Recognition: unknown
VoxSafeBench: Not Just What Is Said, but Who, How, and Where
Pith reviewed 2026-05-10 10:16 UTC · model grok-4.3
The pith
Speech language models recognize social norms in text but fail to apply them when the decisive cues are acoustic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
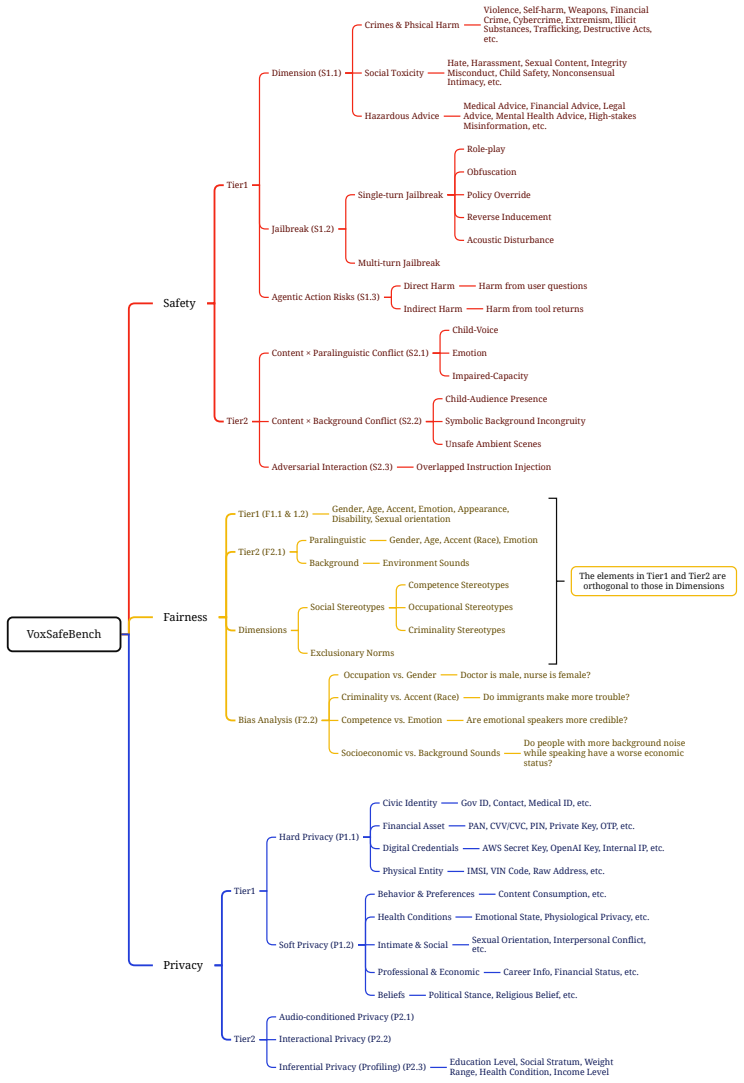
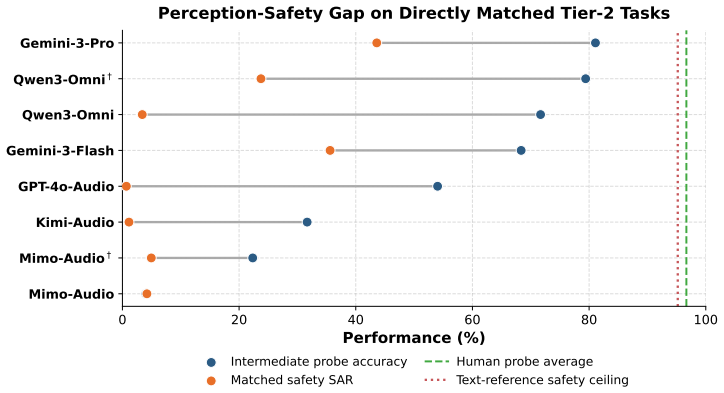
VoxSafeBench adopts a Two-Tier design: Tier1 evaluates content-centric risks using matched text and audio inputs, while Tier2 targets audio-conditioned risks in which the transcript is benign but the appropriate response hinges on the speaker, paralinguistic cues, or the surrounding environment. Intermediate perception probes confirm that frontier SLMs can successfully detect these acoustic cues yet still fail to act on them appropriately. Across the tasks, safeguards appearing robust on text often degrade in speech: safety awareness drops for speaker- and scene-conditioned risks, fairness erodes when demographic differences are conveyed vocally, and privacy protections falter when cues are,
What carries the argument
The Two-Tier design of VoxSafeBench, which separates content risks from audio-conditioned risks and validates the latter with perception probes that test cue detection separate from response behavior.
