Recognition: no theorem link
The Devil Is in Gradient Entanglement: Energy-Aware Gradient Coordinator for Robust Generalized Category Discovery
Pith reviewed 2026-05-15 00:26 UTC · model grok-4.3
The pith
Gradient entanglement between supervised and unsupervised objectives limits generalized category discovery, but an energy-aware coordinator resolves it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
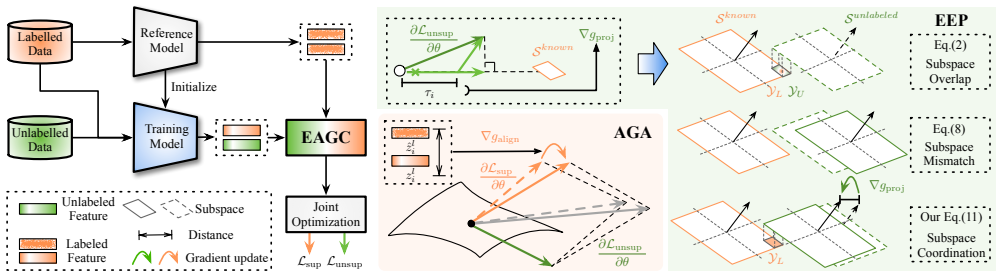
The authors claim that gradient entanglement is the core issue limiting GCD performance, as it weakens discrimination among known classes and reduces separability of novel categories. They introduce EAGC as a plug-and-play module with AGA to anchor labeled gradients via a reference model and EEP to project unlabeled gradients onto the complement of the known subspace using an energy-based scaling coefficient.
What carries the argument
Energy-Aware Gradient Coordinator (EAGC), a gradient-level module with Anchor-based Gradient Alignment (AGA) that preserves discriminative structure using a reference model, and Energy-aware Elastic Projection (EEP) that adaptively scales projections based on alignment energy to reduce subspace overlap.
If this is right
- Existing GCD methods achieve higher accuracy on both known and novel classes when integrated with EAGC.
- New state-of-the-art results are established on standard GCD benchmarks.
- The plug-and-play nature allows easy adoption without extensive retraining or hyperparameter searches.
- Representation subspaces become more separable for novel categories without suppressing samples likely from known classes.
Where Pith is reading between the lines
- The gradient regulation approach could extend to other semi-supervised or multi-objective settings where labeled and unlabeled signals interfere.
- Similar coordination modules might improve open-set recognition tasks by reducing subspace overlap.
- The energy coefficient could serve as a diagnostic signal for estimating sample novelty during training.
Load-bearing premise
That gradient entanglement is the primary limiting factor and that the AGA and EEP components address it without introducing new optimization instabilities.
What would settle it
Training existing GCD baselines with EAGC added and observing no accuracy gains or degradations on known-class and novel-class metrics across multiple random seeds and datasets.
Figures


read the original abstract
Generalized Category Discovery (GCD) leverages labeled data to categorize unlabeled samples from known or unknown classes. Most previous methods jointly optimize supervised and unsupervised objectives and achieve promising results. However, inherent optimization interference still limits their ability to improve further. Through quantitative analysis, we identify a key issue, i.e., gradient entanglement, which 1) distorts supervised gradients and weakens discrimination among known classes, and 2) induces representation-subspace overlap between known and novel classes, reducing the separability of novel categories. To address this issue, we propose the Energy-Aware Gradient Coordinator (EAGC), a plug-and-play gradient-level module that explicitly regulates the optimization process. EAGC comprises two components: Anchor-based Gradient Alignment (AGA) and Energy-aware Elastic Projection (EEP). AGA introduces a reference model to anchor the gradient directions of labeled samples, preserving the discriminative structure of known classes against the interference of unlabeled gradients. EEP softly projects unlabeled gradients onto the complement of the known-class subspace and derives an energy-based coefficient to adaptively scale the projection for each unlabeled sample according to its degree of alignment with the known subspace, thereby reducing subspace overlap without suppressing unlabeled samples that likely belong to known classes. Experiments show that EAGC consistently boosts existing methods and establishes new state-of-the-art results. Code is available at https://haiyangzheng.github.io/EAGC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that gradient entanglement arising from joint supervised-unsupervised optimization in Generalized Category Discovery (GCD) distorts labeled gradients (weakening known-class discrimination) and induces known-novel subspace overlap (reducing novel-class separability). It introduces the plug-and-play Energy-Aware Gradient Coordinator (EAGC) with two components: Anchor-based Gradient Alignment (AGA), which uses a reference model to anchor labeled gradients, and Energy-aware Elastic Projection (EEP), which softly projects unlabeled gradients onto the complement of the known-class subspace with per-sample energy-based adaptive scaling. Experiments are reported to show that EAGC consistently improves prior GCD methods and yields new state-of-the-art results on standard benchmarks; code is released.
