Recognition: 2 theorem links
· Lean TheoremFrom Web to Pixels: Bringing Agentic Search into Visual Perception
Pith reviewed 2026-05-13 05:41 UTC · model grok-4.3
The pith
Pixel-Searcher resolves hidden object identities from external sources before localizing them at the pixel level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
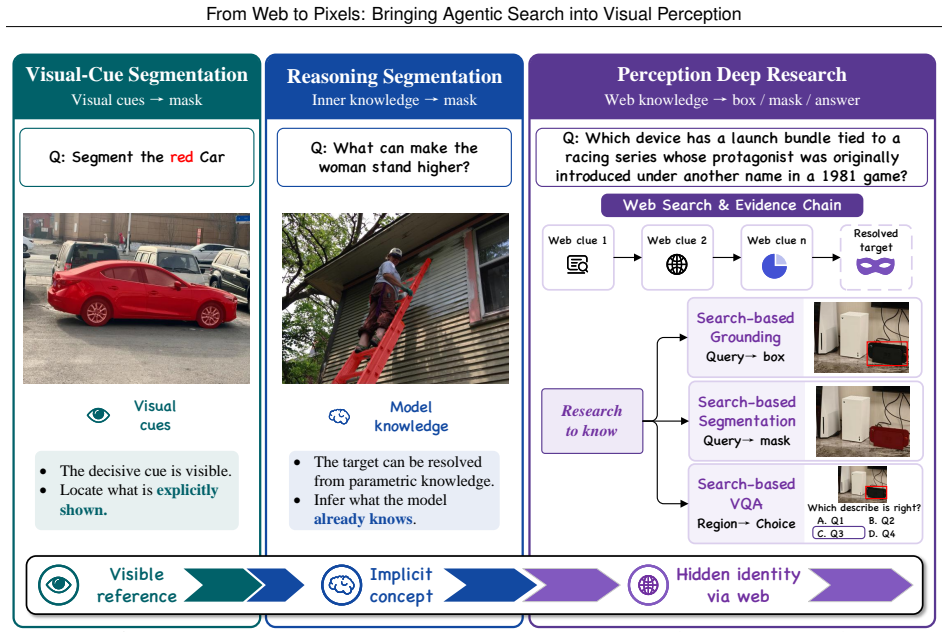
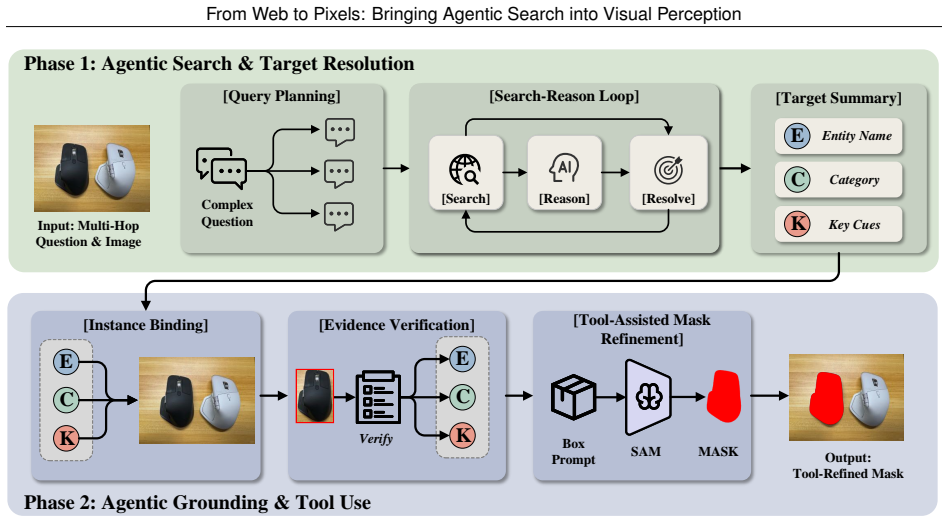
The paper establishes Perception Deep Research as the setting where visible objects require external resolution before localization, presents the WebEye benchmark with verifiable evidence and annotations, and demonstrates that the Pixel-Searcher agentic workflow outperforms other open-source methods on search-based grounding, segmentation, and VQA by resolving identities and binding them visually.
