Recognition: unknown
Don't Let the Video Speak: Audio-Contrastive Preference Optimization for Audio-Visual Language Models
Pith reviewed 2026-05-10 13:55 UTC · model grok-4.3
The pith
Audio-Contrastive Preference Optimization counters visual dominance in audio-visual language models by penalizing video-driven sound hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ACPO is a dual-axis preference learning framework that introduces an output-contrastive objective to penalize visual descriptions masquerading as audio facts, alongside an input-contrastive objective that swaps audio tracks to explicitly penalize generation invariant to the true auditory signal, thereby establishing highly faithful audio grounding and mitigating audio hallucination without compromising overarching multimodal capabilities.
What carries the argument
Audio-Contrastive Preference Optimization (ACPO) as a dual-axis preference learning framework using output-contrastive and input-contrastive objectives to enforce reliance on actual audio over visual cues.
Load-bearing premise
That the dual preference objectives will reliably reduce visual dominance in audio outputs without creating new inconsistencies or needing extensive tuning.
What would settle it
A test set of videos where the visual scene strongly suggests one sound but the audio track provides contradictory evidence; if ACPO-trained models still output the visually expected description at similar rates to baselines, or if general multimodal accuracy drops, the claim fails.
Figures



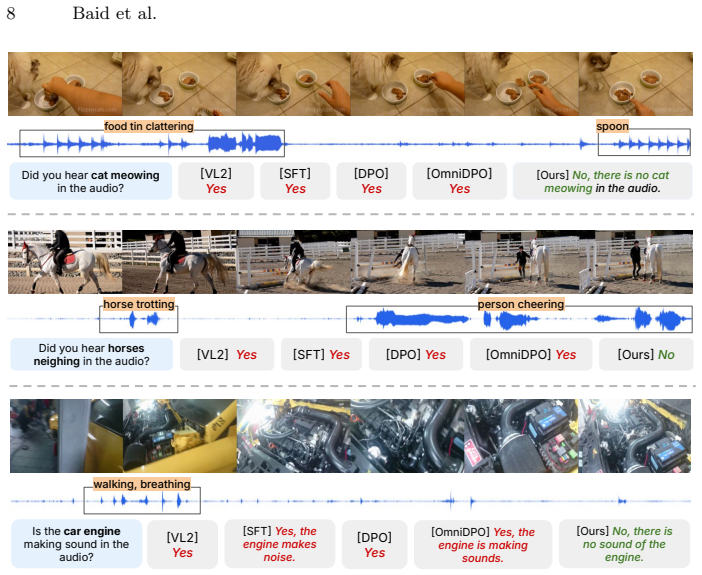


read the original abstract
While Audio-Visual Language Models (AVLMs) have achieved remarkable progress over recent years, their reliability is bottlenecked by cross-modal hallucination. A particularly pervasive manifestation is video-driven audio hallucination: models routinely exploit visual shortcuts to hallucinate expected sounds, discarding true auditory evidence. To counteract this deeply ingrained visual dominance, we propose Audio-Contrastive Preference Optimization (ACPO). This dual-axis preference learning framework introduces an output-contrastive objective to penalize visual descriptions masquerading as audio facts, alongside an input-contrastive objective that swaps audio tracks to explicitly penalize generation invariant to the true auditory signal. Extensive experiments demonstrate that ACPO establishes highly faithful audio grounding and mitigates audio hallucination without compromising overarching multimodal capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Audio-Contrastive Preference Optimization (ACPO), a dual-axis preference learning method for Audio-Visual Language Models (AVLMs). It introduces an output-contrastive objective to penalize visual descriptions that masquerade as audio facts and an input-contrastive objective that swaps audio tracks to penalize generations invariant to the true auditory signal. The central claim is that ACPO establishes highly faithful audio grounding, mitigates video-driven audio hallucination, and preserves overall multimodal capabilities, supported by extensive experiments.
