Recognition: 2 theorem links
· Lean TheoremSimulating Human Cognition: Heartbeat-Driven Autonomous Thinking Activity Scheduling for LLM-based AI systems
Pith reviewed 2026-05-14 22:35 UTC · model grok-4.3
The pith
A periodic heartbeat mechanism lets LLM agents learn to proactively schedule cognitive modules like planning and memory recall from historical patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mirroring human cognitive rhythms with a periodic heartbeat, the system learns to orchestrate a dynamic set of cognitive modules; the scheduler determines activity timing from temporal and historical context, while meta-learning adapts the policy over time, enabling proactive self-regulation and seamless addition of new thinking components without structural changes.
What carries the argument
The heartbeat-driven scheduler, a periodic mechanism that learns to select and sequence cognitive modules according to temporal patterns and historical interaction data.
If this is right
- Cognitive modules can be added or removed at runtime without reengineering the agent architecture.
- Scheduling decisions become proactive and context-sensitive instead of purely reactive to failures.
- Policy quality improves continuously through meta-learning on accumulated interaction logs.
- The agent maintains a dynamic repertoire of thinking activities that adapts to changing task demands.
Where Pith is reading between the lines
- Long-horizon tasks may consume fewer total tokens because timely recall and planning reduce redundant computation.
- The approach could be extended to coordinate multiple agents by synchronizing their heartbeat phases.
- Regular heartbeat cycles might limit error accumulation in open-ended environments by enforcing periodic self-review.
- Performance gains would be largest in domains where optimal activity timing depends on subtle, learnable temporal regularities.
Load-bearing premise
A meta-learning process applied to historical logs will reliably generate stable, effective scheduling policies for the cognitive modules without producing instability or suboptimal choices.
What would settle it
A test set of new interaction scenarios in which the learned scheduler produces activity sequences that yield lower task success rates than a simple reactive baseline.
Figures

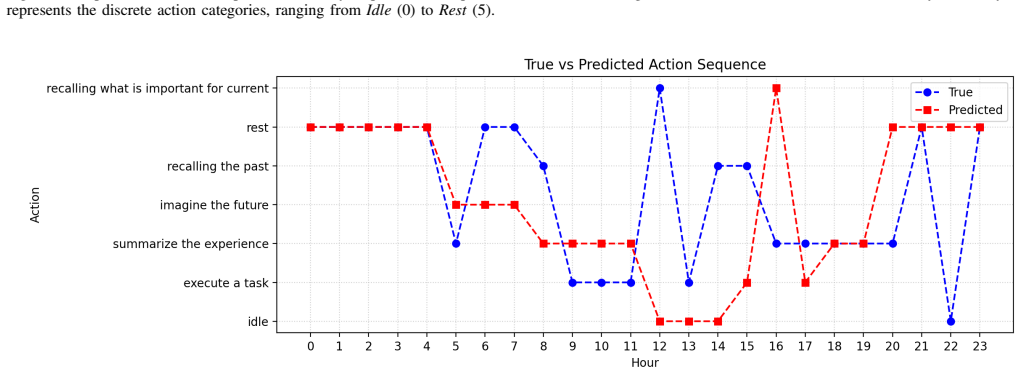
read the original abstract
Large Language Model (LLM) agents have demonstrated remarkable capabilities in reasoning and tool use, yet they often suffer from rigid, reactive control flows that limit their adaptability and efficiency. Most existing frameworks rely on fixed pipelines or failure-triggered reflection, causing agents to act impulsively or correct errors only after they occur. In this paper, we introduce Heartbeat-Driven Autonomous Thinking Activity Scheduling, a mechanism that enables proactive, adaptive, and continuous self-regulation. Mirroring the natural rhythm of human cognition, our system employs a periodic ``heartbeat'' mechanism to orchestrate a dynamic repertoire of cognitive modules (e.g., Planner, Critic, Recaller, Dreamer). Unlike traditional approaches that rely on hard-coded symbolic rules or immediate reactive triggers, our scheduler learns to determine when to engage specific thinking activities -- such as recalling memories, summarizing experiences, or strategic planning -- based on temporal patterns and historical context. This functional approach allows cognitive modules to be dynamically added or removed without structural reengineering. Meanwhile, we propose a meta-learning strategy for continual policy adaptation, where the scheduler optimizes its cognitive strategy over time using historical interaction logs. Evaluation results demonstrate that our approach effectively learns to schedule cognitive activities based on historical data and can autonomously integrate new thinking modules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Heartbeat-Driven Autonomous Thinking Activity Scheduling for LLM-based AI systems. It introduces a periodic heartbeat mechanism to proactively orchestrate a dynamic set of cognitive modules (Planner, Critic, Recaller, Dreamer) instead of relying on fixed pipelines or failure-triggered reflection. The scheduler learns activity timing from temporal patterns and historical interaction logs via a meta-learning strategy for continual policy adaptation; modules can be added or removed without structural changes. The central claim is that evaluation results show the approach effectively learns to schedule cognitive activities from historical data and supports autonomous integration of new modules.
