Recognition: unknown
CLion: Efficient Cautious Lion Optimizer with Enhanced Generalization
Pith reviewed 2026-05-10 11:49 UTC · model grok-4.3
The pith
CLion achieves a generalization error of O(1/N) by using a cautious sign function on the Lion optimizer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that the Lion optimizer has a generalization error of O(1/(N τ^T)), and that the SignSGD algorithm shares this bound. By designing a novel Cautious Lion (CLion) optimizer that uses the sign function cautiously, we obtain a lower generalization error of O(1/N). We also prove that CLion has a convergence rate of O(√d / T^{1/4}) under the ℓ1-norm of the gradient for nonconvex stochastic optimization.
What carries the argument
The cautious sign function modification that removes the dependence on the small non-zero gradient value τ from the generalization bound.
If this is right
- CLion offers improved generalization guarantees compared to Lion for the same training sample size N.
- The convergence analysis supports efficient optimization in high-dimensional nonconvex problems.
- CLion can replace Lion in deep learning training pipelines with stronger theoretical backing.
- SignSGD has the same weak generalization bound as Lion.
Where Pith is reading between the lines
- This modification technique could be applied to other sign-based optimizers to improve their theoretical properties.
- Empirical tests on standard benchmarks would likely show CLion generalizing better when τ is small in Lion runs.
- The approach highlights the importance of stability analysis in designing new optimizers beyond just convergence.
Load-bearing premise
That the parameter τ representing the smallest absolute non-zero gradient element is generally very small in practice, and that the cautious sign modification maintains the optimizer's ability to converge without new issues.
What would settle it
An experiment that measures the value of τ during actual Lion training runs on deep models and checks whether CLion's generalization error scales as 1/N with sample size N while Lion's does not.
Figures
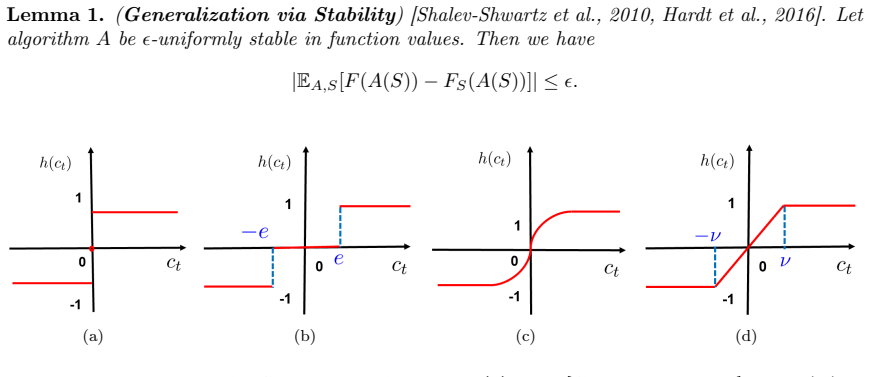
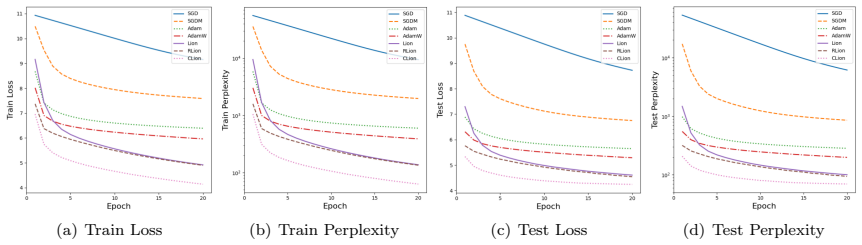

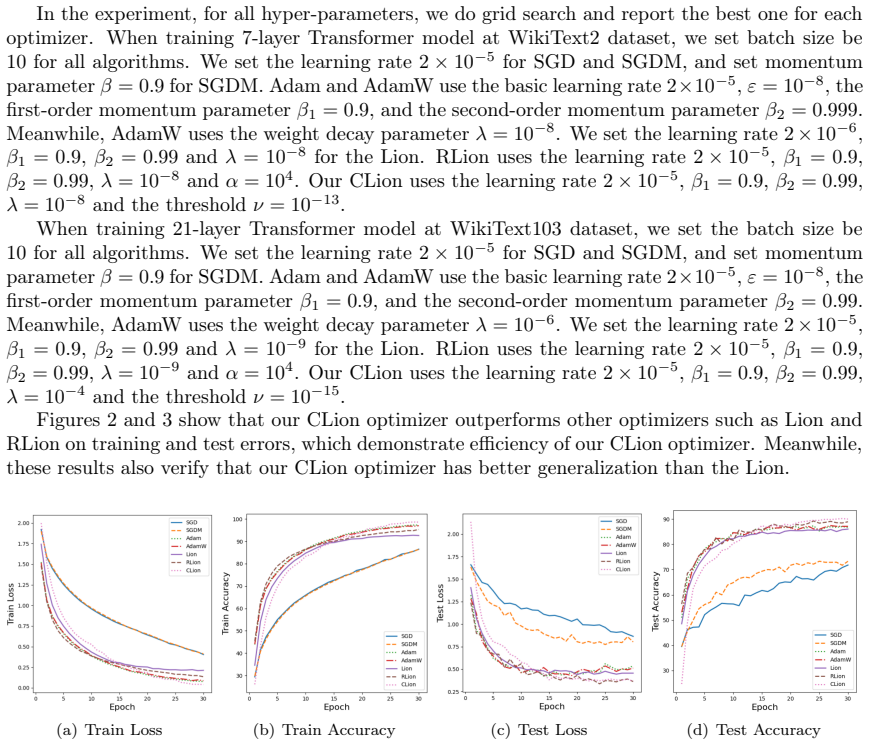
