Recognition: no theorem link
CROP: Token-Efficient Reasoning in Large Language Models via Regularized Prompt Optimization
Pith reviewed 2026-05-10 17:52 UTC · model grok-4.3
The pith
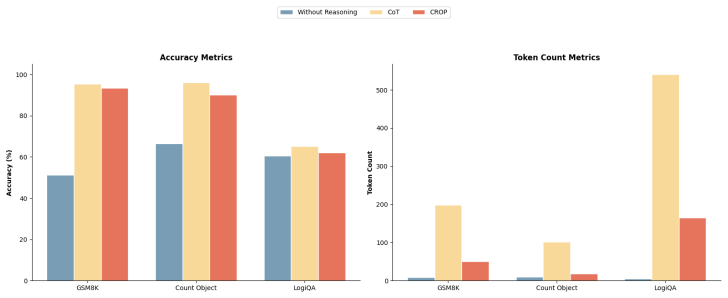
CROP adds length regularization to prompt optimization, cutting token use by over 80 percent with competitive accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that regularizing prompt optimization for response length produces prompts that elicit much shorter yet still accurate reasoning. By adding a feedback signal that comments on the length of generated responses, the optimization loop finds prompts whose outputs contain only the necessary information. This results in an 80.6% drop in tokens used while accuracy on the three evaluated datasets stays competitive.
What carries the argument
The dual-feedback mechanism in CROP that combines accuracy evaluation with textual comments on response brevity to guide prompt evolution.
If this is right
- Token-efficient reasoning becomes available for production agentic systems without retraining the underlying models.
- The same optimization technique applies to any reasoning task by changing only the feedback signals.
- Latency and monetary cost of running complex queries fall in proportion to the token reduction.
- Accuracy remains close to the level achieved by accuracy-only optimization on the tested benchmarks.
Where Pith is reading between the lines
- The length feedback idea could be ported to other automatic prompt search methods beyond the one implemented in CROP.
- Similar regularization might be used to control other generation properties such as the number of reasoning steps or the use of specific formats.
- Whether the concise prompts discovered transfer to larger or different language models is not addressed and would require further testing.
Load-bearing premise
That textual feedback on response length added to the optimization process will reliably produce prompts that keep accuracy high while shortening outputs, without creating side effects the experiments do not measure.
What would settle it
Applying CROP to a new reasoning benchmark and finding that the accuracy drop exceeds the nominal decline reported or that token savings fail to materialize.
Figures

read the original abstract
Large Language Models utilizing reasoning techniques improve task performance but incur significant latency and token costs due to verbose generation. Existing automatic prompt optimization(APO) frameworks target task accuracy exclusively at the expense of generating long reasoning traces. We propose Cost-Regularized Optimization of Prompts (CROP), an APO method that introduces regularization on response length by generating textual feedback in addition to standard accuracy feedback. This forces the optimization process to produce prompts that elicit concise responses containing only critical information and reasoning. We evaluate our approach on complex reasoning datasets, specifically GSM8K, LogiQA and BIG-Bench Hard. We achieved an 80.6\% reduction in token consumption while maintaining competitive accuracy, seeing only a nominal decline in performance. This presents a pragmatic solution for deploying token-efficient and cost-effective agentic AI systems in production pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CROP, a method for automatic prompt optimization that adds length regularization through textual feedback on response length, in addition to accuracy feedback. This is intended to generate prompts that elicit concise yet accurate reasoning from LLMs. The authors evaluate the approach on GSM8K, LogiQA, and BIG-Bench Hard datasets, claiming an 80.6% reduction in token consumption with only a nominal decline in task accuracy.
Significance. If validated, the result would offer a practical way to mitigate the high token costs associated with reasoning in LLMs without substantial performance loss, which is relevant for scalable deployment of agentic systems. The approach builds on existing APO frameworks by introducing a simple regularization mechanism via natural language feedback.
major comments (2)
- Abstract and Experiments: The central claim of an 80.6% token reduction with nominal accuracy drop is presented at a high level. The manuscript must provide detailed experimental protocols, including the specific baselines used for comparison, the number of independent runs, reported variance or confidence intervals, and any statistical tests performed to support the significance of the reduction.
- Evaluation Methodology: Accuracy on the final answer is used as the primary metric across the three datasets. However, this does not directly assess whether the length-regularized prompts preserve the quality and completeness of intermediate reasoning steps. An ablation or analysis examining reasoning trace correctness (e.g., via step-by-step verification or error categorization) is needed to rule out the possibility that token savings result from shallower, less robust reasoning that happens to produce correct final answers.
minor comments (1)
- Abstract: The abstract refers to 'nominal decline in performance' without quantifying the accuracy drop; providing the exact percentage or absolute values would improve clarity.
