Recognition: no theorem link
PolyBench: Benchmarking LLM Forecasting and Trading Capabilities on Live Prediction Market Data
Pith reviewed 2026-05-13 19:13 UTC · model grok-4.3
The pith
Only two of seven LLMs achieve positive returns on live prediction market data while five lose money despite high confidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
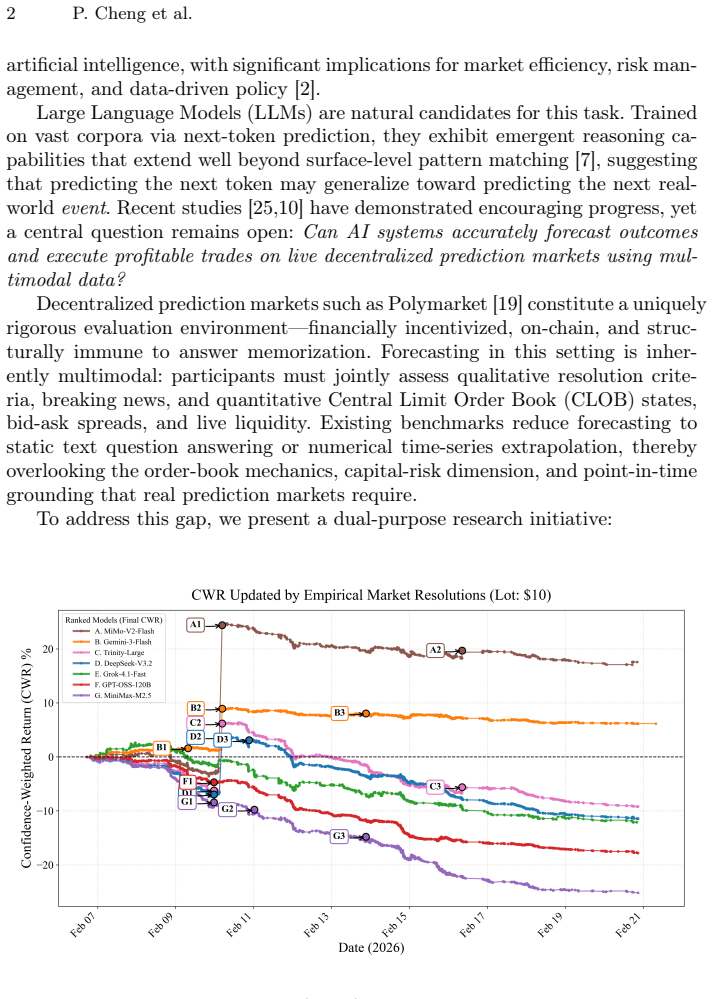
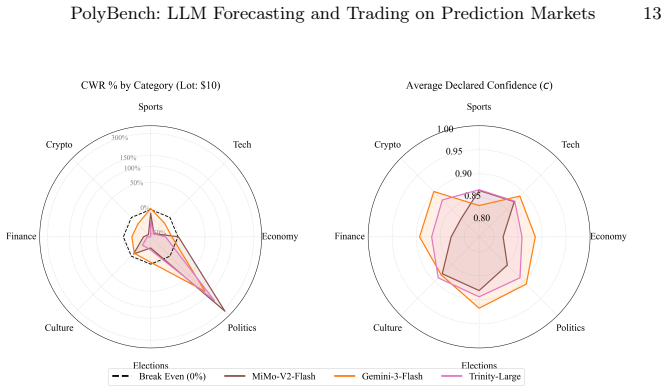
PolyBench records point-in-time cross-sections of 38,666 binary prediction markets together with Central Limit Order Book states and real-time news, then evaluates seven state-of-the-art LLMs on 36,165 predictions generated under identical market conditions; the results show that only MiMo-V2-Flash and Gemini-3-Flash produce positive financial returns via the proposed Confidence-Weighted Return metric while the remaining five models incur losses despite uniformly high stated confidence.
