Recognition: unknown
One Token per Highly Selective Frame: Towards Extreme Compression for Long Video Understanding
Pith reviewed 2026-05-10 13:24 UTC · model grok-4.3
The pith
Learnable token reduction to one per frame plus attention-based selection lets VLMs process far more frames from long videos with higher accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
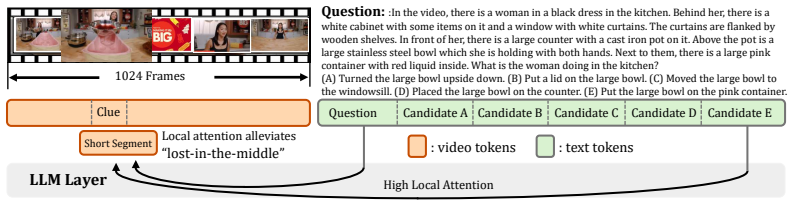
Heuristic compression is prone to information loss, so the authors supervise LLM layers to become learnable progressive modules (LP-Comp) that reduce each frame to one token; they further add question-conditioned frame selection (QC-Comp) that splits long videos into short segments and uses local attention scores to retain only the most relevant frames. The combined system, XComp, reaches a significantly larger compression ratio, supports denser frame sampling, and is obtained by fine-tuning VideoChat-Flash on only 2.5 percent of the supervised data yet raises LVBench accuracy from 42.9 percent to 46.2 percent and improves other long-video benchmarks.
What carries the argument
LP-Comp and QC-Comp: learnable progressive token compression supervised inside LLM layers to reach one token per frame, combined with question-conditioned frame selection that uses local attention scores after segmenting long videos to avoid position bias.
If this is right
- The model can digest 2x-4x more frames than prior methods while still fitting inside the LLM context window.
- Extreme compression is achieved without the information loss typical of heuristic token dropping.
- Only 2.5 percent of the usual supervised fine-tuning data is required to reach the reported accuracy gains.
- Accuracy rises on LVBench and on multiple additional long-video understanding benchmarks.
Where Pith is reading between the lines
- If the local-attention selector generalizes, the same segmentation trick could be applied to other long-sequence tasks such as long-document question answering.
- The one-token-per-frame regime opens the possibility of feeding entire hour-long videos into a single forward pass once the LLM context is enlarged.
- Because the compression modules are learned inside the LLM rather than applied as a fixed preprocessor, they may adapt to new video domains with little additional data.
Load-bearing premise
The internal attention scores of the LLM layers, once videos are split into short segments, can identify the frames most relevant to an arbitrary query without losing temporal context that the token compression stage cannot recover.
What would settle it
On a long-video benchmark whose queries depend on information located in the middle of the sequence, the local-segment attention selector would show no gain over random frame selection or over global attention; that outcome would falsify the claim that local attention reliably surfaces the right frames.
Figures




read the original abstract
Long video understanding is inherently challenging for vision-language models (VLMs) because of the extensive number of frames. With each video frame typically expanding into tens or hundreds of tokens, the limited context length of large language models (LLMs) forces the VLMs to perceive the frames sparsely and lose temporal information. To address this, we explore extreme video token compression towards one token per frame at the final LLM layer. Our key insight is that heuristic-based compression, widely adopted by previous methods, is prone to information loss, and this necessitates supervising LLM layers into learnable and progressive modules for token-level compression (LP-Comp). Such compression enables our VLM to digest 2x-4x more frames with improved performance. To further increase the token efficiency, we investigate frame-level compression, which selects the frames most relevant to the queries via the internal attention scores of the LLM layers, named question-conditioned compression (QC-Comp). As a notable distinction from previous studies, we mitigate the position bias of LLM attention in long contexts, i.e., the over-concentration on the beginning and end of a sequence, by splitting long videos into short segments and employing local attention. Collectively, our combined token-level and frame-level leads to an extreme compression model for long video understanding, named XComp, achieving a significantly larger compression ratio and enabling denser frame sampling. Our XComp is finetuned from VideoChat-Flash with a data-efficient supervised compression tuning stage that only requires 2.5% of the supervised fine-tuning data, yet boosts the accuracy from 42.9% to 46.2% on LVBench and enhances multiple other long video benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes XComp, a VLM for long video understanding that achieves extreme compression via two components: LP-Comp, which uses supervised progressive modules to reduce each frame to a single token at the final LLM layer, and QC-Comp, which performs frame-level selection by computing query-conditioned attention scores within locally segmented video windows to mitigate position bias. The model is obtained by fine-tuning VideoChat-Flash on only 2.5% of the usual supervised data and is reported to raise LVBench accuracy from 42.9% to 46.2% while supporting denser frame sampling.