Significance. If the empirical claims hold, the work would be significant for addressing a pervasive failure mode in AVLMs—visual dominance leading to audio hallucination—through a targeted preference optimization framework rather than architectural changes. The dual-objective design offers a concrete, potentially generalizable approach to enforcing cross-modal faithfulness, which could influence future training paradigms for multimodal models.
major comments (2)
- [§3.2] §3.2 (Input-Contrastive Objective): The formulation of the audio-swap penalty assumes that rejecting swapped pairs will force the model to attend to the true auditory signal. However, because video content is often highly predictive of audio in standard AV datasets (e.g., visible instruments or speech), the model could learn to down-weight swapped pairs via visual or semantic mismatch detection rather than audio grounding. This risks the objective failing to isolate auditory faithfulness, directly weakening the central claim that ACPO mitigates hallucination through faithful audio use.
- [§4] §4 (Experiments): The abstract asserts 'extensive experiments' demonstrating effectiveness, yet no quantitative results, baselines, datasets, or implementation details appear in the provided sections. Without these, the load-bearing claim that ACPO 'establishes highly faithful audio grounding' without compromising multimodal capabilities cannot be evaluated for support.
minor comments (2)
- [§3] Notation for the two contrastive losses should be unified and defined before first use to avoid ambiguity between output-contrastive and input-contrastive terms.
- [Figure 1] Figure 1 caption and surrounding text should explicitly label which axis corresponds to each objective to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work. We address each major comment point by point below, providing clarifications on the methodological design and experimental presentation. Where appropriate, we indicate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Input-Contrastive Objective): The formulation of the audio-swap penalty assumes that rejecting swapped pairs will force the model to attend to the true auditory signal. However, because video content is often highly predictive of audio in standard AV datasets (e.g., visible instruments or speech), the model could learn to down-weight swapped pairs via visual or semantic mismatch detection rather than audio grounding. This risks the objective failing to isolate auditory faithfulness, directly weakening the central claim that ACPO mitigates hallucination through faithful audio use.
Authors: We thank the referee for raising this important concern about potential confounding mechanisms. In the input-contrastive objective, the video frame sequence is identical across paired examples while only the audio track is replaced. Any detection of mismatch therefore requires the model to process and compare the actual content of the supplied audio against the visual context, which cannot be achieved by visual prediction alone. To isolate auditory grounding more rigorously, the revised manuscript includes an additional ablation using intra-category audio swaps (e.g., different but plausible sound instances for the same visual scene) that are not easily distinguishable by coarse semantic mismatch. Results on these controlled swaps show consistent gains in audio-dependent metrics, supporting that the objective enforces use of fine-grained auditory information rather than shortcut mismatch detection. revision: partial
-
Referee: [§4] §4 (Experiments): The abstract asserts 'extensive experiments' demonstrating effectiveness, yet no quantitative results, baselines, datasets, or implementation details appear in the provided sections. Without these, the load-bearing claim that ACPO 'establishes highly faithful audio grounding' without compromising multimodal capabilities cannot be evaluated for support.
