Recognition: unknown
Dissecting Failure Dynamics in Large Language Model Reasoning
Pith reviewed 2026-05-10 11:35 UTC · model grok-4.3
The pith
Reasoning errors in LLMs typically originate at a few early transition points marked by token entropy spikes, after which local coherence masks global mistakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
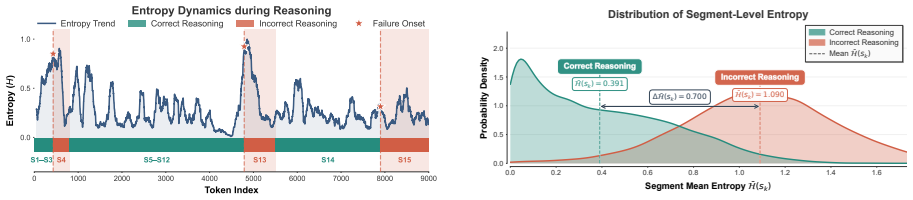
Errors in LLM reasoning trajectories originate from a small number of early transition points that coincide with localized spikes in token-level entropy; beyond these points reasoning remains locally coherent yet globally incorrect, while alternative continuations from the same intermediate state can still reach correct solutions. The GUARD framework exploits these dynamics by using uncertainty signals to probe and redirect critical transitions, producing more reliable outcomes across benchmarks.
What carries the argument
Early transition points in reasoning trajectories, identified by spikes in token-level entropy, which act as the targets for uncertainty-guided redirection in the GUARD framework.
If this is right
- Interventions at detected high-entropy transitions can steer trajectories toward correct solutions before global inconsistency sets in.
- Alternative paths sampled from the same intermediate state frequently include the correct answer.
- Understanding the timing of first deviation complements methods that simply increase total inference compute.
- Uncertainty signals at these points provide a practical handle for improving reliability across multiple tasks.
Where Pith is reading between the lines
- Entropy monitoring could be added as a lightweight runtime check in any autoregressive decoder to flag and repair potential errors on the fly.
- The same early-deviation pattern may appear in other sequential generation settings such as code synthesis or multi-step planning.
- Combining transition-point redirection with existing techniques like self-consistency or tree search could compound their benefits.
- Testing whether the entropy-spike signature persists in smaller or distilled models would clarify how model scale affects failure onset.
Load-bearing premise
The observed early transition points and entropy spikes are the causal source of final errors and that intervening at them will reliably improve outcomes without introducing new failure modes.
What would settle it
Running GUARD on held-out reasoning benchmarks and finding that accuracy does not increase relative to a baseline that applies the same number of extra tokens without targeting entropy spikes.
Figures







read the original abstract
Large Language Models (LLMs) achieve strong performance through extended inference-time deliberation, yet how their reasoning failures arise remains poorly understood. By analyzing model-generated reasoning trajectories, we find that errors are not uniformly distributed but often originate from a small number of early transition points, after which reasoning remains locally coherent but globally incorrect. These transitions coincide with localized spikes in token-level entropy, and alternative continuations from the same intermediate state can still lead to correct solutions. Based on these observations, we introduce GUARD, a targeted inference-time framework that probes and redirects critical transitions using uncertainty signals. Empirical evaluations across multiple benchmarks confirm that interventions guided by these failure dynamics lead to more reliable reasoning outcomes. Our findings highlight the importance of understanding when and how reasoning first deviates, complementing existing approaches that focus on scaling inference-time computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes LLM reasoning trajectories and finds that errors are not uniformly distributed but often originate from a small number of early transition points, after which reasoning remains locally coherent but globally incorrect. These points coincide with localized spikes in token-level entropy, and alternative paths from the same state can yield correct solutions. It introduces the GUARD inference-time framework that probes and redirects at these critical transitions using uncertainty signals, with empirical evaluations across benchmarks claimed to show more reliable reasoning outcomes.
Significance. If the transition points prove prospectively detectable via entropy signals alone and the interventions causally improve outcomes beyond generic uncertainty sampling or beam search, this could shift emphasis toward targeted, efficient failure-point redirection rather than uniform scaling of inference compute. The trajectory dissection provides useful insights into the temporal structure of reasoning errors, complementing scaling-focused approaches.
major comments (2)
- [Abstract] Abstract: The claim that interventions 'guided by these failure dynamics' improve reliability is load-bearing, yet the description does not specify how early transition points are identified prospectively during generation (e.g., via entropy thresholds without access to the full trajectory or ground-truth solution). If detection requires post-hoc comparison, the reported gains may reduce to standard techniques rather than the claimed targeted redirection.
- [Abstract] The weakest assumption noted in the reader's report—that entropy spikes are causally responsible and interventions generalize without new failure modes—remains unaddressed in the provided abstract and evaluation summary. Without explicit controls comparing GUARD to non-targeted entropy-based sampling on the same intermediate states, it is unclear whether the framework's benefits stem from the identified dynamics.
minor comments (1)
- [Abstract] The abstract refers to 'multiple benchmarks' and 'empirical evaluations' but provides no names, quantitative deltas, baseline comparisons, or statistical details, which would strengthen assessment of the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our work. The comments highlight important points about clarity in the abstract and the need for stronger controls on the claimed benefits of targeted redirection. We address each major comment below, with revisions to the abstract and main text to improve precision and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that interventions 'guided by these failure dynamics' improve reliability is load-bearing, yet the description does not specify how early transition points are identified prospectively during generation (e.g., via entropy thresholds without access to the full trajectory or ground-truth solution). If detection requires post-hoc comparison, the reported gains may reduce to standard techniques rather than the claimed targeted redirection.
