Recognition: 1 theorem link
· Lean TheoremChinese Language Is Not More Efficient Than English in Vibe Coding: A Preliminary Study on Token Cost and Problem-Solving Rate
Pith reviewed 2026-05-10 19:16 UTC · model grok-4.3
The pith
Empirical tests find no token efficiency advantage for Chinese prompts in LLM coding tasks, with lower success rates than English.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
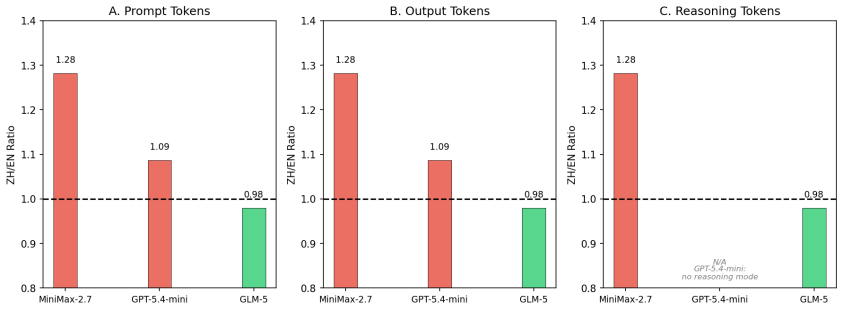
A direct comparison on SWE-bench Lite shows that Chinese prompts produce no consistent token savings over English across tested models. One model incurs 1.28 times higher token costs with Chinese, while another uses fewer tokens; success rates on the same tasks are lower for Chinese in every case. When cost is measured as expected expense per successfully solved task, the joint metric does not favor Chinese. The authors present these outcomes as preliminary evidence that language effects on token cost are model-dependent rather than a general rule.
What carries the argument
Controlled side-by-side measurement of token counts and task resolution rates on identical SWE-bench Lite coding problems, using both Chinese and English prompts across multiple models.
Load-bearing premise
The results assume that the small set of models and the narrow software engineering tasks examined are representative of broader LLM coding use.
What would settle it
A larger evaluation across more models and diverse coding benchmarks that finds consistent 20-40 percent token reductions plus equal or higher success rates with Chinese prompts would falsify the main claim.
Figures





read the original abstract
A claim has been circulating on social media and practitioner forums that Chinese prompts are more token-efficient than English for LLM coding tasks, potentially reducing costs by up to 40\%. This claim has influenced developers to consider switching to Chinese for ``vibe coding'' to save on API costs. In this paper, we conduct a rigorous empirical study using SWE-bench Lite, a benchmark of software engineering tasks, to evaluate whether this claim of Chinese token efficiency holds up to scrutiny. Our results reveal three key findings: First, the efficiency advantage of Chinese is not observed. Second, token cost varies by model architecture in ways that defy simple assumptions: while MiniMax-2.7 shows 1.28x higher token costs for Chinese, GLM-5 actually consumes fewer tokens with Chinese prompts. Third, and most importantly, we found that the success rate when prompting in Chinese is generally lower than in English across all models we tested. We also measure cost efficiency as expected cost per successful task -- jointly accounting for token consumption and task resolution rate. These findings should be interpreted as preliminary evidence rather than a definitive conclusion, given the limited number of models evaluated and the narrow set of benchmarks tested due to resource constraints; they indicate that language effects on token cost are model-dependent, and that practitioners should not expect cost savings or performance gains just by switching their prompt language to Chinese.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical evaluation on SWE-bench Lite to test the circulating claim that Chinese prompts are more token-efficient than English for LLM coding tasks, potentially saving up to 40% in costs. Using a small set of models, it measures token consumption and task success rates for equivalent prompts in each language, finding no general Chinese efficiency advantage (with model-dependent ratios, e.g., 1.28x higher cost for Chinese in MiniMax-2.7 but lower in GLM-5), consistently lower success rates for Chinese prompts, and lower overall cost efficiency when measured as expected cost per successful task. The authors present the work as preliminary due to resource constraints on model and benchmark coverage.
Significance. If the measurements are robust, the study supplies direct counter-evidence to an influential but unverified practitioner claim, showing that prompt-language choice for coding tasks does not produce simple token savings and can degrade resolution rates. It introduces a joint cost-success metric that is more relevant than token count alone and underscores the model-specific nature of tokenization effects, which is useful for the multilingual prompting literature in NLP and software engineering.
minor comments (3)
- The abstract and introduction cite a 'circulating claim' of up to 40% savings but provide no specific source, social-media post, or practitioner reference; adding one or two concrete citations would strengthen the motivation without altering the empirical core.
- The methods section should explicitly state the procedure used to create 'equivalent' Chinese and English prompts (e.g., human translation protocol, back-translation check, or use of a fixed translator) so that readers can assess whether prompt quality differences could contribute to the observed success-rate gap.
- Table or figure captions for token-ratio and success-rate results should include the exact number of tasks per model-language pair and any statistical test (or lack thereof) for the reported differences, given the small sample implied by the 'preliminary' framing.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of our work, as well as the recommendation for minor revision. The report accurately captures our empirical findings on SWE-bench Lite regarding the lack of general Chinese token efficiency, model-dependent effects, and lower success rates for Chinese prompts. Since the report lists no specific major comments, we have no points to address point-by-point and see no need for changes to the manuscript at this stage.
