Recognition: unknown
DEEP-GAP: Deep-learning Evaluation of Execution Parallelism in GPU Architectural Performance
Pith reviewed 2026-05-10 08:56 UTC · model grok-4.3
The pith
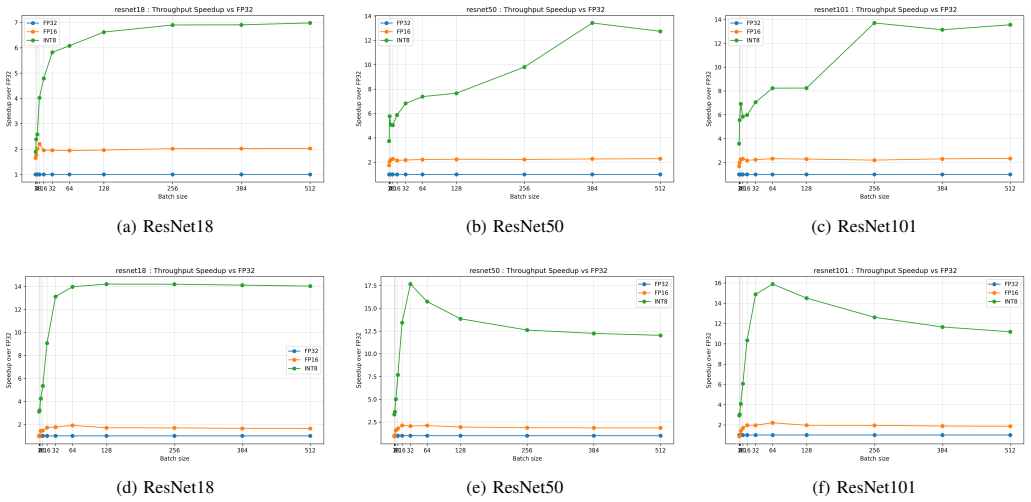
NVIDIA L4 GPU achieves up to 4.4x higher inference throughput than T4, peaking at smaller batch sizes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
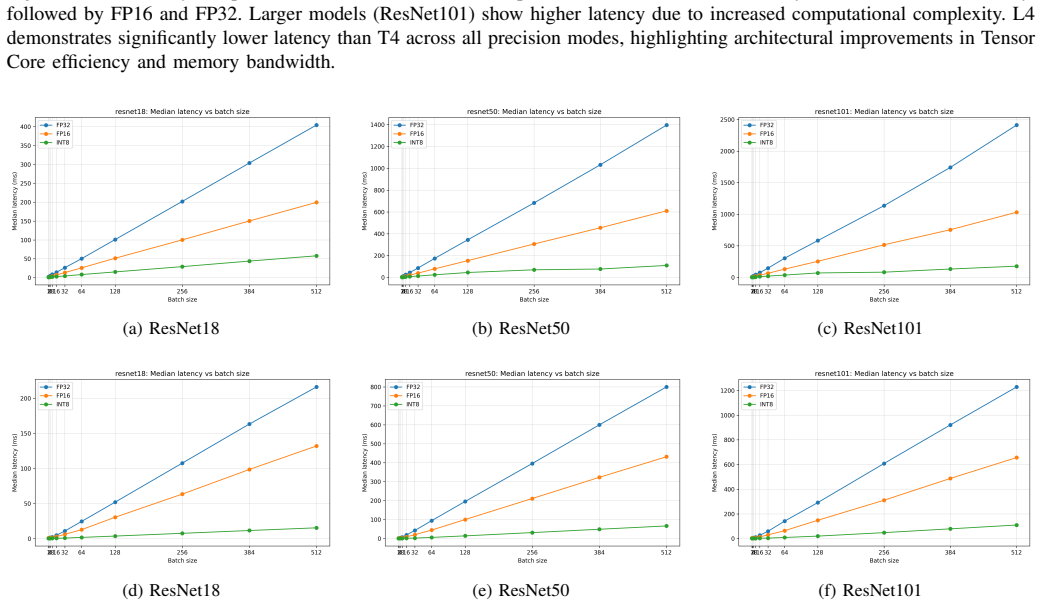
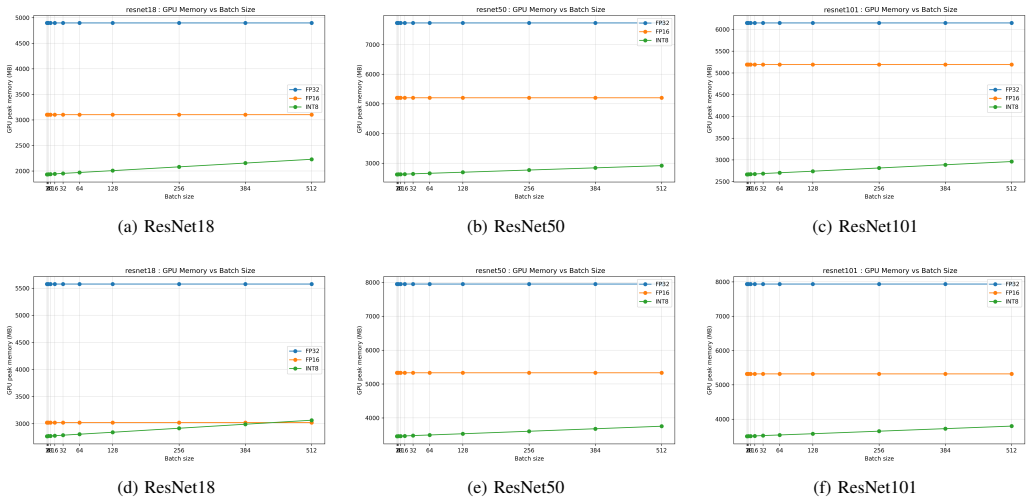
Using the DEEP-GAP evaluation on ResNet18, ResNet50, and ResNet101 models in FP32, FP16, and INT8 modes with PyTorch and TensorRT, the L4 GPU delivers up to 4.4x higher throughput than the T4 and reaches peak efficiency at batch sizes between 16 and 32. This improves latency-throughput tradeoffs for latency-sensitive workloads. Reduced precision yields large gains, with INT8 reaching up to 58x throughput over CPU baselines, while the T4 remains competitive for large-batch cases where cost or power efficiency matters.
What carries the argument
DEEP-GAP, a controlled side-by-side benchmarking method that extends prior GPU evaluation techniques to measure inference throughput and efficiency across GPU generations and precision modes.
If this is right
- INT8 precision can deliver up to 58x higher throughput than CPU baselines across the tested models.
- L4 GPUs improve options for latency-sensitive inference by hitting peak efficiency at smaller batches than prior generations.
- T4 GPUs remain suitable for high-volume large-batch workloads when power or cost per unit throughput is the priority.
- Deployments can select precision mode, batch size, and GPU generation together to meet specific latency or efficiency targets.
Where Pith is reading between the lines
- Operators could mix L4 and T4 cards within the same rack according to whether workloads are latency-focused or throughput-focused at scale.
- The same controlled comparison method could be applied to newer GPU generations or to training workloads to track how architectural changes accumulate.
- If the small-batch advantage holds more broadly, inference frameworks might default to lower batch sizes on newer hardware to reduce tail latency.
Load-bearing premise
The three ResNet models together with the selected batch sizes, precisions, and software frameworks stand in for typical production inference workloads.