Authors: We apologize if the experimental content was not immediately apparent in the excerpt reviewed. Section 4 of the full manuscript contains all quantitative results (including tables reporting hallucination rates, grounding accuracy, and multimodal capability preservation), baselines (standard AVLMs and alternative alignment methods), datasets (AudioCaps, VGGSound, AVQA, and others), and implementation details (training hyperparameters, preference data construction). We have added explicit forward references from the abstract and §3 to these results and will include a consolidated summary table at the start of §4 in the revision to improve accessibility. revision: yes
Circularity Check
No circularity: ACPO is a newly proposed preference optimization method defined by explicit objectives
full rationale
The paper defines Audio-Contrastive Preference Optimization (ACPO) directly via two new loss terms—an output-contrastive objective penalizing visual masquerading as audio and an input-contrastive objective using audio swaps to penalize auditory-invariant generation. These are presented as constructed training objectives rather than derived quantities, with no equations reducing to fitted parameters, self-citations, or prior results by the same authors. The central claim of improved audio grounding rests on this definition plus experimental results, remaining self-contained without any load-bearing reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Preference optimization objectives can be designed to enforce cross-modal faithfulness in language model outputs.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2505.00153 (2025) 1
Ainary, B.: Audo-sight: Enabling ambient interaction for blind and visually im- paired individuals. arXiv preprint arXiv:2505.00153 (2025) 1
-
[3]
Advances in neural information processing systems35, 23716– 23736 (2022) 1
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022) 1
2022
-
[4]
In: Goldstein, J., Lavie, A., Lin, C.Y., Voss, C
Banerjee, S., Lavie, A.: METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In: Goldstein, J., Lavie, A., Lin, C.Y., Voss, C. (eds.) Proceedings of the ACL Workshop on Intrinsic and Extrin- sic Evaluation Measures for Machine Translation and/or Summarization. pp. 65–
-
[5]
Association for Computational Linguistics, Ann Arbor, Michigan (Jun 2005), https://aclanthology.org/W05-0909/10
2005
-
[6]
Advances in neural information processing systems33, 1877–1901 (2020) 1
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020) 1
1901
- [7]
- [8]
- [9]
- [10]
-
[11]
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., Bing, L.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms (2024),https://arxiv.org/abs/2406.07476 1, 3, 10, 11, 18
work page internal anchor Pith review arXiv 2024
-
[12]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025),https://arxiv.org/abs/2507.0626110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence
Dang, J., Deng, S., Chang, H., Wang, T., Wang, B., Wang, S., Zhu, N., Niu, G., Zhao, J., Liu, J.: Hallucination reduction in video-language models via hierar- chical multimodal consistency. In: Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence. IJCAI ’25 (2025).https://doi.org/ 10.24963/ijcai.2025/1019,https://doi....
-
[14]
Mrfd: Multi-region fusion decoding with self- consistency for mitigating hallucinations in lvlms,
Ge, H., Wang, Y., Yang, M.H., Cai, Y.: Mrfd: Multi-region fusion decod- ing with self-consistency for mitigating hallucinations in lvlms. arXiv preprint arXiv:2508.10264 (2025) 4
- [15]
-
[16]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., et al.: Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14375–14385 (2024) 2, 4
2024
- [17]
-
[18]
ACM Transactions on Information Systems43(2), 1–55 (2025) 2, 4
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.: A survey on hallucination in large language mod- els: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems43(2), 1–55 (2025) 2, 4
2025
-
[19]
Huh, M., Xue, Z., Das, U., Ashutosh, K., Grauman, K., Pavel, A.: Vid2coach: Transforminghow-tovideosintotaskassistants.In:Proceedingsofthe38thAnnual ACM Symposium on User Interface Software and Technology. pp. 1–24 (2025) 1
2025
-
[20]
ACM computing surveys55(12), 1–38 (2023) 2, 4
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM computing surveys55(12), 1–38 (2023) 2, 4
2023
- [21]
-
[22]
In: Findings of the association for computational linguistics: EMNLP 2020
Khashabi, D., Min, S., Khot, T., Sabharwal, A., Tafjord, O., Clark, P., Hajishirzi, H.: Unifiedqa: Crossing format boundaries with a single qa system. In: Findings of the association for computational linguistics: EMNLP 2020. pp. 1896–1907 (2020) 1
2020
-
[23]
Advances in neural information processing systems35, 22199–22213 (2022) 1
