Recognition: unknown
Hierarchical vs. Flat Iteration in Shared-Weight Transformers
Pith reviewed 2026-05-10 12:55 UTC · model grok-4.3
The pith
Hierarchical shared-weight recurrence cannot match independent Transformer layers in language modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
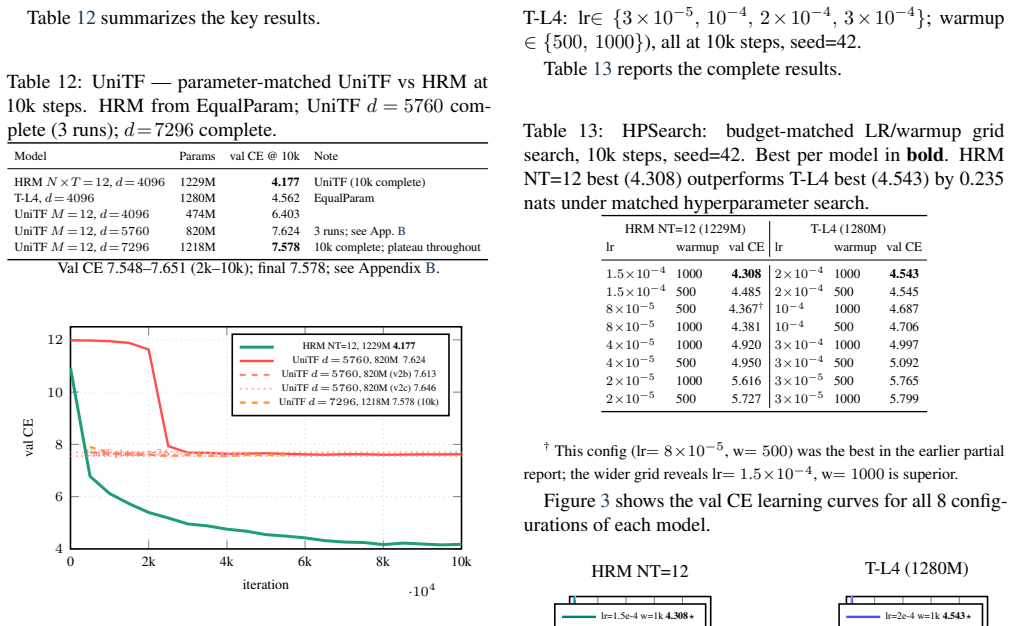
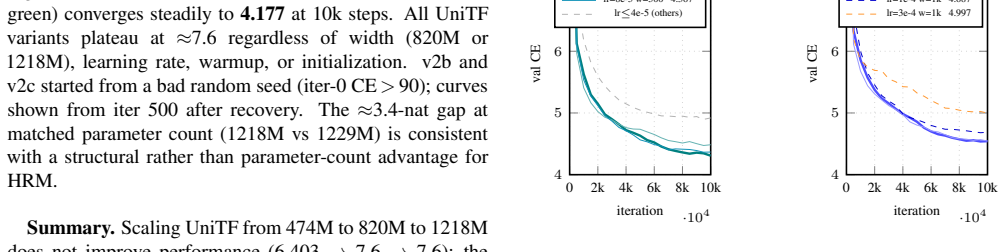
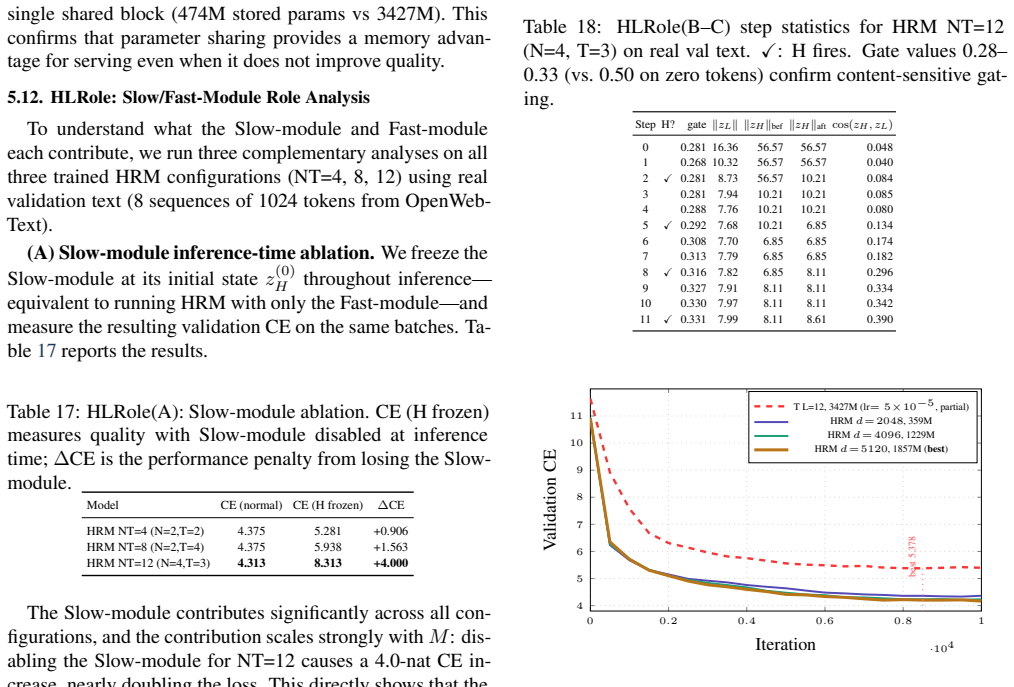
HRM-LM replaces L independent Transformer layers with a recurrent pair consisting of a Fast module that operates at every step and a Slow module that operates every T steps; the pair is unrolled for M = N × T steps while all parameters remain shared. When this construction is compared head-to-head with a parameter-matched Universal Transformer ablation across five independent runs, the two approaches exhibit a sharp empirical gap, with the independent-layer model achieving higher performance.
What carries the argument
The two-speed recurrent pair (Fast module at every step for local refinement, Slow module every T steps for global compression) unrolled with fully shared parameters.
If this is right
- Independent layers supply representational advantages that shared-weight hierarchical recurrence does not replicate at matched parameter counts.
- The performance edge of deeper Transformers arises at least partly from having distinct parameters at successive depths rather than from recurrence structure alone.
- Architectural efforts that rely on shared-weight hierarchies will need additional mechanisms to close the observed quality difference.
Where Pith is reading between the lines
- Model scaling strategies may gain more from adding independent layers than from elaborating recurrence hierarchies.
- The same comparison could be repeated on tasks with longer contexts or in non-language domains to check whether the preference for flat iteration generalizes.
- Alternative recurrence speeds or compression schedules might narrow the gap if the current T and M choices prove suboptimal.
Load-bearing premise
That the two-speed recurrent unrolling with shared parameters and the specific choice of T and M provides a fair test of whether hierarchical structure can substitute for independent layers.
What would settle it
