Recognition: unknown
CooperDrive: Enhancing Driving Decisions Through Cooperative Perception
Pith reviewed 2026-05-10 12:30 UTC · model grok-4.3
The pith
CooperDrive augments autonomous vehicle perception by sharing object detections with nearby vehicles to enable earlier safer decisions at occluded intersections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
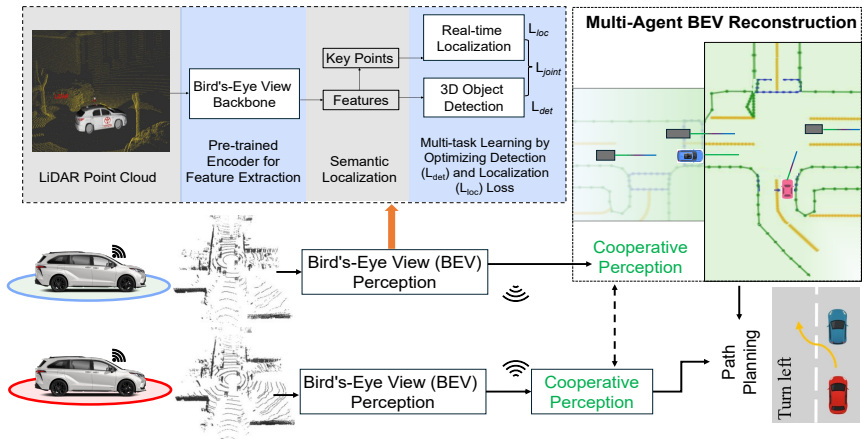
CooperDrive is a cooperative perception framework that augments situational awareness by sharing and fusing object-level information between vehicles, reusing detector BEV features for accurate pose estimation and BEV reconstruction to enable low-latency planning inputs. On the planning side it uses the expanded object set to anticipate potential conflicts earlier transforming reactive driving into predictive and safer behaviors. Real-world closed-loop tests at occlusion-heavy NLOS intersections confirm increases in reaction lead time minimum time-to-collision and stopping margin with only 90 kbps bandwidth and 89 ms average latency.
What carries the argument
the lightweight object-level sharing and fusion strategy that reuses existing detector BEV features to estimate vehicle poses and reconstruct BEV representations for the planner
If this is right
- Vehicles retain their native perception localization and planning stacks while gaining from shared detections.
- Planners receive an expanded object set that supports earlier conflict anticipation and proactive speed trajectory adjustments.
- Real-world tests at occlusion-heavy NLOS intersections produce measurable gains in reaction lead time minimum TTC and stopping margin.
- The system operates with only 90 kbps bandwidth and 89 ms average end-to-end latency.
Where Pith is reading between the lines
- Neighboring vehicles could supply missing detections in dense traffic reducing the need for every car to carry the most expensive sensors.
- The same lightweight fusion could be chained across multiple vehicles to extend awareness beyond immediate neighbors.
- Integration with existing V2X communication standards might allow gradual deployment without dedicated new infrastructure.
Load-bearing premise
Reliable low-latency vehicle-to-vehicle communication is always available and the shared object detections are accurate enough to improve planning without introducing new errors or false positives.
What would settle it
A controlled experiment at an NLOS intersection where V2V links are intentionally delayed or corrupted with detection noise and safety metrics such as minimum TTC show no improvement or a decline relative to non-cooperative driving.
Figures





read the original abstract
Autonomous vehicles equipped with robust onboard perception, localization, and planning still face limitations in occlusion and non-line-of-sight (NLOS) scenarios, where delayed reactions can increase collision risk. We propose CooperDrive, a cooperative perception framework that augments situational awareness and enables earlier, safer driving decisions. CooperDrive offers two key advantages: (i) each vehicle retains its native perception, localization, and planning stack, and (ii) a lightweight object-level sharing and fusion strategy bridges perception and planning. Specifically, CooperDrive reuses detector Bird's-Eye View (BEV) features to estimate accurate vehicle poses without additional heavy encoders, thereby reconstructing BEV representations and feeding the planner with low latency. On the planning side, CooperDrive leverages the expanded object set to anticipate potential conflicts earlier and adjust speed and trajectory proactively, thereby transforming reactive behaviors into predictive and safer driving decisions. Real-world closed-loop tests at occlusion-heavy NLOS intersections demonstrate that CooperDrive increases reaction lead time, minimum time-to-collision (TTC), and stopping margin, while requiring only 90 kbps bandwidth and maintaining an average end-to-end latency of 89 ms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CooperDrive, a cooperative perception framework for autonomous vehicles that augments onboard perception in occlusion and NLOS scenarios via lightweight object-level sharing and fusion. Each vehicle retains its native perception, localization, and planning stack; the system reuses detector BEV features to estimate poses, reconstructs an expanded BEV representation, and feeds additional objects to the planner for earlier, predictive adjustments to speed and trajectory. Real-world closed-loop tests at occlusion-heavy NLOS intersections are claimed to demonstrate gains in reaction lead time, minimum time-to-collision, and stopping margin, while using only 90 kbps bandwidth and achieving 89 ms average end-to-end latency.
