Recognition: unknown
Towards Design Compositing
Pith reviewed 2026-05-10 11:41 UTC · model grok-4.3
The pith
Identity-preserving compositing is the missing step for harmonized graphic design pipelines from mismatched inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
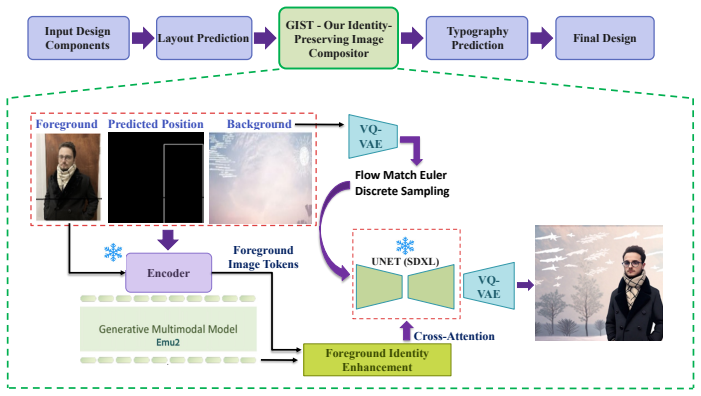
The authors argue that identity-preserving stylization and compositing of input elements is a critical missing ingredient for truly harmonized components-to-design pipelines. They present GIST, a training-free, identity-preserving image compositor that sits between layout prediction and typography generation and can be plugged into any existing components-to-design or design-refining pipeline without modification. Integration with LaDeCo and Design-o-meter yields significant improvements in visual harmony and aesthetic quality, as measured by LLaVA-OV and GPT-4V on aspect-wise ratings and pairwise preference over naive pasting.
What carries the argument
GIST, a training-free image compositor that applies identity-preserving stylization to blend disparate visual elements while retaining their original appearances.
If this is right
- GIST can be inserted into any existing layout or design-refinement pipeline without retraining or architectural changes.
- Naive pasting of mismatched elements can be replaced by stylistically harmonized composites that keep source identities intact.
- Visual harmony and aesthetic quality scores rise across different base methods when the compositor is added.
- The approach works with multimodal inputs including images, text, and logos collected from diverse sources.
Where Pith is reading between the lines
- If AI judges prove consistent with humans, GIST could become a standard post-processing stage in automated design tools.
- The method highlights a broader need for compositing stages in other creative pipelines where source assets arrive stylistically inconsistent.
- Future extensions might test whether the same training-free identity preservation works for video or 3D asset assembly.
Load-bearing premise
Evaluations by LLaVA-OV and GPT-4V on aspect-wise ratings and pairwise preferences reliably measure visual harmony and aesthetic quality without human validation or quantitative metrics.
What would settle it
A human preference study in which participants directly compare GIST-enhanced designs against naive-paste versions and rate harmony on the same aspects used by the vision-language models, then check whether model and human rankings align.
Figures





read the original abstract
Graphic design creation involves harmoniously assembling multimodal components such as images, text, logos, and other visual assets collected from diverse sources, into a visually-appealing and cohesive design. Recent methods have largely focused on layout prediction or complementary element generation, while retaining input elements exactly, implicitly assuming that provided components are already stylistically harmonious. In practice, inputs often come from disparate sources and exhibit visual mismatch, making this assumption limiting. We argue that identity-preserving stylization and compositing of input elements is a critical missing ingredient for truly harmonized components-to-design pipelines. To this end, we propose GIST, a training-free, identity-preserving image compositor that sits between layout prediction and typography generation, and can be plugged into any existing components-to-design or design-refining pipeline without modification. We demonstrate this by integrating GIST with two substantially different existing methods, LaDeCo and Design-o-meter. GIST shows significant improvements in visual harmony and aesthetic quality across both pipelines, as validated by LLaVA-OV and GPT-4V on aspect-wise ratings and pairwise preference over naive pasting. Project Page: abhinav-mahajan10.github.io/GIST/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing components-to-design pipelines assume stylistically harmonious inputs but often receive mismatched elements from disparate sources. It introduces GIST, a training-free, identity-preserving image compositor that can be inserted as a plug-in module between layout prediction and typography generation. Integration with LaDeCo and Design-o-meter is shown to produce significant gains in visual harmony and aesthetic quality, as measured by LLaVA-OV and GPT-4V via aspect-wise ratings and pairwise preferences over naive pasting.
