Recognition: unknown
Evaluation of Agents under Simulated AI Marketplace Dynamics
Pith reviewed 2026-05-10 12:30 UTC · model grok-4.3
The pith
Simulating competitive marketplaces lets AI systems be judged by user retention and market share over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Marketplace Evaluation is a simulation-based paradigm that evaluates information access systems as participants in a competitive marketplace. By simulating repeated interactions and evolving user and agent preferences, the framework enables longitudinal evaluation and marketplace-level metrics, such as retention and market share, that complement and can extend beyond traditional accuracy-based metrics.
What carries the argument
Marketplace Evaluation, the simulation framework that models repeated user-system interactions with preference evolution to compute retention, market share, and related competitive outcomes.
If this is right
- Evaluation campaigns can add longitudinal runs to measure which systems retain users rather than only ranking them on single queries.
- Developers can optimize systems for competitive positioning and switching resistance in addition to per-query accuracy.
- Early-adoption effects and paths to market dominance become observable through repeated simulation rounds.
- Routing decisions and operational constraints can be tested for their impact on long-term marketplace position.
Where Pith is reading between the lines
- Teams could use the simulations to test whether accuracy advantages survive when users can switch freely between systems.
- The framework might reveal that certain accuracy gains are invisible in static tests but drive retention once competition is modeled.
- Adoption studies could compare simulated market shares against real user behavior logs to refine the preference-evolution rules.
Load-bearing premise
Simulations of repeated interactions with evolving user and agent preferences will produce metrics that accurately reflect real-world competitive dynamics and post-deployment outcomes.
What would settle it
Run the simulation to predict which system will capture the largest market share after many rounds, then compare that prediction to actual market share observed in a live deployment of the same systems.
Figures

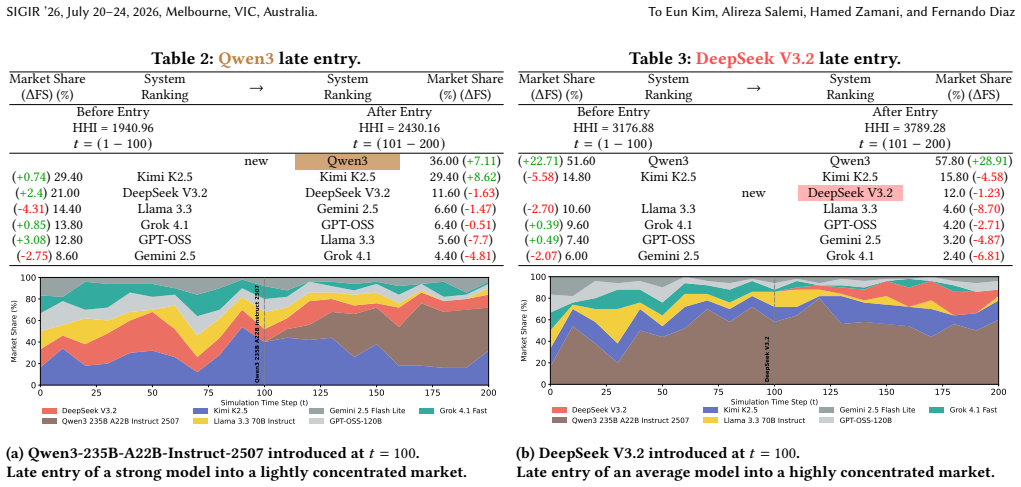
read the original abstract
Modern information access ecosystems consist of mixtures of systems, such as retrieval systems and large language models, and increasingly rely on marketplaces to mediate access to models, tools, and data, making competition between systems inherent to deployment. In such settings, outcomes are shaped not only by benchmark quality but also by competitive pressure, including user switching, routing decisions, and operational constraints. Yet evaluation is still largely conducted on static benchmarks with accuracy-focused measures that assume systems operate in isolation. This mismatch makes it difficult to predict post-deployment success and obscures competitive effects such as early-adoption advantages and market dominance. We introduce Marketplace Evaluation, a simulation-based paradigm that evaluates information access systems as participants in a competitive marketplace. By simulating repeated interactions and evolving user and agent preferences, the framework enables longitudinal evaluation and marketplace-level metrics, such as retention and market share, that complement and can extend beyond traditional accuracy-based metrics. We formalize the framework and outline a research agenda, motivated by business and economics, around marketplace simulation, metrics, optimization, and adoption in evaluation campaigns like TREC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Marketplace Evaluation, a simulation-based evaluation paradigm for information access systems (retrieval systems, LLMs, etc.) operating in competitive AI marketplaces. It argues that static accuracy benchmarks fail to capture competitive dynamics such as user switching, routing decisions, and evolving preferences, and introduces repeated-interaction simulations to produce longitudinal marketplace metrics including retention and market share. The paper formalizes the framework and sketches a research agenda covering simulation mechanics, metrics, optimization, and integration into campaigns like TREC.
