Recognition: unknown
Rhetorical Questions in LLM Representations: A Linear Probing Study
Pith reviewed 2026-05-10 14:09 UTC · model grok-4.3
The pith
Rhetorical questions in LLMs are encoded by multiple linear directions emphasizing different cues rather than a single shared direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
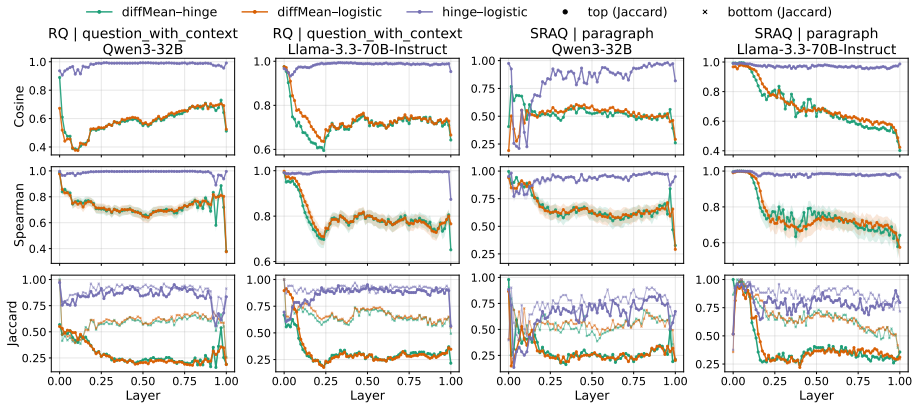
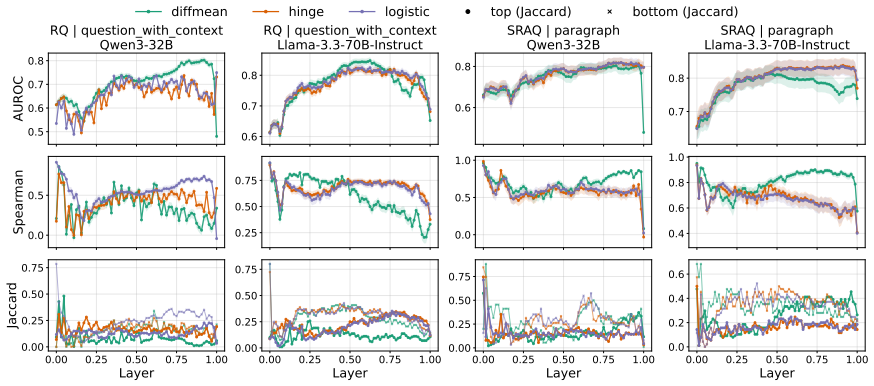
Rhetorical questions are linearly separable from information-seeking questions within datasets and remain detectable under cross-dataset transfer, reaching AUROC around 0.7-0.8. However, transferability does not simply imply a shared representation. Probes trained on different datasets produce different rankings when applied to the same target corpus, with overlap among the top-ranked instances often below 0.2. Qualitative analysis shows that these divergences correspond to distinct rhetorical phenomena: some probes capture discourse-level rhetorical stance embedded in extended argumentation, while others emphasize localized, syntax-driven interrogative acts. Together, these findings suggest
What carries the argument
Linear probes on LLM layer representations, particularly last-token ones, applied across two social-media datasets to assess separability, transfer, and ranking consistency.
Load-bearing premise
The two social-media datasets differ in discourse context in a way that isolates distinct rhetorical phenomena rather than other confounding factors such as topic or length.
What would settle it
A finding of high overlap, say above 0.4, among top-ranked instances across probes from both datasets on a new corpus would suggest more shared representation than the multiple-directions claim allows.
