Recognition: no theorem link
Grading the Unspoken: Evaluating Tacit Reasoning in Quantum Field Theory and String Theory with LLMs
Pith reviewed 2026-05-13 22:39 UTC · model grok-4.3
The pith
LLMs achieve near-ceiling scores on explicit quantum field theory derivations but degrade when required to reconstruct omitted reasoning steps or reorganize representations under global consistency constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
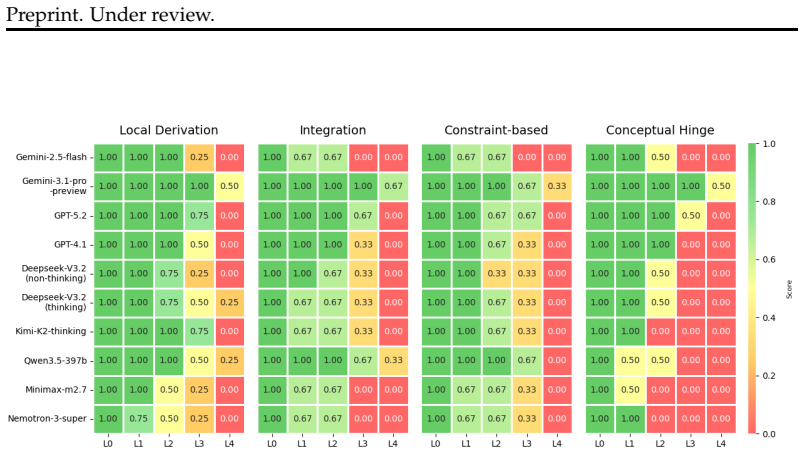
Contemporary LLMs exhibit near-ceiling performance on explicit derivations within stable conceptual frames in quantum field theory and string theory, yet display systematic degradation when tasks require reconstruction of omitted reasoning steps or reorganization of representations under global consistency constraints. These failures arise not only from absent intermediate steps but from instability in representation selection, where models frequently fail to identify the correct conceptual framing needed to resolve implicit tensions.
What carries the argument
The five-level grading rubric that separates statement correctness, key concept awareness, reasoning chain presence, tacit step reconstruction, and enrichment.
If this is right
- Standard answer-matching metrics are inadequate for capturing layered correctness in abstract theoretical physics.
- Models need improved mechanisms for maintaining global consistency across implicit constraints.
- Tacit reasoning tasks serve as a sensitive probe for epistemic limits in current AI evaluation paradigms.
- Performance gaps appear specifically when representation selection must resolve unspoken tensions rather than follow explicit instructions.
Where Pith is reading between the lines
- The same rubric and question set could be applied to other highly abstract domains such as algebraic geometry to map similar reasoning limits.
- If future models close the tacit reconstruction gap, the tasks could become a practical benchmark for assessing readiness to assist in theoretical research.
- Training data for LLMs may systematically under-represent the reconstruction of unspoken steps typical in expert theoretical discourse.
Load-bearing premise
The expert-curated set of twelve questions and the five-level rubric accurately isolate and measure tacit reasoning demands without introducing selection bias or rubric-specific artifacts.
What would settle it
An independent large language model that achieves ceiling scores on all five rubric levels across the same twelve questions, or a re-grading by multiple independent experts that shows the original rubric systematically misclassifies tacit reconstruction in model outputs.
Figures

read the original abstract
Large language models have demonstrated impressive performance across many domains of mathematics and physics. One natural question is whether such models can support research in highly abstract theoretical fields such as quantum field theory and string theory. Evaluating this possibility faces an immediate challenge: correctness in these domains is layered, tacit, and fundamentally non-binary. Standard answer-matching metrics fail to capture whether intermediate conceptual steps are properly reconstructed or whether implicit structural constraints are respected. We construct a compact expert-curated dataset of twelve questions spanning core areas of quantum field theory and string theory, and introduce a five-level grading rubric separating statement correctness, key concept awareness, reasoning chain presence, tacit step reconstruction, and enrichment. Evaluating multiple contemporary LLMs, we observe near-ceiling performance on explicit derivations within stable conceptual frames, but systematic degradation when tasks require reconstruction of omitted reasoning steps or reorganization of representations under global consistency constraints. These failures are driven not only by missing intermediate steps, but by an instability in representation selection: models often fail to identify the correct conceptual framing required to resolve implicit tensions. We argue that highly abstract theoretical physics provides a uniquely sensitive lens on the epistemic limits of current evaluation paradigms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript constructs an expert-curated dataset of twelve questions spanning core topics in quantum field theory and string theory, together with a five-level rubric that separately scores statement correctness, key concept awareness, reasoning chain presence, tacit step reconstruction, and enrichment. Evaluation of several contemporary LLMs shows near-ceiling performance on explicit derivations within stable frames but systematic degradation on tasks that require reconstruction of omitted steps or reorganization of representations to satisfy global consistency constraints; the authors attribute the failures primarily to instability in selecting the appropriate conceptual framing.