A hierarchical recurrent variant that reaches equivalent or superior perplexity to the independent-layer baseline in a parameter-matched run on the same language-modeling benchmark would falsify the gap.
Figures

read the original abstract
We present an empirical study of whether hierarchically structured, shared-weight recurrence can match the representational quality of independent-layer stacking in a Transformer-based language model. HRM-LM replaces L independent Transformer layers with a two-speed recurrent pair: a Fast module operating at every step for local refinement, and a Slow module operating every T steps for global compression. This recurrent hierarchy is unrolled for M = N x T steps with shared parameters. The central and most robust finding, supported by a parameter-matched Universal Transformer ablation (UniTF, 1.2B) across five independent runs, is a sharp empirical gap between the two approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of whether hierarchically structured shared-weight recurrence can match the quality of independent-layer stacking in Transformer language models. HRM-LM replaces L independent layers with a two-speed recurrent pair (Fast module at every step for local refinement, Slow module every T steps for global compression) that is unrolled for M = N × T steps using shared parameters. The central finding, based on a parameter-matched 1.2B Universal Transformer ablation (UniTF) run five times, is a sharp empirical gap favoring the flat architecture.
Significance. If the reported gap is robust and not an artifact of the specific T and M choices, the result would indicate that shared-weight hierarchical recurrence cannot serve as a drop-in substitute for depth in Transformers. This would have direct implications for the design of efficient recurrent language models and would strengthen the case for independent layers even under parameter sharing. The parameter-matched ablation and multiple independent runs are positive features of the experimental design.
major comments (2)
- [Abstract] Abstract: the claim of a 'sharp empirical gap' between HRM-LM and UniTF is asserted without any numerical results, perplexity scores, accuracy metrics, tables, or error bars from the five runs. This absence prevents evaluation of the magnitude or statistical reliability of the difference and is load-bearing for the paper's central conclusion.