Significance. If the real-world results prove robust under controlled conditions and the fusion demonstrably improves planner inputs without introducing offsetting errors, the work could provide a practical, low-overhead path to cooperative perception that integrates with existing AV stacks. The emphasis on object-level rather than feature-level sharing and the reported bandwidth/latency figures address deployment constraints that many prior cooperative-perception studies leave unexamined.
major comments (2)
- [Experimental evaluation / Results] The central experimental claim (increased reaction lead time, min TTC, and stopping margin from real-world NLOS tests) is load-bearing for the paper's contribution, yet the description provides no quantitative values, baselines, error bars, statistical tests, or ablation of planner behavior with versus without fusion. This prevents evaluation of effect size and reproducibility.
- [Method / Fusion and planning integration] The method relies on the fused object set improving planning without net increase in false positives or localization errors from shared detections. No precision, recall, false-positive rate, or pose-estimation accuracy metrics are reported for the lightweight BEV-feature reuse and object-level fusion, leaving open whether observed safety gains could be offset by fusion-induced planner errors under different conditions.
minor comments (1)
- [Abstract] The abstract summarizes performance gains without including the actual measured improvements or confidence intervals; adding these would make the contribution clearer to readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments below, clarifying the experimental results and method details, and outlining the revisions we will make.
read point-by-point responses
-
Referee: [Experimental evaluation / Results] The central experimental claim (increased reaction lead time, min TTC, and stopping margin from real-world NLOS tests) is load-bearing for the paper's contribution, yet the description provides no quantitative values, baselines, error bars, statistical tests, or ablation of planner behavior with versus without fusion. This prevents evaluation of effect size and reproducibility.
Authors: We appreciate this observation. Upon review, while the manuscript presents the improvements through qualitative descriptions and supporting figures in the experimental section, it lacks the explicit quantitative breakdowns, error bars, and statistical analyses requested. We will revise the paper to include specific values for the increases in reaction lead time, minimum TTC, and stopping margin (e.g., average improvements with standard deviations), direct comparisons to the no-fusion baseline, and appropriate statistical tests. Additionally, we will provide an ablation study on the planner's behavior with and without the fused objects to demonstrate the contribution of the cooperative perception. revision: yes
-
Referee: [Method / Fusion and planning integration] The method relies on the fused object set improving planning without net increase in false positives or localization errors from shared detections. No precision, recall, false-positive rate, or pose-estimation accuracy metrics are reported for the lightweight BEV-feature reuse and object-level fusion, leaving open whether observed safety gains could be offset by fusion-induced planner errors under different conditions.