What carries the argument
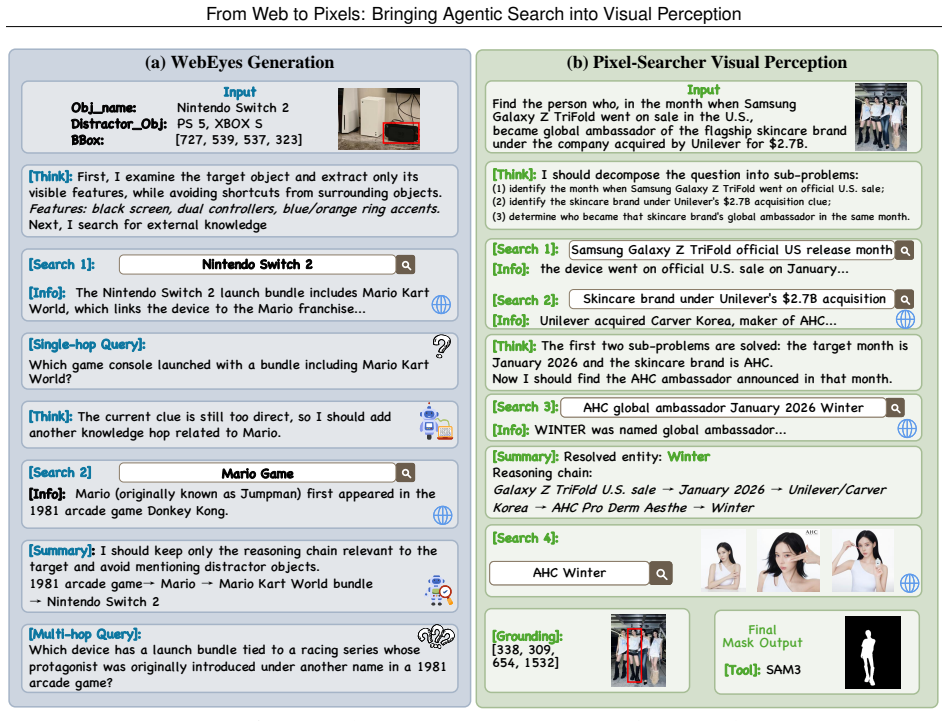
Pixel-Searcher, the agentic search-to-pixel workflow that resolves hidden target identities from web sources and binds them to boxes, masks, or grounded answers.
If this is right
- Pixel-Searcher achieves the strongest open-source performance across Search-based Grounding, Search-based Segmentation, and Search-based VQA.
- Remaining failures concentrate in evidence acquisition, identity resolution, and visual instance binding.
