Recognition: 2 theorem links
· Lean TheoremCellwise Outliers
Pith reviewed 2026-05-13 23:42 UTC · model grok-4.3
The pith
Cellwise outliers as individual bad entries can contaminate over half the cases in high-dimensional data, requiring robust methods that differ from traditional casewise approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Traditional outlier detection treats an entire case as the basic unit, but in high-dimensional data even a small fraction of anomalous cells can contaminate more than half the observations. Robust methods must therefore target individual cells rather than whole cases, which means relinquishing some intuitive equivariance properties that casewise methods rely on. Over the past decade this shift has produced workable procedures for estimating location and covariance, for regression, for principal component analysis, and for tensor data; these cellwise techniques are becoming the standard choice for high-dimensional problems and routinely handle missing values at the same time.
What carries the argument
Cellwise outliers, defined as anomalous single entries inside a data matrix or tensor, which force the construction of robust estimators that act on cells instead of entire cases and therefore relax certain equivariance requirements.
Load-bearing premise
A relatively small proportion of outlying cells can contaminate over half the cases, making casewise methods insufficient for modern high-dimensional data.
What would settle it
A controlled experiment on high-dimensional data with a known small percentage of contaminated cells that nonetheless affect most rows, in which standard casewise robust estimators recover the true parameters as accurately as cellwise estimators, would undermine the claim that cellwise methods are required.
Figures



read the original abstract
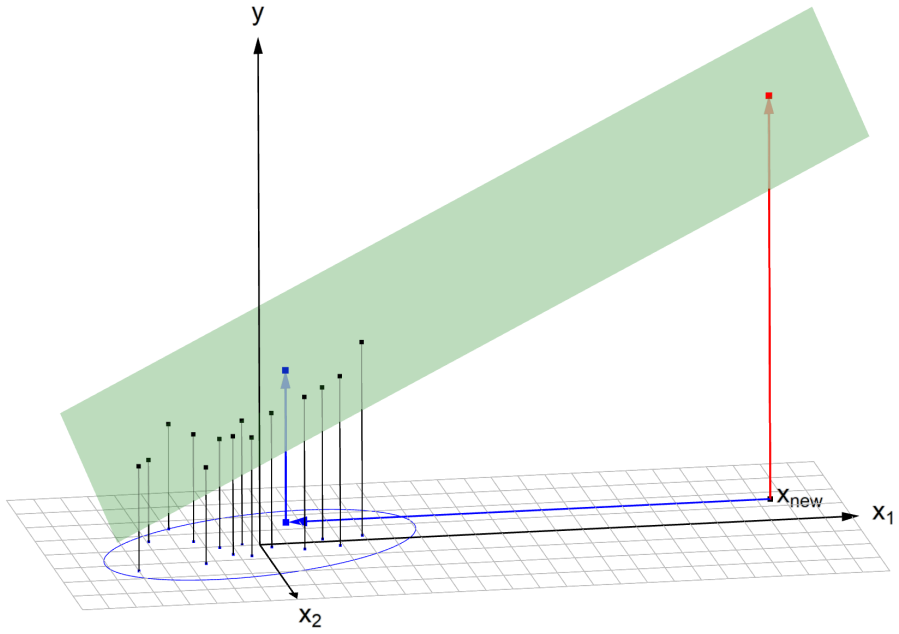
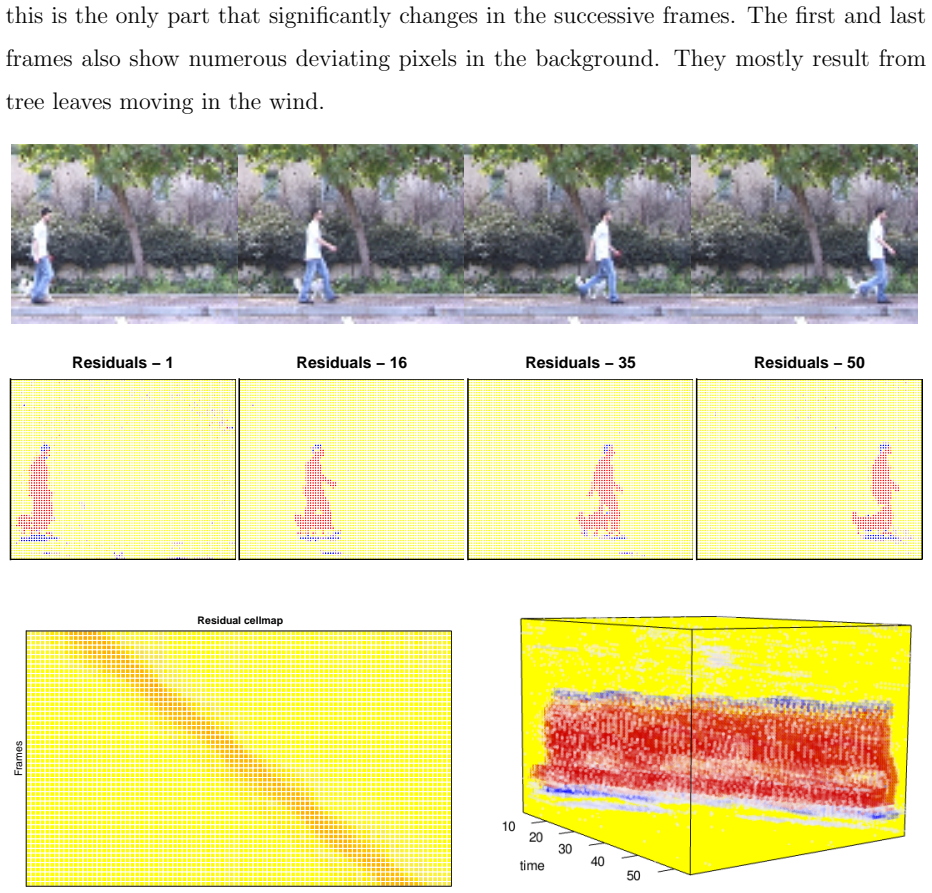
In statistics and machine learning, the traditional meaning of the terms `outlier' and `anomaly' is a case in the dataset that behaves differently from the bulk of the data. This raises suspicion that it may belong to a different population. But nowadays increasing attention is being paid to so-called cellwise outliers. These are individual values somewhere in the data matrix (or data tensor). Depending on the dimension, even