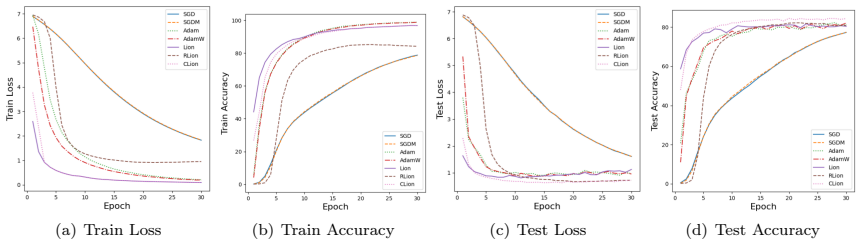
read the original abstract
Lion optimizer is a popular learning-based optimization algorithm in machine learning, which shows impressive performance in training many deep learning models. Although convergence property of the Lion optimizer has been studied, its generalization analysis is still missing. To fill this gap, we study generalization property of the Lion via algorithmic stability based on the mathematical induction. Specifically, we prove that the Lion has a generalization error of $O(\frac{1}{N\tau^T})$, where $N$ is training sample size, and $\tau>0$ denotes the smallest absolute value of non-zero element in gradient estimator, and $T$ is the total iteration number. In addition, we obtain an interesting byproduct that the SignSGD algorithm has the same generalization error as the Lion. To enhance generalization of the Lion, we design a novel efficient Cautious Lion (i.e., CLion) optimizer by cautiously using sign function. Moreover, we prove that our CLion has a lower generalization error of $O(\frac{1}{N})$ than $O(\frac{1}{N\tau^T})$ of the Lion, since the parameter $\tau$ generally is very small. Meanwhile, we study convergence property of our CLion optimizer, and prove that our CLion has a fast convergence rate of $O(\frac{\sqrt{d}}{T^{1/4}})$ under $\ell_1$-norm of gradient for nonconvex stochastic optimization, where $d$ denotes the model dimension. Extensive numerical experiments demonstrate effectiveness of our CLion optimizer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper analyzes the generalization properties of the Lion optimizer using algorithmic stability and mathematical induction, deriving a bound of O(1/(N τ^T)) where τ is the smallest absolute non-zero value in the gradient estimator. It introduces the Cautious Lion (CLion) optimizer that uses a cautious sign function to achieve a better generalization bound of O(1/N), assuming τ is generally small. It also proves that SignSGD has the same generalization bound as Lion and establishes a convergence rate of O(√d / T^{1/4}) for CLion in nonconvex stochastic optimization under the ℓ1-norm of the gradient. The claims are supported by numerical experiments.