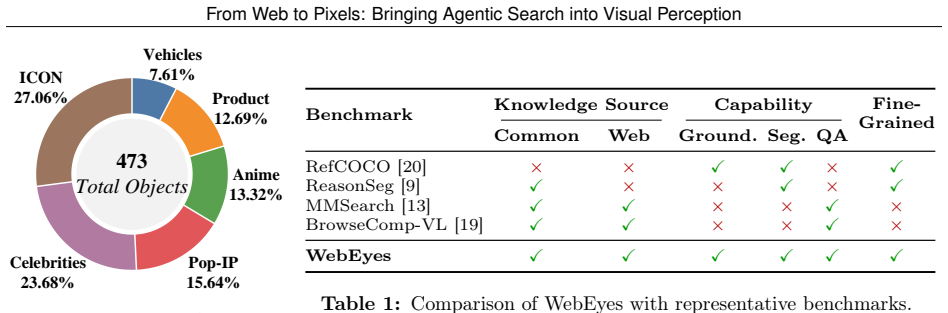
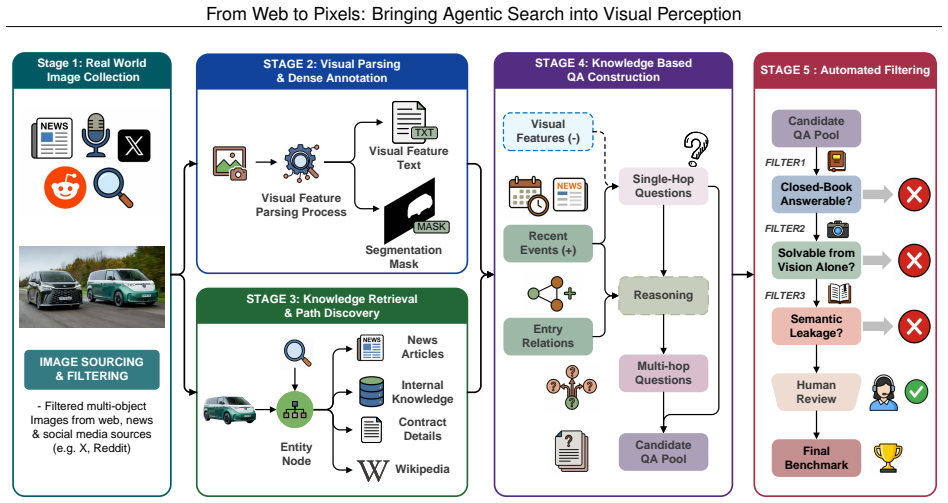
- The benchmark supplies verifiable evidence chains, precise box and mask labels, and knowledge-intensive queries across 120 images and 473 instances.
- Three distinct task views are defined that all require external resolution prior to pixel-level output.
Where Pith is reading between the lines
- Tighter coupling between search modules and visual grounding could reduce the observed binding errors.
- The same workflow pattern may extend to video sequences or real-time camera feeds where targets change with current events.
- Long-tail and multi-hop identity resolution remains a bottleneck that future agent designs must target explicitly.
Load-bearing premise
The decisive evidence for identifying a target is not already in the image or model knowledge but must be resolved from external facts, recent events, long-tail entities, or multi-hop relations before localization is possible.
What would settle it
A non-agentic model that reaches comparable accuracy on all three WebEye tasks without external evidence acquisition would falsify the claim that external resolution is required.
Figures

read the original abstract
Visual perception connects high-level semantic understanding to pixel-level perception, but most existing settings assume that the decisive evidence for identifying a target is already in the image or frozen model knowledge. We study a more practical yet harder open-world case where a visible object must first be resolved from external facts, recent events, long-tail entities, or multi-hop relations before it can be localized. We formalize this challenge as Perception Deep Research and introduce WebEye, an object-anchored benchmark with verifiable evidence, knowledge-intensive queries, precise box/mask annotations, and three task views: Search-based Grounding, Search-based Segmentation, and Search-based VQA. WebEyes contains 120 images, 473 annotated object instances, 645 unique QA pairs, and 1,927 task samples. We further propose Pixel-Searcher, an agentic search-to-pixel workflow that resolves hidden target identities and binds them to boxes, masks, or grounded answers. Experiments show that Pixel-Searcher achieves the strongest open-source performance across all three task views, while failures mainly arise from evidence acquisition, identity resolution, and visual instance binding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Perception Deep Research as a setting for visual perception where identifying a visible target requires resolving external facts, recent events, long-tail entities, or multi-hop relations via web search before localization or answering is possible. It presents the WebEye benchmark (120 images, 473 annotated object instances, 645 unique QA pairs, 1,927 task samples) with three task views—Search-based Grounding, Search-based Segmentation, and Search-based VQA—along with verifiable evidence and precise box/mask annotations. The authors propose Pixel-Searcher, an agentic search-to-pixel workflow, and report that it achieves the strongest open-source performance across the three views, with primary failure modes in evidence acquisition, identity resolution, and visual instance binding.