a relatively small proportion of outlying cells can contaminate over half the cases, which is a problem for existing casewise methods. It turns out that detecting cellwise outliers as well as constructing cellwise robust methods requires techniques that are quite different from the casewise setting. For instance, one has to let go of some intuitive equivariance properties. The problem is difficult, but the past decade has seen substantial progress. For high-dimensional data the cellwise approach is becoming dominant, and typically can deal with missing values as well. We review developments in the estimation of location and covariance matrices as well as regression methods, principal component analysis, methods for tensor data, and various other settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a review of developments in cellwise outlier detection and robust methods for data matrices and tensors. It contrasts cellwise outliers (individual aberrant entries) with traditional casewise outliers, notes that under an independent contamination model even modest cellwise contamination fractions can affect over half the observations in high dimensions, and argues that cellwise techniques require different tools (including relaxation of some equivariance properties). The review covers progress in location and covariance estimation, regression, PCA, tensor methods, and related settings, concluding that cellwise approaches are becoming dominant for high-dimensional data and often accommodate missing values.
Significance. As a timely synthesis of the literature, the review usefully documents the shift toward cellwise robust procedures in high-dimensional statistics and their compatibility with missing-data handling. If the cited developments are accurately summarized, the paper provides a consolidated reference that can orient researchers to the key distinctions, technical challenges, and available methods in this area.
major comments (2)
- [Abstract / Introduction] The central contamination claim (small cellwise fraction contaminating >50% of cases) is stated in the abstract and introduction but would benefit from an explicit short derivation or citation to the independent contamination model (1-α)^p in the opening section, to make the quantitative motivation self-contained for readers unfamiliar with the model.