Figures












read the original abstract
Rhetorical questions are asked not to seek information but to persuade or signal stance. How large language models internally represent them remains unclear. We analyze rhetorical questions in LLM representations using linear probes on two social-media datasets with different discourse contexts, and find that rhetorical signals emerge early and are most stably captured by last-token representations. Rhetorical questions are linearly separable from information-seeking questions within datasets, and remain detectable under cross-dataset transfer, reaching AUROC around 0.7-0.8. However, we demonstrate that transferability does not simply imply a shared representation. Probes trained on different datasets produce different rankings when applied to the same target corpus, with overlap among the top-ranked instances often below 0.2. Qualitative analysis shows that these divergences correspond to distinct rhetorical phenomena: some probes capture discourse-level rhetorical stance embedded in extended argumentation, while others emphasize localized, syntax-driven interrogative acts. Together, these findings suggest that rhetorical questions in LLM representations are encoded by multiple linear directions emphasizing different cues, rather than a single shared direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates how large language models internally represent rhetorical questions (as opposed to information-seeking ones) via linear probing. The authors use two social-media datasets differing in discourse context, train probes on last-token representations, and report that rhetorical signals emerge early, are linearly separable within each dataset (AUROC 0.7-0.8), transfer across datasets at similar AUROC levels, yet produce highly divergent rankings of the same target instances (top-k overlap often <0.2). Qualitative inspection attributes the divergences to distinct cues (discourse-level stance vs. localized syntax), leading to the claim that rhetorical questions are encoded by multiple linear directions rather than a single shared one.
Significance. If the central claim holds, the work advances mechanistic interpretability by demonstrating that pragmatic phenomena like rhetorical questions are not captured by one linear direction but by multiple directions sensitive to different cues. The cross-dataset transfer design combined with low overlap and qualitative analysis provides non-circular evidence against a monolithic representation, which is a methodological strength. This has implications for probing methodology and for understanding how LLMs handle stance and persuasion.
major comments (3)
- [§3.1] §3.1 (Datasets): The two social-media datasets are presented as varying primarily in discourse context for rhetorical phenomena, yet no controls, matching, or statistics are reported for topic distribution, question length, syntactic complexity, or other potential confounders. This is load-bearing for the multiple-directions claim, because the observed probe divergences and qualitative distinctions could instead reflect dataset-specific non-rhetorical features.
- [§4.2] §4.2 (Probe Training and Evaluation): While within-dataset AUROC values of 0.7-0.8 and cross-dataset transfer are reported, the manuscript provides no details on model sizes, exact probe architectures, regularization, number of training examples per dataset, or statistical significance tests (e.g., against random or majority baselines). These omissions make it difficult to assess whether the separability and transfer results robustly support the central claim.
- [§5.1] §5.1 (Ranking Overlap Analysis): The top-instance overlap below 0.2 is used to argue against a shared direction, but the value of k, the exact ranking metric, and a comparison to a random baseline or shuffled-probe control are not specified. Without these, the low overlap could be consistent with noise rather than distinct linear directions.
minor comments (2)
- [§5.2] The abstract and §5.2 refer to 'qualitative analysis' showing distinct phenomena, but the manuscript does not report inter-annotator agreement, annotation guidelines, or example counts, which would strengthen the presentation.
- Figure captions (e.g., those showing probe rankings or AUROC curves) could more explicitly state the number of runs, error bars, and exact dataset splits used.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive comments, which identify opportunities to improve the clarity and rigor of our analysis. We address each major comment below and will incorporate revisions to strengthen the manuscript while preserving our core findings on multiple linear directions for rhetorical questions.
read point-by-point responses
-
Referee: §3.1 (Datasets): The two social-media datasets are presented as varying primarily in discourse context for rhetorical phenomena, yet no controls, matching, or statistics are reported for topic distribution, question length, syntactic complexity, or other potential confounders. This is load-bearing for the multiple-directions claim, because the observed probe divergences and qualitative distinctions could instead reflect dataset-specific non-rhetorical features.
Authors: We selected the datasets precisely because they differ in discourse context—one featuring extended argumentative threads and the other shorter conversational exchanges—which underpins our demonstration of cue-sensitive directions. The high cross-dataset transfer AUROC already indicates that the rhetorical signal is not reducible to superficial dataset artifacts. We agree that explicit statistics would improve transparency and will add them in revision: average question lengths, syntactic complexity (dependency parse depth), and topic distributions via LDA. We will also discuss why these are unlikely to drive the ranking divergences, given that qualitative examples isolate rhetorical stance and syntax as the distinguishing factors. revision: partial
-
Referee: §4.2 (Probe Training and Evaluation): While within-dataset AUROC values of 0.7-0.8 and cross-dataset transfer are reported, the manuscript provides no details on model sizes, exact probe architectures, regularization, number of training examples per dataset, or statistical significance tests (e.g., against random or majority baselines). These omissions make it difficult to assess whether the separability and transfer results robustly support the central claim.