Authors: We agree that metrics on the fusion accuracy are necessary to ensure that the observed benefits are not compromised by potential errors in shared detections. The current manuscript focuses on the end-to-end closed-loop safety metrics rather than intermediate perception metrics for the fusion module. In the revised version, we will report precision, recall, and false-positive rates for the object-level fusion, as well as accuracy of the pose estimation from BEV features, using the collected real-world data. This will help confirm that the fusion does not introduce offsetting errors. revision: yes
Circularity Check
No circularity: engineering system proposal with no derivation chain or self-referential predictions
full rationale
The paper presents CooperDrive as a practical cooperative perception framework for AVs, describing a lightweight object-level sharing strategy that reuses existing detector BEV features for pose estimation and feeds an expanded object set to the planner. All claims rest on real-world closed-loop tests at NLOS intersections reporting gains in reaction lead time, min TTC, and stopping margin, plus bandwidth/latency figures. No mathematical derivations, first-principles predictions, parameter fitting, or equations appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is used to justify core claims. The work is self-contained as an applied systems contribution whose validity depends on empirical test outcomes rather than any internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cooper: Cooperative percep- tion for connected autonomous vehicles based on 3d point clouds,
Q. Chen, S. Tang, Q. Yang, and S. Fu, “Cooper: Cooperative percep- tion for connected autonomous vehicles based on 3d point clouds,” in 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2019, pp. 514–524
2019
-
[2]
F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3d point clouds,
Q. Chen, X. Ma, S. Tang, J. Guo, Q. Yang, and S. Fu, “F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3d point clouds,” inProceedings of the 4th ACM/IEEE Symposium on Edge Computing, 2019, pp. 88–100
2019
-
[3]
V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,
R. Xu, H. Xiang, Z. Tu, X. Xia, M.-H. Yang, and J. Ma, “V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,” inEuropean conference on computer vision. Springer, 2022, pp. 107– 124
2022
-
[4]
R. Xu, Z. Tu, H. Xiang, W. Shao, B. Zhou, and J. Ma, “Cobevt: Cooperative bird’s eye view semantic segmentation with sparse trans- formers,”arXiv preprint arXiv:2207.02202, 2022
-
[5]
Sicp: Simultaneous individual and cooperative perception for 3d object detection in connected and automated vehicles,
D. Qu, Q. Chen, T. Bai, H. Lu, H. Fan, H. Zhang, S. Fu, and Q. Yang, “Sicp: Simultaneous individual and cooperative perception for 3d object detection in connected and automated vehicles,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 8905–8912
2024
-
[6]
End- to-end autonomous driving through v2x cooperation,
H. Yu, W. Yang, J. Zhong, Z. Yang, S. Fan, P. Luo, and Z. Nie, “End- to-end autonomous driving through v2x cooperation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9598–9606
2025
-
[7]
Coopernaut: End-to- end driving with cooperative perception for networked vehicles,
J. Cui, H. Qiu, D. Chen, P. Stone, and Y . Zhu, “Coopernaut: End-to- end driving with cooperative perception for networked vehicles,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 252–17 262
2022
-
[8]
Towards collaborative autonomous driving: Simulation platform and end-to-end system,
G. Liu, Y . Hu, C. Xu, W. Mao, J. Ge, Z. Huang, Y . Lu, Y . Xu, J. Xia, Y . Wang,et al., “Towards collaborative autonomous driving: Simulation platform and end-to-end system,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[9]
Risk map as middleware: Toward interpretable cooperative end-to-end autonomous driving for risk-aware planning,
M. Lei, Z. Zhou, H. Li, J. Ma, and J. Hu, “Risk map as middleware: Toward interpretable cooperative end-to-end autonomous driving for risk-aware planning,”IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 818–825, 2025
2025
-
[10]
Towards interactive and learnable cooperative driving automation: a large language model-driven decision-making framework,
S. Fang, J. Liu, M. Ding, Y . Cui, C. Lv, P. Hang, and J. Sun, “Towards interactive and learnable cooperative driving automation: a large language model-driven decision-making framework,”IEEE Transactions on Vehicular Technology, 2025
2025
-
[11]
Autoware on board: Enabling autonomous vehicles with embedded systems,
S. Kato, S. Tokunaga, Y . Maruyama, S. Maeda, M. Hirabayashi, Y . Kitsukawa, A. Monrroy, T. Ando, Y . Fujii, and T. Azumi, “Autoware on board: Enabling autonomous vehicles with embedded systems,” in2018 ACM/IEEE 9th International Conference on Cyber-Physical Systems (ICCPS). IEEE, 2018, pp. 287–296
2018
-
[12]
Baidu Apollo EM Motion Planner
H. Fan, F. Zhu, C. Liu, L. Zhang, L. Zhuang, D. Li, W. Zhu, J. Hu, H. Li, and Q. Kong, “Baidu apollo em motion planner,”arXiv preprint arXiv:1807.08048, 2018
work page Pith review arXiv 2018