Significance. If the experimental claims hold under rigorous verification, the work is significant for highlighting gradient-level interference as a concrete bottleneck in GCD and for supplying a modular, gradient-coordination fix that can be attached to existing pipelines. The code release supports reproducibility, and the emphasis on explicit gradient regulation rather than loss redesign offers a useful perspective for related open-world semi-supervised settings.
major comments (3)
- [§3.2] §3.2 (quantitative analysis): the identification of gradient entanglement as the primary cause is not accompanied by controls that rule out downstream effects from mismatched loss scales, pseudo-label noise, or representation collapse under the combined objective.
- [§3.3] §3.3 (AGA description): the reference model is presented as an anchor for labeled gradients, yet no analysis demonstrates that its own training dynamics remain independent of the entanglement it is intended to correct.
- [§4] §4 (experiments): the reported SOTA gains and consistent boosts lack error bars, statistical significance tests, and detailed ablations isolating AGA versus EEP contributions, weakening verification of the central performance claim.
minor comments (2)
- [Abstract] Abstract: the quantitative analysis is mentioned but its concrete metrics, datasets, and visualization details are not summarized, reducing immediate clarity.
- [§3.4] Notation in the EEP energy-coefficient definition could be made more explicit (e.g., clarifying how the alignment score is computed from subspace projections).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: §3.2 (quantitative analysis): the identification of gradient entanglement as the primary cause is not accompanied by controls that rule out downstream effects from mismatched loss scales, pseudo-label noise, or representation collapse under the combined objective.
Authors: We appreciate the referee highlighting the need for stronger isolation of the claimed cause. Section 3.2 presents gradient-norm comparisons, directional misalignment metrics, and subspace-overlap measurements between supervised and unsupervised gradients. To rule out confounding factors, the revised manuscript will add three targeted controls: (1) explicit loss-scale normalization experiments, (2) oracle-label runs that eliminate pseudo-label noise, and (3) monitoring of representation-collapse indicators (e.g., singular-value spectra). These additions will more rigorously attribute the observed degradation to gradient entanglement. revision: yes
-
Referee: §3.3 (AGA description): the reference model is presented as an anchor for labeled gradients, yet no analysis demonstrates that its own training dynamics remain independent of the entanglement it is intended to correct.
Authors: The reference model is trained exclusively on labeled data with the supervised loss and is kept frozen during the joint optimization; consequently its gradients never encounter the unsupervised term. We will add an explicit analysis in the revision (new paragraph in §3.3 plus supporting figure in the appendix) that compares gradient statistics and class-separation metrics of the reference model against the jointly trained model, confirming the absence of entanglement patterns in the reference. revision: yes
-
Referee: §4 (experiments): the reported SOTA gains and consistent boosts lack error bars, statistical significance tests, and detailed ablations isolating AGA versus EEP contributions, weakening verification of the central performance claim.