Significance. If the empirical gains are reproducible and the attention-based selection proves reliable, the work would demonstrate a practical route to 2-4x denser frame sampling under fixed context budgets, with the data-efficient supervised tuning stage constituting a clear engineering contribution. The explicit separation of token-level and frame-level compression stages is a useful conceptual distinction.
major comments (2)
- [Abstract] Abstract: the central claim that QC-Comp enables the observed 3.3-point LVBench gain (42.9% to 46.2%) rests on an unreviewed empirical result; no ablation isolating QC-Comp from LP-Comp, no error bars, and no statistical test are supplied, so it is impossible to rule out that the improvement is attributable to the supervised tuning stage alone.
- [QC-Comp description] QC-Comp description: the load-bearing assumption that local attention scores reliably surface frames most relevant to arbitrary queries (and thereby preserve temporal context that one-token-per-frame compression cannot recover) is asserted without any supporting correlation study, qualitative attention maps, or comparison against query-agnostic frame sampling baselines.
minor comments (2)
- The abstract states that the method achieves a 'significantly larger compression ratio' but supplies no concrete ratio figures or direct numerical comparison against the strongest prior token-compression baselines.
- Notation for the progressive compression modules (LP-Comp) and the local-attention windowing procedure would benefit from a compact diagram or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will make the requested revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that QC-Comp enables the observed 3.3-point LVBench gain (42.9% to 46.2%) rests on an unreviewed empirical result; no ablation isolating QC-Comp from LP-Comp, no error bars, and no statistical test are supplied, so it is impossible to rule out that the improvement is attributable to the supervised tuning stage alone.
Authors: We agree that an ablation isolating QC-Comp's contribution is required to substantiate the claim. In the revised manuscript we will add an ablation comparing LVBench accuracy of the LP-Comp-only model against the full XComp model (both trained with the same 2.5% supervised compression tuning data). We will also report standard deviations across multiple runs and include statistical significance tests. revision: yes
-
Referee: [QC-Comp description] QC-Comp description: the load-bearing assumption that local attention scores reliably surface frames most relevant to arbitrary queries (and thereby preserve temporal context that one-token-per-frame compression cannot recover) is asserted without any supporting correlation study, qualitative attention maps, or comparison against query-agnostic frame sampling baselines.
Authors: We acknowledge the need for direct evidence. The revised version will include (i) qualitative attention maps visualizing query-conditioned frame selection, (ii) a correlation analysis between selected frames and query-relevant frames (using available annotations where possible), and (iii) quantitative comparisons against query-agnostic baselines such as uniform sampling and motion-based keyframe selection. revision: yes
Circularity Check
No circularity; empirical supervised tuning result
full rationale
The paper presents an engineering pipeline (LP-Comp token compression via supervised layer modules + QC-Comp frame selection via local LLM attention) whose performance gains are measured on held-out benchmarks after finetuning on 2.5% of SFT data. No equations, self-citations, or fitted parameters are shown to reduce the reported accuracy lift (42.9% → 46.2% on LVBench) to a definitional identity or tautology. The central claims rest on external empirical validation rather than internal re-derivation of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ht-step: Aligning instructional articles with how-to videos.NeurIPS, 2023
Triantafyllos Afouras, Effrosyni Mavroudi, Tushar Nagarajan, Huiyu Wang, and Lorenzo Torresani. Ht-step: Aligning instructional articles with how-to videos.NeurIPS, 2023. 25
2023
-
[2]
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, and Mohamed Elhoseiny. Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens.arXiv preprint arXiv:2404.03413, 2024. 3
-
[3]
Goldfish: Vision-language understanding of arbitrarily long videos
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Mingchen Zhuge, Jian Ding, Deyao Zhu, Jürgen Schmidhuber, and Mohamed Elhoseiny. Goldfish: Vision-language understanding of arbitrarily long videos. InECCV, 2024. 2, 3