- [Conclusion / Summary of methods] The statement that cellwise methods 'typically can deal with missing values as well' is asserted without a dedicated subsection or table summarizing which reviewed methods (location, regression, PCA, tensor) explicitly handle missingness and under what assumptions; this weakens the comparative claim.
minor comments (2)
- [Abstract] The abstract introduces the term 'anomaly' alongside 'outlier' but does not clarify whether the cellwise framework treats them identically or distinguishes them; a brief sentence would improve precision.
- [Introduction] Notation for cellwise contamination probability (α) and dimension (p) is used informally in the text; consistent definition in a preliminary section would aid readability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript and for the helpful suggestions. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Introduction] The central contamination claim (small cellwise fraction contaminating >50% of cases) is stated in the abstract and introduction but would benefit from an explicit short derivation or citation to the independent contamination model (1-α)^p in the opening section, to make the quantitative motivation self-contained for readers unfamiliar with the model.
Authors: We agree with this suggestion. To make the motivation more self-contained, we will include a brief derivation of the independent contamination model in the introduction. Specifically, we will explain that under the model where each cell is contaminated independently with probability α, the probability that a given case remains uncontaminated is (1-α)^p, so the expected proportion of contaminated cases is 1-(1-α)^p. For example, with p=100 and α=0.01 this exceeds 0.63. We will also add a citation to the original reference for this model. revision: yes
-
Referee: [Conclusion / Summary of methods] The statement that cellwise methods 'typically can deal with missing values as well' is asserted without a dedicated subsection or table summarizing which reviewed methods (location, regression, PCA, tensor) explicitly handle missingness and under what assumptions; this weakens the comparative claim.
Authors: We appreciate this observation. In the revised manuscript, we will add a summary table (or a dedicated paragraph in the conclusion) that lists the main methods reviewed in each section (location/covariance, regression, PCA, tensors) and indicates whether they handle missing values, along with the underlying assumptions (e.g., missing at random). This will provide concrete support for the claim that cellwise approaches often accommodate missing data. revision: yes
Circularity Check
No significant circularity in this review paper
full rationale
This is a review summarizing external literature on cellwise outlier methods without presenting new derivations, equations, fitted parameters, or predictions. The central descriptive claim that cellwise approaches are becoming dominant for high-dimensional data follows from documented field progress and external citations rather than internal reduction. The contamination statement (small cellwise fraction contaminating over half the cases) is a direct mathematical consequence of the independent contamination model (1-α)^p dropping below 0.5 for large p, which requires no self-definition, self-citation chain, or ansatz from the present paper. No load-bearing steps reduce to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking uncleareven a relatively small proportion of outlying cells can contaminate over half the cases... cellwise breakdown value... ε*_n(bμ,X) ≤ ⌊n/d⌋/n ≈ 1/d