Authors: We agree that additional statistical rigor and component-wise ablations are required. In the revised experiments section we will report means and standard deviations over five random seeds for all main tables, include paired statistical significance tests (t-tests) against baselines, and expand the ablation study with separate rows for AGA-only, EEP-only, and full EAGC, together with corresponding performance deltas. revision: yes
Circularity Check
No circularity in derivation: EAGC components defined independently from analysis
full rationale
The paper's chain begins with quantitative identification of gradient entanglement (distorting supervised gradients and causing subspace overlap), then defines AGA (reference model anchors labeled gradients) and EEP (energy-based projection scaling per sample) as explicit, plug-and-play modules. Neither component reduces by construction to a fitted quantity on the same data, nor relies on self-citation for uniqueness or ansatz. The reference model and energy coefficients are derived from the optimization process itself rather than tautologically from target outputs. Empirical claims rest on external benchmarks showing consistent boosts, which are falsifiable outside any internal fit. No load-bearing step collapses to renaming, self-definition, or imported uniqueness from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amend: Adaptive margin and expanded neighbor- hood for efficient generalized category discovery
Anwesha Banerjee, Liyana Sahir Kallooriyakath, and Soma Biswas. Amend: Adaptive margin and expanded neighbor- hood for efficient generalized category discovery. InWACV,
-
[2]
Open-world semi-supervised learning
Kaidi Cao, Maria Brbic, and Jure Leskovec. Open-world semi-supervised learning. InICLR, 2022. 6, 7
work page 2022
-
[3]
Solv- ing the catastrophic forgetting problem in generalized cate- gory discovery
Xinzi Cao, Xiawu Zheng, Guanhong Wang, Weijiang Yu, Yunhang Shen, Ke Li, Yutong Lu, and Yonghong Tian. Solv- ing the catastrophic forgetting problem in generalized cate- gory discovery. InCVPR, 2024. 1, 2, 6, 7, 8
work page 2024
-
[4]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, 2021. 6
work page 2021
-
[5]
Parametric information maxi- mization for generalized category discovery
Florent Chiaroni, Jose Dolz, Ziko Imtiaz Masud, Amar Mitiche, and Ismail Ben Ayed. Parametric information maxi- mization for generalized category discovery. InICCV, 2023. 1, 2
work page 2023
-
[6]
Contrastive mean- shift learning for generalized category discovery
Sua Choi, Dahyun Kang, and Minsu Cho. Contrastive mean- shift learning for generalized category discovery. InCVPR,
-
[7]
Qiyuan Dai, Hanzhuo Huang, Yu Wu, and Sibei Yang. Adap- tive part learning for fine-grained generalized category dis- covery: A plug-and-play enhancement. InCVPR, 2025. 2
work page 2025
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR. Ieee, 2009. 5, 2
work page 2009
-
[9]
On-the-fly cate- gory discovery
Ruoyi Du, Dongliang Chang, Kongming Liang, Timothy Hospedales, Yi-Zhe Song, and Zhanyu Ma. On-the-fly cate- gory discovery. InCVPR, 2023. 2
work page 2023
-
[10]
Yixin Fei, Zhongkai Zhao, Siwei Yang, and Bingchen Zhao. Xcon: Learning with experts for fine-grained category dis- covery.arXiv preprint arXiv:2208.01898, 2022. 1, 2, 6, 7
-
[11]
Towards novel class discovery: A study in novel skin lesions clustering
Wei Feng, Lie Ju, Lin Wang, Kaimin Song, and Zongyuan Ge. Towards novel class discovery: A study in novel skin lesions clustering. InMICCAI, 2023. 2
work page 2023
-
[12]
A unified objective for novel class discovery
Enrico Fini, Enver Sangineto, St ´ephane Lathuili `ere, Zhun Zhong, Moin Nabi, and Elisa Ricci. A unified objective for novel class discovery. InICCV, 2021
