Recognition: unknown
ROSE: Retrieval-Oriented Segmentation Enhancement
Pith reviewed 2026-05-10 13:35 UTC · model grok-4.3
The pith
A retrieval framework augments multimodal segmentation models with web data to handle novel and emerging entities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
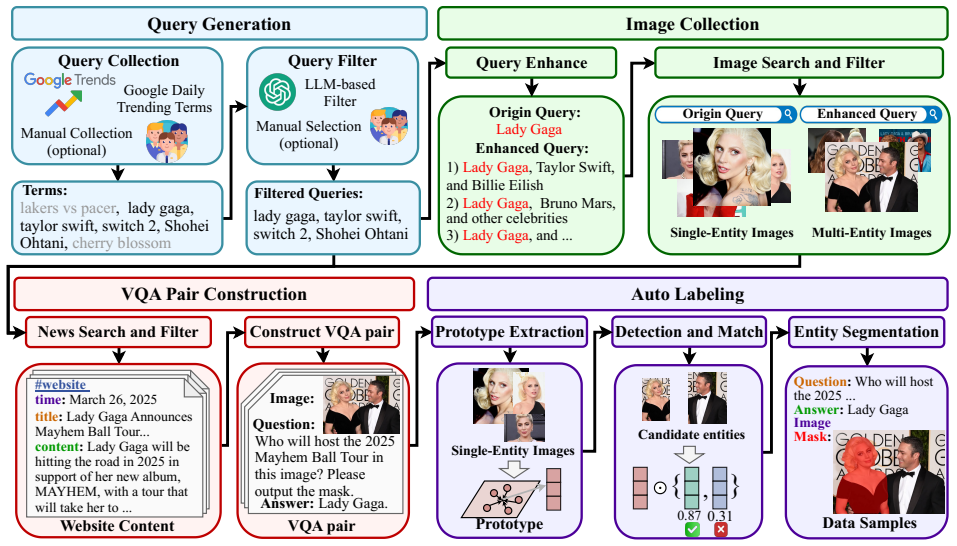
ROSE is a plug-and-play framework that augments any MLLM-based segmentation model through four components: an Internet Retrieval-Augmented Generation module that fetches real-time web information from user multimodal inputs, a Textual Prompt Enhancer that supplies up-to-date knowledge for emerging entities, a Visual Prompt Enhancer that supplies internet-sourced images to compensate for lack of exposure to novel entities, and a WebSense module that decides when retrieval is required, yielding large gains on the NEST benchmark.
What carries the argument
ROSE framework with its Internet Retrieval-Augmented Generation module, Textual Prompt Enhancer, Visual Prompt Enhancer, and WebSense decision module that together integrate retrieved web text and images into model prompts.
If this is right
- ROSE can be attached to existing models such as LISA to improve their handling of novel entities without retraining.
- The NEST benchmark supplies a standardized test for measuring segmentation performance on objects outside model knowledge.
- WebSense preserves efficiency by selectively triggering retrieval only for inputs that need external information.
- On the NEST benchmark ROSE outperforms a Gemini-2.0 Flash retrieval baseline by 19.2 gIoU.
Where Pith is reading between the lines
- The same retrieval-plus-prompt structure could be adapted to other multimodal tasks such as detection or captioning of new entities.
- In deployed systems the approach would need additional checks on retrieval source quality to prevent propagation of outdated or incorrect web data.
- Models might eventually embed similar retrieval mechanisms internally rather than relying on an external plug-in layer.
Load-bearing premise
The automated news-based benchmark and internet retrieval results are representative of real novel and emerging entities that users will encounter, and the WebSense module reliably avoids harmful retrieval.
What would settle it
If applying ROSE to a collection of real user images containing entities unknown to the base model and absent from current web sources produces no segmentation improvement or introduces errors, the performance claim would be falsified.