Significance. If the reported results hold, the work provides a concrete bridge between web-scale search and pixel-level visual tasks, filling a gap left by models that assume all necessary evidence is already present in the image or frozen parameters. The new benchmark supplies a reproducible, object-anchored testbed with knowledge-intensive queries and fine-grained annotations, while the failure categorization offers actionable diagnostics for future agentic systems. These elements constitute a useful resource and methodological template for multimodal research that must handle open-world, externally grounded perception.
minor comments (3)
- Abstract: the benchmark is introduced as 'WebEye' but then referred to as 'WebEyes contains 120 images...'; standardize the name throughout for consistency.
- Abstract and Experiments: while the full manuscript supplies direct comparisons on the 1,927 samples, the abstract itself contains no quantitative metrics, baselines, or error bars; adding a compact results table or key numbers would strengthen the headline claim for readers who stop at the abstract.
- Benchmark description: the three task views are listed but lack a short illustrative example for each (e.g., one query per view); adding one concrete query per view would improve immediate clarity without lengthening the paper.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance in bridging web-scale search with pixel-level perception, and recommendation for minor revision. We are pleased that the WebEye benchmark and Pixel-Searcher are viewed as a useful resource and methodological template.
Circularity Check
No significant circularity detected
full rationale
The manuscript introduces the WebEye benchmark (120 images, 473 instances, 1,927 samples) and the Pixel-Searcher agentic workflow, then reports direct experimental comparisons across Search-based Grounding, Segmentation, and VQA. No equations, derivations, or fitted parameters appear in the provided text. Claims rest on new benchmark construction and measured performance rather than any self-referential reduction of outputs to inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A visible object must first be resolved from external facts, recent events, long-tail entities, or multi-hop relations before it can be localized in the image.
invented entities (2)
-
WebEye benchmark
no independent evidence
-
Pixel-Searcher
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPixel-Searcher ... agentic search-to-pixel workflow that resolves hidden target identities and binds them to boxes, masks, or grounded answers
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclearSearch-Reason Loop ... Resolve ... h = R(q, E_1:T)
Reference graph
Works this paper leans on
-
[1]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025. 10 From Web to Pixels: Bringing Agentic Search into Visual Perception
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Chengming Xu, Yue Ma, Xiaobin Hu, Zhe Cao, Jie Xu, et al. The latent space: Foundation, evolution, mechanism, ability, and outlook.arXiv preprint arXiv:2604.02029, 2026
-
[4]
En Yu, Kangheng Lin, Liang Zhao, Yana Wei, Yuang Peng, Haoran Wei, Jianjian Sun, Chunrui Han, Zheng Ge, Xiangyu Zhang, et al. Perception-r1: Pioneering perception policy with reinforcement learning.Advances in Neural Information Processing Systems, 38:94827–94853, 2026
work page 2026
-
[5]
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing.Advances in Neural Information Processing Systems, 38:143297–143330, 2026
work page 2026
-
[6]
Sophiavl-r1: Reinforcing mllms reasoning with thinking reward.arXiv preprint arXiv:2505.17018, 2025
Kaixuan Fan, Kaituo Feng, Haoming Lyu, Dongzhan Zhou, and Xiangyu Yue. Sophiavl-r1: Reinforcing mllms reasoning with thinking reward.arXiv preprint arXiv:2505.17018, 2025
-
[7]
Mdetr- modulated detection for end-to-end multi-modal understanding
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr- modulated detection for end-to-end multi-modal understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 1780–1790, 2021
work page 2021
-
[8]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European conference on computer vision, pages 38–55. Springer, 2024
work page 2024
-