-
[13]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang,et al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[14]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
2023
-
[15]
St-p3: End- to-end vision-based autonomous driving via spatial-temporal feature learning,
S. Hu, L. Chen, P. Wu, H. Li, J. Yan, and D. Tao, “St-p3: End- to-end vision-based autonomous driving via spatial-temporal feature learning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 533–549
2022
-
[16]
Head: A bandwidth-efficient cooperative perception approach for heterogeneous connected and autonomous vehicles,
D. Qu, Q. Chen, Y . Zhu, Y . Zhu, S. S. Avedisov, S. Fu, and Q. Yang, “Head: A bandwidth-efficient cooperative perception approach for heterogeneous connected and autonomous vehicles,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 198–211
2024
- [17]
-
[18]
Cmp: Co- operative motion prediction with multi-agent communication,
Z. Wang, Y . Wang, Z. Wu, H. Ma, Z. Li, H. Qiu, and J. Li, “Cmp: Co- operative motion prediction with multi-agent communication,”IEEE Robotics and Automation Letters, 2025
2025
-
[19]
V2xpnp: Vehicle-to-everything spatio-temporal fusion for multi-agent perception and prediction,
Z. Zhou, H. Xiang, Z. Zheng, S. Z. Zhao, M. Lei, Y . Zhang, T. Cai, X. Liu, J. Liu, M. Bajji,et al., “V2xpnp: Vehicle-to-everything spatio-temporal fusion for multi-agent perception and prediction,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 25 399–25 409
2025
-
[20]
Autowarev2x: Reliable v2x communication and collective perception for autonomous driving,
Y . Asabe, E. Javanmardi, J. Nakazato, M. Tsukada, and H. Esaki, “Autowarev2x: Reliable v2x communication and collective perception for autonomous driving,” in2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring). IEEE, 2023, pp. 1–7
2023
-
[21]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[22]
Lidar-based cooperative relative localization,
J. Dong, Q. Chen, D. Qu, H. Lu, A. Ganlath, Q. Yang, S. Chen, and S. Labi, “Lidar-based cooperative relative localization,” in2023 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2023, pp. 1–8
2023
-
[23]
Ssn: Shape signature networks for multi-class object detection from point clouds,
X. Zhu, Y . Ma, T. Wang, Y . Xu, J. Shi, and D. Lin, “Ssn: Shape signature networks for multi-class object detection from point clouds,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 581–597
2020
-
[24]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705
2019
-
[25]
Center-based 3d object detec- tion and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detec- tion and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793
2021
-
[26]
MMDetection3D: OpenMMLab next-generation platform for general 3D object detection,
M. Contributors, “MMDetection3D: OpenMMLab next-generation platform for general 3D object detection,” https://github.com/ open-mmlab/mmdetection3d, 2020
2020
-
[27]
Method for registration of 3-d shapes,
P. J. Besl and N. D. McKay, “Method for registration of 3-d shapes,” inSensor fusion IV: control paradigms and data structures, vol. 1611. Spie, 1992, pp. 586–606
1992
-
[28]
The normal distributions transform: A new approach to laser scan matching,
P. Biber and W. Straßer, “The normal distributions transform: A new approach to laser scan matching,” inProceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003)(Cat. No. 03CH37453), vol. 3. IEEE, 2003, pp. 2743–2748
2003
-
[29]
Assessing the safety benefit of automatic collision avoidance systems (during emergency braking situations),
B. Sultan and M. McDonald, “Assessing the safety benefit of automatic collision avoidance systems (during emergency braking situations),” inProceedings of the 18th International Technical Conference on the Enhanced Safety of Vehicle.(DOT HS 809 543), 2003
2003
-
[30]
L. Westhofen, C. Neurohr, T. Koopmann, M. Butz, B. Sch ¨utt, F. Utesch, B. Kramer, C. Gutenkunst, and E. B¨ode, “Criticality metrics for automated driving: A review and suitability analysis of the state of the art,”arXiv preprint arXiv:2108.02403, 2021
-
[31]
Safety challenges for autonomous vehicles in the absence of connectivity,
A. Shetty, M. Yu, A. Kurzhanskiy, O. Grembek, H. Tavafoghi, and P. Varaiya, “Safety challenges for autonomous vehicles in the absence of connectivity,”Transportation research part C: emerging technolo- gies, vol. 128, p. 103133, 2021
2021
-
[32]
Does physical adversarial example really matter to autonomous driving? towards system-level effect of adversarial object evasion attack,
N. Wang, Y . Luo, T. Sato, K. Xu, and Q. A. Chen, “Does physical adversarial example really matter to autonomous driving? towards system-level effect of adversarial object evasion attack,” inProceed- ings of the IEEE/CVF international conference on computer vision, 2023, pp. 4412–4423
2023
-
[33]
V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception,
R. Xu, X. Xia, J. Li, H. Li, S. Zhang, Z. Tu, Z. Meng, H. Xiang, X. Dong, R. Song,et al., “V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 13 712–13 722
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.