What carries the argument
PolyBench, a multimodal benchmark that synchronously couples live prediction-market snapshots with order-book dynamics and news streams and evaluates forecasts through realistic order-book execution simulation to compute directional accuracy, Confidence-Weighted Return, APY, and Sharpe ratio.
If this is right
- Directional accuracy alone is insufficient to certify an LLM as a capable forecaster; profitability under execution simulation provides a stricter test.
- High self-reported confidence in LLMs does not reliably translate into positive trading outcomes in live markets.
- Multimodal inputs that combine news and order-book data are required to expose gaps hidden by language-only benchmarks.
- The observed performance split between two profitable models and five losing ones indicates that current LLM training leaves most systems poorly calibrated for real-time financial uncertainty.
- PolyBench supplies a timestamp-locked, financially grounded dataset that future work can use to track progress without contamination from static training data.
Where Pith is reading between the lines
- Developers may need to add explicit loss signals from simulated or real trades during fine-tuning to improve confidence calibration in uncertain environments.
- Extending the benchmark to longer holding periods or multi-outcome markets could test whether the current performance gap persists beyond short binary resolutions.
- Platforms that host prediction markets might incorporate similar live benchmarks before deploying LLM-assisted trading tools to limit user losses.
- The divergence suggests that general-purpose scaling alone may not close the gap; targeted training on order-book dynamics and news integration could be necessary for most models.
Load-bearing premise
The order-book execution simulation accurately captures real-world slippage, liquidity, and fees without introducing artifacts that favor or penalize particular models.
What would settle it
Running the identical model predictions as actual trades with real capital on Polymarket and comparing the realized profits or losses against the benchmark's simulated CWR values would confirm or refute the performance rankings.
Figures

read the original abstract
Predicting real-world events from live market signals demands systems that fuse qualitative news with quantitative order-book dynamics under strict temporal discipline -- a challenge existing benchmarks fail to capture. We present \textbf{PolyBench}, a multimodal benchmark derived from Polymarket that records point-in-time cross-sections of 38,666 binary prediction markets spanning 4,997 events, synchronously coupling each snapshot with a Central Limit Order Book (CLOB) state and a real-time news stream. Using PolyBench, we evaluate seven state-of-the-art Large Language Models -- spanning open- and closed-source families -- generating 36,165 predictions under identical, timestamp-locked market states collected between February 6 and 12, 2026. Our multidimensional framework assesses directional accuracy, our proposed Confidence-Weighted Return (CWR), Annualized Percentage Yield (APY), and Sharpe ratio via realistic order-book execution simulation. The results reveal a pronounced performance divergence: only two of seven models achieve positive financial returns -- MiMo-V2-Flash at \textbf{17.6%} CWR and Gemini-3-Flash at 6.2% CWR -- while the remaining five incur losses despite uniformly high stated confidence. These findings highlight the gap between surface-level language fluency and genuine probabilistic reasoning under live market uncertainty, and establish PolyBench as a contamination-proof, financially-grounded evaluation standard for future LLM research. Our dataset and code available at \underline{\href{https://github.com/PolyBench/PolyBench}{https://github.com/PolyBench/PolyBench}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolyBench, a multimodal benchmark derived from 38,666 Polymarket binary prediction markets that synchronously couples timestamp-locked CLOB states and news streams. It evaluates seven LLMs on 36,165 predictions collected over one week, reporting directional accuracy, Confidence-Weighted Return (CWR), APY, and Sharpe ratio computed via order-book execution simulation. The central finding is that only MiMo-V2-Flash (17.6% CWR) and Gemini-3-Flash (6.2% CWR) achieve positive financial returns while the remaining five models incur losses despite uniformly high stated confidence; the work positions PolyBench as a contamination-proof, financially grounded evaluation standard and releases the dataset and code.