Reference graph
Works this paper leans on
-
[1]
Aerts, S. and I. Wilms (2017). Cellwise robust regularized discriminant analysis. Statistical Analysis and Data Mining: The ASA Data Science Journal\/ 10\/ (6), 436--447
work page 2017
- [2]
-
[3]
Alfons, A. (2022). robustHD : Robust methods for high-dimensional data. R package, https://CRAN.R-project.org/package=robustHD, DOI 10.32614/CRAN.package.robustHD
-
[4]
Alqallaf, F., S. Van Aelst, V. J. Yohai, and R. H. Zamar (2009). Propagation of outliers in multivariate data. The Annals of Statistics\/ 37 , 311--331
work page 2009
-
[5]
Ballard, G. and T. G. Kolda (2025). Tensor Decompositions for Data Science . Cambridge University Press
work page 2025
-
[6]
Bezdek, J., R. Hathaway, R. Howard, C. Wilson, and M. Windham (1987). Local convergence analysis of a grouped variable version of coordinate descent. Journal of Optimization Theory and Applications\/ 54 , 471--477
work page 1987
-
[7]
Bi, X., X. Tang, Y. Yuan, Y. Zhang, and A. Qu (2021). Tensors in statistics. Annual Review of Statistics and Its Application\/ 8 , 345--368
work page 2021
-
[8]
Bottmer, L., C. Croux, and I. Wilms (2022). Sparse regression for large data sets with outliers. European Journal of Operational Research\/ 297\/ (2), 782--794
work page 2022
-
[9]
Boudt, K., J. Cornelissen, and C. Croux (2012). The gaussian rank correlation estimator: robustness properties. Statistics and Computing\/ 22\/ (2), 471--483
work page 2012
- [10]
-
[11]
Centofanti, F., M. Hubert, and P. J. Rousseeuw (2025). Cellwise and casewise robust covariance in high dimensions. arXiv preprint, https://arxiv.org/abs/2505.19925 \/
-
[12]
Centofanti, F., M. Hubert, and P. J. Rousseeuw (2026). Robust principal components by casewise and cellwise weighting. Technometrics, to appear \/ \!\! , \; https://doi.org/10.1080/00401706.2026.2643216\,
-
[13]
Christidis, A., J. Pyneeandee, and G. Cohen-Freue (2026). Fast and Scalable Cellwise-Robust Ensembles for High-Dimensional Data . arXiv preprint, https://arxiv.org/abs/2603.20940 \/
-
[14]
Croux, C., P. Filzmoser, and H. Fritz (2013). Robust S parse P rincipal C omponent A nalysis. Technometrics\/ 55 , 202--214
work page 2013
-
[15]
Croux, C., P. Filzmoser, and M. Oliveira (2007). Algorithms for P rojection- P ursuit R obust P rincipal C omponent A nalysis. Chemometrics and Intelligent Laboratory Systems\/ 87 , 218--225
work page 2007
-
[16]
Croux, C., P. Filzmoser, G. Pison, and P. J. Rousseeuw (2003). Fitting multiplicative models by robust alternating regressions. Statistics and Computing\/ 13 , 23--36
work page 2003
-
[17]
Croux, C. and V. \"O llerer (2016). Robust and sparse estimation of the inverse covariance matrix using rank correlation measures. In Recent Advances in Robust Statistics: Theory and Applications , pp.\ 35--55. Springer
work page 2016
-
[18]
Danilov, M. (2010). Robust estimation of multivariate scatter in non-affine equivariant scenarios . Ph.\ D. thesis, Statistics Dept
work page 2010
-
[19]
Danilov, M., V. J. Yohai, and R. H. Zamar (2012). Robust estimation of multivariate location and scatter in the presence of missing data. Journal of the American Statistical Association\/ 107 , 1178--1186
work page 2012
-
[20]
De La Torre, F. and M. J. Black (2003). A framework for robust subspace learning. International Journal of Computer Vision\/ 54 , 117--142
work page 2003
-
[21]
Donoho, D. and P. Huber (1983). The notion of breakdown point. In P. Bickel, K. Doksum, and J. Hodges (Eds.), A Festschrift for Erich Lehmann , Belmont, pp.\ 157--184. Wadsworth