[9]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9579–9589, 2024
work page 2024
-
[10]
Glamm: Pixel grounding large multimodal model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13009–13018, 2024
work page 2024
-
[11]
Peng Wang, Qi Wu, Chunhua Shen, Anthony Dick, and Anton Van Den Hengel. Fvqa: Fact-based visual question answering.IEEE transactions on pattern analysis and machine intelligence, 40(10):2413–2427, 2017
work page 2017
-
[12]
Ok-vqa: A visual question answering benchmark requiring external knowledge
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 3195–3204, 2019
work page 2019
- [13]
-
[14]
Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
Jinming Wu, Zihao Deng, Wei Li, Yiding Liu, Bo You, Bo Li, Zejun Ma, and Ziwei Liu. Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
-
[15]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Exploring Reasoning Reward Model for Agents
Kaixuan Fan, Kaituo Feng, Manyuan Zhang, Tianshuo Peng, Zhixun Li, Yilei Jiang, Shuang Chen, Peng Pei, Xunliang Cai, and Xiangyu Yue. Exploring reasoning reward model for agents.arXiv preprint arXiv:2601.22154, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
A-okvqa: A benchmark for visual question answering using world knowledge
Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. InEuropean conference on computer vision, pages 146–162. Springer, 2022. 11 From Web to Pixels: Bringing Agentic Search into Visual Perception
work page 2022
-
[19]
arXiv preprint arXiv:2508.05748 (2025)
Xinyu Geng, Peng Xia, Zhen Zhang, Xinyu Wang, Qiuchen Wang, Ruixue Ding, Chenxi Wang, Jialong Wu, Yida Zhao, Kuan Li, et al. Webwatcher: Breaking new frontier of vision-language deep research agent.arXiv preprint arXiv:2508.05748, 2025
-
[20]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
work page 2016
-
[21]
Segmentation from natural language expressions
Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from natural language expressions. In European conference on computer vision, pages 108–124. Springer, 2016
work page 2016
-
[22]
Onlinerefer: A simple online baseline for referring video object segmentation
Dongming Wu, Tiancai Wang, Yuang Zhang, Xiangyu Zhang, and Jianbing Shen. Onlinerefer: A simple online baseline for referring video object segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2761–2770, 2023
work page 2023
-
[23]
Lavt: Language-aware vision transformer for referring image segmentation
Zhao Yang, Jiaqi Wang, Yansong Tang, Kai Chen, Hengshuang Zhao, and Philip HS Torr. Lavt: Language-aware vision transformer for referring image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18155–18165, 2022
work page 2022
-
[24]
Cris: Clip-driven referring image segmentation
Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11686–11695, 2022
work page 2022
-
[25]
Prompt-driven referring image segmentation with instance contrasting
Chao Shang, Zichen Song, Heqian Qiu, Lanxiao Wang, Fanman Meng, and Hongliang Li. Prompt-driven referring image segmentation with instance contrasting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4124–4134, 2024
work page 2024
-
[26]
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Chaoyang Wang, Kaituo Feng, Dongyang Chen, Zhongyu Wang, Zhixun Li, Sicheng Gao, Meng Meng, Xu Zhou, Manyuan Zhang, Yuzhang Shang, et al. Adatooler-v: Adaptive tool-use for images and videos.arXiv preprint arXiv:2512.16918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Referdino: Referring video object segmentation with visual grounding foundations
Tianming Liang, Kun-Yu Lin, Chaolei Tan, Jianguo Zhang, Wei-Shi Zheng, and Jian-Fang Hu. Referdino: Referring video object segmentation with visual grounding foundations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20009–20019, 2025
work page 2025
-
[28]
Ragnet: Large-scale reasoning-based affordance segmentation benchmark towards general grasping
Dongming Wu, Yanping Fu, Saike Huang, Yingfei Liu, Fan Jia, Nian Liu, Feng Dai, Tiancai Wang, Rao Muhammad Anwer, Fahad Shahbaz Khan, et al. Ragnet: Large-scale reasoning-based affordance segmentation benchmark towards general grasping. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11980–11990, 2025
work page 2025
-
[29]
Gen-Searcher: Reinforcing Agentic Search for Image Generation