Significance. If the execution simulation is shown to be faithful to Polymarket's actual taker/maker fees, depth-based slippage, and partial-fill mechanics, the results would establish a valuable live-market benchmark that directly links LLM outputs to realizable P&L. The timestamp-locked design and public release of data/code are clear strengths that enable reproducible, contamination-resistant evaluation of forecasting and trading capabilities.
major comments (2)
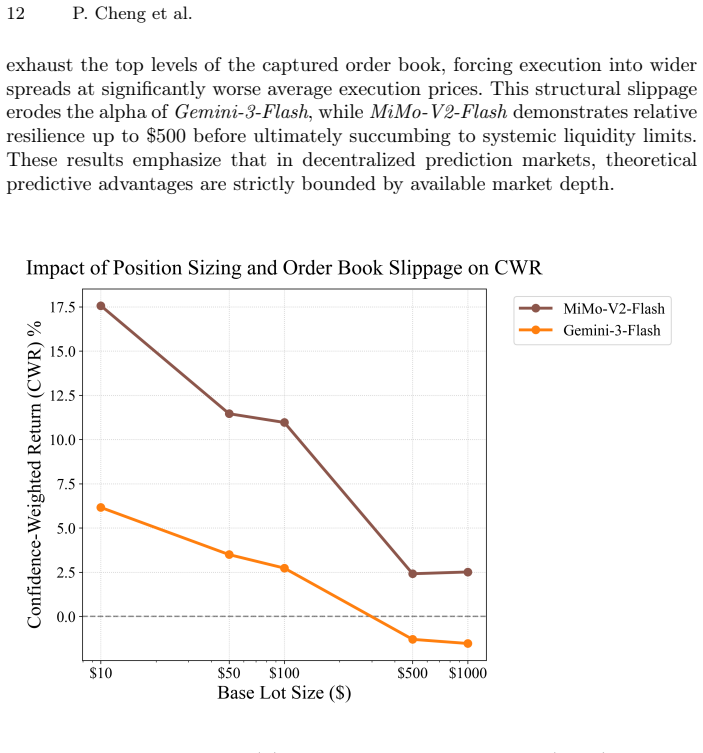
- [Methods (order-book execution simulation)] The order-book execution simulation (described in the methods section on CWR/APY computation) is load-bearing for all financial-return claims, yet the manuscript provides no explicit algorithm, parameters, or validation for (i) mapping stated confidence to position size, (ii) depth consumption and slippage from the recorded CLOB, (iii) fee structure matching Polymarket's taker/maker schedule, or (iv) latency and partial-fill handling. Without these details the sign of the reported CWR gap (17.6 % vs. negative) cannot be verified.
- [Results and Evaluation Framework] The one-week collection window (February 6–12, 2026) and the 36,165-prediction sample are used to support annualized metrics (APY, Sharpe); the paper does not report robustness checks for this short horizon or for potential post-hoc filtering of markets, both of which directly affect the headline claim that five of seven models lose money.
minor comments (2)
- [Tables/Figures] Table and figure captions should explicitly state the exact number of markets and predictions retained after any filtering, and whether the CLOB snapshots include full depth or only top-of-book.
- [Abstract] The abstract states 'February 6 and 12, 2026'; confirm this is the intended future-looking collection period or correct the year if it is a typographical error.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments identify important gaps in methodological transparency and robustness analysis. We address each point below and will incorporate the requested details and checks in the revised manuscript.
read point-by-point responses
-
Referee: [Methods (order-book execution simulation)] The order-book execution simulation (described in the methods section on CWR/APY computation) is load-bearing for all financial-return claims, yet the manuscript provides no explicit algorithm, parameters, or validation for (i) mapping stated confidence to position size, (ii) depth consumption and slippage from the recorded CLOB, (iii) fee structure matching Polymarket's taker/maker schedule, or (iv) latency and partial-fill handling. Without these details the sign of the reported CWR gap (17.6 % vs. negative) cannot be verified.
