Recognition: unknown
Towards Unconstrained Human-Object Interaction
Pith reviewed 2026-05-10 14:13 UTC · model grok-4.3
The pith
Multimodal language models can detect human-object interactions in the wild without any predefined list of actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
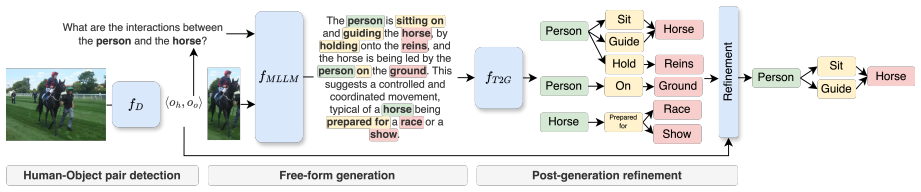
The paper establishes the Unconstrained HOI task, which eliminates any requirement for a predefined interaction vocabulary at training and inference, and demonstrates that multimodal large language models can address it through test-time inference followed by language-to-graph conversion to extract structured interaction representations from free-form text outputs.
What carries the argument
The Unconstrained HOI task, which drops the predefined interaction vocabulary at both training and inference, paired with language-to-graph conversion that structures free-form text outputs into interaction representations.
If this is right
- Current detectors limited to fixed vocabularies cannot generalize to novel interactions encountered in unconstrained scenes.
- Multimodal models enable recognition of arbitrary interactions by generating natural language descriptions instead of selecting from a closed list.
- Test-time inference allows adaptation to new environments without additional model training.
- Structured interaction data remains extractable from open-ended text outputs through the conversion step.
Where Pith is reading between the lines
- This task definition could apply to other open-vocabulary vision problems where interactions or actions cannot be fully enumerated in advance.
- Combining the pipeline with video streams might support real-time monitoring in environments with unpredictable human-object contacts.
- Lower annotation requirements for new domains could arise if models generate descriptions without needing exhaustive predefined lists.
- Chaining the output graphs with downstream reasoning systems might enable higher-level scene interpretation beyond pairwise interactions.
Load-bearing premise
The conversion from the language model's free-form text descriptions to structured interaction graphs occurs without significant parsing errors or loss of scene context.
What would settle it
A set of images showing rare or novel human-object interactions where the extracted graphs from model text are compared against human annotations for accuracy and completeness.
Figures












read the original abstract
Human-Object Interaction (HOI) detection is a longstanding computer vision problem concerned with predicting the interaction between humans and objects. Current HOI models rely on a vocabulary of interactions at training and inference time, limiting their applicability to static environments. With the advent of Multimodal Large Language Models (MLLMs), it has become feasible to explore more flexible paradigms for interaction recognition. In this work, we revisit HOI detection through the lens of MLLMs and apply them to in-the-wild HOI detection. We define the Unconstrained HOI (U-HOI) task, a novel HOI domain that removes the requirement for a predefined list of interactions at both training and inference. We evaluate a range of MLLMs on this setting and introduce a pipeline that includes test-time inference and language-to-graph conversion to extract structured interactions from free-form text. Our findings highlight the limitations of current HOI detectors and the value of MLLMs for U-HOI. Code will be available at https://github.com/francescotonini/anyhoi
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines the Unconstrained HOI (U-HOI) task, which removes the requirement for a predefined list of interactions at both training and inference. It evaluates a range of MLLMs on in-the-wild settings and introduces a pipeline with test-time inference and language-to-graph conversion to extract structured interactions from free-form text, claiming this highlights limitations of current HOI detectors and the value of MLLMs for U-HOI.
Significance. If the pipeline's conversion step holds up under validation, the work could meaningfully advance flexible, open-vocabulary HOI detection for unconstrained real-world scenes, leveraging MLLMs to overcome fixed-vocabulary constraints in traditional detectors.
major comments (2)
- The language-to-graph conversion is load-bearing for all claims about MLLM performance and superiority, yet the manuscript provides no validation of this step (e.g., agreement with human-annotated graphs on the same images) or analysis of parsing errors, hallucinations, or context loss in unconstrained scenes.