Figures



read the original abstract
Existing segmentation models based on multimodal large language models (MLLMs), such as LISA, often struggle with novel or emerging entities due to their inability to incorporate up-to-date knowledge. To address this challenge, we introduce the Novel Emerging Segmentation Task (NEST), which focuses on segmenting (i) novel entities that MLLMs fail to recognize due to their absence from training data, and (ii) emerging entities that exist within the model's knowledge but demand up-to-date external information for accurate recognition. To support the study of NEST, we construct a NEST benchmark using an automated pipeline that generates news-related data samples for comprehensive evaluation. Additionally, we propose ROSE: Retrieval-Oriented Segmentation Enhancement, a plug-and-play framework designed to augment any MLLM-based segmentation model. ROSE comprises four key components. First, an Internet Retrieval-Augmented Generation module is introduced to employ user-provided multimodal inputs to retrieve real-time web information. Then, a Textual Prompt Enhancer enriches the model with up-to-date information and rich background knowledge, improving the model's perception ability for emerging entities. Furthermore, a Visual Prompt Enhancer is proposed to compensate for MLLMs' lack of exposure to novel entities by leveraging internet-sourced images. To maintain efficiency, a WebSense module is introduced to intelligently decide when to invoke retrieval mechanisms based on user input. Experimental results demonstrate that ROSE significantly boosts performance on the NEST benchmark, outperforming a strong Gemini-2.0 Flash-based retrieval baseline by 19.2 in gIoU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Novel Emerging Segmentation Task (NEST) for segmenting novel entities absent from MLLM training data and emerging entities requiring up-to-date external knowledge. It constructs a NEST benchmark via an automated pipeline generating news-related samples and proposes ROSE, a plug-and-play framework augmenting MLLM segmentation models (e.g., LISA) with an Internet Retrieval-Augmented Generation module, Textual Prompt Enhancer, Visual Prompt Enhancer, and WebSense decision module. The central empirical claim is that ROSE outperforms a strong Gemini-2.0 Flash-based retrieval baseline by 19.2 gIoU on the NEST benchmark.
Significance. If the performance gains hold after addressing benchmark validity, this work would be a useful engineering contribution to MLLM-based segmentation by enabling real-time knowledge retrieval for entities outside training distributions. The plug-and-play design and selective retrieval via WebSense are practical strengths that could integrate with existing models without full retraining.
major comments (2)
- [Abstract] Abstract and benchmark construction: The NEST benchmark is generated by an automated pipeline focused on news-related samples, while ROSE's core mechanism is internet retrieval (also news-heavy). This creates a plausible distribution match or leakage that could inflate the reported 19.2 gIoU gain; the improvement may not generalize to truly novel entities (e.g., obscure technical terms or non-news visual concepts) outside the news domain. A non-news hold-out evaluation is required to support the central claim.
- [Experimental Results] Method and experiments: No ablation studies, error bars, or quantitative evaluation of the WebSense module (e.g., false-positive rate on benign inputs or decision accuracy) are described. These details are load-bearing for verifying that the 19.2 gIoU improvement stems from the proposed components rather than benchmark artifacts or untested retrieval invocation.
minor comments (1)
- [Abstract] The four components of ROSE are listed but would benefit from an accompanying diagram or pseudocode to clarify their interactions and data flow.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract and benchmark construction: The NEST benchmark is generated by an automated pipeline focused on news-related samples, while ROSE's core mechanism is internet retrieval (also news-heavy). This creates a plausible distribution match or leakage that could inflate the reported 19.2 gIoU gain; the improvement may not generalize to truly novel entities (e.g., obscure technical terms or non-news visual concepts) outside the news domain. A non-news hold-out evaluation is required to support the central claim.