Kaituo Feng, Manyuan Zhang, Shuang Chen, Yunlong Lin, Kaixuan Fan, Yilei Jiang, Hongyu Li, Dian Zheng, Chenyang Wang, and Xiangyu Yue. Gen-searcher: Reinforcing agentic search for image generation.arXiv preprint arXiv:2603.28767, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Retrieval augmented visual question answering with outside knowledge
Weizhe Lin and Bill Byrne. Retrieval augmented visual question answering with outside knowledge. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 11238–11254, 2022
work page 2022
-
[31]
Huanjin Yao, Qixiang Yin, Min Yang, Ziwang Zhao, Yibo Wang, Haotian Luo, Jingyi Zhang, and Jiaxing Huang. Mm-deepresearch: A simple and effective multimodal agentic search baseline.arXiv preprint arXiv:2603.01050, 2026
-
[32]
OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
Shuang Chen, Kaituo Feng, Hangting Chen, Wenxuan Huang, Dasen Dai, Quanxin Shou, Yunlong Lin, Xiangyu Yue, Shenghua Gao, and Tianyu Pang. Opensearch-vl: An open recipe for frontier multimodal search agents. arXiv preprint arXiv:2605.05185, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
ROSE: Retrieval-Oriented Segmentation Enhancement
Song Tang, Guangquan Jie, Henghui Ding, and Yu-Gang Jiang. Rose: Retrieval-oriented segmentation enhance- ment.arXiv preprint arXiv:2604.14147, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Tianming Liang, Qirui Du, Jian-Fang Hu, Haichao Jiang, Zicheng Lin, and Wei-Shi Zheng. Seg-research: Segmentation with interleaved reasoning and external search.arXiv preprint arXiv:2602.04454, 2026
-
[35]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023. 12 From Web to Pixels: Bringing Agentic Search into Visual Perception
work page 2023
- [36]
-
[37]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. Univg-r1: Reasoning guided universal visual grounding with reinforcement learning.arXiv preprint arXiv:2505.14231, 2025
-
[38]
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang. Ground-r1: Incentivizing grounded visual reasoning via reinforcement learning.arXiv preprint arXiv:2505.20272, 2025
-
[39]
OneThinker: All-in-one Reasoning Model for Image and Video
Kaituo Feng, Manyuan Zhang, Hongyu Li, Kaixuan Fan, Shuang Chen, Yilei Jiang, Dian Zheng, Peiwen Sun, Yiyuan Zhang, Haoze Sun, et al. Onethinker: All-in-one reasoning model for image and video.arXiv preprint arXiv:2512.03043, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement.arXiv preprint arXiv:2503.06520, 2025
-
[42]
Zuyao You and Zuxuan Wu. Seg-r1: Segmentation can be surprisingly simple with reinforcement learning.arXiv preprint arXiv:2506.22624, 2025
-
[43]
Hanqing Wang, Shaoyang Wang, Yiming Zhong, Zemin Yang, Jiamin Wang, Zhiqing Cui, Jiahao Yuan, Yifan Han, Mingyu Liu, and Yuexin Ma. Affordance-r1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 9738–9746, 2026
work page 2026
-
[44]
Sam 3: Segment anything with concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page 2025
-
[45]
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025
-
[46]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025. 13 From Web to Pixels: Bringing Agentic Search into Visual Perception A Dataset Samples Table 6 shows five representative...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
1-3 sub-questions, ordered by reasoning dependency
-
[48]
Each sub-question should target one hop of reasoning
-
[49]
If the question is already simple, return it as the only sub-question
-
[50]
Preserve the final target of the original question. If the question asks about the item/person in the image, the last sub-question must still ask about that final target, not about an intermediate clue
-
[51]
Intermediate clues are for resolving the target, not for becoming the target
Do not let a year, event, or historical clue replace the final grounded entity. Intermediate clues are for resolving the target, not for becoming the target
-
[52]
Return only JSON. Multi-round search agent. You are a multi-round reasoning agent for visual grounding. Your goal is to identify the exact entity described by the question so it can be located in an image. Original question: {question} Sub-questions: {sub_questions} Accumulated evidence so far: {evidence} Interaction round {round_num} of {max_rounds}. Onl...