Significance. If implemented with concrete, reproducible simulations, the framework could meaningfully extend IR evaluation beyond isolated benchmarks by incorporating competitive and longitudinal effects drawn from business and economics. The formalization and explicit research agenda are strengths that could guide community efforts toward falsifiable marketplace-level predictions.
minor comments (3)
- The abstract and framework description would benefit from at least one concrete toy simulation example (e.g., agent preference update rule and resulting retention calculation) to make the longitudinal metrics operational rather than purely conceptual.
- Clarify how the proposed marketplace metrics relate to or differ from existing multi-agent or game-theoretic evaluation approaches already used in IR and recommender systems literature; add 2-3 targeted citations.
- The research agenda section should specify minimal requirements for a simulation to be considered valid (e.g., how preference evolution is parameterized and validated against real marketplace data).
Simulated Author's Rebuttal
We thank the referee for the positive and constructive review. We appreciate the acknowledgment that Marketplace Evaluation has the potential to meaningfully extend IR evaluation by incorporating competitive and longitudinal effects. The recommendation for minor revision is noted.
Circularity Check
No significant circularity detected
full rationale
The paper introduces Marketplace Evaluation as a new simulation-based evaluation paradigm for information access systems in competitive marketplaces. It defines the framework, describes how repeated interactions and evolving preferences enable longitudinal metrics like retention and market share, and outlines a research agenda motivated by business and economics. No mathematical derivations, equations, fitted parameters, predictions, or self-citations appear in the provided text that reduce the central claims to their inputs by construction. The contribution is a methodological proposal for complementary evaluation, which is self-contained and does not rely on tautological steps or load-bearing self-references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulations of repeated interactions and evolving preferences can model real marketplace dynamics and competitive effects
Reference graph
Works this paper leans on
-
[1]
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. 2025. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Pranjal Aggarwal, Aman Madaan, Ankit Anand, Srividya Pranavi Potharaju, Swaroop Mishra, Pei Zhou, Aditya Gupta, Dheeraj Rajagopal, Karthik Kappa- ganthu, Yiming Yang, Shyam Upadhyay, Manaal Faruqui, and Mausam. 2024. AutoMix: automatically mixing language models. InProceedings of the 38th International Conference on Neural Information Processing Systems(V...
2024
- [3]
-
[4]
Mohammad Aliannejadi, Zahra Abbasiantaeb, Shubham Chatterjee, Jeffrey Dal- ton, and Leif Azzopardi. 2024. TREC iKAT 2023: A Test Collection for Evaluating Conversational and Interactive Knowledge Assistants. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Informa- tion Retrieval(Washington DC, USA)(SIGIR ’24). A...
-
[5]
Allen and Wendy M
Mary J. Allen and Wendy M. Yen. 2001.Introduction to Measurement Theory. Waveland Press, Long Grove, IL
2001
-
[6]
2026.A WS Marketplace
Amazon Web Services. 2026.A WS Marketplace. https://aws.amazon.com/ marketplace/solutions/ai-agents-and-tools Accessed: 2026-02-04
2026
-
[7]
Anthropic. 2024. Introducing the Model Context Protocol. https://www. anthropic.com/news/model-context-protocol Accessed: 2026-02-05
2024
-
[8]
Nima Asadi and Jimmy Lin. 2013. Effectiveness/efficiency tradeoffs for candidate generation in multi-stage retrieval architectures. InProceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval(Dublin, Ireland)(SIGIR ’13). Association for Computing Machinery, New York, NY, USA, 997–1000. doi:10.1145/2484...
-
[9]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi
-
[10]
InThe Twelfth International Conference on Learning Representations
Self-RAG: Learning to Retrieve, Generate, and Critique through Self- Reflection. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hSyW5go0v8
-
[11]
2000.Why agents?: on the varied motivations for agent computing in the social sciences
Robert Axtell. 2000.Why agents?: on the varied motivations for agent computing in the social sciences. Vol. 17. Center on Social and Economic Dynamics Washington, DC
2000
-
[12]
Krisztian Balog and ChengXiang Zhai. 2024. User Simulation for Evaluating Information Access Systems.Foundations and Trends®in Information Retrieval 18, 1-2 (2024), 1–261. doi:10.1561/1500000098
-
[13]
Ryan C Barron, Vesselin Grantcharov, Selma Wanna, Maksim E Eren, Manish Bhattarai, Nicholas Solovyev, George Tompkins, Charles Nicholas, Kim Ø Ras- mussen, Cynthia Matuszek, et al. 2024. Domain-specific retrieval-augmented generation using vector stores, knowledge graphs, and tensor factorization. In 2024 International Conference on Machine Learning and A...