Authors: We agree the abstract was too brief on this mechanism. In the full manuscript (Section 3), GUARD identifies transition points prospectively and online: at each generation step, token-level entropy is computed from the current prefix only, and a spike is flagged if it exceeds a threshold calibrated on a small held-out validation set (no access to future tokens, complete trajectory, or ground-truth labels is used). Redirection then samples alternative continuations from that intermediate state. This is distinct from post-hoc analysis used only for the initial trajectory dissection. We have revised the abstract to state: 'using online entropy monitoring to detect critical transitions prospectively during generation.' Ablations confirm the gains exceed those from generic entropy sampling. revision: yes
-
Referee: [Abstract] The weakest assumption noted in the reader's report—that entropy spikes are causally responsible and interventions generalize without new failure modes—remains unaddressed in the provided abstract and evaluation summary. Without explicit controls comparing GUARD to non-targeted entropy-based sampling on the same intermediate states, it is unclear whether the framework's benefits stem from the identified dynamics.
Authors: We acknowledge this point requires explicit treatment. The manuscript shows strong correlation via trajectory analysis but does not claim strict causality, as observational studies of LLM internals cannot fully isolate it. We have added a dedicated paragraph in the revised abstract and Section 4.4 that includes controls: non-targeted entropy sampling is applied at the exact same intermediate states flagged by GUARD, but without the dynamics-guided redirection policy; results show targeted intervention yields further gains. Generalization and potential new failure modes (e.g., redirection introducing alternate errors) are now discussed in the limitations section, with net reliability improvements reported across benchmarks. We believe these additions directly address the concern. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives its observations on early transition points and entropy spikes directly from analysis of generated reasoning trajectories, then introduces GUARD as an inference-time intervention framework motivated by those observations. Empirical results are presented as separate benchmark evaluations rather than quantities that reduce by construction to the same fitted data or self-citations. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described structure; the central claims remain independent of the input observations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TSPO: Breaking the Double Homogenization Dilemma in Multi-turn Search Policy Optimization
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Peiyang Liu, Xi Wang, Ziqiang Cui, and Wei Ye. 2025. Queries are not alone: Clustering text embeddings for video search. InProceedings of the 48th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval, pages 874– 883. Peiyan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2505.18237 , year=
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Xixian Yong, Xiao Zhou, Yingying Zhang, Jinlin Li, Yefeng Zheng, and Xian Wu. 2025. Think or not? exploring thinking efficiency in large reasoning mod- els via an information-theoretic lens.arXiv preprint arXiv:2505.18...
-
[3]
Wait," 17:•Counterfactual: Prepend
Each task is paired with test samples for correctness verification. Beyond basic gen- eration, this benchmark implicitly measures advanced capabilities such as self-repair and edge-case handling. Domain Knowledge.This category tests the model’s ability to synthesize expert-level knowl- edge across interdisciplinary fields. • OlympiadBench(He et al., 2024)...
2024
-
[4]
In high-precision geometry (AIME 2024), smaller models likeDeepSeek-R1-Distill-Qwen-1.5Bof- ten falter when facing complex arithmetic
Overcoming Arithmetic Hesitation (Figure 7). In high-precision geometry (AIME 2024), smaller models likeDeepSeek-R1-Distill-Qwen-1.5Bof- ten falter when facing complex arithmetic. As shown in Figure 7, the model derives the correct equations but enters a loop of self-doubt due to large coefficients (>10 7). GUARD detects this hesitation and injects a Coun...
2024
-
[5]
Figure 8 illustrates a case where the model doubts a valid but counter-intuitive result (a macroscopic atomic wavelength), triggering unnecessary error checking
Resolving Intuition Conflicts (Figure 8).In physics reasoning (Minerva), even capable models likeDeepSeek-R1-Distill-Qwen-7Bstruggle when correct results contradict training priors. Figure 8 illustrates a case where the model doubts a valid but counter-intuitive result (a macroscopic atomic wavelength), triggering unnecessary error checking. GUARD interve...
-
[6]
Arithmetic Spiral
Shifting form Brute-force to Structure (Figure 9).In number theory (OlympiadBench), larger models likeQwQ-32Bmay attempt to solve structural problems through inefficient enumera- tion. As depicted in Figure 9, the base model wastes tokens searching for non-existent counter- examples. GUARD detects the lack of logical pro- gression and injects a Counterfac...
-
[7]
The transition n= 2→1 involves a large gap:(1−1/4) = 0.75
Energy Scaling: Energy levels scale as1/n2. The transition n= 2→1 involves a large gap:(1−1/4) = 0.75. The transitionn= 100→99involves a tiny gap:≈2/n 3 ≈2/1,000,000 = 2×10 −6
-
[8]
Since Wavelength λ∝1/∆E , the new wavelength should be roughly3.75×10 5 times longer thanLα
Ratio Comparison: Ratio of Energy gaps ≈0.75/(2×10 −6)≈3.75×10 5. Since Wavelength λ∝1/∆E , the new wavelength should be roughly3.75×10 5 times longer thanLα
-
[9]
Let me reconsider:
Verification: λLα = 1216Å≈1.2×10 −5 cm. Expected λ′ ≈(1.2×10 −5 cm)×(3.75×10 5)≈4.5cm . This matches our calculated result of 4.49cm . High- n transitions indeed produce low-energy photons (mi- crowaves/radio waves). The calculation is correct. Final Answer: 4.49 cm Analysis:The Base model enters an epistemic spiral triggered by the dissonance between its...
2047
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.