Authors: We acknowledge the concern regarding potential overlap between the news-centric NEST benchmark and the web retrieval process. News data was chosen because it naturally captures emerging entities that require timely external knowledge, which is a core motivation for NEST. Nevertheless, to demonstrate broader applicability, we will add a non-news hold-out evaluation set in the revised manuscript. This set will include samples involving obscure technical terms and non-news visual concepts, allowing us to report performance on entities outside the news domain and confirm that ROSE's gains are not artifacts of domain match. revision: yes
-
Referee: [Experimental Results] Method and experiments: No ablation studies, error bars, or quantitative evaluation of the WebSense module (e.g., false-positive rate on benign inputs or decision accuracy) are described. These details are load-bearing for verifying that the 19.2 gIoU improvement stems from the proposed components rather than benchmark artifacts or untested retrieval invocation.
Authors: We agree that these analyses are essential for isolating the contribution of each component. The current manuscript emphasizes end-to-end gains on NEST, but we will expand the experiments section in the revision to include: (1) ablation studies removing or altering each ROSE module (Internet RAG, Textual Prompt Enhancer, Visual Prompt Enhancer, and WebSense), (2) error bars computed over multiple runs with different random seeds, and (3) quantitative metrics for WebSense, such as decision accuracy, false-positive rate on inputs that do not require retrieval, and comparison against always-retrieve or never-retrieve baselines. These additions will clarify that the reported improvements arise from the proposed design rather than unexamined factors. revision: yes
Circularity Check
No circularity: empirical framework evaluated on constructed benchmark
full rationale
The paper introduces the NEST task and benchmark via an automated news-related data pipeline, then describes ROSE as a plug-and-play retrieval framework with four components (Internet Retrieval-Augmented Generation, Textual Prompt Enhancer, Visual Prompt Enhancer, WebSense). Performance is reported solely as experimental gIoU gains on the NEST benchmark, with no equations, fitted parameters, self-definitional reductions, or load-bearing self-citations that equate outputs to inputs by construction. The central claim remains an empirical outcome of external retrieval augmentation rather than a tautological derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MLLMs have fixed knowledge cutoffs and cannot recognize novel or emerging entities without external input
- domain assumption Internet retrieval can be performed safely and efficiently on user-provided multimodal inputs
invented entities (2)
-
NEST benchmark
no independent evidence
-
WebSense module
no independent evidence
Forward citations
Cited by 1 Pith paper
-
From Web to Pixels: Bringing Agentic Search into Visual Perception
WebEye benchmark and Pixel-Searcher agent enable visual perception tasks by using web search to resolve object identities before precise localization or answering.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
S ´ebastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[3]
Langchain: Building applications with large language models
Harrison Chase. Langchain: Building applications with large language models. 2022. 5, 6
2022
-
[4]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR, 2024. 2, 3
2024
-
[5]
Vision-language transformer and query generation for referring segmentation
Henghui Ding, Chang Liu, Suchen Wang, and Xudong Jiang. Vision-language transformer and query generation for referring segmentation. InICCV, 2021. 3, 6
2021
-
[6]
VLT: Vision-language transformer and query generation for referring segmentation.IEEE TPAMI, 45(6), 2023
Henghui Ding, Chang Liu, Suchen Wang, and Xudong Jiang. VLT: Vision-language transformer and query generation for referring segmentation.IEEE TPAMI, 45(6), 2023. 3
2023
-
[7]
MeViS: A multi-modal dataset for referring motion expression video segmentation.IEEE TPAMI, 2025
Henghui Ding, Chang Liu, Shuting He, Kaining Ying, Xudong Jiang, Chen Change Loy, and Yu-Gang Jiang. MeViS: A multi-modal dataset for referring motion expression video segmentation.IEEE TPAMI, 2025. 3
2025
-
[8]
Multimodal referring segmentation: A survey.arXiv preprint arXiv:2508.00265, 2025
Henghui Ding, Song Tang, Shuting He, Chang Liu, Zuxuan Wu, and Yu-Gang Jiang. Multimodal referring segmentation: A survey.arXiv preprint arXiv:2508.00265, 2025. 3
-
[9]
GREx: Generalized referring expression segmentation, comprehension, and generation.IJCV, 2026