Authors: We apologize for the omitted implementation details. The probes were logistic regression classifiers applied to last-token hidden states from Llama-2 (7B and 13B), with L2 regularization (C=1.0). Datasets were split 80/20, yielding roughly 800–1200 training examples each. In the revision we will report these specifications in §4.2 together with bootstrap significance tests confirming that all AUROCs significantly exceed both random (0.5) and majority-class baselines (p<0.01). These additions will make the separability and transfer results fully reproducible and robust. revision: yes
-
Referee: §5.1 (Ranking Overlap Analysis): The top-instance overlap below 0.2 is used to argue against a shared direction, but the value of k, the exact ranking metric, and a comparison to a random baseline or shuffled-probe control are not specified. Without these, the low overlap could be consistent with noise rather than distinct linear directions.
Authors: We will clarify §5.1 by specifying that overlap was computed for k=50 and k=100 using the Jaccard index on the top-ranked instances. We will add a shuffled-probe control that randomly permutes scores within each probe before ranking; the resulting expected overlap is approximately 0.05–0.10. The observed values (<0.2) remain substantially lower, and we will report exact figures and statistical comparisons. This control directly addresses the noise concern and reinforces that the low overlap reflects genuinely distinct linear directions rather than random variation. revision: yes
Circularity Check
No circularity: empirical probe results are independent of input definitions
full rationale
The paper trains linear probes independently on held-out splits of two social-media datasets, measures within-dataset separability and cross-dataset AUROC transfer (0.7-0.8), computes ranking overlap (<0.2), and performs qualitative inspection of captured phenomena. These steps use standard supervised classification and post-hoc analysis; none of the reported quantities are defined in terms of each other or obtained by fitting a parameter to a subset and relabeling the fit as a prediction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and the multi-direction conclusion follows from observed probe divergences rather than reducing to the training data by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes trained on hidden states can recover task-relevant information present in the model's representations.
Forward citations
Cited by 1 Pith paper
-
Exploring Concreteness Through a Figurative Lens
LLMs compress concreteness into a consistent 1D direction in mid-to-late layers that separates literal from figurative noun uses and supports efficient classification plus steering.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925. Guillaume Alain and Yoshua Bengio
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Automatic identification of rhetorical questions. InProceedings of the 53rd An- nual Meeting of the Association for Computational Linguistics and the 7th International Joint Confer- ence on Natural Language Processing (ACL-IJCNLP 2015). Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey
2015
-
[3]
InThe Twelfth International Conference on Learning Representations (ICLR 2024)
Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations (ICLR 2024). Lucy Farnik, Tim Lawson, Conor Houghton, and Lau- rence Aitchison
2024
-
[4]
InPro- ceedings of the 42nd International Conference on Machine Learning (ICML 2025)
Jacobian sparse autoencoders: Sparsify computations, not just activations. InPro- ceedings of the 42nd International Conference on Machine Learning (ICML 2025). Jane Frank
2025
-
[5]
InThe Thirteenth Inter- national Conference on Learning Representations (ICLR 2025)
Scaling and evaluat- ing sparse autoencoders. InThe Thirteenth Inter- national Conference on Learning Representations (ICLR 2025). Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lu- cas Dixon, and Mor Geva
2025
-
[6]
InProceedings of the 41st International Conference on Machine Learning (ICML 2024)
Patchscopes: A unifying framework for inspecting hidden represen- tations of language models. InProceedings of the 41st International Conference on Machine Learning (ICML 2024). Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela ...