2024
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022. 3, 5, 23
work page internal anchor Pith review arXiv 2022
-
[6]
Revisiting the" video" in video-language understanding
Shyamal Buch, Cristóbal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the" video" in video-language understanding. InCVPR, 2022. 6
2022
-
[7]
Gui-world: A video benchmark and dataset for multimodal gui-oriented understanding
Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Huichi Zhou, Qihui Zhang, Zhigang He, Yilin Bai, Chujie Gao, Liuyi Chen, et al. Gui-world: A video benchmark and dataset for multimodal gui-oriented understanding. InThe Thirteenth International Conference on Learning Representations, 2024. 25
2024
-
[8]
arXiv preprint arXiv:2504.15271 , year=
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Tuomas Rintamaki, et al. Eagle 2.5: Boosting long-context post-training for frontier vision-language models.arXiv preprint arXiv:2504.15271, 2025. 7
-
[9]
Sharegpt4video: Improving video understanding and generation with better captions.NeurIPS, 2024
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. Sharegpt4video: Improving video understanding and generation with better captions.NeurIPS, 2024. 25
2024
-
[10]
arXiv preprint arXiv:2411.18211 , year=
Shimin Chen, Xiaohan Lan, Yitian Yuan, Zequn Jie, and Lin Ma. Timemarker: A versatile video-llm for long and short video understanding with superior temporal localization ability. arXiv preprint arXiv:2411.18211, 2024. 7
-
[11]
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context visual language models for long videos.arXiv preprint arXiv:2408.10188, 2024. 2, 3
-
[12]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024. 1, 3
work page internal anchor Pith review arXiv 2024
-
[13]
vid-tldr: Training free token merging for light-weight video transformer
Joonmyung Choi, Sanghyeok Lee, Jaewon Chu, Minhyuk Choi, and Hyunwoo J Kim. vid-tldr: Training free token merging for light-weight video transformer. InCVPR, 2024. 3
2024
-
[14]
Sharegpt-4o: Comprehensive multimodal annotations with gpt-4o, 2024
E Cui, Y He, Z Ma, Z Chen, H Tian, W Wang, K Li, Y Wang, W Wang, X Zhu, et al. Sharegpt-4o: Comprehensive multimodal annotations with gpt-4o, 2024. 25 11
2024
- [15]
-
[16]
Videoagent: A memory-augmented multimodal agent for video understanding
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multimodal agent for video understanding. InECCV, 2024. 6
2024
-
[17]
Jiajun Fei, Dian Li, Zhidong Deng, Zekun Wang, Gang Liu, and Hui Wang. Video-ccam: Enhancing video-language understanding with causal cross-attention masks for short and long videos.arXiv preprint arXiv:2408.14023, 2024. 3
-
[18]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075,
work page internal anchor Pith review arXiv
-
[19]
Interleaved-modal chain-of-thought.arXiv preprint arXiv:2411.19488, 2024
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought.arXiv preprint arXiv:2411.19488, 2024. 2
-
[20]
something something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InICCV, 2017. 25
2017
-
[21]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InCVPR, 2022. 25
2022
-
[22]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. InCVPR, 2024. 1
2024
-
[23]
From image to video, what do we need in multimodal llms?
Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, and Zengchang Qin. From image to video, what do we need in multimodal llms?arXiv preprint arXiv:2404.11865, 2024. 1
-
[24]
Introducing idefics: An open reproduction of state-of-the-art visual language model.https://huggingface.co/blog/idefics, 2023
IDEFICS Team. Introducing idefics: An open reproduction of state-of-the-art visual language model.https://huggingface.co/blog/idefics, 2023. Accessed 2025-05-12. 3
2023
-
[25]
Tgif-qa: Toward spatio-temporal reasoning in visual question answering
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio-temporal reasoning in visual question answering. InICCV, 2017. 25
2017
-
[26]
Chat-univi: Unified visual representation empowers large language models with image and video understanding
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In CVPR, 2024. 3
2024
-
[27]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017. 25
work page internal anchor Pith review arXiv 2017
-
[28]
Text-conditioned resampler for long form video understanding
Bruno Korbar, Yongqin Xian, Alessio Tonioni, Andrew Zisserman, and Federico Tombari. Text-conditioned resampler for long form video understanding. InECCV, 2024. 3
2024
-
[29]
Multi-criteria token fusion with one-step-ahead attention for efficient vision transformers