work page 1983
-
[22]
Donoho, D. L. (1982). Breakdown properties of multivariate location estimators. P h D qualifying paper, H arvard U niversity
work page 1982
-
[23]
Engelen, S. and M. Hubert (2011). Detecting outlying samples in a parallel factor analysis model. Analytica Chimica Acta\/ 705 , 155--165
work page 2011
-
[24]
Esbensen, K., T. Midtgaard, and S. Sch\"onkopf (1996). Multivariate Analysis in Practice: A Training Package . Camo As, Oslo
work page 1996
-
[25]
Farcomeni, A. (2014). Robust constrained clustering in presence of entry-wise outliers. Technometrics\/ 56\/ (1), 102--111
work page 2014
-
[26]
Farcomeni, A. and A. Leung (2019). Package snipEM: Snipping Methods for Robust Estimation and Clustering . CRAN, R package version 1.0.1
work page 2019
-
[27]
Friedman, J., T. Hastie, and R. Tibshirani (2008). Sparse inverse covariance estimation with the graphical lasso. Biostatistics\/ 9\/ (3), 432--441
work page 2008
-
[28]
Garc \' a-Escudero, L.-A., D. Rivera-Garc \' a, A. Mayo-Iscar, and J. Ortega (2021). Cluster analysis with cellwise trimming and applications for the robust clustering of curves. Information Sciences\/ 573 , 100--124
work page 2021
-
[29]
Gervini, D. and V. J. Yohai (2002). A class of robust and fully efficient regression estimators. The Annals of Statistics\/ 30\/ (2), 583--616
work page 2002
-
[30]
Gnanadesikan, R. and J. R. Kettenring (1972). Robust estimates, residuals, and outlier detection with multiresponse data. Biometrics\/ 28 , 81--124
work page 1972
-
[31]
Grygar, T. M., U. Radojičić, I. Pavlů, S. Greven, J. G. Nešlehová, Štěpánka Tůmová, and K. Hron (2024). Exploratory functional data analysis of multivariate densities for the identification of agricultural soil contamination by risk elements. Journal of Geochemical Exploration\/ 259 , 107416
work page 2024
-
[32]
Hampel, F. R., E. M. Ronchetti, P. Rousseeuw, and W. A. Stahel (1986). Robust Statistics: the Approach based on Influence Functions . Wiley-Interscience, New York
work page 1986
-
[33]
Hampel, F. R., P. J. Rousseeuw, and E. Ronchetti (1981). The Change-of-Variance Curve and Optimal Redescending M-Estimators . Journal of the American Statistical Association\/ 76\/ (375), 643--648
work page 1981
-
[34]
Hirari, M., F. Centofanti, M. Hubert, and S. Van Aelst (2026a). Casewise and cellwise robust multilinear principal component analysis. Journal of Computational and Graphical Statistics, to appear \/ \!\! , \;https://doi.org/10.1080/10618600.2026.2637632
-
[35]
Hirari, M., F. Centofanti, M. Hubert, and S. Van Aelst (2026b). Robust tensor-on-tensor regression. arXiv preprint, https://arxiv.org/abs/2603.25911 \/
-
[36]
Hirari, M., M. Hubert, and P. J. Rousseeuw (2025). Graphical tools for visualizing cellwise and casewise outliers. Journal of Data Science, Statistics, and Visualisation,\/ 5\/ (10), DOI (https://doi.org/jdssv.v5i10.165)
work page 2025
-
[37]
Huber, P. J. (1964). Robust Estimation of a Location Parameter . The Annals of Mathematical Statistics\/ 35\/ (1), 73 -- 101
work page 1964
-
[38]
Hubert, M. and M. Hirari (2024). MacroPARAFAC for handling rowwise and cellwise outliers in incomplete multiway data. Chemometrics and Intelligent Laboratory Systems\/ 251 , 105170
work page 2024
-
[39]
Hubert, M., T. Reynkens, E. Schmitt, and T. Verdonck (2016). Sparse PCA for H igh- D imensional D ata W ith O utliers. Technometrics\/ 58 , 424--434
work page 2016
-
[40]