work page 2021
-
[13]
Class- relation knowledge distillation for novel class discovery
Peiyan Gu, Chuyu Zhang, Ruijie Xu, and Xuming He. Class- relation knowledge distillation for novel class discovery. In ICCV, 2023. 2
work page 2023
-
[14]
Learning to discover novel visual categories via deep transfer cluster- ing
Kai Han, Andrea Vedaldi, and Andrew Zisserman. Learning to discover novel visual categories via deep transfer cluster- ing. InICCV, 2019. 1, 2
work page 2019
-
[15]
Zahid Hasan, Abu Zaher Md Faridee, Masud Ahmed, Sanjay Purushotham, Heesung Kwon, Hyungtae Lee, and Nirmalya Roy. Novel categories discovery via constraints on empirical prediction statistics.arXiv preprint arXiv:2307.03856, 2023. 2
-
[16]
Seal: Semantic-aware hierarchical learning for generalized category discovery
Zhenqi He, Yuanpei Liu, and Kai Han. Seal: Semantic-aware hierarchical learning for generalized category discovery. In NeurIPS, 2025. 1, 2
work page 2025
-
[17]
Directional gradient pro- jection for robust fine-tuning of foundation models.ICLR,
Chengyue Huang, Junjiao Tian, Brisa Maneechotesuwan, Shivang Chopra, and Zsolt Kira. Directional gradient pro- jection for robust fine-tuning of foundation models.ICLR,
-
[18]
Anomalyncd: Towards novel anomaly class discovery in industrial scenarios
Ziming Huang, Xurui Li, Haotian Liu, Feng Xue, Yuzhe Wang, and Yu Zhou. Anomalyncd: Towards novel anomaly class discovery in industrial scenarios. InCVPR, 2025. 6
work page 2025
-
[19]
Controlling recurrent neural networks by conceptors.arXiv preprint arXiv:1403.3369, 2014
Herbert Jaeger. Controlling recurrent neural networks by conceptors.arXiv preprint arXiv:1403.3369, 2014. 5
-
[20]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In CVPRW, 2013. 5, 2
work page 2013
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 5, 2
work page 2009
- [22]
-
[23]
Bingyu Li, Feiyu Wang, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xuelong Li. Maris: Marine open-vocabulary in- stance segmentation with geometric enhancement and se- mantic alignment.arXiv preprint arXiv:2510.15398, 2025. 6
-
[24]
Bingyu Li, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xue- long Li. Fgaseg: Fine-grained pixel-text alignment for open-vocabulary semantic segmentation.arXiv preprint arXiv:2501.00877, 2025
-
[25]
Exploring efficient open-vocabulary segmentation in the remote sensing
Bingyu Li, Haocheng Dong, Da Zhang, Zhiyuan Zhao, Hao Sun, and Junyu Gao. Exploring efficient open-vocabulary segmentation in the remote sensing. InAAAI, 2026. 6
work page 2026
-
[26]
Model- ing inter-class and intra-class constraints in novel class dis- covery
Wenbin Li, Zhichen Fan, Jing Huo, and Yang Gao. Model- ing inter-class and intra-class constraints in novel class dis- covery. InCVPR, 2023. 2
work page 2023
-
[27]
Lion-fs: Fast & slow video-language thinker as online video assistant
Wei Li, Bing Hu, Rui Shao, Leyang Shen, and Liqiang Nie. Lion-fs: Fast & slow video-language thinker as online video assistant. InCVPR, 2025. 6
work page 2025
-
[28]
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. Cogvla: Cognition-aligned vision-language-action model via instruction-driven routing & sparsification. InNeurIPS,
-
[29]
A closer look at novel class discovery from the labeled set
Ziyun Li, Jona Otholt, Ben Dai, Di Hu, Christoph Meinel, and Haojin Yang. A closer look at novel class discovery from the labeled set. InNeurIPS Workshop, 2022. 2
work page 2022
-
[30]
Supervised knowledge may hurt novel class discovery performance.TMLR, 2023
Ziyun Li, Jona Otholt, Ben Dai, Di Hu, Christoph Meinel, and Haojin Yang. Supervised knowledge may hurt novel class discovery performance.TMLR, 2023. 2
work page 2023
-
[31]