2024
-
[14]
Sébastien Bubeck, Nicolo Cesa-Bianchi, et al. 2012. Regret analysis of stochastic and nonstochastic multi-armed bandit problems.Foundations and Trends®in Machine Learning5, 1 (2012), 1–122
2012
- [15]
-
[16]
Ben Carterette, Evangelos Kanoulas, and Emine Yilmaz. 2011. Simulating Simple User Behavior for System Effectiveness Evaluation. InProceedings of the 20th ACM International Conference on Information and Knowledge Management (CIKM ’11). Association for Computing Machinery, New York, NY, USA, 611–620
2011
-
[17]
2025.How people use chatgpt
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. 2025.How people use chatgpt. Technical Report. National Bureau of Economic Research
2025
-
[18]
Zheng Chu, Jingchang Chen, Qianglong Chen, Haotian Wang, Kun Zhu, Xiyuan Du, Weijiang Yu, Ming Liu, and Bing Qin. 2024. BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Marti...
-
[19]
Cyril Cleverdon. 1967. The Cranfield Tests on Index Language Devices.Aslib Proceedings19, 6 (2025/06/06 1967), 173–194
1967
-
[20]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Shane Culpepper, Fernando Diaz, and Mark D
J. Shane Culpepper, Fernando Diaz, and Mark D. Smucker. 2018. Research Frontiers in Information Retrieval: Report from the Third Strategic Workshop on Information Retrieval in Lorne (SWIRL 2018).SIGIR Forum52, 1 (Aug. 2018), 34–90. doi:10.1145/3274784.3274788
-
[22]
Zhuyun Dai, Yubin Kim, and Jamie Callan. 2017. Learning to rank resources. InProceedings of the 40th International ACM SIGIR conference on research and development in information retrieval. 837–840
2017
-
[23]
Ovidiu Dan and Brian D Davison. 2016. Measuring and predicting search engine users’ satisfaction.ACM Computing Surveys (CSUR)49, 1 (2016), 1–35
2016
-
[24]
Yufan Dang, Chen Qian, Xueheng Luo, Jingru Fan, Zihao Xie, Ruijie Shi, Weize Chen, Cheng Yang, Xiaoyin Che, Ye Tian, Xuantang Xiong, Lei Han, Zhiyuan Liu, and Maosong Sun. 2025. Multi-Agent Collaboration via Evolving Orchestration. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=L0xZPXT3le
2025
-
[25]
2026.Databricks Marketplace
Databricks, Inc. 2026.Databricks Marketplace. https://www.databricks.com/ product/marketplace Accessed: 2026-02-04. Evaluation of Agents under Simulated AI Marketplace Dynamics SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia
2026
-
[26]
Fernando Diaz, Bhaskar Mitra, Michael D. Ekstrand, Asia J. Biega, and Ben Carterette. 2020. Evaluating Stochastic Rankings with Expected Exposure. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management(Virtual Event, Ireland)(CIKM ’20). Association for Computing Machinery, New York, NY, USA, 275–284. doi:10.1145/3340...