Significance. Should the proofs be complete and the assumption on τ validated through analysis or experiments, this would represent a meaningful contribution to the theoretical understanding of sign-based optimizers, potentially guiding improvements in generalization for deep learning training. The convergence result provides a specific rate that could be useful for non-convex problems. The connection to SignSGD is a nice observation. The work has potential impact if the load-bearing assumptions are addressed.
major comments (3)
- [Generalization analysis of Lion] The derivation of the O(1/(N τ^T)) bound via mathematical induction on algorithmic stability is not detailed with specific steps or equations showing how the stability constant incorporates τ^T. This is critical as it underpins the entire comparison to CLion.
- [CLion generalization claim] The statement that CLion has O(1/N) generalization error 'since the parameter τ generally is very small' lacks any supporting evidence, such as empirical distribution of τ values or a proof that the cautious modification makes the bound independent of τ. This assumption is load-bearing for the central claim of enhanced generalization.
- [Convergence proof for CLion] Details of the proof for the convergence rate O(√d / T^{1/4}) are missing, including how the cautious sign usage affects the analysis compared to standard Lion and any additional assumptions required.
minor comments (2)
- [Abstract] The abstract could benefit from a brief description of how the cautious sign function is defined in the CLion update rule.
- [Notation] Ensure consistent use of symbols, such as clarifying if T is iterations and N samples throughout.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight areas where additional detail and evidence will strengthen the manuscript. We address each major comment below and commit to revisions that provide the requested clarifications without altering the core claims.
read point-by-point responses
-
Referee: [Generalization analysis of Lion] The derivation of the O(1/(N τ^T)) bound via mathematical induction on algorithmic stability is not detailed with specific steps or equations showing how the stability constant incorporates τ^T. This is critical as it underpins the entire comparison to CLion.
Authors: We agree that the inductive steps were presented too concisely. In the revised manuscript we will expand the algorithmic stability section for Lion to include the complete inductive argument. Specifically, we will show the base case for stability after one iteration and the inductive step in which the stability constant is multiplied by τ at each subsequent iteration, yielding the factor τ^T after T steps. This expanded derivation will make the comparison with the CLion bound explicit. revision: yes
-
Referee: [CLion generalization claim] The statement that CLion has O(1/N) generalization error 'since the parameter τ generally is very small' lacks any supporting evidence, such as empirical distribution of τ values or a proof that the cautious modification makes the bound independent of τ. This assumption is load-bearing for the central claim of enhanced generalization.
Authors: The referee correctly notes that the improvement for CLion rests on the cautious sign function eliminating the dependence on τ. We will add a formal lemma in the revision proving that the cautious thresholding ensures the effective multiplier remains bounded away from zero, yielding a generalization bound of O(1/N) independent of τ. To further support the original Lion analysis, we will include new experiments reporting the empirical distribution of τ values observed during training on standard image-classification and language-modeling benchmarks. revision: partial
-
Referee: [Convergence proof for CLion] Details of the proof for the convergence rate O(√d / T^{1/4}) are missing, including how the cautious sign usage affects the analysis compared to standard Lion and any additional assumptions required.