Hubert, M., P. J. Rousseeuw, and P. Segaert (2015). Multivariate functional outlier detection (with discussion). Statistical Methods and Applications\/ 24 , 177--202
work page 2015
-
[41]
Hubert, M., P. J. Rousseeuw, and W. Van den Bossche (2019). Macro PCA : An all-in-one PCA method allowing for missing values as well as cellwise and rowwise outliers. Technometrics\/ 61\/ (4), 459--473
work page 2019
-
[42]
Hubert, M., P. J. Rousseeuw, and K. Vanden Branden (2005). ROBPCA : A new approach to robust principal component analysis. Technometrics\/ 47 , 64--79
work page 2005
-
[43]
Hubert, M., J. Van Kerckhoven, and T. Verdonck (2012). Robust PARAFAC for incomplete data. Journal of Chemometrics\/ 26 , 290--298
work page 2012
-
[44]
Inoue, K., K. Hara, and K. Urahama (2009). Robust multilinear principal component analysis. In 2009 IEEE 12th International Conference on Computer Vision , pp.\ 591--597
work page 2009
-
[45]
Katayama, S., H. Fujisawa, and M. Drton (2018). Robust and sparse G aussian graphical modelling under cell-wise contamination. Stat\/ 7\/ (1), e181
work page 2018
-
[46]
Lee, H. Y., M. R. Gahrooei, H. Liu, and M. Pacella (2024). Robust tensor-on-tensor regression for multidimensional data modeling. IISE Transactions\/ 56\/ (1), 43--53
work page 2024
-
[47]
Leggett, S. (2021). Migration and cultural integration in the early medieval cemetery of finglesham, kent, through stable isotopes. Archaeological and Anthropological Sciences\/ 13\/ (10), 171
work page 2021
-
[48]
Leung, A., M. Danilov, V. Yohai, and R. Zamar (2019). GSE : Robust Estimation in the Presence of Cellwise and Casewise Contamination and Missing Data . CRAN, R package version 4.2, https://CRAN.R-project.org/package=GSE
work page 2019
-
[49]
Leung, A., V. Yohai, and R. Zamar (2017). Multivariate location and scatter matrix estimation under cellwise and casewise contamination. Computational Statistics & Data Analysis\/ 111 , 59--76
work page 2017
-
[50]
Leung, A., H. Zhang, and R. Zamar (2016). Robust regression estimation and inference in the presence of cellwise and casewise contamination. Computational Statistics & Data Analysis\/ 99 , 1--11
work page 2016
-
[51]
Liu, A., R. Mukhopadhyay, and M. Markatou (2025). MDDC: An R and Python package for adverse event identification in pharmacovigilance data . Springer Nature Scientific Reports\/ 15 , 21317
work page 2025
- [52]
-
[53]
Lock, E. F. (2018). Tensor-on-tensor regression. Journal of Computational and Graphical Statistics\/ 27\/ (3), 638--647
work page 2018
-
[54]
Loh, P.-L. and X. L. Tan (2018). High-dimensional robust precision matrix estimation: Cellwise corruption under -contamination. Electronic Journal of Statistics\/ 12 , 1429--1467
work page 2018
-
[55]
Lopuha\"a, H. P. and P. J. Rousseeuw (1991). Breakdown points of affine equivariant estimators of multivariate location and covariance matrices. The Annals of Statistics\/ 19 , 229--248
work page 1991
-
[56]
Lu, H., K. N. Plataniotis, and A. N. Venetsanopoulos (2008). MPCA : Multilinear principal component analysis of tensor objects. IEEE Transactions on Neural Networks\/ 19\/ (1), 18--39
work page 2008
-
[57]
Maronna, R. (2005). Principal components and orthogonal regression based on robust scales. Technometrics\/ 47 , 264--273
work page 2005
-
[58]
Maronna, R. A. and V. J. Yohai (2008). Robust low-rank approximation of data matrices with elementwise contamination. Technometrics\/ 50\/ (3), 295--304
work page 2008
-
[59]
Mayrhofer, M., U. Radojičić, and P. Filzmoser (2025). Robust covariance estimation and explainable outlier detection for matrix-valued data. Technometrics\/ 67\/ (3), 516--530