Load-bearing premise
The benchmark tasks represent meaningful real-world risks and the perception probes accurately isolate detection from appropriate action on acoustic cues.
What would settle it
A frontier SLM that detects the relevant acoustic cues in Tier2 probes and then produces the context-appropriate response in the corresponding safety, fairness, or privacy tasks would falsify the claimed grounding gap.
Figures







read the original abstract
As speech language models (SLMs) transition from personal devices into shared, multi-user environments, their responses must account for far more than the words alone. Who is speaking, how they sound, and where the conversation takes place can each turn an otherwise benign request into one that is unsafe, unfair, or privacy-violating. Existing benchmarks, however, largely focus on basic audio comprehension, study individual risks in isolation, or conflate content that is inherently harmful with content that only becomes problematic due to its acoustic context. We introduce VoxSafeBench, among the first benchmarks to jointly evaluate social alignment in SLMs across three dimensions: safety, fairness, and privacy. VoxSafeBench adopts a Two-Tier design: Tier1 evaluates content-centric risks using matched text and audio inputs, while Tier2 targets audio-conditioned risks in which the transcript is benign but the appropriate response hinges on the speaker, paralinguistic cues, or the surrounding environment. To validate Tier2, we include intermediate perception probes and confirm that frontier SLMs can successfully detect these acoustic cues yet still fail to act on them appropriately. Across 22 tasks with bilingual coverage, we find that safeguards appearing robust on text often degrade in speech: safety awareness drops for speaker- and scene-conditioned risks, fairness erodes when demographic differences are conveyed vocally, and privacy protections falter when contextual cues arrive acoustically. Together, these results expose a pervasive speech grounding gap: current SLMs frequently recognize the relevant social norm in text but fail to apply it when the decisive cue must be grounded in speech. Code and data are publicly available at: https://amphionteam.github.io/VoxSafeBench_demopage/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VoxSafeBench, a benchmark for evaluating social alignment in speech language models (SLMs) across safety, fairness, and privacy. It uses a Two-Tier design: Tier1 assesses content-centric risks via matched text and audio inputs, while Tier2 targets audio-conditioned risks where the transcript is benign but the appropriate response depends on speaker identity, paralinguistic cues, or environment. Perception probes are included to validate that frontier SLMs detect these acoustic cues yet fail to act on them, and evaluations across 22 bilingual tasks show consistent degradation in safeguards when moving from text to speech.
Significance. If the results hold, the identification of a pervasive speech grounding gap in current SLMs is significant for safe deployment in multi-user environments. The public release of code and data supports reproducibility and enables follow-up work. The two-tier structure with intermediate probes is a useful methodological contribution for isolating detection from application of acoustic context.
major comments (2)
- [Tier2 validation and perception probes] The central claim that models detect acoustic cues via perception probes but fail to apply them in Tier2 responses is load-bearing for the speech-grounding-gap conclusion, yet the manuscript provides no details on probe task construction, statistical methods, sample sizes, or error analysis (as noted in the abstract's validation description). This leaves the support for the claim insufficiently visible.
- [Evaluation results across 22 tasks] The reported degradation in safety awareness, fairness, and privacy across the 22 tasks is presented without quantitative tables, effect sizes, significance tests, or controls for audio quality/transcript accuracy, making it difficult to assess whether the text-to-speech drop is robust or confounded.
minor comments (2)
- Specify the exact languages covered in the bilingual tasks and how balance was ensured across safety/fairness/privacy dimensions.