What would settle it
Repeating the measurements on transformer models or on traces from actual production inference services would show whether the 4.4x throughput edge and the 16-32 batch-size efficiency peak still appear.
Figures









read the original abstract
Modern datacenters increasingly rely on low-power, single-slot inference accelerators to balance performance, energy efficiency, and rack density constraints. The NVIDIA T4 GPU has become widely deployed due to strong performance per watt and mature software support. Its successor, the NVIDIA L4 GPU, introduces improvements in Tensor Core throughput, cache capacity, memory bandwidth, and parallel execution capability. However, limited empirical evidence quantifies the practical inference performance gap between these two generations under controlled and reproducible conditions. This work introduces DEEP-GAP, a systematic evaluation extending the GDEV-AI methodology to GPU inference. Using identical configurations and workloads, we evaluate ResNet18, ResNet50, and ResNet101 across FP32, FP16, and INT8 precision modes using PyTorch and TensorRT. Results show that reduced precision significantly improves performance, with INT8 achieving up to 58x throughput improvement over CPU baselines. L4 achieves up to 4.4x higher throughput than T4 while reaching peak efficiency at smaller batch sizes between 16 and 32, improving latency-throughput tradeoffs for latency-sensitive workloads. T4 remains competitive for large batch workloads where cost or power efficiency is important. DEEP-GAP provides practical guidance for selecting precision modes, batch sizes, and GPU architectures for modern inference deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DEEP-GAP, an extension of the GDEV-AI methodology, to empirically compare NVIDIA T4 and L4 GPUs for deep learning inference. Using identical configurations, it evaluates ResNet18, ResNet50, and ResNet101 models under FP32, FP16, and INT8 precisions with both PyTorch and TensorRT frameworks. Key claims include up to 4.4x higher throughput on L4 versus T4, peak efficiency on L4 at batch sizes 16-32 (versus larger batches for T4), and up to 58x throughput gains for INT8 over CPU baselines, with guidance on precision, batch size, and architecture selection for inference workloads.