Unknown sniffer for object detection: Don’t turn a blind eye to unknown objects
Wenteng Liang*, Feng Xue*, Yihao Liu, Guofeng Zhong, and Anlong Ming. Unknown sniffer for object detection: Don’t turn a blind eye to unknown objects. InCVPR, 2023. 6
work page 2023
-
[32]
Xiao Liu, Nan Pu, Haiyang Zheng, Wenjing Li, Nicu Sebe, and Zhun Zhong. Generate, refine, and encode: Leveraging synthesized novel samples for on-the-fly fine-grained cate- gory discovery. InICCV, 2025. 2
work page 2025
-
[33]
Debgcd: Debiased learning with distribution guidance for generalized category discovery
Yuanpei Liu and Kai Han. Debgcd: Debiased learning with distribution guidance for generalized category discovery. In ICLR, 2025. 1, 2
work page 2025
-
[34]
Residual tuning: Toward novel category discovery without labels.TNNLS, 2023
Yu Liu and Tinne Tuytelaars. Residual tuning: Toward novel category discovery without labels.TNNLS, 2023. 2
work page 2023
-
[35]
Novel class discovery for ultra-fine-grained visual categorization
Yu Liu, Yaqi Cai, Qi Jia, Binglin Qiu, Weimin Wang, and Nan Pu. Novel class discovery for ultra-fine-grained visual categorization. InCVPR, 2024. 2
work page 2024
-
[36]
Yuanpei Liu, Zhenqi He, and Kai Han. Hyperbolic category discovery. InCVPR, 2025. 2
work page 2025
-
[37]
Pro- togcd: Unified and unbiased prototype learning for general- ized category discovery.TPAMI, 2025
Shijie Ma, Fei Zhu, Xu-Yao Zhang, and Cheng-Lin Liu. Pro- togcd: Unified and unbiased prototype learning for general- ized category discovery.TPAMI, 2025. 1, 2
work page 2025
-
[38]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classi- fication of aircraft.arXiv preprint arXiv:1306.5151, 2013. 5, 2
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[39]
Novel class dis- covery: A dependency approach
Tanmoy Mukherjee and Nikos Deligiannis. Novel class dis- covery: A dependency approach. InICASSP, 2022. 2
work page 2022
-
[40]
Jorge Nocedal and Stephen J Wright.Numerical optimiza- tion. Springer, 2006. 4
work page 2006
-
[41]
Rabah Ouldnoughi, Chia-Wen Kuo, and Zsolt Kira. Clip- gcd: Simple language guided generalized category discov- ery.arXiv preprint arXiv:2305.10420, 2023. 2
-
[42]
Mos: Modeling object-scene associations in generalized category discovery
Zhengyuan Peng, Jinpeng Ma, Zhimin Sun, Ran Yi, Haichuan Song, Xin Tan, and Lizhuang Ma. Mos: Modeling object-scene associations in generalized category discovery. InCVPR, 2025. 1, 2
work page 2025
-
[43]
Dynamic conceptional contrastive learning for generalized category discovery
Nan Pu, Zhun Zhong, and Nicu Sebe. Dynamic conceptional contrastive learning for generalized category discovery. In CVPR, 2023. 1, 2, 6, 7
work page 2023
-
[44]
Federated generalized category discovery
Nan Pu, Wenjing Li, Xingyuan Ji, Yalan Qin, Nicu Sebe, and Zhun Zhong. Federated generalized category discovery. In CVPR, 2024. 2
work page 2024
-
[45]
Prompt gradient pro- jection for continual learning
Jingyang Qiao, Zhizhong Zhang, Xin Tan, Chengwei Chen, Yanyun Qu, Yong Peng, and Yuan Xie. Prompt gradient pro- jection for continual learning. InICLR, 2024. 3
work page 2024
-
[46]
End-to-end novel visual categories learning via auxiliary self-supervision.Neural Networks, 2021
Yuanyuan Qing, Yijie Zeng, Qi Cao, and Guang-Bin Huang. End-to-end novel visual categories learning via auxiliary self-supervision.Neural Networks, 2021. 2
work page 2021
-
[47]
A conditional denoising diffusion proba- bilistic model for point cloud upsampling
Wentao Qu, Yuantian Shao, Lingwu Meng, Xiaoshui Huang, and Liang Xiao. A conditional denoising diffusion proba- bilistic model for point cloud upsampling. InCVPR, 2024. 6
work page 2024
-
[48]