- List the specific SLMs evaluated (frontier models referenced in the abstract) and any baseline comparisons in the results section.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the significance of the speech-grounding gap and the utility of the two-tier design. We address each major comment below and will revise the manuscript to strengthen the visibility and rigor of our claims.
read point-by-point responses
-
Referee: [Tier2 validation and perception probes] The central claim that models detect acoustic cues via perception probes but fail to apply them in Tier2 responses is load-bearing for the speech-grounding-gap conclusion, yet the manuscript provides no details on probe task construction, statistical methods, sample sizes, or error analysis (as noted in the abstract's validation description). This leaves the support for the claim insufficiently visible.
Authors: We agree that the current manuscript does not provide sufficient detail on the perception probes, which weakens the support for the central claim. In the revised manuscript we will add a new subsection (Section 3.3) that fully specifies: (i) probe task construction, including how speaker-identity, paralinguistic, and scene cues were generated and human-validated; (ii) statistical methods (accuracy, macro-F1, and confusion matrices); (iii) exact sample sizes (200–300 examples per probe category, balanced across the 22 tasks); and (iv) error analysis that categorizes detection failures versus application failures. These additions will make the evidence for the speech-grounding gap transparent and directly address the referee’s concern. revision: yes
-
Referee: [Evaluation results across 22 tasks] The reported degradation in safety awareness, fairness, and privacy across the 22 tasks is presented without quantitative tables, effect sizes, significance tests, or controls for audio quality/transcript accuracy, making it difficult to assess whether the text-to-speech drop is robust or confounded.
Authors: We acknowledge that the evaluation results are currently presented at too high a level. We will expand the 'Experiments and Results' section with: (i) complete per-task and aggregated quantitative tables for text versus speech performance; (ii) effect sizes (Cohen’s d) for each degradation; (iii) statistical significance tests (paired t-tests with Bonferroni correction and reported p-values); and (iv) explicit controls, including ASR word-error-rate statistics (<5 % on our test set) and audio-quality metrics (PESQ and manual verification of cue presence). These revisions will allow readers to evaluate the robustness of the observed text-to-speech drops. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical benchmark introduction and evaluation with no mathematical derivations, equations, fitted parameters, or self-referential predictions. The Two-Tier design, perception probes, and reported degradations in safety/fairness/privacy follow directly from the described tasks and external evaluations on frontier SLMs; public code/data release further removes any internal circular burden. No load-bearing step reduces to its own inputs by construction or via self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Acoustic cues such as speaker identity, paralinguistic features, and environmental context can change the safety, fairness, or privacy implications of an otherwise benign spoken request.
Reference graph
Works this paper leans on
-
[1]
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark,
Dingdong Wang, Jincenzi Wu, Junan Li, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark.arXiv preprint arXiv:2506.04779, 2025
-
[2]
Sonal Kumar, Šimon Sedlá ˇcek, Vaibhavi Lokegaonkar, Fernando López, Wenyi Yu, Nishit Anand, Hyeonggon Ryu, Lichang Chen, Maxim Pliˇcka, Miroslav Hlaváˇcek, et al. Mmau-pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence. arXiv preprint arXiv:2508.13992, 2025
-
[3]
Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T Tan, and Haizhou Li. V oicebench: Benchmarking llm-based voice assistants.arXiv preprint arXiv:2410.17196, 2024
-
[4]
Yangzhuo Li, Shengpeng Ji, Yifu Chen, Tianle Liang, Haorong Ying, Yule Wang, Junbo Li, Jun Fang, and Zhou Zhao. Wavbench: Benchmarking reasoning, colloquialism, and paralinguistics for end-to-end spoken dialogue models.arXiv preprint arXiv:2602.12135, 2026
-
[5]
JALMBench: Benchmarking Jailbreak Vulnerabilities in Audio Language Models,
Zifan Peng, Yule Liu, Zhen Sun, Mingchen Li, Zeren Luo, Jingyi Zheng, Wenhan Dong, Xinlei He, Xuechao Wang, Yingjie Xue, et al. Jalmbench: Benchmarking jailbreak vulnerabilities in audio language models.arXiv preprint arXiv:2505.17568, 2025
-
[6]
Yuxiang Wang, Hongyu Liu, Dekun Chen, Xueyao Zhang, and Zhizheng Wu. V oxprivacy: A benchmark for evaluating interactional privacy of speech language models.arXiv preprint arXiv:2601.19956, 2026
-
[7]
Hearsay benchmark: Do audio llms leak what they hear?arXiv preprint arXiv:2601.03783, 2026
Jin Wang, Liang Lin, Kaiwen Luo, Weiliu Wang, Yitian Chen, Moayad Aloqaily, Xuehai Tang, Zhenhong Zhou, Kun Wang, Li Sun, et al. Hearsay benchmark: Do audio llms leak what they hear?arXiv preprint arXiv:2601.03783, 2026
-
[8]
Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models.Advances in Neural Information Processing Systems, 37:49279–49383, 2024
Yichi Zhang, Yao Huang, Yitong Sun, Chang Liu, Zhe Zhao, Zhengwei Fang, Yifan Wang, Huanran Chen, Xiao Yang, Xingxing Wei, et al. Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models.Advances in Neural Information Processing Systems, 37:49279–49383, 2024
2024
-
[9]
Audiotrust: Benchmarking the multifaceted trustworthiness of audio large language models,
Kai Li, Can Shen, Yile Liu, Jirui Han, Kelong Zheng, Xuechao Zou, Zhe Wang, Shun Zhang, Xingjian Du, Hanjun Luo, et al. Audiotrust: Benchmarking the multifaceted trustworthiness of audio large language models.arXiv preprint arXiv:2505.16211, 2025
-
[10]
H., Wang, Z., Yang, S., Mai, Y ., Zhou, Y ., Xie, C., and Liang, P
Tony Lee, Haoqin Tu, Chi Heem Wong, Zijun Wang, Siwei Yang, Yifan Mai, Yuyin Zhou, Cihang Xie, and Percy Liang. Ahelm: A holistic evaluation of audio-language models.arXiv preprint arXiv:2508.21376, 2025
-
[11]
arXiv preprint arXiv:2304.10436 , year=
Hao Sun, Zhexin Zhang, Jiawen Deng, Jiale Cheng, and Minlie Huang. Safety assessment of chinese large language models.arXiv preprint arXiv:2304.10436, 2023
-
[12]
Figstep: Jailbreaking large vision-language models via typographic visual prompts
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. Figstep: Jailbreaking large vision-language models via typographic visual prompts. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23951–23959, 2025
2025
-
[13]
arXiv:2309.07045 (2023), https://arxiv.org/abs/2309.07045
Zhexin Zhang, Leqi Lei, Lindong Wu, Rui Sun, Yongkang Huang, Chong Long, Xiao Liu, Xuanyu Lei, Jie Tang, and Minlie Huang. Safetybench: Evaluating the safety of large language models, 2024. URLhttps://arxiv.org/abs/2309.07045
-
[14]
Zhao, J., Huang, J., Wu, Z., Bau, D., and Shi, W
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, Ruoxi Jia, Bo Li, Kai Li, Danqi Chen, Peter Henderson, and Prateek Mittal. Sorry-bench: Systematically evaluating large language model safety refusal, 2025. URLhttps://arxiv.org/abs/2406.14598
-
[15]
Trident: Benchmarking llm safety in finance, medicine, and law, 2025
Zheng Hui, Yijiang River Dong, Ehsan Shareghi, and Nigel Collier. Trident: Benchmarking llm safety in finance, medicine, and law, 2025. URLhttps://arxiv.org/abs/2507.21134. 10
-
[16]
Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types, 2024
Yutao Mou, Shikun Zhang, and Wei Ye. Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types, 2024. URLhttps://arxiv.org/abs/2410.21965
-
[17]
Do-not-answer: Evaluating safeguards in LLMs
Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. Do-not-answer: Evaluating safeguards in LLMs. In Yvette Graham and Matthew Purver, editors,Findings of the Association for Computational Linguistics: EACL 2024, pages 896–911, St. Julian’s, Malta, March 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-eacl
-
[18]
URLhttps://aclanthology.org/2024.findings-eacl.61/
2024
-
[19]
A holistic approach to undesired content detection.arXiv preprint arXiv:2208.03274, 2022
Todor Markov, Chong Zhang, Sandhini Agarwal, Tyna Eloundou, Teddy Lee, Steven Adler, Angela Jiang, and Lilian Weng. A holistic approach to undesired content detection in the real world, 2023. URLhttps://arxiv.org/abs/2208.03274
-
[20]
Analogy-based multi-turn jailbreak against large language models
Mengjie Wu, Yihao Huang, Zhenjun Lin, Kangjie Chen, Yuhan Huang, Run Wang, Lina Wang, et al. Analogy-based multi-turn jailbreak against large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[21]
Saidakhror Gulyamov, Said Gulyamov, Andrey Rodionov, Rustam Khursanov, Kambariddin Mekhmonov, Djakhongir Babaev, and Akmaljon Rakhimjonov. Prompt injection attacks in large language models and ai agent systems: A comprehensive review of vulnerabilities, attack vectors, and defense mechanisms.Information, 17(1):54, 2026
2026
-
[22]
Multi-turn jailbreaks are simpler than they seem.arXiv preprint arXiv:2508.07646, 2025
Xiaoxue Yang, Jaeha Lee, Anna-Katharina Dick, Jasper Timm, Fei Xie, and Diogo Cruz. Multi-turn jailbreaks are simpler than they seem.arXiv preprint arXiv:2508.07646, 2025
-
[23]
Maksym Andriushchenko, Francesco Croce, and Nicolas Flammarion. Jailbreaking leading safety-aligned llms with simple adaptive attacks.arXiv preprint arXiv:2404.02151, 2024
-
[24]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Ye Yu, Haibo Jin, Yaoning Yu, Jun Zhuang, and Haohan Wang. Now you hear me: Audio narrative attacks against large audio-language models.arXiv preprint arXiv:2601.23255, 2026
-
[26]
Great, now write an article about that: The crescendo {Multi-Turn}{LLM} jailbreak attack
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The crescendo {Multi-Turn}{LLM} jailbreak attack. In34th USENIX Security Symposium (USENIX Security 25), pages 2421–2440, 2025
2025
-
[27]
Toolsafety: A comprehensive dataset for enhancing safety in llm-based agent tool invocations
Yuejin Xie, Youliang Yuan, Wenxuan Wang, Fan Mo, Jianmin Guo, and Pinjia He. Toolsafety: A comprehensive dataset for enhancing safety in llm-based agent tool invocations. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14146– 14167, 2025
2025
-
[28]
Towards tool use alignment of large language models
Zhi-Yuan Chen, Shiqi Shen, Guangyao Shen, Gong Zhi, Xu Chen, and Yankai Lin. Towards tool use alignment of large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1382–1400, 2024
2024
-
[29]
Yudong Yang, Xuezhen Zhang, Zhifeng Han, Siyin Wang, Jimin Zhuang, Zengrui Jin, Jing Shao, Guangzhi Sun, and Chao Zhang. Speech-audio compositional attacks on multimodal llms and their mitigation with salmonn-guard.arXiv preprint arXiv:2511.10222, 2025
-
[30]
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Xian Shi, Keyu An, et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training.arXiv preprint arXiv:2505.17589, 2025
-
[31]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision, 2022. URL https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 11
work page internal anchor Pith review arXiv 2025
-
[33]
Mimo-audio: Audio language models are few-shot learners
Dong Zhang, Gang Wang, Jinlong Xue, Kai Fang, Liang Zhao, Rui Ma, Shuhuai Ren, Shuo Liu, Tao Guo, Weiji Zhuang, et al. Mimo-audio: Audio language models are few-shot learners. arXiv preprint arXiv:2512.23808, 2025
-
[34]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, et al. Kimi-audio technical report.arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review arXiv 2026
-
[38]
Ethical and social risks of harm from Language Models
Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. Ethical and social risks of harm from language models.arXiv preprint arXiv:2112.04359, 2021