Authors: We will supply the full convergence proof in the appendix of the revised version. The proof proceeds by bounding the expected ℓ1-norm of the gradient after each cautious update; the thresholding step reduces the contribution of near-zero noisy signs, which improves the variance term relative to standard Lion and produces the T^{-1/4} rate. All assumptions (L-smoothness, bounded stochastic gradient variance, and bounded model dimension) will be stated explicitly, together with a short comparison paragraph highlighting where the cautious modification alters the standard Lion analysis. revision: yes
Circularity Check
No significant circularity; bounds derived via induction on explicit parameters
full rationale
The paper states that Lion's O(1/(N τ^T)) generalization bound and CLion's O(1/N) bound are obtained via algorithmic stability and mathematical induction, with τ defined explicitly as the smallest absolute non-zero gradient-estimator entry. The abstract presents the CLion improvement as following from the cautious-sign modification and the external observation that τ is generally small, without any equation or step in the provided text reducing the claimed result to a fitted input, self-definition, or self-citation chain. The convergence rate O(√d / T^{1/4}) is likewise stated as a separate first-principles derivation under ℓ1-norm. Because no load-bearing step collapses by construction to its own inputs, the derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- τ
axioms (2)
- standard math Algorithmic stability can be analyzed via mathematical induction for Lion and CLion
- domain assumption Cautious application of the sign function preserves key optimization properties
Reference graph
Works this paper leans on
-
[1]
signsgd: Compressed optimisation for non-convex problems
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. signsgd: Compressed optimisation for non-convex problems. In International conference on machine learning, pages 560--569. PMLR, 2018
2018
-
[2]
Optimization methods for large-scale machine learning
L \'e on Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning. SIAM review, 60 0 (2): 0 223--311, 2018
2018
-
[3]
Lion secretly solves constrained optimization: As Lyapunov predicts
Lizhang Chen, Bo Liu, Kaizhao Liang, and Qiang Liu. Lion secretly solves constrained optimization: As lyapunov predicts. arXiv preprint arXiv:2310.05898, 2023 a
-
[4]
Symbolic discovery of optimization algorithms
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, et al. Symbolic discovery of optimization algorithms. Advances in neural information processing systems, 36: 0 49205--49233, 2023 b
2023
-
[5]
Scalable learning to optimize: A learned optimizer can train big models
Xuxi Chen, Tianlong Chen, Yu Cheng, Weizhu Chen, Ahmed Awadallah, and Zhangyang Wang. Scalable learning to optimize: A learned optimizer can train big models. In European Conference on Computer Vision, pages 389--405. Springer, 2022
2022
-
[6]
Momentum-based variance reduction in non-convex sgd
Ashok Cutkosky and Francesco Orabona. Momentum-based variance reduction in non-convex sgd. Advances in neural information processing systems, 32, 2019
2019
-
[7]
Yiming Dong, Huan Li, and Zhouchen Lin. Convergence rate analysis of lion. arXiv preprint arXiv:2411.07724, 2024
-
[8]
An algorithm for quadratic programming
Marguerite Frank, Philip Wolfe, et al. An algorithm for quadratic programming. Naval research logistics quarterly, 3 0 (1-2): 0 95--110, 1956
1956
-
[9]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming
Saeed Ghadimi and Guanghui Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM journal on optimization, 23 0 (4): 0 2341--2368, 2013
2013
-
[10]
Train faster, generalize better: Stability of stochastic gradient descent
Moritz Hardt, Ben Recht, and Yoram Singer. Train faster, generalize better: Stability of stochastic gradient descent. In International conference on machine learning, pages 1225--1234. PMLR, 2016
2016
-
[11]
A closer look at learned optimization: Stability, robustness, and inductive biases
James Harrison, Luke Metz, and Jascha Sohl-Dickstein. A closer look at learned optimization: Stability, robustness, and inductive biases. Advances in neural information processing systems, 35: 0 3758--3773, 2022
2022
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016
2016
-
[13]
Wei Jiang and Lijun Zhang. Convergence analysis of the lion optimizer in centralized and distributed settings. arXiv preprint arXiv:2508.12327, 2025