Authors: We agree that the current description of the execution simulation is insufficient for independent verification. In the revised manuscript we will add a dedicated subsection 'Order-Book Execution Simulation' that supplies: (i) the exact linear mapping from model confidence to position size together with the scaling parameter, (ii) the depth-consumption and slippage model applied to each recorded CLOB snapshot, (iii) the precise taker/maker fee schedule used to match Polymarket's rules, and (iv) the latency (zero-latency benchmark) and partial-fill handling logic. We will also include pseudocode and a short validation example against historical trade data. These additions will allow direct reproduction and sign-checking of the reported CWR values. revision: yes
-
Referee: [Results and Evaluation Framework] The one-week collection window (February 6–12, 2026) and the 36,165-prediction sample are used to support annualized metrics (APY, Sharpe); the paper does not report robustness checks for this short horizon or for potential post-hoc filtering of markets, both of which directly affect the headline claim that five of seven models lose money.
Authors: We acknowledge that the short one-week horizon limits the strength of annualized claims and that explicit robustness checks are warranted. In revision we will add: (a) bootstrapped confidence intervals for APY and Sharpe ratios, (b) sensitivity tables showing how results change when the collection window is shifted or shortened, and (c) an explicit statement confirming that no post-hoc market filtering occurred beyond the pre-specified timestamp-locking rule. We will also report the raw one-week cumulative returns alongside the annualized figures so readers can assess the headline claim in context. revision: yes
Circularity Check
No significant circularity; metrics computed from external market data
full rationale
The paper computes CWR, APY, and Sharpe ratio by feeding LLM predictions into an order-book execution simulator driven by timestamp-locked Polymarket CLOB states and real resolutions. No equation in the provided text reduces these outputs to a fitted parameter defined inside the paper, nor does any self-citation chain or ansatz serve as the load-bearing justification for the headline performance gap. The simulation is an external modeling step whose fidelity is an assumption rather than a definitional identity, matching the reader's assessment of score 2.0 with no self-definitional or fitted-input reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Market outcomes are independent of the models' predictions and can be used as ground truth.
Forward citations
Cited by 1 Pith paper
-
Agentic Forecasting using Sequential Bayesian Updating of Linguistic Beliefs
BLF achieves state-of-the-art binary forecasting on ForecastBench by using linguistic belief states updated in tool-use loops, hierarchical multi-trial logit averaging, and hierarchical Platt scaling calibration.
Reference graph
Works this paper leans on
-
[1]
Finbert: Financial sentiment analysis with pre-trained language models
Araci, D.: Finbert: Financial sentiment analysis with pre-trained language models. arXiv preprint arXiv:1908.10063 (2019)
-
[2]
Science320(5878), 877–878 (2008) PolyBench: LLM Forecasting and Trading on Prediction Markets 15
Arrow, K.J., Forsythe, R., Gorham, M., Hahn, R., Hanson, R., Ledyard, J.O., Levmore, S., Litan, R., Milgrom, P., Nelson, F.D., et al.: The promise of prediction markets. Science320(5878), 877–878 (2008) PolyBench: LLM Forecasting and Trading on Prediction Markets 15
work page 2008
-
[3]
The Annals of Statistics51(2), 816–845 (2023)
Barber, R.F., Candes, E.J., Ramdas, A., Tibshirani, R.J.: Conformal prediction beyond exchangeability. The Annals of Statistics51(2), 816–845 (2023)
work page 2023
-
[4]
Journal of econometrics31(3), 307–327 (1986)
Bollerslev, T.: Generalized autoregressive conditional heteroskedasticity. Journal of econometrics31(3), 307–327 (1986)