Wentao Qu, Jing Wang, YongShun Gong, Xiaoshui Huang, and Liang Xiao. An end-to-end robust point cloud semantic segmentation network with single-step conditional diffusion models. InCVPR, 2025. 6
work page 2025
-
[49]
Sarah Rastegar, Hazel Doughty, and Cees Snoek. Learn to categorize or categorize to learn? self-coding for generalized category discovery.NeurIPS, 2023. 1, 2, 6, 7
work page 2023
-
[50]
Selex: Self-expertise in fine-grained generalized category discovery
Sarah Rastegar, Mohammadreza Salehi, Yuki M Asano, Hazel Doughty, and Cees GM Snoek. Selex: Self-expertise in fine-grained generalized category discovery. InECCV. Springer, 2024. 6, 7, 8, 3, 5
work page 2024
-
[51]
Masked jigsaw puzzle: A versatile position embedding for vision transformers
Bin Ren, Yahui Liu, Yue Song, Wei Bi, Rita Cucchiara, Nicu Sebe, and Wei Wang. Masked jigsaw puzzle: A versatile position embedding for vision transformers. InCVPR, 2023. 6
work page 2023
-
[52]
Masked clustering pre- diction for unsupervised point cloud pre-training
Bin Ren, Xiaoshui Huang, Mengyuan Liu, Hong Liu, Fabio Poiesi, Nicu Sebe, and Guofeng Mei. Masked clustering pre- diction for unsupervised point cloud pre-training. InAAAI,
-
[53]
Cdad-net: Bridging domain gaps in generalized category discovery
Sai Bhargav Rongali, Sarthak Mehrotra, Ankit Jha, Mo- hamad Hassan N C, Shirsha Bose, Tanisha Gupta, Mainak Singha, and Biplab Banerjee. Cdad-net: Bridging domain gaps in generalized category discovery. InCVPRW, 2024. 2
work page 2024
-
[54]
Q-value regularized decision con- vformer for offline reinforcement learning
Zhendong Ruan, Teng Yan, Yaobang Cai, Yu Han, Leyi Zheng, and Yang Zhang. Q-value regularized decision con- vformer for offline reinforcement learning. InROBIO. IEEE,
-
[55]
Gradient projection memory for continual learning.arXiv preprint arXiv:2103.09762, 2021
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient projection memory for continual learning.arXiv preprint arXiv:2103.09762, 2021. 3
-
[56]
Qiannan Shen and Jing Zhang. Ai-enhanced disaster risk prediction with explainable shap analysis: A multi-class classification approach using xgboost. 2025. Preprint, Ver- sion 1, posted December 31, 2025. 6
work page 2025
-
[57]
Multi- modal generalized category discovery.arXiv preprint arXiv:2409.11624, 2024
Yuchang Su, Renping Zhou, Siyu Huang, Xingjian Li, Tianyang Wang, Ziyue Wang, and Min Xu. Multi- modal generalized category discovery.arXiv preprint arXiv:2409.11624, 2024. 2
-
[58]
Opencon: Open-world contrastive learning.TMLR, 2022
Yiyou Sun and Yixuan Li. Opencon: Open-world contrastive learning.TMLR, 2022. 1, 2
work page 2022
-
[59]
A graph-theoretic framework for understanding open-world semi-supervised learning
Yiyou Sun, Zhenmei Shi, and Yixuan Li. A graph-theoretic framework for understanding open-world semi-supervised learning. InNeurIPS, 2023. 1, 2
work page 2023
-
[60]
Yiyou Sun, Zhenmei Shi, Yingyu Liang, and Yixuan Li. When and how does known class help discover unknown ones? provable understandings through spectral analysis. In ICML, 2023. 2
work page 2023
-
[61]
The Herbarium Challenge 2019 Dataset
Kiat Chuan Tan, Yulong Liu, Barbara Ambrose, Melissa Tulig, and Serge Belongie. The herbarium challenge 2019 dataset.arXiv preprint arXiv:1906.05372, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[62]
Luyao Tang, Kunze Huang, Chaoqi Chen, Yuxuan Yuan, Chenxin Li, Xiaotong Tu, Xinghao Ding, and Yue Huang. Dissecting generalized category discovery: Mul- tiplex consensus under self-deconstruction.arXiv preprint arXiv:2508.10731, 2025. 2
-
[63]
Generalized category discovery
Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisser- man. Generalized category discovery. InCVPR, 2022. 1, 2, 5, 6, 7, 3
work page 2022
-
[64]
Open-set recognition: A good closed-set classifier is all you need
Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisser- man. Open-set recognition: A good closed-set classifier is all you need. InICLR2022. OpenReview.net, 2022. 5
work page 2022
-
[65]
No representation rules them all in category discovery
Sagar Vaze, Andrea Vedaldi, and Andrew Zisserman. No representation rules them all in category discovery. In NeurIPS, 2024. 1, 2, 6, 7
work page 2024
-
[66]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Per- ona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011. 5, 2
work page 2011
-
[67]
Get: Unlocking the multi-modal po- tential of clip for generalized category discovery
Enguang Wang, Zhimao Peng, Zhengyuan Xie, Xialei Liu, and Ming-Ming Cheng. Get: Unlocking the multi-modal po- tential of clip for generalized category discovery. InCVPR,
-
[68]
Hongjun Wang, Sagar Vaze, and Kai Han. Sptnet: An effi- cient alternative framework for generalized category discov- ery with spatial prompt tuning. InICLR, 2024. 1, 2, 6, 7
work page 2024
-
[69]
Hilo: A learn- ing framework for generalized category discovery robust to domain shifts
Hongjun Wang, Sagar Vaze, and Kai Han. Hilo: A learn- ing framework for generalized category discovery robust to domain shifts. InICLR, 2025. 2
work page 2025
-
[70]
Jingyu Wang, Zhenyu Ma, Feiping Nie, and Xuelong Li. Progressive self-supervised clustering with novel category discovery.IEEE Transactions on Cybernetics, 2022. 2
work page 2022
-
[71]
Federated continual novel class learning
Lixu Wang, Chenxi Liu, Junfeng Guo, Jiahua Dong, Xiao Wang, Heng Huang, and Qi Zhu. Federated continual novel class learning. InICCV, 2025. 2
work page 2025
-
[72]
Ex- clusive style removal for cross domain novel class discovery
Yicheng Wang, Feng Liu, Junmin Liu, and Kai Sun. Ex- clusive style removal for cross domain novel class discovery. arXiv preprint arXiv:2406.18140, 2024. 2
-
[73]
Discover and align taxonomic context priors for open- world semi-supervised learning
Yu Wang, Zhun Zhong, Pengchong Qiao, Xuxin Cheng, Xi- awu Zheng, Chang Liu, Nicu Sebe, Rongrong Ji, and Jie Chen. Discover and align taxonomic context priors for open- world semi-supervised learning. InNeurIPS, 2024. 1, 2
work page 2024
-
[74]
Parametric classification for generalized category discovery: A baseline study
Xin Wen, Bingchen Zhao, and Xiaojuan Qi. Parametric classification for generalized category discovery: A baseline study. InICCV, 2023. 1, 2, 6, 7, 8, 3
work page 2023
-
[75]
Feng Xue, Yicong Chang, Tianxi Wang, Yu Zhou, and An- long Ming. Indoor obstacle discovery on reflective ground via monocular camera.International Journal of Computer Vision, 132(3), 2024. 6
work page 2024
-
[76]
Pandas: Prediction and detection of accurate slippage
Teng Yan, Xiaohong Zhou, Jiamin Long, Wenxian Li, and Yang Zhang. Pandas: Prediction and detection of accurate slippage. InIROS. IEEE, 2025. 6
work page 2025
-
[77]
Divide and conquer: Compositional experts for gen- eralized novel class discovery
Muli Yang, Yuehua Zhu, Jiaping Yu, Aming Wu, and Cheng Deng. Divide and conquer: Compositional experts for gen- eralized novel class discovery. InCVPR, 2022. 1, 2
work page 2022
-
[78]
Consistent prompt tuning for generalized category discovery.IJCV, 2025
Muli Yang, Jie Yin, Yanan Gu, Cheng Deng, Hanwang Zhang, and Hongyuan Zhu. Consistent prompt tuning for generalized category discovery.IJCV, 2025. 2
work page 2025
-
[79]
Self- labeling framework for novel category discovery over do- mains
Qing Yu, Daiki Ikami, Go Irie, and Kiyoharu Aizawa. Self- labeling framework for novel category discovery over do- mains. InAAAI, 2022. 2
work page 2022
-
[80]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. InNeurIPS, 2020. 3
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.