Significance. If the reported pattern survives larger-scale validation, the work supplies a sensitive diagnostic for the epistemic limits of LLMs in domains where correctness is layered and tacit. By moving beyond binary answer-matching to a multi-dimensional rubric, it offers a concrete template that could guide future benchmark design in theoretical physics and related abstract fields. The expert curation itself is a methodological strength that distinguishes the study from purely automated evaluations.
major comments (3)
- [§3] §3 (Dataset Construction and Rubric): The headline claim of systematic degradation on tacit reconstruction and global consistency is supported by only twelve questions; no inter-rater reliability statistics, no pilot validation of the five-level rubric against alternative schemes, and no statistical controls for scoring variability are reported. With such a compact expert-curated set, even modest inconsistencies in expert scoring or rubric-specific artifacts could generate the observed pattern without implying broader LLM limitations.
- [§3] §3: Explicit criteria for question selection, difficulty calibration, and coverage of tacit demands are not provided. Without these, it remains unclear whether the twelve items were chosen to maximize the contrast between explicit and tacit performance or whether the contrast is an artifact of the particular sample.
- [Results] Results section: The dataset and exact prompts are not released. Reproducibility is therefore impossible, and independent verification of the rubric application or extension to additional models cannot be performed.
minor comments (2)
- [Abstract] The abstract introduces the rubric dimension 'enrichment' without a concise definition; a one-sentence gloss in the abstract would improve immediate clarity.
- [Introduction] A short paragraph comparing the proposed rubric to existing physics LLM benchmarks (e.g., those based on textbook problems or multiple-choice sets) would better situate the novelty of the five-level scheme.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We agree that the small scale of the study and lack of released materials represent genuine limitations that must be addressed for greater transparency and credibility. We will revise the manuscript to incorporate explicit selection criteria, rubric development details, and full data release while maintaining that the expert-curated approach provides a valuable initial diagnostic for tacit reasoning limits. Point-by-point responses to the major comments are provided below.
read point-by-point responses
-
Referee: §3 (Dataset Construction and Rubric): The headline claim of systematic degradation on tacit reconstruction and global consistency is supported by only twelve questions; no inter-rater reliability statistics, no pilot validation of the five-level rubric against alternative schemes, and no statistical controls for scoring variability are reported. With such a compact expert-curated set, even modest inconsistencies in expert scoring or rubric-specific artifacts could generate the observed pattern without implying broader LLM limitations.
Authors: We acknowledge that the dataset of twelve questions is small and that the absence of formal inter-rater reliability statistics or pilot validation against alternative rubrics is a methodological gap. The compact size was chosen deliberately to enable in-depth expert analysis of tacit elements that would be difficult to scale without diluting quality. In the revision we will expand §3 with a description of the iterative rubric development process performed by the expert authors, any available internal consistency notes from curation, and an explicit discussion of scoring variability as a limitation. We will also frame the results as an initial diagnostic rather than a definitive claim, directing readers to the need for larger-scale follow-up studies. revision: partial
-
Referee: §3: Explicit criteria for question selection, difficulty calibration, and coverage of tacit demands are not provided. Without these, it remains unclear whether the twelve items were chosen to maximize the contrast between explicit and tacit performance or whether the contrast is an artifact of the particular sample.
Authors: We will revise §3 to include explicit criteria for question selection. Each question was chosen to cover core QFT and string theory topics while deliberately balancing items that admit stable explicit derivations against those requiring reconstruction of omitted steps or resolution of implicit global constraints. Difficulty was calibrated via expert judgment on the depth of tacit knowledge needed. The revision will add a summary table or paragraph detailing the explicit-versus-tacit focus and selection rationale for each item to demonstrate that the contrast is not an artifact of arbitrary sampling. revision: yes
-
Referee: Results section: The dataset and exact prompts are not released. Reproducibility is therefore impossible, and independent verification of the rubric application or extension to additional models cannot be performed.
Authors: We agree that reproducibility requires public release of the materials. In the revised manuscript we will include the complete set of twelve questions, the exact prompts supplied to each model, and the full five-level rubric as supplementary material. We will also deposit these resources in a public repository (e.g., GitHub) with a DOI upon acceptance so that independent verification and extension to new models become possible. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper reports direct empirical observations from scoring LLM outputs against an independently defined five-level rubric on a fixed set of twelve expert-curated questions. No derivation, prediction, or central claim reduces by construction to fitted parameters, self-referential definitions, or load-bearing self-citations; the performance patterns (near-ceiling on explicit derivations, degradation on tacit reconstruction) are measured outputs rather than re-expressions of the input rubric or dataset. The methodology is self-contained and externally falsifiable via replication on the same questions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five-level rubric validly separates statement correctness, key concept awareness, reasoning chain presence, tacit step reconstruction, and enrichment in theoretical physics.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
http://www.w3.org/1999/02/22-rdf-syntax-ns#
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.