work page 1986
-
[5]
Box, G.E., Jenkins, G.M.: Time series analysis: Forecasting and control. Holden- Day (1970)
work page 1970
-
[6]
Box, G.E., Jenkins, G.M.: Time series analysis. forecasting and control. Holden- Day Series in Time Series Analysis (1976)
work page 1976
-
[7]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Bubeck,S.,Chandrasekaran,V.,Eldan,R.,Gehrke,J.,Horvitz,E.,Kamar,E.,Lee, P., Lee, Y.T., Li, Y., Lundberg, S., et al.: Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [8]
-
[9]
Games and Eco- nomic Behavior29(1-2), 7–35 (1999)
Foster, D.P., Vohra, R.: Regret in the on-line decision problem. Games and Eco- nomic Behavior29(1-2), 7–35 (1999)
work page 1999
-
[10]
Advances in Neural Information Processing Systems 37, 50426–50468 (2024)
Halawi,D.,Zhang,F.,Yueh-Han,C.,Steinhardt,J.:Approachinghuman-levelfore- casting with language models. Advances in Neural Information Processing Systems 37, 50426–50468 (2024)
work page 2024
-
[11]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the MATH dataset (2021),https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Neural computation 9(8), 1735–1780 (1997)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation 9(8), 1735–1780 (1997)
work page 1997
-
[13]
A decoder-only foundation model for time-series forecasting.arXiv preprint arXiv:2310.10688, 2023
Jin, M., Wen, S., Liang, Y., Zhang, C., Xue, S., Wang, X., Zhang, J., Wang, M., Chen, H., Li, X., et al.: Time-llm: Time series forecasting by reprogramming large language models. arXiv preprint arXiv:2310.10688 (2023)
- [14]
-
[15]
Philo- sophical Transactions of the Royal Society A379(2194), 20200209 (2021)
Lim, B., Zohren, S.: Time-series forecasting with deep learning: a survey. Philo- sophical Transactions of the Royal Society A379(2194), 20200209 (2021)
work page 2021
-
[16]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
In: The Twelfth International Conference on Learning Representations (2024)
Liu,X.,Yu,H.,Zhang,H.,Xu,Y.,Lei,X.,Lai,H.,Gu,Y.,Ding,H.,Men,K.,Yang, K., et al.: Agentbench: Evaluating llms as agents. In: The Twelfth International Conference on Learning Representations (2024)
work page 2024
-
[18]
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Zhang, C.B.C., Shaaban, M., Ling, J., Shi, S., et al.: Humanity’s last exam (2025),https://arxiv.org/ abs/2501.14249
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Saguillo, O., Ghafouri, V., Kiffer, L., Suarez-Tangil, G.: Unravelling the probabilis- tic forest: Arbitrage in prediction markets. arXiv e-prints pp. arXiv–2508 (2025)
work page 2025
-
[20]
In: Advances in neural information processing systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems. vol. 30 (2017)
work page 2017
-
[21]
BloombergGPT: A Large Language Model for Finance
Wu, S., Irzan, O., Schleiden, S., et al.: Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564 (2023)
work page internal anchor Pith review arXiv 2023
-
[22]
Yang, Q., Mahns, S., Li, S., Gu, A., Wu, J., Xu, H.: Llm-as-a-prophet: Under- standing predictive intelligence with prophet arena (2025),https://arxiv.org/ abs/2510.17638 16 P. Cheng et al
- [23]
-
[24]
Zeng, Z., Liu, J., Chen, S., He, T., Liao, Y., Tian, Y., Wang, J., Wang, Z., Yang, Y., Yin, L., Yin, M., Zhu, Z., Cai, T., Chen, Z., Chen, J., Du, Y., Gao, X., Guo, J., Hu, L., Jiao, J., Li, X., Liu, J., Ni, S., Wen, Z., Zhang, G., Zhang, K., Zhou, X., Blanchet, J., Qiu, X., Wang, M., Huang, W.: Futurex: An advanced live benchmark for llm agents in future...
-
[25]
Advances in Neural Information Processing Systems35, 27293–27305 (2022)
Zou, A., Xiao, T., Jia, R., Kwon, J., Mazeika, M., Li, R., Song, D., Steinhardt, J., Evans, O., Hendrycks, D.: Forecasting future world events with neural networks. Advances in Neural Information Processing Systems35, 27293–27305 (2022)
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.