Significance. If the controlled measurements hold, the work provides practical, reproducible empirical data on generational improvements in low-power inference GPUs, particularly L4's advantages in Tensor Core throughput, cache, bandwidth, and parallelism for latency-sensitive scenarios. The systematic cross-precision and cross-framework design, combined with direct T4/L4 comparisons under matched conditions, offers actionable insights for datacenter deployment decisions where power, density, and latency tradeoffs matter.
major comments (2)
- [Abstract and Results] Abstract and Results: The central quantitative claims (4.4x L4 vs. T4 throughput and 58x INT8 vs. CPU) are reported as point values without error bars, standard deviations, number of runs, or exclusion criteria. This directly affects verifiability of the headline measurements that support the latency-throughput tradeoff interpretation.
- [Evaluation and Discussion] Evaluation and Discussion: The claim that L4 improves latency-throughput tradeoffs for latency-sensitive workloads rests on batch-size scaling observed only for ResNet18/50/101; no ablation or sensitivity analysis on other workload classes (e.g., transformers or recommendation models) is provided, so the architectural interpretation cannot be separated from model-specific traits.
minor comments (2)
- A summary table comparing key T4 and L4 hardware parameters (Tensor Core throughput, memory bandwidth, cache sizes) would help readers contextualize the observed deltas without external lookup.
- [Abstract] The abstract should explicitly state the precise model, precision, and batch size at which the 4.4x throughput figure is attained, rather than leaving it as an unqualified maximum.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation and the detailed feedback on verifiability and scope. We address each major comment below and have revised the manuscript accordingly to improve clarity and precision.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The central quantitative claims (4.4x L4 vs. T4 throughput and 58x INT8 vs. CPU) are reported as point values without error bars, standard deviations, number of runs, or exclusion criteria. This directly affects verifiability of the headline measurements that support the latency-throughput tradeoff interpretation.
Authors: We agree that statistical details enhance verifiability. In the revised manuscript we now state that each configuration was executed 10 times under identical conditions, report mean throughput values, and include standard deviations in the results tables and key figures. The abstract and results sections have been updated to reference these details. Variations were small in our controlled environment, but the added information addresses the concern directly. revision: yes
-
Referee: [Evaluation and Discussion] Evaluation and Discussion: The claim that L4 improves latency-throughput tradeoffs for latency-sensitive workloads rests on batch-size scaling observed only for ResNet18/50/101; no ablation or sensitivity analysis on other workload classes (e.g., transformers or recommendation models) is provided, so the architectural interpretation cannot be separated from model-specific traits.
Authors: We acknowledge the limitation. Our evaluation deliberately focuses on ResNet models as representative CNN inference workloads. In the revised version we have qualified all relevant claims to specify 'for ResNet-based models' and added a dedicated paragraph in the discussion section noting that broader applicability to transformers or recommendation models remains future work. This prevents overgeneralization while retaining the value of the controlled T4/L4 comparison for the evaluated class of workloads. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivations or fitted predictions
full rationale
The paper reports direct experimental throughput and latency results for ResNet models on T4 and L4 GPUs across precisions and frameworks. No equations, parameter fitting, self-citations as uniqueness theorems, or renamings of known results appear in the provided text. Claims such as 'L4 achieves up to 4.4x higher throughput' and 'peak efficiency at smaller batch sizes' are presented as measured outcomes, not derived quantities. The evaluation methodology (DEEP-GAP extending GDEV-AI) is described as a systematic comparison under identical conditions, with no load-bearing steps that reduce to inputs by construction. Generalization concerns exist but are outside the circularity definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ImageNet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. Hinton, “ImageNet classification with deep convolutional neural networks,” NeurIPS, 2012