- Although the abstract states that evaluations of MLLMs were performed, the text supplies no quantitative metrics, baselines, dataset details, or error analysis, preventing verification that the data support the claims of limitations and value.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our introduction of the U-HOI task and the MLLM-based pipeline. We address the major comments point by point below.
read point-by-point responses
-
Referee: The language-to-graph conversion is load-bearing for all claims about MLLM performance and superiority, yet the manuscript provides no validation of this step (e.g., agreement with human-annotated graphs on the same images) or analysis of parsing errors, hallucinations, or context loss in unconstrained scenes.
Authors: We agree that the language-to-graph conversion step requires explicit validation to support the performance claims. The manuscript currently describes the conversion rules and pipeline but does not include quantitative agreement metrics or error analysis. In the revision we will add a dedicated validation subsection that reports inter-annotator agreement on a held-out set of images, together with a breakdown of parsing errors, hallucinations, and context-loss cases observed in unconstrained scenes. revision: yes
-
Referee: Although the abstract states that evaluations of MLLMs were performed, the text supplies no quantitative metrics, baselines, dataset details, or error analysis, preventing verification that the data support the claims of limitations and value.
Authors: We acknowledge that the presentation of the experimental results is insufficiently detailed. While the manuscript contains some evaluation descriptions, it lacks the full set of quantitative metrics, baseline comparisons, dataset specifications, and error analysis needed for verification. The revised version will expand Sections 4 and 5 to include explicit tables of metrics, baseline results from existing HOI detectors, precise dataset construction details, and a systematic error analysis that directly supports the stated claims about limitations of current detectors and the value of MLLMs for U-HOI. revision: yes
Circularity Check
No circularity detected in task definition or pipeline
full rationale
The paper introduces the U-HOI task and an empirical pipeline using MLLMs plus language-to-graph conversion, with no mathematical derivations, equations, fitted parameters, or self-citations that reduce any claimed result to its own inputs by construction. Evaluation relies on external model outputs and conversion heuristics rather than self-referential definitions or predictions forced by prior fits. The conversion step is an unvalidated methodological choice but does not constitute circularity under the specified patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal large language models can produce reliable free-form descriptions of human-object interactions from visual input.
invented entities (1)
-
Unconstrained HOI (U-HOI) task
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Alameda-Pineda, A
X. Alameda-Pineda, A. Addlesee, D. Hern ´andez Garc ´ıa, C. Reinke, S. Arias, F. Arrigoni, A. Auternaud, L. Blavette, C. Beyan, L. Gomez Camara, et al. Socially pertinent robots in gerontological healthcare.International Journal of Social Robotics, pages 1–22, 2025
2025
-
[3]
Y . Cao, Q. Tang, X. Su, S. Chen, S. You, X. Lu, and C. Xu. Detecting any human-object interaction relationship: Universal HOI detector with spatial prompt learning on foundation models. InAdv. Neural Inf. Process. Syst. (NeurIPS), 2023
2023
-
[4]
Carion, F
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with transformers. In European Conf. Comput. Vis. (ECCV), pages 213–229, 2020
2020
-
[5]
Y . Chao, Y . Liu, X. Liu, H. Zeng, and J. Deng. Learning to detect human-object interactions. InIEEE Winter Conf. Appl. Comp. Vis. (WACV), pages 381–389, 2018
2018
-
[6]
Chen, Z.-h