Circularity Check
No circularity: purely empirical token and success-rate measurements
full rationale
The paper reports direct experimental measurements of token consumption and task success rates for Chinese versus English prompts on SWE-bench Lite across a small set of models. No equations, derivations, fitted parameters, ansatzes, or uniqueness theorems appear. Claims follow immediately from the observed counts and rates; authors explicitly flag the narrow scope as a limitation rather than deriving broader conclusions. No self-citation load-bearing steps or reductions by construction exist.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe also measure cost efficiency as expected cost per successful task—jointly accounting for token consumption and task resolution rate. Ceff = Avg. Token Cost per Attempt / Resolution Rate
Reference graph
Works this paper leans on
-
[1]
Chinese is more efficient for llm coding - try it now!https://www
AI Advocate. Chinese is more efficient for llm coding - try it now!https://www. youtube.com/shorts/tbfCOa3XRFc, 2024
2024
-
[2]
Raising the bar on swe- bench verified with claude 3.5 sonnet
Anthropic. Raising the bar on swe- bench verified with claude 3.5 sonnet. https://www.anthropic.com/ engineering/swe-bench-sonnet, 2025
2025
-
[3]
Japanese is the most expensive language in terms of input to- kens.https://dylancastillo.co/ til/counting-tokens.html, 2025
Dylan Castillo. Japanese is the most expensive language in terms of input to- kens.https://dylancastillo.co/ til/counting-tokens.html, 2025
2025
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qim- ing Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Eval- uating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Efficient and effective text encoding for chinese llama and alpaca
Yiming Cui, Ziqing Yang, and Xin Yao. Ef- ficient and effective text encoding for Chi- nese LLaMA and Alpaca.arXiv preprint arXiv:2304.08177, 2023
-
[6]
Swe-bench: Can lan- guage models resolve real-world bugs?arXiv preprint arXiv:2211.15553, 2024
Carlos E Jimenez, Xinyu Yang, Alexander Wet- tig, Shunyu Jiang, Kexin Yao, Jindi Pei, Orr Zheng, Pulli Chen, et al. Swe-bench: Can lan- guage models resolve real-world bugs?arXiv preprint arXiv:2211.15553, 2024
-
[7]
Taku Kudo and John Richardson. Sentence- piece: A simple and language independent sub- word tokenizer and detokenizer for neural text processing.arXiv preprint arXiv:1808.06243, 2018
-
[8]
Introducing swe-bench ver- ified.https://openai.com/ index/introducing-swe-bench- verified/, 2024
OpenAI. Introducing swe-bench ver- ified.https://openai.com/ index/introducing-swe-bench- verified/, 2024
2024
-
[9]
Qiwei Peng, Yekun Chai, and Xuhong Li. Humaneval-xl: A multilingual code gen- eration benchmark for cross-lingual natu- ral language generalization.arXiv preprint arXiv:2402.16694, 2024
-
[10]
Torr, and Adel Bibi
Aleksandar Petrov, Emanuele La Malfa, Philip H.S. Torr, and Adel Bibi. Language model tokenizers introduce unfairness between languages. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[11]
How multilingual is multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4996–5001, 2019
Telmo Pires, Eva Schlinger, and Dan Garrette. How multilingual is multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4996–5001, 2019
2019
-
[12]
Neural Machine Translation of Rare Words with Subword Units
Rico Sennrich, Barry Haddow, and Alexan- dra Birch. Neural machine translation of rare words with subword units.arXiv preprint arXiv:1508.07909, 2015
work page internal anchor Pith review arXiv 2015
-
[13]
SNS Insider. AI code tools market to hit USD 37.34 billion by 2032.https: //www.globenewswire.com/news- release/2025/09/26/3157060/ 0/en/AI-Code-Tools-Market- to-Hit-USD-37-34-Billion-by- 2032-Driven-by-Rising-Demand- for-Automation-Globally-SNS- Insider.html, 2025. 11
2032
-
[14]
AI — 2025 stack Over- flow developer survey.https://survey
Stack Overflow. AI — 2025 stack Over- flow developer survey.https://survey. stackoverflow.co/2025/ai, 2025
2025
-
[15]
Who is using AI to code? Global diffusion and impact of gen- erative AI.Science, 2026
Georg Tamm et al. Who is using AI to code? Global diffusion and impact of gen- erative AI.Science, 2026. arXiv preprint arXiv:2506.08945
-
[16]
Eight months in, Swedish unicorn Lovable crosses the $100M ARR milestone
TechCrunch. Eight months in, Swedish unicorn Lovable crosses the $100M ARR milestone. https://techcrunch.com/2025/ 07/23/eight-months-in-swedish- unicorn-lovable-crosses-the- 100m-arr-milestone/, 2025
2025
-
[17]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Li, Dayiheng Liu, Fei Huang, Guanting Wei, Huan Lin, et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
arXiv preprint arXiv:2306.05179 , year=
Wenxuan Zhang, Sharifah Mahani Aljunied, Chang Gao, Yew Ken Chia, and Lidong Bing. M3exam: A multilingual, multimodal, multi- level benchmark for examining large language models.arXiv preprint arXiv:2306.05179, 2023. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.