-
[27]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[28]
1996.Growing artificial societies: social science from the bottom up
Joshua M Epstein and Robert Axtell. 1996.Growing artificial societies: social science from the bottom up. Brookings Institution Press
1996
-
[29]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. Ragas: Automated evaluation of retrieval augmented generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. 150–158
2024
-
[30]
2019.Information Retrieval Evaluation in a Changing World: Lessons Learned from 20 Years of CLEF
Nicola Ferro and Carol Peters (Eds.). 2019.Information Retrieval Evaluation in a Changing World: Lessons Learned from 20 Years of CLEF. The Information Retrieval Series, Vol. 41. Springer Cham. doi:10.1007/978-3-030-22948-1
-
[31]
Simone Filice, Guy Horowitz, David Carmel, Zohar Karnin, Liane Lewin-Eytan, and Yoelle Maarek. 2025. Generating Q&A Benchmarks for RAG Evaluation in Enterprise Settings, Georg Rehm and Yunyao Li (Eds.). Association for Com- putational Linguistics, Vienna, Austria, 469–484. doi:10.18653/v1/2025.acl- industry.33
-
[32]
Apostolos Filippas, John J. Horton, and Benjamin S. Manning. 2024. Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus?. InProceedings of the 25th ACM Conference on Economics and Computation. ACM, New Haven CT USA, 614–615. doi:10.1145/3670865.3673513
-
[33]
Carlos A. Gomez-Uribe and Neil Hunt. 2016. The Netflix Recommender System: Algorithms, Business Value, and Innovation.ACM Trans. Manage. Inf. Syst.6, 4, Article 13 (Dec. 2016), 19 pages. doi:10.1145/2843948
-
[34]
William Greene. 2009.Discrete Choice Modeling. Palgrave Macmillan UK, London, 473–556. doi:10.1057/9780230244405_11
-
[35]
Harrington and Myong-Hun Chang
Joseph E. Harrington and Myong-Hun Chang. 2005. Co-evolution of firms and consumers and the implications for market dominance.Journal of Economic Dynamics and Control29, 1-2 (Jan. 2005), 245–276. doi:10.1016/j.jedc.2003.04.012
-
[36]
Ahmed Hassan, Rosie Jones, and Kristina Lisa Klinkner. 2010. Beyond DCG: user behavior as a predictor of a successful search. InProceedings of the third ACM international conference on Web search and data mining. 221–230
2010
-
[37]
de Vries, Maarten de Rijke, and Faegheh Hasibi
Mohanna Hoveyda, Harrie Oosterhuis, Arjen P. de Vries, Maarten de Rijke, and Faegheh Hasibi. 2025. Adaptive Orchestration of Modular Generative Information Access Systems. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 38...
-
[38]
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. 2024. RouterBench: A Benchmark for Multi-LLM Routing System. InAgentic Markets Workshop at ICML 2024. https://openreview.net/forum?id=IVXmV8Uxwh
2024
-
[39]
Canbin Huang, Tianyuan Shi, Yuhua Zhu, Ruijun Chen, and Xiaojun Quan. 2025. Lookahead Routing for Large Language Models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/ forum?id=DRIRD9ELMb
2025
-
[40]
Kung-Hsiang Huang, Akshara Prabhakar, Onkar Thorat, Divyansh Agarwal, Prafulla Kumar Choubey, Yixin Mao, Silvio Savarese, Caiming Xiong, and Chien- Sheng Wu. 2026. CRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions.Transactions on Machine Learning Research(2026). https://openreview.net/forum?id=EPlpe3Fx1x
2026
-
[41]
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, and Dario Amodei. 2018. Reward learning from human preferences and demonstrations in atari.Advances in neural information processing systems31 (2018)
2018
-
[42]
Dietmar Jannach and Michael Jugovac. 2019. Measuring the business value of recommender systems.ACM Transactions on Management Information Systems (TMIS)10, 4 (2019), 1–23
2019
-
[43]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
-
[44]
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Li...
-
[45]
Ray Jiang, Silvia Chiappa, Tor Lattimore, András György, and Pushmeet Kohli
-
[46]
Degenerate Feedback Loops in Recommender Systems. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society(Honolulu, HI, USA) (AIES ’19). Association for Computing Machinery, New York, NY, USA, 383–390. doi:10.1145/3306618.3314288
-
[47]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. InSecond Conference on Language Modeling. https://openreview.net/forum?id=Rwhi91ideu
2025
-
[48]
Thorsten Joachims. 2002. Optimizing search engines using clickthrough data. InKDD ’02: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining. 133–142
2002
-
[49]
Hideaki Joko, Shakiba Amirshahi, Charles L. A. Clarke, and Faegheh Hasibi
-
[50]
In Advances in Information Retrieval
WildClaims: Conversational Information Access in the Wild(Chat). In Advances in Information Retrieval. Springer Nature Switzerland, Cham, 367–382
-
[51]
Jushaan Singh Kalra, Xinran Zhao, To Eun Kim, Fengyu Cai, Fernando Diaz, and Tongshuang Wu. 2025. MoR: Better Handling Diverse Queries with a Mixture of Sparse, Dense, and Human Retrievers. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Pen...
-
[52]
Sora Kang, Andreea-Elena Potinteu, and Nadia Said. 2025. ExplainitAI: When do we trust artificial intelligence? The influence of content and explainability in a cross-cultural comparison. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association for Computing Machinery, New York, NY, USA,...