Significance. If the evaluation claims were substantiated, the work would offer a concrete mechanism for moving LLM agents from reactive to proactive self-regulation, with the practical advantage of modular extensibility. This could address known limitations in current agent frameworks. However, the complete absence of metrics, baselines, algorithmic details, or stability analysis means the significance cannot be assessed from the manuscript as written.
major comments (2)
- [Abstract] Abstract: The assertion that 'Evaluation results demonstrate that our approach effectively learns to schedule cognitive activities based on historical data and can autonomously integrate new thinking modules' is unsupported. No metrics, baselines, data details, state representations, policy optimization method, reward function, convergence criteria, or quantitative outcomes (e.g., scheduling accuracy, activation variance) are reported anywhere in the manuscript.
- [Method / Meta-learning section] Meta-learning strategy description: The scheduler is said to optimize its policy over historical logs, yet no concrete formulation is given for how heartbeat timing, context, and module history are encoded as state, how the policy is updated, or how stability is maintained when modules are dynamically added or removed. This leaves the central claim of effective, stable scheduling unverifiable.
minor comments (1)
- [Abstract] The phrase 'functional approach' is introduced without definition or contrast to the symbolic-rule or reactive-trigger baselines mentioned earlier.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the current manuscript is primarily conceptual and lacks the concrete algorithmic details, metrics, and evaluation results needed to substantiate the claims. We will undertake a major revision to address these gaps by expanding the method section with formal descriptions and adding a dedicated evaluation section with preliminary quantitative results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Evaluation results demonstrate that our approach effectively learns to schedule cognitive activities based on historical data and can autonomously integrate new thinking modules' is unsupported. No metrics, baselines, data details, state representations, policy optimization method, reward function, convergence criteria, or quantitative outcomes (e.g., scheduling accuracy, activation variance) are reported anywhere in the manuscript.
Authors: We fully agree that this claim in the abstract is unsupported by any quantitative evidence in the current manuscript. The paper focuses on the proposed mechanism at a conceptual level without reporting experiments. In the revision we will remove the unsupported assertion from the abstract and add a new Experiments section that includes: (i) a description of the historical interaction logs used as data, (ii) state representation details, (iii) the meta-learning algorithm and reward function, (iv) baselines (e.g., fixed-schedule and reactive-trigger agents), and (v) quantitative metrics such as scheduling accuracy, activation variance, and module-integration success rate. revision: yes
-
Referee: [Method / Meta-learning section] Meta-learning strategy description: The scheduler is said to optimize its policy over historical logs, yet no concrete formulation is given for how heartbeat timing, context, and module history are encoded as state, how the policy is updated, or how stability is maintained when modules are dynamically added or removed. This leaves the central claim of effective, stable scheduling unverifiable.