Sanghyeok Lee, Joonmyung Choi, and Hyunwoo J Kim. Multi-criteria token fusion with one-step-ahead attention for efficient vision transformers. InCVPR, 2024. 3
2024
-
[30]
TVQA: Localized, Compositional Video Question Answering
Jie Lei, Licheng Yu, Mohit Bansal, and Tamara L Berg. Tvqa: Localized, compositional video question answering.arXiv preprint arXiv:1809.01696, 2018. 25
work page Pith review arXiv 2018
-
[31]
Llava-next: Stronger llms supercharge multimodal capabilities in the wild
Bo Li, Kaichen Zhang, Hao Zhang, Dong Guo, Renrui Zhang, Feng Li, Yuanhan Zhang, Ziwei Liu, and Chunyuan Li. Llava-next: Stronger llms supercharge multimodal capabilities in the wild. 2024. 2
2024
-
[32]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024. 1, 3, 25 12
work page Pith review arXiv 2024
-
[33]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024. 25
work page internal anchor Pith review arXiv 2024
-
[34]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355,
work page internal anchor Pith review arXiv
-
[35]
Videochat-flash: Hierarchical compression for long-context video modeling,
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, et al. Videochat-flash: Hierarchical compression for long-context video modeling.arXiv preprint arXiv:2501.00574, 2024. 1, 2, 3, 4, 5, 7, 8, 9, 23, 24, 25, 26
-
[36]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InECCV, 2024. 3
2024
-
[37]
Mapsparse: Accelerating pre-filling for long-context visual language models via modality-aware permutation sparse attention
Yucheng Li, Huiqiang Jiang, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Amir H Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, et al. Mapsparse: Accelerating pre-filling for long-context visual language models via modality-aware permutation sparse attention. InICLR 2025 Workshop on Foundation Models in the Wild. 5
2025
-
[38]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection.arXiv preprint arXiv:2311.10122,
work page internal anchor Pith review arXiv
-
[39]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. 25
2024
-
[40]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023. 4
2023
-
[41]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee
Jiajun Liu, Yibing Wang, Hanghang Ma, Xiaoping Wu, Xiaoqi Ma, Xiaoming Wei, Jianbin Jiao, Enhua Wu, and Jie Hu. Kangaroo: A powerful video-language model supporting long-context video input.arXiv preprint arXiv:2408.15542, 2024. 7
-
[42]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172, 2023. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection
Ye Liu, Siyuan Li, Yang Wu, Chang-Wen Chen, Ying Shan, and Xiaohu Qie. Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection. InCVPR,
-
[44]
arXiv preprint arXiv:2306.07207 , year=
Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Da Li, Pengcheng Lu, Tao Wang, Linmei Hu, Minghui Qiu, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability.arXiv preprint arXiv:2306.07207, 2023. 3
-
[45]
Image as set of points.arXiv preprint arXiv:2303.01494, 2023
Xu Ma, Yuqian Zhou, Huan Wang, Can Qin, Bin Sun, Chang Liu, and Yun Fu. Image as set of points.arXiv preprint arXiv:2303.01494, 2023. 3
-
[46]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424, 2023. 3
-
[47]
X-former elucidator: reviving efficient attention for long context language modeling
Xupeng Miao, Shenhan Zhu, Fangcheng Fu, Ziyu Guo, Zhi Yang, Yaofeng Tu, Zhihao Jia, and Bin Cui. X-former elucidator: reviving efficient attention for long context language modeling. InIJCAI, 2024. 2
2024
-
[48]
Gpt-4 technical report, 2024
OpenAI. Gpt-4 technical report, 2024. 7
2024
-
[49]
Gpt-4o system card, 2024
OpenAI. Gpt-4o system card, 2024. 3, 7
2024
-
[50]
Too many frames, not all useful: Efficient strategies for long-form video qa,
Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryu, Donghyun Kim, and Michael S Ryoo. Too many frames, not all useful: Efficient strategies for long-form video qa.arXiv preprint arXiv:2406.09396, 2024. 6 13
-
[51]
Occluded video instance segmentation: A benchmark
Jiyang Qi, Yan Gao, Yao Hu, Xinggang Wang, Xiaoyu Liu, Xiang Bai, Serge Belongie, Alan Yuille, Philip HS Torr, and Song Bai. Occluded video instance segmentation: A benchmark. IJCV, 2022. 25
2022
-
[52]
Shuhuai Ren, Sishuo Chen, Shicheng Li, Xu Sun, and Lu Hou. Testa: Temporal-spatial token aggregation for long-form video-language understanding.arXiv preprint arXiv:2310.19060,
-
[53]
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024. 2
-
[54]
Fine-grained audible video description
