pages 13294–13304, 2025. 6
2025
-
[42]
Imagere- ward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Pro- cessing Systems, 36:15903–15935, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Pro- cessing Systems, 36:15903–15935, 2023. 5
2023
-
[43]
Hoiedit: Human– object interaction editing with text-to-image diffusion model
Tang Xu, Wenbin Wang, and Alin Zhong. Hoiedit: Human– object interaction editing with text-to-image diffusion model. The Visual Computer, pages 1–13, 2025. 1, 2, 6
2025
-
[44]
Zhang, Yuhui Yuan, Dylan Campbell, Zhuoyao Zhong, and Stephen Gould
Frederic Z. Zhang, Yuhui Yuan, Dylan Campbell, Zhuoyao Zhong, and Stephen Gould. Exploring predicate visual con- text in detecting human–object interactions. InICCV, pages 10411–10421, 2023. 5, 2
2023
-
[45]
arXiv preprint arXiv:2501.01097 (2025)
Hong Zhang, Zhongjie Duan, Xingjun Wang, Yingda Chen, and Yu Zhang. Eligen: Entity-level controlled im- age generation with regional attention.arXiv preprint arXiv:2501.01097, 2025. 2, 3, 6, 8, 1
-
[46]
Migc++: Advanced multi-instance generation controller for image synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Dewei Zhou, You Li, Fan Ma, Zongxin Yang, and Yi Yang. Migc++: Advanced multi-instance generation controller for image synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 6
2024
-
[47]
Migc: Multi-instance generation controller for text-to-image synthesis
Dewei Zhou, You Li, Fan Ma, Xiaoting Zhang, and Yi Yang. Migc: Multi-instance generation controller for text-to-image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6818– 6828, 2024. 2, 6 OneHOI: Unifying Human-Object Interaction Generation and Editing Supplementary Material A. Implementation Details ...
2024
-
[48]
a photo of〈subject〉〈target action〉〈object〉 at〈background〉
and InteractDiffusion [13] frameworks. We adapt the original SDXL-based InteractEdit backbone to the InteractDiffusion-XL variant. Our implementation follows a two-stage inversion process for each source image in the IEBench benchmark. In a departure from the standard text- only inversion used in InteractEdit, we leverage InteractD- iffusion’s native supp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.