- [Architecture description] Architecture description (two-speed recurrence and unrolling): the specific recurrence interval T and total unroll length M = N × T are not ablated against other values or against non-two-speed hierarchical designs. Different choices of T or M could close or reverse the observed gap, so the experiment does not yet establish that the result is a general property of hierarchical versus flat shared-weight iteration rather than an artifact of the chosen speeds.
minor comments (2)
- Define N explicitly when stating M = N × T; it is unclear whether N corresponds to the number of layers, sequence length, or another quantity.
- [Abstract] The abstract mentions 'five independent runs' but does not state the random seeds, training details, or evaluation protocol used to establish robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our empirical study of hierarchical versus flat shared-weight iteration in Transformers. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'sharp empirical gap' between HRM-LM and UniTF is asserted without any numerical results, perplexity scores, accuracy metrics, tables, or error bars from the five runs. This absence prevents evaluation of the magnitude or statistical reliability of the difference and is load-bearing for the paper's central conclusion.
Authors: We agree that the abstract would be strengthened by including quantitative support. The manuscript reports results from five independent runs of the 1.2B parameter-matched ablation, but these metrics appear only in the experimental section. In the revised version we will update the abstract to state the mean perplexity (with standard deviation) for both HRM-LM and UniTF, allowing readers to evaluate the size and reliability of the gap directly. revision: yes
-
Referee: [Architecture description] Architecture description (two-speed recurrence and unrolling): the specific recurrence interval T and total unroll length M = N × T are not ablated against other values or against non-two-speed hierarchical designs. Different choices of T or M could close or reverse the observed gap, so the experiment does not yet establish that the result is a general property of hierarchical versus flat shared-weight iteration rather than an artifact of the chosen speeds.
Authors: The referee correctly identifies that we did not ablate T or M, nor compare against alternative hierarchical recurrence patterns. The chosen T and M were selected to produce an effective depth comparable to the flat baseline while preserving parameter sharing, consistent with prior recurrent Transformer designs. We will revise the architecture and discussion sections to provide an explicit rationale for these values, add a limitations paragraph stating that the observed gap is demonstrated for this specific two-speed configuration, and note that broader ablations remain an important direction for future work. This clarifies the scope of the claim without overstating generality. revision: yes
Circularity Check
No circularity: purely empirical ablation with no derivation or fitted predictions
full rationale
The paper presents an empirical comparison of HRM-LM (two-speed recurrent hierarchy unrolled M = N × T steps) against a parameter-matched Universal Transformer (UniTF). No mathematical derivation, first-principles prediction, or fitted parameter is presented as an output that reduces to its own inputs. The central claim is a reported performance gap across five runs; this is a direct experimental result, not a constructed equivalence. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The skeptic concern about specific T/M choices is a question of experimental fairness, not circularity in any derivation chain.
Axiom & Free-Parameter Ledger
free parameters (2)
- T (slow module interval)
- M (unroll steps)
Reference graph
Works this paper leans on
-
[1]
Attention is all you need,
A. Vaswani et al., “Attention is all you need,”NeurIPS, 2017
2017
-
[2]
Finding structure in time,
J. L. Elman, “Finding structure in time,”Cognitive Sci- ence, 14(2):179–211, 1990
1990
-
[3]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, 9(8):1735–1780, 1997
1997
-
[4]
Learning phrase representations using RNN encoder-decoder for statistical machine transla- tion,
K. Cho et al., “Learning phrase representations using RNN encoder-decoder for statistical machine transla- tion,”EMNLP, 2014
2014
-
[5]
Neural machine translation by jointly learning to align and translate,
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,” ICLR, 2015
2015
-
[6]
Improving language understanding by generative pre-training,
A. Radford et al., “Improving language understanding by generative pre-training,” Technical Report, OpenAI, 2018
2018
-
[7]
Language models are unsupervised multitask learners,