2012
-
[2]
ImageNet: A Large-Scale Hierarchical Image Database,
J. Deng et al., “ImageNet: A Large-Scale Hierarchical Image Database,” CVPR, 2009
2009
-
[3]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” CVPR, 2016
2016
-
[4]
An Analysis of Deep Neural Network Models for Practical Applications.arXiv2017, arXiv:1605.07678
A. Canziani, A. Paszke, and E. Culurciello, “An Analysis of Deep Neural Network Models for Practical Applications,” arXiv:1605.07678, 2016
-
[5]
Available: https://docs.pytorch.org/vision/main/models/resnet.html
PyTorch Contributors,TorchVision ResNet Documentation. Available: https://docs.pytorch.org/vision/main/models/resnet.html
-
[6]
The Datacenter as a Computer,
L. Barroso, J. Clidaras, and U. Holzle, “The Datacenter as a Computer,” Morgan & Claypool, 2013
2013
-
[7]
In-Datacenter Performance Analysis of a Tensor Processing Unit,
N. Jouppi et al., “In-Datacenter Performance Analysis of a Tensor Processing Unit,” ISCA, 2017
2017
-
[8]
Mixed precision training,
P. Micikevicius et al., “Mixed precision training,” ICLR, 2018
2018
-
[9]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob et al., “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” CVPR, 2018
2018
-
[10]
Quantizing deep convolutional networks for efficient inference: A whitepaper
R. Krishnamoorthi, “Quantizing deep convolutional networks for effi- cient inference,” arXiv:1806.08342, 2018
-
[11]
Available: https://docs.nvidia.com/deeplearning/tensorrt/latest/index.html
NVIDIA Corporation,NVIDIA TensorRT Documentation. Available: https://docs.nvidia.com/deeplearning/tensorrt/latest/index.html
-
[12]
Available: https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt- 861/developer-guide/index.html
NVIDIA Corporation,NVIDIA TensorRT Developer Guide. Available: https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt- 861/developer-guide/index.html
-
[13]
NVIDIA Corporation,NVIDIA Turing GPU Architecture Whitepaper, 2018
2018
-
[14]
NVIDIA Corporation,NVIDIA Ampere Architecture Whitepaper, 2020
2020
-
[15]
NVIDIA Corporation,NVIDIA Ada GPU Architecture Whitepaper, 2022
2022
-
[16]
NVIDIA Corporation,NVIDIA T4 Tensor Core GPU Datasheet, 2018
2018
-
[17]
NVIDIA Corporation,NVIDIA L4 Tensor Core GPU Datasheet, 2023
2023
-
[18]
MLPerf Inference Benchmark,
V . J. Reddi et al., “MLPerf Inference Benchmark,” ISCA, 2020
2020
-
[19]
The Tail at Scale,
J. Dean and L. Barroso, “The Tail at Scale,” Communications of the ACM, 2013
2013
-
[20]
Roofline: An insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: An insightful visual performance model for multicore architectures,” Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009
2009
-
[21]
Better performance at lower occupancy,
V . V olkov, “Better performance at lower occupancy,” Proceedings of GPU Technology Conference (GTC), 2010
2010
-
[22]
Analysis of Large-Scale Multi-Tenant GPU Clusters for DNN Training Workloads,
M. Jeon et al., “Analysis of Large-Scale Multi-Tenant GPU Clusters for DNN Training Workloads,” USENIX ATC, 2019
2019
-
[23]
Improving Reproducibility in Machine Learning Research,
J. Pineau et al., “Improving Reproducibility in Machine Learning Research,” JMLR, 2021
2021
-
[24]
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding,
S. Han, H. Mao, and W. Dally, “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding,” ICLR, 2016
2016
-
[25]
GPUSync: A Framework for Real-Time GPU Manage- ment,
Y . Kang et al., “GPUSync: A Framework for Real-Time GPU Manage- ment,” IEEE RTSS, 2017
2017
-
[26]
Achieving Rapid Response Times in Large Online Services,
J. Dean, “Achieving Rapid Response Times in Large Online Services,” ACM Queue, 2013
2013
-
[27]
Attention Is All You Need,
A. Vaswani et al., “Attention Is All You Need,” NeurIPS, 2017
2017
-
[28]
GDEV-AI: A Generalized Evaluation of Deep Learning Inference Scaling and Architectural Saturation,
K. Palaniappan, “GDEV-AI: A Generalized Evaluation of Deep Learning Inference Scaling and Architectural Saturation,” arXiv preprint, 2026
2026
-
[29]
DEEP-GAP GPU Inference Benchmark,
K. Palaniappan, “DEEP-GAP GPU Inference Benchmark,” GitHub repository, 2026. Available: https://github.com/kpalania1/deep-gap-gpu- inference-benchmark
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.