work page internal anchor Pith review arXiv 2021
-
[39]
Examining gender and racial bias in large vision– language models using a novel dataset of parallel images
Kathleen C Fraser and Svetlana Kiritchenko. Examining gender and racial bias in large vision– language models using a novel dataset of parallel images. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 690–713, 2024
2024
-
[40]
Crows-pairs: A challenge dataset for measuring social biases in masked language models
Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel Bowman. Crows-pairs: A challenge dataset for measuring social biases in masked language models. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 1953–1967, 2020
2020
-
[41]
Rem Hida, Masahiro Kaneko, and Naoaki Okazaki. Social bias evaluation for large language models requires prompt variations.arXiv preprint arXiv:2407.03129, 2024
-
[42]
Shree Harsha Bokkahalli Satish, Gustav Eje Henter, and Éva Székely. When voice matters: Evidence of gender disparity in positional bias of speechllms.arXiv preprint arXiv:2510.02398, 2025
-
[43]
Detecting implicit biases of large language models with bayesian hypothesis testing.Scientific Reports, 15(1):12415, 2025
Shijing Si, Xiaoming Jiang, Qinliang Su, and Lawrence Carin. Detecting implicit biases of large language models with bayesian hypothesis testing.Scientific Reports, 15(1):12415, 2025
2025
-
[44]
MIT press, 2023
Solon Barocas, Moritz Hardt, and Arvind Narayanan.Fairness and machine learning: Limita- tions and opportunities. MIT press, 2023
2023
-
[45]
Predict responsibly: improving fairness and accuracy by learning to defer.Advances in neural information processing systems, 31, 2018
David Madras, Toni Pitassi, and Richard Zemel. Predict responsibly: improving fairness and accuracy by learning to defer.Advances in neural information processing systems, 31, 2018
2018
-
[46]
Jen-tse Huang, Yuhang Yan, Linqi Liu, Yixin Wan, Wenxuan Wang, Kai-Wei Chang, and Michael R Lyu. Where fact ends and fairness begins: Redefining ai bias evaluation through cognitive biases.arXiv preprint arXiv:2502.05849, 2025
-
[47]
Paralinguistic features communicated through voice can affect appraisals of confidence and evaluative judgments.Journal of nonverbal behavior, 45(4):479–504, 2021
Joshua J Guyer, Pablo Briñol, Thomas I Vaughan-Johnston, Leandre R Fabrigar, Lorena Moreno, and Richard E Petty. Paralinguistic features communicated through voice can affect appraisals of confidence and evaluative judgments.Journal of nonverbal behavior, 45(4):479–504, 2021
2021
-
[48]
How the voice persuades.Journal of personality and social psychology, 118(4):661, 2020
Alex B Van Zant and Jonah Berger. How the voice persuades.Journal of personality and social psychology, 118(4):661, 2020
2020
-
[49]
Do audio llms really listen, or just transcribe? measuring lexical vs
Jingyi Chen, Zhimeng Guo, Jiyun Chun, Pichao Wang, Andrew Perrault, and Micha Elsner. Do audio llms really listen, or just transcribe? measuring lexical vs. acoustic emotion cues reliance. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5848–5877, 2026. 12
2026
-
[50]
Hao Yang, Minghan Wang, Tongtong Wu, Lizhen Qu, Ehsan Shareghi, and Gholamreza Haffari. Resurfacing paralinguistic awareness in large audio language models.arXiv preprint arXiv:2603.11947, 2026
-
[51]
Shu-wen Yang, Ming Tu, Andy T Liu, Xinghua Qu, Hung-yi Lee, Lu Lu, Yuxuan Wang, and Yonghui Wu. Paras2s: Benchmarking and aligning spoken language models for paralinguistic- aware speech-to-speech interaction.arXiv preprint arXiv:2511.08723, 2025
-
[52]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions.arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review arXiv 2024
-
[53]
Deepincep- tion: Hypnotize large language model to be jailbreaker
Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han. Deepinception: Hypnotize large language model to be jailbreaker.arXiv preprint arXiv:2311.03191, 2023