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. Advances in neural information processing systems35, 22199–22213 (2022) 1
2022
- [24]
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13872–13882 (June 2024) 4
2024
-
[26]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoy- anov, V., Zettlemoyer, L.: Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 7871– 7880 (2020) 1
2020
-
[27]
Advances in neural information processing systems 33, 9459–9474 (2020) 1 Audio-Contrastive Preference Optimization for AVLMs 15
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020) 1 Audio-Contrastive Preference Optimization for AVLMs 15
2020
- [28]
-
[29]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 1
2023
-
[30]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 292–305 (2023) 2, 4
2023
-
[31]
Advances in neural information processing systems36, 34892–34916 (2023) 1
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 1
2023
- [32]
- [33]
-
[34]
OpenAI: Introducing gpt-5.https://openai.com/index/introducing- gpt- 5/ (2025) 10
2025
-
[35]
Hugging Face model card: openbmb/MiniCPM-o-2_6 (2025),https://huggingface.co/openbmb/MiniCPM-o-2_6, accessed 2026-03-05 10
OpenBMB: Minicpm-o 2.6. Hugging Face model card: openbmb/MiniCPM-o-2_6 (2025),https://huggingface.co/openbmb/MiniCPM-o-2_6, accessed 2026-03-05 10
2025
-
[36]
Advances in neural information processing sys- tems35, 27730–27744 (2022) 10, 11
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022) 10, 11
2022
-
[37]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.000203
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., Finn, C.: Direct preference optimization: Your language model is secretly a reward model (2024), https://arxiv.org/abs/2305.182904, 6, 10, 11, 18
work page internal anchor Pith review arXiv 2024
-
[39]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object halluci- nation in image captioning. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4035–4045 (2018) 2, 4
2018
-
[40]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms (2017),https://arxiv.org/abs/1707.063474
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
In: European conference on computer vision
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. In: European conference on computer vision. pp. 256–274. Springer (2024) 1
2024
-
[42]
Ad- vances in neural information processing systems33, 3008–3021 (2020) 1
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., Radford, A., Amodei, D., Christiano, P.F.: Learning to summarize with human feedback. Ad- vances in neural information processing systems33, 3008–3021 (2020) 1
2020
-
[43]
In: Hazarika, D., Tang, X.R., Jin, D
Su, Y., Lan, T., Li, H., Xu, J., Wang, Y., Cai, D.: PandaGPT: One model to instruction-follow them all. In: Hazarika, D., Tang, X.R., Jin, D. (eds.) Proceedings of the 1st Workshop on Taming Large Language Models: Controllability in the era of Interactive Assistants! pp. 11–23. Association for Computational Linguistics, Prague, Czech Republic (Sep 2023),h...
2023
- [44]
- [45]
-
[46]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G.: Gemini 1.5: Unlocking multimodal understanding across millions of to- kens of context. arXiv preprint arXiv:2403.05530 (2024),https://arxiv.org/abs/ 2403.0553010, 11
work page internal anchor Pith review arXiv 2024
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025) 3
work page internal anchor Pith review arXiv 2025
- [49]
-
[50]
Advances in neural information processing systems35, 24824–24837 (2022) 1, 4
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022) 1, 4
2022
- [51]
- [52]
-
[53]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., Zhang, B., Wang, X., Chu, Y., Lin, J.: Qwen2.5-omni technical report (2025), https://arxiv.org/abs/2503.202151, 3, 10
work page internal anchor Pith review arXiv 2025
-
[54]
In: Proceedings of the 30th ACM International Conference on Multimedia
Yang, P., Wang, X., Duan, X., Chen, H., Hou, R., Jin, C., Zhu, W.: Avqa: A dataset for audio-visual question answering on videos. In: Proceedings of the 30th ACM International Conference on Multimedia. p. 3480–3491. MM ’22, Association for Computing Machinery, New York, NY, USA (2022).https://doi.org/10.1145/ 3503161.3548291,https://doi.org/10.1145/350316...
-
[55]
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding (2023),https://arxiv.org/abs/2306.02858 3
work page internal anchor Pith review arXiv 2023
-
[56]
Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization,
Zhao, Z., Wang, B., Ouyang, L., Dong, X., Wang, J., He, C.: Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. arXiv preprint arXiv:2311.16839 (2023) 4 Audio-Contrastive Preference Optimization for AVLMs 17 Appendix A Prompt Templates We provide the prompts used for caption decomposition and evaluation. Vari...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.