A. Radford et al., “Language models are unsupervised multitask learners,” Technical Report, OpenAI, 2019
2019
-
[8]
Language models are few-shot learners,
T. B. Brown et al., “Language models are few-shot learners,”NeurIPS, 2020
2020
-
[9]
RoFormer: Enhanced transformer with rotary position embedding,
J. Su et al., “RoFormer: Enhanced transformer with rotary position embedding,”Neurocomputing, 568:127063, 2024
2024
-
[10]
Universal transformers,
M. Dehghani et al., “Universal transformers,”ICLR, 2019
2019
-
[11]
Deep equilibrium models,
S. Bai, J. Z. Kolter, and V . Koltun, “Deep equilibrium models,”NeurIPS, 2019
2019
-
[12]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer et al., “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”ICLR, 2017
2017
-
[13]
A neural probabilistic language model,
Y . Bengio, R. Ducharme, P. Vincent, and C. Jauvin, “A neural probabilistic language model,”JMLR, 3:1137– 1155, 2003
2003
-
[14]
Hierarchical reasoning model, 2025
G. Wang, J. Li, Y . Sun, X. Chen, C. Liu, Y . Wu, M. Lu, S. Song, and Y . Abbasi Yadkori, “Hierarchical Reason- ing Model,”arXiv preprint arXiv:2506.21734, 2025. https://arxiv.org/abs/2506.21734
-
[15]
OpenWebText cor- pus,
A. Gokaslan and V . Cohen, “OpenWebText cor- pus,”http://Skylion007.github.io/ OpenWebTextCorpus, 2019
2019
-
[16]
Hierarchical recurrent neural networks for long-term dependencies,
S. El Hihi and Y . Bengio, “Hierarchical recurrent neural networks for long-term dependencies,”NeurIPS, 1996
1996
-
[17]
Scaling Laws for Neural Language Models
J. Kaplan et al., “Scaling laws for neural language mod- els,”Preprint, arXiv:2001.08361, 2020. 22
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[18]
Turboquant: Online vector quantization with near-optimal distortion rate,
A. Zandieh, M. Daliri, M. Hadian, and V . Mir- rokni, “TurboQuant: Online vector quantization with near-optimal distortion rate,”arXiv preprint arXiv:2504.19874, 2025.https://arxiv.org/ abs/2504.19874
-
[19]
QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead,
A. Zandieh, M. Daliri, and I. Han, “QJL: 1-bit quan- tized JL transform for KV cache quantization with zero overhead,”arXiv preprint arXiv:2406.03482, 2024. https://arxiv.org/abs/2406.03482
-
[20]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Y . Bai et al., “LongBench: A bilingual, multitask benchmark for long context understanding,”arXiv preprint arXiv:2308.14508, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Z. Liu et al., “KIVI: A tuning-free asymmetric 2-bit quantization for KV cache,”arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review arXiv 2024
-
[22]
PolarQuant: Polar-Coordinate KV Cache Quantization,
I. Han et al., “PolarQuant: Quantizing KV caches with polar transformation,”arXiv preprint arXiv:2502.02617, 2025
-
[23]
J. Gao et al., “Practical and asymptotically optimal quantization of high-dimensional vectors in Euclidean space for approximate nearest neighbor search,”arXiv preprint arXiv:2409.09913, 2024
-
[24]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate post-training quantization for gener- ative pre-trained transformers,”ICLR, 2023.https: //arxiv.org/abs/2210.17323
work page internal anchor Pith review arXiv 2023
-
[25]
J. Shah, G. Bikshandi, Y . Zhang, V . Thakkar, P. Ra- mani, and T. Dao, “FlashAttention-3: Fast and accurate attention with asynchrony and low-precision,”arXiv preprint arXiv:2407.08608, 2024.https://arxiv. org/abs/2407.08608
-
[26]
Efficient Memory Management for Large Language Model Serving with PagedAttention
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,”Proc. ACM SOSP, pp. 611–626, 2023.https://arxiv.org/abs/2309.06180
work page internal anchor Pith review arXiv 2023
-
[27]
A primer in BERTology: What we know about how BERT works.arXiv [cs.CL], 2020
A. Rogers, O. Kovaleva, and A. Rumshisky, “A primer in BERTology: What we know about how BERT works,”Transactions of the Association for Com- putational Linguistics, 8:842–866, 2020.https:// arxiv.org/abs/2002.12327
-
[28]
Fast in- ference from transformers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast in- ference from transformers via speculative decoding,” ICML, 2023.https://arxiv.org/abs/2211. 17192
2023
- [29]
-
[30]
S. Yu, T. Chu, P. Tian, and Y . Ma, “White-Box Trans- formers via Sparse Rate Reduction,Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[31]
Martens and R
J. Martens and R. Grosse, “Optimizing neural networks with Kronecker-factored approximate curvature,Proc. ICML, 2015
2015
-
[32]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
RWKV: Reinventing RNNs for the Transformer era,
B. Peng et al., “RWKV: Reinventing RNNs for the Transformer era,” inFindings of EMNLP, 2023. 23
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.