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, and Yu-Gang Jiang. GREx: Generalized referring expression segmentation, comprehension, and generation.IJCV, 2026. 3
2026
-
[10]
A survey on rag meeting llms: Towards retrieval-augmented large language models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024. 3
2024
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Retrieval augmented language model pre- training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre- training. InICML, 2020. 3
2020
-
[13]
Segmentation from natural language expressions
Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from natural language expressions. InECCV,
-
[14]
Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory
Ziniu Hu, Ahmet Iscen, Chen Sun, Zirui Wang, Kai- Wei Chang, Yizhou Sun, Cordelia Schmid, David A Ross, and Alireza Fathi. Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory. InCVPR, 2023. 3
2023
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Ultralytics yolov8, 2023
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Ultralytics yolov8, 2023. 3, 6
2023
-
[17]
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara L. Berg. Referitgame: Referring to objects in photographs of natural scenes. InEMNLP, 2014. 6, 7
2014
-
[18]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InICCV, 2023. 4, 6
2023
-
[19]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InCVPR, 2024. 2, 3, 6, 7, 8
2024
-
[20]
Internet-augmented language models through few-shot prompting for open-domain question answering,
Angeliki Lazaridou, Elena Gribovskaya, Wojciech Stokowiec, and Nikolai Grigorev. Internet-augmented language models through few-shot prompting for open-domain question answering.arXiv preprint arXiv:2203.05115, 2022. 3
-
[21]
Searchlvlms: A plug-and-play framework for augmenting large vision-language models by searching up- to-date internet knowledge
Chuanhao Li, Zhen Li, Chenchen Jing, Shuo Liu, Wenqi Shao, Yuwei Wu, Ping Luo, Yu Qiao, and Kaipeng Zhang. Searchlvlms: A plug-and-play framework for augmenting large vision-language models by searching up- to-date internet knowledge. InNeurIPS, 2024. 3
2024
-
[22]
Referring image segmentation via recurrent refinement networks
Ruiyu Li, Kaican Li, Yi-Chun Kuo, Michelle Shu, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia. Referring image segmentation via recurrent refinement networks. InCVPR,
-
[23]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Recurrent multimodal interaction for referring image segmentation
Chenxi Liu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, and Alan Yuille. Recurrent multimodal interaction for referring image segmentation. InICCV, 2017. 3
2017
-
[25]
GRES: generalized referring expression segmentation
Chang Liu, Henghui Ding, and Xudong Jiang. GRES: generalized referring expression segmentation. InCVPR,
-
[26]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2024. 2, 3, 7
2024
-
[27]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review arXiv
-
[28]
Reasoning to attend: Try to understand how<SEG>token works
Rui Qian, Xin Yin, and Dejing Dou. Reasoning to attend: Try to understand how<SEG>token works. InCVPR, 2025. 2, 3, 6, 7, 8
2025
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, 9 Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021. 3, 6
2021
-
[30]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
-
[31]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Cris: Clip-driven referring image segmentation
Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. InCVPR, 2022. 7
2022
-
[33]
See say and segment: Teaching lmms to overcome false premises
Tsung-Han Wu, Giscard Biamby, David Chan, Lisa Dunlap, Ritwik Gupta, Xudong Wang, Joseph E Gonzalez, and Trevor Darrell. See say and segment: Teaching lmms to overcome false premises. InCVPR, 2024. 2, 3, 6, 7
2024
-
[34]
Retrieval-augmented multimodal language modeling
Michihiro Yasunaga, Armen Aghajanyan, Weijia Shi, Rich James, Jure Leskovec, Percy Liang, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Retrieval-augmented multimodal language modeling. InICML, 2022. 3
2022
-
[35]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InECCV, 2016. 6, 7
2016
-
[36]
Generate rather than retrieve: Large language models are strong context generators
Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, and Meng Jiang. Generate rather than retrieve: Large language models are strong context generators. InICLR,
-
[37]
Segment everything everywhere all at once.NeurIPS, 36, 2024
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once.NeurIPS, 36, 2024. 7 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.