Y . Chen, Z.-h. Ding, Z. Wang, Y . Wang, L. Zhang, and S. Liu. Asynchronous large language model enhanced planner for autonomous driving. InEuropean Conf. Comput. Vis. (ECCV), pages 22–38, 2024
2024
-
[7]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
2024
-
[8]
Devlin, M
J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Confer. North Americ. Chap. Assoc. Comp. Ling.: Human Lang. Tech. (NAACL-HLT), pages 4171–4186, 2019
2019
-
[9]
A. Diko, D. Avola, B. Prenkaj, F. Fontana, and L. Cinque. Se- mantically guided representation learning for action anticipation. In European Conference on Computer Vision, pages 448–466. Springer, 2024
2024
-
[10]
C. Gao, J. Xu, Y . Zou, and J. Huang. DRG: dual relation graph for human-object interaction detection. InEuropean Conf. Comput. Vis. (ECCV), pages 696–712, 2020
2020
-
[11]
Y . Guo, Y . Liu, J. Li, W. Wang, and Q. Jia. Unseen no more: Unlocking the potential of clip for generative zero-shot hoi detection. InProceed- ings of the 32nd ACM International Conference on Multimedia, pages 1711–1720, 2024
2024
-
[12]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [13]
-
[14]
Honnibal, I
M. Honnibal, I. Montani, S. Van Landeghem, and A. Boyd. spaCy: Industrial-strength Natural Language Processing in Python. 2020
2020
-
[15]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022
2022
- [16]
-
[17]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
B. Kim, T. Choi, J. Kang, and H. J. Kim. Uniondet: Union-level detector towards real-time human-object interaction detection. In European Conf. Comput. Vis. (ECCV), pages 498–514, 2020
2020
-
[19]
B. Kim, J. Lee, J. Kang, E.-S. Kim, and H. J. Kim. Hotr: End- to-end human-object interaction detection with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 74–83, 2021
2021
-
[20]
D. Kim, X. Sun, J. Choi, S. Lin, and I. S. Kweon. Detecting human- object interactions with action co-occurrence priors. InEuropean Conf. Comput. Vis. (ECCV), pages 718–736, 2020
2020
-
[21]
S. Kim, D. Jung, and M. Cho. Locality-aware zero-shot human-object interaction detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20190–20200, 2025
2025
-
[22]
Krishna, Y
R. Krishna, Y . Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y . Kalantidis, L.-J. Li, D. A. Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International journal of computer vision, 123:32–73, 2017
2017
-
[23]
Laurenc ¸on, L
H. Laurenc ¸on, L. Tronchon, M. Cord, and V . Sanh. What matters when building vision-language models?Advances in Neural Information Processing Systems, 37:87874–87907, 2025
2025
-
[24]
Q. Lei, B. Wang, and R. Tan. Ez-hoi: Vlm adaptation via guided prompt learning for zero-shot hoi detection.Advances in Neural Information Processing Systems, 37:55831–55857, 2024
2024
-
[25]
T. Lei, F. Caba, Q. Chen, H. Jin, Y . Peng, and Y . Liu. Efficient adaptive human-object interaction detection with concept-guided memory. In IEEE Int. Conf. Comput. Vis. (ICCV), pages 6457–6467, 2023
2023
-
[26]
T. Lei, S. Yin, Y . Peng, and Y . Liu. Exploring conditional multi- modal prompts for zero-shot hoi detection. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024
2024
-
[27]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[29]
L. Li, J. Wei, W. Wang, and Y . Yang. Neural-logic human-object interaction detection.Advances in Neural Information Processing Systems, 36:21158–21171, 2023
2023
-
[30]
Y . Li, X. Liu, H. Lu, S. Wang, J. Liu, J. Li, and C. Lu. Detailed 2d- 3d joint representation for human-object interaction. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 10163–10172, 2020
2020
-
[31]
Y . Li, X. Liu, X. Wu, X. Huang, L. Xu, and C. Lu. Transferable in- teractiveness knowledge for human-object interaction detection.IEEE Trans. Pattern Anal. Mach. Intell., 44(7):3870–3882, 2022
2022
- [32]
-
[33]
Y . Liao, S. Liu, F. Wang, Y . Chen, C. Qian, and J. Feng. PPDM: parallel point detection and matching for real-time human-object interaction detection. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 479–487, 2020
2020
-
[34]