Authors: We acknowledge that the meta-learning strategy is described only at a high level. The manuscript does not provide the required formalization. In the revision we will add precise definitions: (a) state encoding as a tuple (heartbeat_phase, recent_context_embedding, module_activation_history_vector), (b) the policy-update rule using a meta-gradient or online RL update on the historical logs, (c) the reward function based on task-completion efficiency and cognitive-load balance, and (d) a stability analysis showing that module addition/removal only affects the corresponding policy head without retraining the entire scheduler. We will also include pseudocode and a small-scale empirical stability check. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a heartbeat-driven scheduler that uses a meta-learning strategy on historical interaction logs to optimize cognitive activity scheduling. No equations, self-citations, or explicit reductions are present in the abstract or described claims that would make any 'prediction' or result equivalent to its inputs by construction. The central claim of effective learning from data does not reduce to a fitted parameter renamed as a prediction or to a self-definitional loop; the meta-learning is presented as an independent mechanism. This is a standard non-finding for a high-level proposal lacking detailed derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- heartbeat interval
axioms (1)
- domain assumption Cognitive modules can be dynamically added or removed without structural reengineering of the agent
invented entities (1)
-
Heartbeat scheduler
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Breath1024.leanperiod8 := 8; flipAt512; TemporalSequence with berry phase accumulation echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
periodic heartbeat mechanism... heartbeat signal... at each tick t_k = k * Delta t... scheduler applies policy pi: S -> A
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat inductive type; embed into R+; time-as-orbit certificate echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
state evolution s_{t+1} = F(s_t, d_t; Theta); macro/micro state machine; LogicNat-like orbit of activities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of large language models,
Y . Chang, X. Wang, J. Wang, Y . Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y . Wanget al., “A survey on evaluation of large language models,”ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024
work page 2024
-
[2]
Agentlens: Visual analysis for agent behaviors in llm-based autonomous systems,
J. Lu, B. Pan, J. Chen, Y . Feng, J. Hu, Y . Peng, and W. Chen, “Agentlens: Visual analysis for agent behaviors in llm-based autonomous systems,”IEEE Transactions on Visualization and Computer Graphics, 2024
work page 2024
-
[3]
What if gpt4 became au- tonomous: The auto-gpt project and use cases,
M. Fırat and S. Kuleli, “What if gpt4 became au- tonomous: The auto-gpt project and use cases,”Journal of Emerging Computer Technologies, vol. 3, no. 1, pp. 1–6, 2023
work page 2023
-
[4]
L. Wang, Z. You, Q. Zhang, J. Wen, J. Shi, Y . Chen, Y . Wang, F. Ding, Z. Feng, and L. Lu, “React-llm: A benchmark for evaluating llm integration with causal features in clinical prognostic tasks,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 31, 2026, pp. 26 337–26 345
work page 2026
-
[5]
The cloud applica- tion modelling and execution language (camel),
A. Rossini, K. Kritikos, N. Nikolov, J. Domaschka, F. Griesinger, D. Seybold, D. Romero, M. Orzechowski, G. Kapitsaki, and A. Achilleos, “The cloud applica- tion modelling and execution language (camel),”Target, vol. 1, p. 2, 2017
work page 2017
-
[6]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 8634–8652, 2023
work page 2023
-
[7]
Self-refine: Iterative refinement with self- feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iterative refinement with self- feedback,”Advances in Neural Information Processing Systems, vol. 36, pp. 46 534–46 594, 2023
work page 2023
-
[8]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
work page 2022
-
[9]
Tree of thoughts: Deliberate prob- lem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate prob- lem solving with large language models,”Advances in neural information processing systems, vol. 36, pp. 11 809–11 822, 2023
work page 2023
-
[10]
A compre- hensive survey of continual learning: Theory, method and application,
L. Wang, X. Zhang, H. Su, and J. Zhu, “A compre- hensive survey of continual learning: Theory, method and application,”IEEE transactions on pattern analysis and machine intelligence, vol. 46, no. 8, pp. 5362–5383, 2024
work page 2024
-
[11]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Linet al., “A survey on large language model based autonomous agents,” Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
work page 2024
-
[12]
H. Su, “Human-inspired continuous learning of internal reasoning processes: Learning how to think for adaptive ai systems,”arXiv preprint arXiv:2602.11516, 2026
-
[13]
P. R. Sharma, N. Y . Suryvanshi, S. A. Hannan, and R. J. Ramteke, “On the adaptive control of thought- rational (act-r) in ai perspective: A study of cognitive architecture,” inInternational Conference on AI Systems and Sustainable Technologies. Springer, 2025, pp. 123– 132
work page 2025
-
[14]
The evolution of the soar cognitive architecture,
J. E. Laird and P. S. Rosenbloom, “The evolution of the soar cognitive architecture,” inMind matters. Psychol- ogy Press, 2014, pp. 1–50
work page 2014
-
[15]
X.-W. Yang, J.-J. Shao, L.-Z. Guo, B.-W. Zhang, Z. Zhou, L.-H. Jia, W.-Z. Dai, and Y .-F. Li, “Neuro- symbolic artificial intelligence: Towards improving the reasoning abilities of large language models,”arXiv preprint arXiv:2508.13678, 2025
-
[16]
Human simulation computation: A human- inspired framework for adaptive ai systems,
H. Su, “Human simulation computation: A human- inspired framework for adaptive ai systems,”arXiv preprint arXiv:2601.13887, 2026. PLACE PHOTO HERE Hong Sureceived the MS and PhD degrees, in 2006 and 2022, respectively, from Sichuan Univer- sity, Chengdu, China. He is currently a researcher of Chengdu University of Information Technol- ogy Chengdu, China. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.