work page 2025
-
[60]
\"O llerer, V., A. Alfons, and C. Croux (2016). The shooting S -estimator for robust regression. Computational Statistics\/ 31\/ (3), 829--844
work page 2016
-
[61]
\"O llerer, V. and C. Croux (2015). Robust high-dimensional precision matrix estimation. In Modern Nonparametric, Robust and Multivariate methods , pp.\ 325--350. Springer
work page 2015
-
[62]
Pfeiffer, P., L. Vana-Gür, and P. Filzmoser (2025). Cellwise robust and sparse principal component analysis. Advances in Data Analysis and Classification, to appear \/
work page 2025
-
[63]
Pravdova, V., B. Walczak, and D. Massart (2001). A robust version of the T ucker3 model. Chemometrics and Intelligent Laboratory Systems\/ 59 , 75--88
work page 2001
-
[64]
Raymaekers, J. and P. J. Rousseeuw (2021a). Fast robust correlation for high-dimensional data. Technometrics\/ 63 , 184--198, https://doi.org/10.1080/00401706.2019.1677270
-
[65]
Raymaekers, J. and P. J. Rousseeuw (2021b). Handling cellwise outliers by sparse regression and robust covariance. Journal of Data Science, Statistics, and Visualisation\/ 1\/ (3), DOI https://doi.org/10.52933/jdssv.v1i3.18)
-
[66]
Raymaekers, J. and P. J. Rousseeuw (2022). cellWise : Analyzing data with cellwise outliers. R package, https://CRAN.R-project.org/package=cellWise, DOI 10.32614/CRAN.package.cellWise
-
[67]
Raymaekers, J. and P. J. Rousseeuw (2024a). The C ellwise M inimum C ovariance D eterminant estimator. Journal of the American Statistical Association\/ 119 , 2610--2621, DOI https://doi.org/10.1080/01621459.2023.2267777
-
[68]
Raymaekers, J. and P. J. Rousseeuw (2024b). Transforming variables to central normality. Machine Learning\/ 113 , 4953–4975, DOI https://doi.org/10.1007/s10994--021--05960--5
-
[69]
Raymaekers, J. and P. J. Rousseeuw (2026a). Challenges of cellwise outliers. Econometrics and Statistics\/ 38 , 6--25, DOI https://doi.org/10.1016/j.ecosta.2024.02.002
- [70]
-
[71]
Rousseeuw, P. J. (1984). Least median of squares regression. Journal of the American Statistical Association\/ 79 , 871--880
work page 1984
-
[72]
Rousseeuw, P. J. (2026). Analyzing cellwise weighted data. Econometrics and Statistics\/ 38 , 31--41, DOI https://doi.org/10.1016/j.ecosta.2023.01.007
-
[73]
Rousseeuw, P. J. and C. Croux (1993). Alternatives to the median absolute deviation. Journal of the American Statistical Association\/ 88 , 1273--1283
work page 1993
-
[74]
Rousseeuw, P. J. and W. Van den Bossche (2018). Detecting deviating data cells. Technometrics\/ 60 , 135--145
work page 2018
-
[75]
Santos, F. (2020). Modern methods for old data: An overview of some robust methods for outliers detection with applications in osteology. Journal of Archaeological Science: Reports\/ 32 , 102423
work page 2020
-
[76]
Saraceno, G. and C. Agostinelli (2021). Robust multivariate estimation based on statistical depth filters. TEST\/ 30 , 1--25
work page 2021
-
[77]
Saraceno, G., F. Alqallaf, and C. Agostinelli (2021). A R obust S eemingly U nrelated R egressions F or R ow- W ise A nd C ell- W ise C ontamination. arXiv preprint arXiv:2107.00975\/
-
[78]
She, Y. and A. B. Owen (2011). Outlier detection using nonconvex penalized regression. Journal of the American Statistical Association\/ 106\/ (494), 626--639
work page 2011
-
[79]
a tzungen: infinitesimale O ptimalit \
Stahel, W. A. (1981). Robuste S ch \"a tzungen: infinitesimale O ptimalit \"a t und S ch \"a tzungen von K ovarianzmatrizen . Ph.\ D. thesis, Fachgruppe f\"ur Statistik
work page 1981
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.