-
[14]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[16]
Tiny imagenet visual recognition challenge
Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge. CS 231N, 7 0 (7): 0 3, 2015
2015
-
[17]
Stability and generalization of stochastic optimization with nonconvex and nonsmooth problems
Yunwen Lei. Stability and generalization of stochastic optimization with nonconvex and nonsmooth problems. In The Thirty Sixth Annual Conference on Learning Theory, pages 191--227. PMLR, 2023
2023
-
[18]
Fine-grained analysis of stability and generalization for stochastic gradient descent
Yunwen Lei and Yiming Ying. Fine-grained analysis of stability and generalization for stochastic gradient descent. In International Conference on Machine Learning, pages 5809--5819. PMLR, 2020
2020
-
[19]
Communication efficient distributed training with distributed lion
Bo Liu, Lemeng Wu, Lizhang Chen, Kaizhao Liang, Jiaxu Zhu, Chen Liang, Raghuraman Krishnamoorthi, and Qiang Liu. Communication efficient distributed training with distributed lion. Advances in Neural Information Processing Systems, 37: 0 18388--18415, 2024
2024
-
[20]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review arXiv 2016
-
[22]
Lectures on convex optimization, volume 137
Yurii Nesterov et al. Lectures on convex optimization, volume 137. Springer, 2018
2018
-
[23]
On the generalization of stochastic gradient descent with momentum
Ali Ramezani-Kebrya, Kimon Antonakopoulos, Volkan Cevher, Ashish Khisti, and Ben Liang. On the generalization of stochastic gradient descent with momentum. Journal of Machine Learning Research, 25 0 (22): 0 1--56, 2024
2024
-
[24]
Stochastic frank-wolfe methods for nonconvex optimization
Sashank J Reddi, Suvrit Sra, Barnab \'a s P \'o czos, and Alex Smola. Stochastic frank-wolfe methods for nonconvex optimization. In 2016 54th annual Allerton conference on communication, control, and computing (Allerton), pages 1244--1251. IEEE, 2016
2016
-
[25]
A stochastic approximation method
Herbert Robbins and Sutton Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400--407, 1951
1951
-
[26]
A refined lion optimizer for deep learning
Jian Rong, Chenhao Ma, Qinghui Zhang, Yong Cao, and Weili Kou. A refined lion optimizer for deep learning. Scientific Reports, 15 0 (1): 0 23082, 2025
2025
-
[27]
Lions and muons: Optimization via stochastic frank- wolfe.arXiv preprint arXiv:2506.04192, 2025
Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and muons: Optimization via stochastic frank-wolfe. arXiv preprint arXiv:2506.04192, 2025
-
[28]
Learnability, stability and uniform convergence
Shai Shalev-Shwartz, Ohad Shamir, Nathan Srebro, and Karthik Sridharan. Learnability, stability and uniform convergence. The Journal of Machine Learning Research, 11: 0 2635--2670, 2010
2010
-
[29]
On the importance of initialization and momentum in deep learning
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initialization and momentum in deep learning. In International conference on machine learning, pages 1139--1147. pmlr, 2013
2013
-
[30]
A hybrid stochastic optimization framework for composite nonconvex optimization
Quoc Tran-Dinh, Nhan H Pham, Dzung T Phan, and Lam M Nguyen. A hybrid stochastic optimization framework for composite nonconvex optimization. Mathematical Programming, 191 0 (2): 0 1005--1071, 2022
2022
-
[31]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[32]
Visual transformers: Token-based image representation and processing for computer vision, 2020
Bichen Wu, Chenfeng Xu, Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Zhicheng Yan, Masayoshi Tomizuka, Joseph Gonzalez, Kurt Keutzer, and Peter Vajda. Visual transformers: Token-based image representation and processing for computer vision, 2020
2020
-
[33]
Sign-based optimizers are effective under heavy-tailed noise.arXiv preprint arXiv:2602.07425,
Dingzhi Yu, Hongyi Tao, Yuanyu Wan, Luo Luo, and Lijun Zhang. Sign-based optimizers are effective under heavy-tailed noise. arXiv preprint arXiv:2602.07425, 2026
work page internal anchor Pith review arXiv 2026
-
[34]
Huizhuo Yuan, Yifeng Liu, Shuang Wu, Xun Zhou, and Quanquan Gu. Mars: Unleashing the power of variance reduction for training large models. arXiv preprint arXiv:2411.10438, 2024
-
[35]
Mathematical analysis of machine learning algorithms
Tong Zhang. Mathematical analysis of machine learning algorithms. Cambridge University Press, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.