Simulated Author's Rebuttal
Thank you for the constructive review of our manuscript. We address each major comment below, indicating the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: Abstract and Experiments: The central claim of an 80.6% token reduction with nominal accuracy drop is presented at a high level. The manuscript must provide detailed experimental protocols, including the specific baselines used for comparison, the number of independent runs, reported variance or confidence intervals, and any statistical tests performed to support the significance of the reduction.
Authors: We agree that additional experimental details are warranted for reproducibility and to substantiate the claims. In the revised manuscript, we will expand the Experiments section to explicitly list all baselines (including standard Chain-of-Thought, Automatic Prompt Optimization without regularization, and other token-reduction methods from prior work), report results averaged over five independent runs with different seeds, include means with standard deviations and 95% confidence intervals in the tables, and add paired t-tests to assess the statistical significance of the observed token reductions relative to baselines. Per-dataset breakdowns of the 80.6% average reduction will also be provided. revision: yes
-
Referee: Evaluation Methodology: Accuracy on the final answer is used as the primary metric across the three datasets. However, this does not directly assess whether the length-regularized prompts preserve the quality and completeness of intermediate reasoning steps. An ablation or analysis examining reasoning trace correctness (e.g., via step-by-step verification or error categorization) is needed to rule out the possibility that token savings result from shallower, less robust reasoning that happens to produce correct final answers.
Authors: This concern is well-taken, as final-answer accuracy alone leaves open the possibility of degraded intermediate reasoning. We will add a new analysis subsection in the revision that samples 50 examples per dataset (150 total) and manually categorizes reasoning traces from CROP versus non-regularized prompts according to error types (e.g., missing steps, logical inconsistencies, or calculation errors). We will report the fraction of traces that remain complete and correct while still achieving token savings, along with an ablation comparing average reasoning-step counts. A exhaustive verification of every test instance is not feasible given resource constraints, but the sampled analysis will provide direct evidence that conciseness does not equate to shallower reasoning. revision: partial
Circularity Check
No circularity: method is a high-level conceptual proposal with empirical evaluation only.
full rationale
The paper describes CROP as an APO variant that adds textual length feedback to accuracy feedback during prompt optimization. No equations, derivations, fitted parameters, or self-citation chains appear in the abstract or method description. The central claim (80.6% token reduction with nominal accuracy drop) is presented as an empirical outcome on GSM8K, LogiQA, and BIG-Bench Hard rather than a mathematical reduction to inputs. No load-bearing step reduces by construction to a fit, definition, or prior self-citation; the approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C3ot: Generating shorter chain-of- thought without compromising effectiveness
C3ot: Generating shorter chain-of-thought without compromising effectiveness.arXiv preprint arXiv:2412.11664. Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vard- hamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, and 1 others. 2024. Dspy: Compiling declarative language model calls into state-of-the-...
-
[2]
BloombergGPT: A Large Language Model for Finance
Bloomberggpt: A large language model for finance.arXiv preprint arXiv:2303.17564. Zhaofeng Wu and 1 others. 2025. An empirical study on prompt compression for large language models. arXiv preprint arXiv:2505.00019. et al. Xia. 2025. Tokenskip: Controllable chain-of- thought compression in llms. InProceedings of the 2025 Conference on Empirical Methods in ...
work page internal anchor Pith review arXiv 2025
-
[3]
NOT", "cannot
**Analyze the Query:** Carefully break down the context and the question. Identify the core logical structure, premises, definitions, and specific requirements. Pay special attention to negative constraints (e.g., "NOT", "cannot", "least likely") and the modality required (e.g., "must be true", "most weakens"). Explicitly state the ultimate goal of the qu...
-
[4]
Include negative criteria (what the correct option must *not* do) and distinguish between necessary and sufficient conditions
**Formulate Criteria:** Establish clear, precise, and prioritized criteria that the correct answer must satisfy based on your logical analysis. Include negative criteria (what the correct option must *not* do) and distinguish between necessary and sufficient conditions
-
[5]
weaken/strengthen
**Evaluate Options:** Systematically and concisely analyze every option using its zero-based index (e.g., Option 0, Option 1, Option 2, Option 3). Use strong, decisive language to explain exactly how it meets or fails the formulated criteria. - For "weaken/strengthen" questions, prioritize options that directly attack or support the core premise or mechan...
-
[6]
Be decisive
**Compare and Conclude:** Conduct a rigorous and direct comparative analysis of the most viable options. Be decisive. Explicitly contrast the strengths of the correct option against the specific weaknesses of the runners-up to summarize why the selected option is definitively the best or only correct choice
-
[7]
Answer :
**Final Answer:** Skip any section heading for this step. On the very last line of your response, provide the final answer in the exact format: Answer: V ALUE (where V ALUE is the single zero-based integer index of the correct option). CRITICAL FORMATTING RULE: The final line MUST be exactly ’Answer: V ALUE’ (e.g., ’Answer: 2’) with NO additional spaces, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.