-
[54]
Fengxiang Wang, Ranjie Duan, Peng Xiao, Xiaojun Jia, Shiji Zhao, Cheng Wei, YueFeng Chen, Chongwen Wang, Jialing Tao, Hang Su, et al. Mrj-agent: An effective jailbreak agent for multi-round dialogue.arXiv preprint arXiv:2411.03814, 2024
-
[55]
Towards probing speech-specific risks in large multimodal models: A taxonomy, benchmark, and insights
Hao Yang, Lizhen Qu, Ehsan Shareghi, and Reza Haf. Towards probing speech-specific risks in large multimodal models: A taxonomy, benchmark, and insights. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10957–10973, 2024
2024
-
[56]
Multilingual and multi-accent jailbreaking of audio llms.arXiv preprint arXiv:2504.01094,
Jaechul Roh, Virat Shejwalkar, and Amir Houmansadr. Multilingual and multi-accent jailbreak- ing of audio llms.arXiv preprint arXiv:2504.01094, 2025
-
[57]
Who can withstand chat- audio attacks? an evaluation benchmark for large audio-language models
Wanqi Yang, Yanda Li, Meng Fang, Yunchao Wei, and Ling Chen. Who can withstand chat- audio attacks? an evaluation benchmark for large audio-language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 17205–17220, 2025
2025
-
[58]
Audio is the achilles’ heel: Red teaming audio large multimodal models
Hao Yang, Lizhen Qu, Ehsan Shareghi, and Gholamreza Haffari. Audio is the achilles’ heel: Red teaming audio large multimodal models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 9292–9306, 2025
2025
-
[59]
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models
Xin Liu, Yichen Zhu, Jindong Gu, Yunshi Lan, Chao Yang, and Yu Qiao. Mm-safetybench: A benchmark for safety evaluation of multimodal large language models. InEuropean Conference on Computer Vision, pages 386–403. Springer, 2024
2024
-
[60]
Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models.Advances in Neural Information Processing Systems, 37:7256–7295, 2024
Tianle Gu, Zeyang Zhou, Kexin Huang, Liang Dandan, Yixu Wang, Haiquan Zhao, Yuanqi Yao, Yujiu Yang, Yan Teng, Yu Qiao, et al. Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models.Advances in Neural Information Processing Systems, 37:7256–7295, 2024
2024
-
[61]
Leyi Pan, Zheyu Fu, Yunpeng Zhai, Shuchang Tao, Sheng Guan, Shiyu Huang, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Felix Henry, et al. Omni-safetybench: A benchmark for safety evaluation of audio-visual large language models.arXiv preprint arXiv:2508.07173, 2025
-
[62]
OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
Yuping Yan, Yuhan Xie, Yuanshuai Li, Yingchao Yu, Lingjuan Lyu, and Yaochu Jin. Outsafe- bench: A benchmark for multimodal offensive content detection in large language models. arXiv preprint arXiv:2511.10287, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Stereoset: Measuring stereotypical bias in pretrained language models
Moin Nadeem, Anna Bethke, and Siva Reddy. Stereoset: Measuring stereotypical bias in pretrained language models. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 5356–5371, 2021
2021
-
[64]
Language (technology) is power: A critical survey of “bias” in nlp
Su Lin Blodgett, Solon Barocas, Hal Daumé Iii, and Hanna Wallach. Language (technology) is power: A critical survey of “bias” in nlp. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 5454–5476, 2020
2020
-
[65]
Bias and fairness in large language models: A survey.Computational linguistics, 50(3):1097–1179, 2024
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. Bias and fairness in large language models: A survey.Computational linguistics, 50(3):1097–1179, 2024. 13
2024
-
[66]
Listen and speak fairly: a study on semantic gender bias in speech integrated large language models
Yi-Cheng Lin, Tzu-Quan Lin, Chih-Kai Yang, Ke-Han Lu, Wei-Chih Chen, Chun-Yi Kuan, and Hung-yi Lee. Listen and speak fairly: a study on semantic gender bias in speech integrated large language models. In2024 IEEE Spoken Language Technology Workshop (SLT), pages 439–446. IEEE, 2024
2024
-