Xuyang Shen, Dong Li, Jinxing Zhou, Zhen Qin, Bowen He, Xiaodong Han, Aixuan Li, Yuchao Dai, Lingpeng Kong, Meng Wang, et al. Fine-grained audible video description. InCVPR,
-
[55]
Yunhang Shen, Chaoyou Fu, Shaoqi Dong, Xiong Wang, Peixian Chen, Mengdan Zhang, Haoyu Cao, Ke Li, Xiawu Zheng, Yan Zhang, et al. Long-vita: Scaling large multi-modal models to 1 million tokens with leading short-context accuray.arXiv preprint arXiv:2502.05177, 2025. 3
-
[56]
Video-xl: Extra-long vision language model for hour-scale video understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding. arXiv preprint arXiv:2409.14485, 2024. 3
-
[57]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InCVPR, 2024. 1, 3, 25
2024
-
[58]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024
Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024. 3, 7
2024
-
[59]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Xiaotao Gu, Shiyu Huang, Bin Xu, Yuxiao Dong, et al. Lvbench: An extreme long video understanding benchmark. arXiv preprint arXiv:2406.08035, 2024. 3, 8
-
[60]
Unidentified video objects: A benchmark for dense, open-world segmentation
Weiyao Wang, Matt Feiszli, Heng Wang, and Du Tran. Unidentified video objects: A benchmark for dense, open-world segmentation. InICCV, 2021. 25
2021
-
[61]
Internvideo2: Scaling foundation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for multimodal video understanding. InECCV, 2024. 1, 3
2024
-
[62]
Internvideo: General video foundation models via generative and discriminative learning
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, et al. Internvideo: General video foundation models via generative and discriminative learning.arXiv preprint arXiv:2212.03191, 2022. 1, 3
-
[63]
Videotree: Adaptive tree- based video representation for llm reasoning on long videos,
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos.arXiv preprint arXiv:2405.19209, 2024. 6
-
[64]
Longvideobench: A benchmark for long-context interleaved video-language understanding.NeurIPS, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.NeurIPS, 2024. 8
2024
-
[65]
A large cross-modal video retrieval dataset with reading comprehension.Pattern Recognition, 157:110818, 2025
Weijia Wu, Yuzhong Zhao, Zhuang Li, Jiahong Li, Hong Zhou, Mike Zheng Shou, and Xiang Bai. A large cross-modal video retrieval dataset with reading comprehension.Pattern Recognition, 157:110818, 2025. 25
2025
-
[66]
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mecha- nistically explains long-context factuality.arXiv preprint arXiv:2404.15574, 2024. 6
-
[67]
Next-qa: Next phase of question- answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question- answering to explaining temporal actions. InCVPR, 2021. 25 14
2021
-
[68]
Groupvit: Semantic segmentation emerges from text supervision
Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision. InCVPR, 2022. 3
2022
-
[69]
arXiv preprint arXiv:2404.16994 , year=
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning.arXiv preprint arXiv:2404.16994, 2024. 1
-
[70]
arXiv preprint arXiv:2407.15841 (2024)
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, and Afshin Dehghan. Slowfast-llava: A strong training-free baseline for video large language models.arXiv preprint arXiv:2407.15841, 2024. 1, 3
-
[71]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
Vript: A video is worth thousands of words.NeurIPS, 2024
Dongjie Yang, Suyuan Huang, Chengqiang Lu, Xiaodong Han, Haoxin Zhang, Yan Gao, Yao Hu, and Hai Zhao. Vript: A video is worth thousands of words.NeurIPS, 2024. 25
2024
-
[73]
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024. 7
-
[74]
Clevrer: Collision events for video representation and reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019. 25
-
[75]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[76]
Qingru Zhang, Dhananjay Ram, Cole Hawkins, Sheng Zha, and Tuo Zhao. Efficient long-range transformers: You need to attend more, but not necessarily at every layer.arXiv preprint arXiv:2310.12442, 2023. 2
-
[77]
Llava-next: A strong zero-shot video understanding model
Y Zhang, B Li, H Liu, Y Lee, L Gui, D Fu, J Feng, Z Liu, and C Li. Llava-next: A strong zero-shot video understanding model. 2024. 3
2024
-
[78]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 10, 25
work page Pith review arXiv 2024
-
[79]
Rmem: Restricted memory banks improve video object segmentation
Junbao Zhou, Ziqi Pang, and Yu-Xiong Wang. Rmem: Restricted memory banks improve video object segmentation. InCVPR, 2024. 6
2024
-
[80]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding.arXiv preprint arXiv:2406.04264, 2024. 8
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.