- [53]
-
[54]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[55]
Sayash Kapoor, Benedikt Stroebl, Zachary S Siegel, Nitya Nadgir, and Arvind Narayanan. 2025. AI Agents That Matter.Transactions on Machine Learning Research(2025). https://openreview.net/forum?id=Zy4uFzMviZ
2025
-
[56]
Seth Karten, Wenzhe Li, Zihan Ding, Samuel Kleiner, Yu Bai, and Chi Jin. 2025. LLM Economist: Large Population Models and Mechanism Design in Multi- Agent Generative Simulacra. doi:10.48550/arXiv.2507.15815 arXiv:2507.15815 [cs]
-
[57]
Timothy L Keiningham, Bruce Cooil, Lerzan Aksoy, Tor W Andreassen, and Jay Weiner. 2007. The value of different customer satisfaction and loyalty metrics in predicting customer retention, recommendation, and share-of-wallet.Managing service quality: An international Journal17, 4 (2007), 361–384
2007
-
[58]
To Eun Kim and Fernando Diaz. 2025. Towards Fair RAG: On the Impact of Fair Ranking in Retrieval-Augmented Generation. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in In- formation Retrieval (ICTIR)(Padua, Italy)(ICTIR ’25). Association for Computing Machinery, New York, NY, USA, 33–43. doi:10.1145/37311...
-
[59]
To Eun Kim and Fernando Diaz. 2026. LTRR: Learning To Rank Retrievers for LLMs. InProceedings of the 49th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’26). Melbourne, VIC, Australia. July 20–24, 2026
2026
-
[60]
Anton Korinek and Jai Vipra. 2025. Concentrating intelligence: scaling and market structure in artificial intelligence.Economic Policy40, 121 (2025), 225– 256
2025
-
[61]
Carlos Lassance and Stéphane Clinchant. 2022. An Efficiency Study for SPLADE Models. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 2220–2226. doi:10.1145/3477495.3531833
-
[62]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M...
2020
-
[63]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[64]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review arXiv 2025
-
[65]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, and Maarten de Rijke. 2025. Ro- bust Information Retrieval. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining(Hannover, Germany)(WSDM ’25). Association for Computing Machinery, New York, NY, USA, 1008–1011. doi:10.1145/3701551.3703476
-
[66]
Shayne Longpre, Christopher Akiki, Campbell Lund, Atharva Kulkarni, Emily Chen, Irene Solaiman, Avijit Ghosh, Yacine Jernite, and Lucie-Aimée Kaffee
- [67]
-
[68]
Winecoff, and Arvind Narayanan
Eli Lucherini, Matthew Sun, Amy A. Winecoff, and Arvind Narayanan. 2021. T- RECS: A Simulation Tool to Study the Societal Impact of Recommender Systems. CoRRabs/2107.08959 (2021)
- [69]
-
[70]
Sendhil Mullainathan and Richard H Thaler. 2000.Behavioral Economics. Work- ing Paper 7948. National Bureau of Economic Research. doi:10.3386/w7948
-
[71]
Thomas E Nelson, Zoe M Oxley, and Rosalee A Clawson. 1997. Toward a psychology of framing effects.Political behavior19, 3 (1997), 221–246
1997
-
[72]
Alexandra Olteanu, Jean Garcia-Gathright, Maarten de Rijke, Michael D Ek- strand, Adam Roegiest, Aldo Lipani, Alex Beutel, Alexandra Olteanu, Ana Lucic, Ana-Andreea Stoica, et al. 2021. FACTS-IR: fairness, accountability, confiden- tiality, transparency, and safety in information retrieval. InACM SIGIR Forum, Vol. 53. ACM New York, NY, USA, 20–43
2021
-
[73]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. 2025. RouteLLM: Learning to Route LLMs from Preference Data. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=8sSqNntaMr
2025
-
[74]
2026.OpenRouter
OpenRouter, Inc. 2026.OpenRouter. https://openrouter.ai/ Accessed: 2026-02-04
2026
-
[75]
O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA)(UIST ’23). Association for Computing Machinery, New York, NY, USA, ...
-
[76]
Baolin Peng, Xiujun Li, Jianfeng Gao, Jingjing Liu, and Kam-Fai Wong. 2018. Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learn- ing. InProceedings of the 56th Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), Iryna Gurevych and Yusuke Miyao (Eds.). Association for Computational Linguistics,...
2018
-
[77]
doi:10.18653/v1/P18-1203
-
[78]
2018.Entry games and free entry equilibria
Michele Polo. 2018.Entry games and free entry equilibria. Edward Elgar Pub- lishing
2018
-
[79]
Michael E Porter. 1997. Competitive strategy.Measuring business excellence1, 2 (1997), 12–17
1997
-
[80]
Ronak Pradeep, Nandan Thakur, Sahel Sharifymoghaddam, Eric Zhang, Ryan Nguyen, Daniel Campos, Nick Craswell, and Jimmy Lin. 2025. Ragnarök: A Reusable RAG Framework and Baselines for TREC 2024 Retrieval-Augmented Generation Track. InAdvances in Information Retrieval: 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6–10, 2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.