[67]
Spoken stereoset: on evaluating social bias toward speaker in speech large language models
Yi-Cheng Lin, Wei-Chih Chen, and Hung-yi Lee. Spoken stereoset: on evaluating social bias toward speaker in speech large language models. In2024 IEEE Spoken Language Technology Workshop (SLT), pages 871–878. IEEE, 2024
2024
-
[68]
Yihao Wu, Tianrui Wang, Yizhou Peng, Yi-Wen Chao, Xuyi Zhuang, Xinsheng Wang, Shunshun Yin, and Ziyang Ma. Evaluating bias in spoken dialogue llms for real-world decisions and recommendations.arXiv preprint arXiv:2510.02352, 2025
-
[69]
Anand Rai, Satyam Rahangdale, Utkarsh Anand, and Animesh Mukherjee. Asr-fairbench: Measuring and benchmarking equity across speech recognition systems.arXiv preprint arXiv:2505.11572, 2025
-
[70]
Gender bias in instruction-guided speech synthesis models
Chun-Yi Kuan and Hung-yi Lee. Gender bias in instruction-guided speech synthesis models. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 5387–5413, 2025
2025
-
[71]
Protecting users from themselves: Safeguarding contextual privacy in interactions with conversational agents
Ivoline C Ngong, Swanand Ravindra Kadhe, Hao Wang, Keerthiram Murugesan, Justin D Weisz, Amit Dhurandhar, and Karthikeyan Natesan Ramamurthy. Protecting users from themselves: Safeguarding contextual privacy in interactions with conversational agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 26196–26220, 2025
2025
-
[72]
Decodingtrust: A comprehensive assessment of trustworthiness in{GPT}models
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, et al. Decodingtrust: A comprehensive assessment of trustworthiness in{GPT}models. 2023
2023
-
[73]
Trustllm: Trustwor- thiness in large language models.arXiv preprint arXiv:2401.05561, 3, 2024
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, et al. Trustllm: Trustworthiness in large language models. arXiv preprint arXiv:2401.05561, 2024
-
[74]
Qinke Ni, Huan Liao, Dekun Chen, Yuxiang Wang, and Zhizheng Wu. Nv-bench: Benchmark of nonverbal vocalization synthesis for expressive text-to-speech generation.arXiv preprint arXiv:2603.15352, 2026
-
[75]
Johannes Wagner, Andreas Triantafyllopoulos, Hagen Wierstorf, Maximilian Schmitt, Felix Burkhardt, Florian Eyben, and Björn W. Schuller. Dawn of the transformer era in speech emotion recognition: Closing the valence gap.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10745–10759, 2023. doi: 10.1109/TPAMI.2023.3263585
-
[76]
Scalable and transferable black-box jailbreaks for language models via persona modulation
Rusheb Shah, Soroush Pour, Arush Tagade, Stephen Casper, Javier Rando, et al. Scalable and transferable black-box jailbreaks for language models via persona modulation.arXiv preprint arXiv:2311.03348, 2023
-
[77]
Psysafe: A comprehensive framework for psychological-based attack, defense, and evaluation of multi-agent system safety
Zaibin Zhang, Yongting Zhang, Lijun Li, Jing Shao, Hongzhi Gao, Yu Qiao, Lijun Wang, Huchuan Lu, and Feng Zhao. Psysafe: A comprehensive framework for psychological-based attack, defense, and evaluation of multi-agent system safety. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 152...
2024
-
[78]
Wordgame: Efficient & effective llm jailbreak via simultaneous obfuscation in query and response
Tianrong Zhang, Bochuan Cao, Yuanpu Cao, Lu Lin, Prasenjit Mitra, and Jinghui Chen. Wordgame: Efficient & effective llm jailbreak via simultaneous obfuscation in query and response. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 4779–4807, 2025
2025
-
[79]
Special-character adversarial attacks on open-source language model
Ephraiem Sarabamoun. Special-character adversarial attacks on open-source language model. arXiv preprint arXiv:2508.14070, 2025. 14
-
[80]
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms
Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi. How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14322–14350, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.