Y . Liao, A. Zhang, M. Lu, Y . Wang, X. Li, and S. Liu. GEN-VLKT: simplify association and enhance interaction understanding for HOI detection. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 20091–20100, 2022
2022
-
[35]
T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft COCO: common objects in context. InEuropean Conf. Comput. Vis. (ECCV) Workshops, pages 740–755, 2014
2014
-
[36]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning. In NeurIPS, 2023
2023
-
[37]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision, pages 38–55. Springer, 2024
2024
-
[38]
Y . Liu, H. Duan, Y . Zhang, B. Li, S. Zhang, W. Zhao, Y . Yuan, J. Wang, C. He, Z. Liu, et al. Mmbench: Is your multi-modal model an all- around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[39]
Y . Liu, J. Yuan, and C. W. Chen. Consnet: Learning consistency graph for zero-shot human-object interaction detection. InACM Multimedia (ACMMM), pages 4235–4243, 2020
2020
-
[40]
Y . Liu, I. E. Zulfikar, J. Luiten, A. Dave, D. Ramanan, B. Leibe, A. Osep, and L. Leal-Taix ´e. Opening up open world tracking. In IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 19023–19033, 2022
2022
-
[41]
J. Luo, W. Ren, W. Jiang, X. Chen, Q. Wang, Z. Han, and H. Liu. Discovering syntactic interaction clues for human-object interaction detection. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 28212–28222, 2024
2024
-
[42]
Z. Luo, W. Xie, S. Kapoor, Y . Liang, M. Cooper, J. C. Niebles, E. Adeli, and F.-F. Li. Moma: Multi-object multi-actor activity parsing. Advances in neural information processing systems, 34:17939–17955, 2021
2021
-
[43]
Y . Mao, J. Deng, W. Zhou, L. Li, Y . Fang, and H. Li. CLIP4HOI: towards adapting CLIP for practical zero-shot HOI detection. InAdv. Neural Inf. Process. Syst. (NeurIPS), 2023
2023
-
[44]
E. V . Mascaro, D. Sliwowski, and D. Lee. Hoi4abot: Human-object interaction anticipation for human intention reading collaborative robots. In7th Annual Conference on Robot Learning
-
[45]
Meinhardt, A
T. Meinhardt, A. Kirillov, L. Leal-Taixe, and C. Feichtenhofer. Track- former: Multi-object tracking with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8844–8854, 2022
2022
-
[46]
MOT16: A Benchmark for Multi-Object Tracking
A. Milan, L. Leal-Taix ´e, I. D. Reid, S. Roth, and K. Schindler. MOT16: A benchmark for multi-object tracking.CoRR, abs/1603.00831, 2016
work page Pith review arXiv 2016
-
[47]
G. A. Miller.WordNet: A Lexical Database for English, volume 38. ACM, 1995
1995
-
[48]
Momeni, M
L. Momeni, M. Caron, A. Nagrani, A. Zisserman, and C. Schmid. Verbs in action: Improving verb understanding in video-language models. InIEEE Int. Conf. Comput. Vis. (ICCV), pages 15533–15545, 2023
2023
-
[49]
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Cand `es, and T. Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393, 2025
work page Pith review arXiv 2025
-
[50]
S. Ning, L. Qiu, Y . Liu, and X. He. HOICLIP: efficient knowledge transfer for HOI detection with vision-language models. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 23507–23517, 2023
2023
-
[51]
J. Park, J. Park, and J. Lee. ViPLO: Vision transformer based pose- conditioned self-loop graph for human-object interaction detection. In IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 17152–17162, 2023
2023
-
[52]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InInt. Conf. Mach. Learn. (ICML), pages 8748–8763, 2021
2021
-
[53]
S. Ren, K. He, R. B. Girshick, and J. Sun. Faster R-CNN: towards real-time object detection with region proposal networks.IEEE Trans. Pattern Anal. Mach. Intell., 39(6):1137–1149, 2017
2017
-
[54]
Shiwa, T
T. Shiwa, T. Kanda, M. Imai, H. Ishiguro, and N. Hagita. How quickly should communication robots respond? InProceedings of the 3rd ACM/IEEE international conference on Human robot interaction, pages 153–160, 2008
2008
-
[55]
Shtedritski, C
A. Shtedritski, C. Rupprecht, and A. Vedaldi. What does CLIP know about a red circle? visual prompt engineering for vlms. InIEEE Int. Conf. Comput. Vis. (ICCV), pages 11953–11963, 2023