2024
-
[7]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Chung-hye Han
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Sparse autoencoders can interpret randomly initialized transformers
Sparse autoencoders can interpret randomly initialized transformers.arXiv preprint arXiv:2501.17727. Eghbal A. Hosseini and Evelina Fedorenko
-
[9]
InProceedings of the 37th International Conference on Neural Infor- mation Processing Systems (NeurIPS 2023)
Large language models implicitly learn to straighten neural sentence trajectories to construct a predictive representation of natural language. InProceedings of the 37th International Conference on Neural Infor- mation Processing Systems (NeurIPS 2023). Oghenevovwe Ikumariegbe, Eduardo Blanco, and Ellen Riloff
2023
-
[10]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025)
Studying rhetorically ambiguous ques- tions. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025). Shiyu Ji, Farnoosh Hashemi, Joice Chen, Juanwen Pan, Weicheng Ma, Hefan Zhang, Sophia Pan, Ming Cheng, Shubham Mohole, Saeed Hassanpour, Soroush V osoughi, and Michael Macy
2025
-
[11]
InFind- ings of the Association for Computational Linguistics: EMNLP 2025 (Findings of EMNLP 2025)
A gen- eralizable rhetorical strategy annotation model using LLM-based debate simulation and labelling. InFind- ings of the Association for Computational Linguistics: EMNLP 2025 (Findings of EMNLP 2025). Daniel Jurafsky, Rebecca Bates, Noah Coccaro, Rachel Martin, Marie Meteer, Klaus Ries, Elizabeth Shriberg, Andreas Stolcke, Paul Taylor, and Carol Van Ess-Dykema
2025
-
[12]
InProceedings of the 25th Annual Meeting of the Special Interest Group on Dis- course and Dialogue (SIGDIAL 2024)
Question type pre- diction in natural debate. InProceedings of the 25th Annual Meeting of the Special Interest Group on Dis- course and Dialogue (SIGDIAL 2024). Joshua Lee, Wyatt Fong, Alexander Le, Sur Shah, Kevin Han, and Kevin Zhu
2024
-
[13]
InFirst Conference on Language Modeling (COLM 2024)
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InFirst Conference on Language Modeling (COLM 2024). Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
2024
-
[14]
Shereen Oraby, Vrindavan Harrison, Amita Misra, Ellen Riloff, and Marilyn Walker
Locating and editing factual associ- ations in gpt.Proceedings of the 36th International Conference on Neural Information Processing Sys- tems (NeurIPS 2022). Shereen Oraby, Vrindavan Harrison, Amita Misra, Ellen Riloff, and Marilyn Walker
2022
-
[15]
InProceedings of the 18th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL 2017)
Are you serious?: Rhetorical questions and sarcasm in social media dia- log. InProceedings of the 18th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL 2017). Kiho Park, Yo Joong Choe, and Victor Veitch
2017
-
[16]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The linear representation hypothesis and the ge- ometry of large language models.arXiv preprint arXiv:2311.03658. Jingyi Qiu, Hong Chen, and Zongyi Li
work page internal anchor Pith review arXiv
-
[17]
Counter- factual llm-based framework for measuring rhetorical style.arXiv preprint arXiv:2512.19908. Alex Reinhart, Ben Markey, Michael Laudenbach, Kachatad Pantusen, Ronald Yurko, Gordon Wein- berg, and David West Brown
-
[18]
In Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (ACL 2024)
Steer- ing llama 2 via contrastive activation addition. In Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (ACL 2024). Richard M Roberts and Roger J Kreuz
2024
-
[19]
InPro- ceedings of the 42nd International Conference on Machine Learning (ICML 2025)
Layer by layer: Uncovering hidden representations in language models. InPro- ceedings of the 42nd International Conference on Machine Learning (ICML 2025). Džemal Špago
2025
-
[20]
Steering Language Models With Activation Engineering
Steering language mod- els with activation engineering.arXiv preprint arXiv:2308.10248. Daniel Vennemeyer, Phan Anh Duong, Tiffany Zhan, and Tianyu Jiang
work page internal anchor Pith review arXiv
-
[21]
Sycophancy is not one thing: Causal separation of sycophantic behaviors in llms. arXiv preprint arXiv:2509.21305. Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, and 1 others
-
[22]
InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (ACL 2025)
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (ACL 2025). An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv,...
2025
-
[23]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Yazhou Zhang, Chunwang Zou, Zheng Lian, Prayag Tiwari, and Jing Qin
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
We evaluate these variants across layers for Qwen3-32B and Llama-3.3-70B-Instruct on RQ (question_with_context) and SRAQ (para- graph)
In addition to mean pooling over all tokens and standard last-token pooling, we consider pooling over the last 5 or 10 tokens and mean pooling restricted to the question span only (question tokens). We evaluate these variants across layers for Qwen3-32B and Llama-3.3-70B-Instruct on RQ (question_with_context) and SRAQ (para- graph). On RQ, pooling over th...
2025
-
[25]
On SRAQ, perfor- mance is more stable across the network, remain- ing in a relatively narrow range between 67.8 and 69.9
On RQ, AUROC improves gradually in the earlier and middle lay- ers, reaching a peak of 64.8 at layer 17, and then declines toward later layers. On SRAQ, perfor- mance is more stable across the network, remain- ing in a relatively narrow range between 67.8 and 69.9. Overall, these results remain below those of the decoder-only models reported in the main t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.