- [53]
- [54]
-
[55]
{"action": "ANSWER", "entity_name": "resolved entity", "visual_category": "phone/person/car/...", "entity_type": "device /person/character/vehicle/object", "key_cues": ["cue1", "cue2"], "confidence": 0.0-1.0} Guidelines: - Use SEARCH to gather information you don’t have yet. - Use THINK only to briefly consolidate evidence before the next action. - If evi...
-
[56]
Answer the actual item/person that should be located in the image
-
[57]
Do not answer with an intermediate clue entity, historical reference, designer, event, or source article unless that is also the visible target
-
[58]
Prefer the concrete visible model/person/character over a generic series or franchise name
-
[59]
Only return an exact model/person if the evidence explicitly supports that exact target; otherwise return the best supported visible target
-
[60]
Return only JSON. Entity verification. You are checking whether a resolved entity is actually consistent with a visual grounding question and the gathered evidence. Question: {question} Proposed entity: {entity_name} Visual category: {visual_category} Entity type: {entity_type} Key cues: {key_cues} Evidence: {evidence} Return strict JSON: {"is_consistent"...
-
[61]
Mark is_consistent false if the proposed entity seems to be the wrong product/person/character/model, too generic, unsupported by evidence, or an intermediate clue rather than the final visible target in the image
-
[62]
consistency_score 5 means the entity is well supported and specific
-
[63]
If inconsistent, provide 1-2 targeted followup_queries to resolve the remaining ambiguity
-
[64]
For model-level answers, exact evidence matters. Do not mark an entity consistent unless the evidence explicitly supports that exact model/person, not just a nearby series, sibling model, platform, or speculative variant
-
[65]
Return only JSON. Entity repair. The current resolved entity for a visual grounding question appears unreliable. Question: {question} Current entity: {entity_name} Known issues with the current entity: {issues} Evidence: {evidence} Return strict JSON: {"entity_name": "better entity", "visual_category": "phone/person/car/object/...", "entity_type": "device...
-
[66]
Do not stick to the current entity if it is unsupported
Re-resolve the entity from the evidence. Do not stick to the current entity if it is unsupported
-
[67]
17 From Web to Pixels: Bringing Agentic Search into Visual Perception
Prefer the most concrete model/person/character/entity actually supported by the evidence. 17 From Web to Pixels: Bringing Agentic Search into Visual Perception
-
[68]
If the question asks about the item/person in the image, answer that final visible target, not an intermediate clue used to identify it
-
[69]
Prefer an exact model/person only when it is explicitly supported by the evidence; otherwise step back to the best supported visible target
-
[70]
If evidence is insufficient, still return the best alternative guess
-
[71]
Return only JSON. B.2 Visual Grounding Visual appearance extraction. Given search results about the appearance of "{entity_name}", extract a concise visual description focusing on shape, color , size, logos, and distinguishing physical features. Search results: {search_evidence} Return strict JSON: {"visual_description": "1-3 sentence description of how i...
-
[72]
bbox must use absolute pixel coordinates in the FIRST image only
-
[73]
Use the attached reference images to find the same object/person/icon/model
-
[74]
If several similar instances exist, choose the one best matching the cues
-
[75]
Return a tight box around one concrete instance only. Avoid broad boxes that cover multiple objects, large empty regions , or the center area between objects
-
[76]
If no plausible match exists, return bbox null
-
[77]
Return only JSON. Candidate joint ranking. You are selecting the best matching candidate in the FIRST image. The FIRST image is the full scene with all candidate boxes labeled. The next candidate images are crops in this order: {candidate_order} Any remaining images are web reference images for the target entity. Question: {reference_text} Entity name: {e...
-
[78]
Compare the labeled boxes in the overview image and the candidate crops jointly
-
[79]
Prefer exact instance-level matches, not just same coarse category
-
[80]
Use reference images when available
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.