2023
-
[56]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Tonini, L
F. Tonini, L. Vaquero, A. Conti, C. Beyan, and E. Ricci. Dynamic scoring with enhanced semantics for training-free human-object in- teraction detection. InProceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 2801–2810, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[58]
Ulutan, A
O. Ulutan, A. S. M. Iftekhar, and B. S. Manjunath. Vsgnet: Spatial attention network for detecting human object interactions using graph convolutions. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 13614–13623, 2020
2020
-
[59]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
S. Wang, Y . Duan, H. Ding, Y . Tan, K. Yap, and J. Yuan. Learning transferable human-object interaction detector with natural language supervision. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 929–938, 2022
2022
-
[61]
T. Wang, T. Yang, M. Danelljan, F. S. Khan, X. Zhang, and J. Sun. Learning human-object interaction detection using interaction points. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 4115–4124, 2020
2020
-
[62]
E. Z. Y . Wu, Y . Li, Y . Wang, and S. Wang. Exploring pose-aware human-object interaction via hybrid learning. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 17815–17825, 2024
2024
-
[63]
M. Wu, J. Gu, Y . Shen, M. Lin, C. Chen, and X. Sun. End-to-end zero- shot HOI detection via vision and language knowledge distillation. In AAAI Conf. Artif. Intell. (AAAI), pages 2839–2846, 2023
2023
-
[64]
M. Wu, Y . Liu, J. Ji, X. Sun, and R. Ji. Toward open-set human object interaction detection. InAAAI Conf. Artif. Intell. (AAAI), pages 6066–6073, 2024
2024
-
[65]
C. Xie, S. Liang, J. Li, Z. Zhang, F. Zhu, R. Zhao, and Y . Wei. Relationlmm: Large multimodal model as open and versatile visual relationship generalist.IEEE Trans. Pattern Anal. Mach. Intell., pages 1–16, 2025
2025
-
[66]
J. Yang, B. Li, A. Zeng, L. Zhang, and R. Zhang. Open-world human- object interaction detection via multi-modal prompts. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 16954–16964, 2024
2024
-
[67]
Z. Yang, X. Liu, D. Ouyang, G. Duan, D. Zhang, T. He, and Y . Li. Towards open-vocabulary HOI detection with calibrated vision- language models and locality-aware queries. InACM Multimedia (ACMMM), pages 1495–1504, 2024
2024
-
[68]
F. Z. Zhang, D. Campbell, and S. Gould. Spatially conditioned graphs for detecting human-object interactions. InIEEE Int. Conf. Comput. Vis. (ICCV), pages 13299–13307, 2021
2021
-
[69]
F. Z. Zhang, D. Campbell, and S. Gould. Efficient two-stage detection of human-object interactions with a novel unary-pairwise transformer. InIEEE Conf. Comput. Vis. Pattern Recog. (CVPR), pages 20072– 20080, 2022
2022
-
[70]
F. Z. Zhang, Y . Yuan, D. Campbell, Z. Zhong, and S. Gould. Exploring predicate visual context in detecting of human-object interactions. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10411–10421, 2023
2023
-
[71]
Zhang, Y
Y . Zhang, Y . Pan, T. Yao, R. Huang, T. Mei, and C.-W. Chen. Exploring structure-aware transformer over interaction proposals for human-object interaction detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19548–19557, 2022
2022
-
[72]
L. Zhao, L. Yuan, B. Gong, Y . Cui, F. Schroff, M. Yang, H. Adam, and T. Liu. Unified visual relationship detection with vision and language models. InIEEE Int. Conf. Comput. Vis. (ICCV), pages 6939–6950, 2023
2023
-
[73]
X. Zhao, Y . Ma, D. Wang, Y . Shen, Y . Qiao, and X. Liu. Revisiting open world object detection.IEEE Trans. Circuits Syst. Video Technol., 34(5):3496–3509, 2024
2024
-
[74]
A. Zunino, J. Cavazza, R. V olpi, P. Morerio, A. Cavallo, C. Becchio, and V . Murino. Predicting intentions from motion: The subject- adversarial adaptation approach.International Journal of Computer Vision, 128:220–239, 2020. Towards Unconstrained Human-Object Interaction Supplementary Material In this document we first analyze the open-vocabulary HOI pa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.