Significance. If the improvements can be corroborated, GIST would supply a practical, modular solution for harmonizing mismatched visual assets in automated design workflows without retraining. The training-free design and seamless compatibility with prior pipelines are clear strengths that support broader applicability. The current evidence base, however, limits the assessed significance.
major comments (1)
- [Experiments / integration results] The central claim of significant improvements in visual harmony and aesthetic quality (abstract and integration results) is supported solely by aspect-wise ratings and pairwise preferences from LLaVA-OV and GPT-4V. No human designer studies, correlation coefficients with human judgments, error bars, or objective proxies (e.g., perceptual metrics or alignment scores) are reported. This evaluation choice is load-bearing for the effectiveness demonstration and leaves the gains vulnerable to VLM-specific biases.
minor comments (1)
- [Abstract] The project page URL is provided in the abstract; confirming whether it hosts code, additional qualitative examples, or failure cases would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the opportunity to clarify our evaluation approach. We address the major comment below.
read point-by-point responses
-
Referee: [Experiments / integration results] The central claim of significant improvements in visual harmony and aesthetic quality (abstract and integration results) is supported solely by aspect-wise ratings and pairwise preferences from LLaVA-OV and GPT-4V. No human designer studies, correlation coefficients with human judgments, error bars, or objective proxies (e.g., perceptual metrics or alignment scores) are reported. This evaluation choice is load-bearing for the effectiveness demonstration and leaves the gains vulnerable to VLM-specific biases.
Authors: We agree that human designer studies would provide stronger corroboration and that the current reliance on VLMs introduces a risk of model-specific biases. Our choice of LLaVA-OV and GPT-4V was motivated by their demonstrated alignment with human aesthetic judgments in recent vision-language literature and by the practical constraints of scaling human evaluations for a training-free plug-in module. We used two independent VLMs and two complementary protocols (aspect-wise ratings plus pairwise preferences) to reduce single-model bias. No correlation coefficients or objective proxies were included because standard perceptual metrics such as LPIPS or SSIM primarily capture content fidelity rather than stylistic harmony in composite designs; we judged them unsuitable. Error bars were omitted because VLM outputs are deterministic for fixed prompts, though we can readily add variance estimates from prompt paraphrases. In a revised manuscript we will expand the limitations section to explicitly discuss these points and the value of future human validation. revision: partial
Circularity Check
No significant circularity; GIST presented as independent training-free plug-in
full rationale
The paper proposes GIST as a training-free identity-preserving compositor that integrates into existing pipelines (LaDeCo, Design-o-meter) without modification. No equations, derivations, fitted parameters, or self-citations are load-bearing in the provided text. The method is explicitly positioned as an add-on component rather than a closed-form result derived from its own outputs. Evaluations rely on external LLM judges (LLaVA-OV, GPT-4V) for ratings, which does not reduce any claim to a self-referential fit or definition. This is a standard non-circular method paper with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Michael Bauerly and Yili Liu. Computational modeling and experimental investigation of effects of compositional ele- ments on interface and design aesthetics.International jour- nal of human-computer studies, 64(8):670–682, 2006. 2
2006
-
[4]
Docsynthv2: A practical autoregressive modeling for document generation
Sanket Biswas, Rajiv Jain, Vlad I Morariu, Jiuxiang Gu, Puneet Mathur, Curtis Wigington, Tong Sun, and Josep Llad´os. Docsynthv2: A practical autoregressive modeling for document generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8148–8153, 2024. 2
2024
-
[5]
FLUX.1 Kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. FLUX.1 Kontext: Flow matching for in-context i...
-
[6]
Two-stage content-aware layout generation for poster designs
Shang Chai, Liansheng Zhuang, Fengying Yan, and Zihan Zhou. Two-stage content-aware layout generation for poster designs. InProceedings of the 31st ACM International Con- ference on Multimedia, pages 8415–8423, 2023. 2
2023
-
[7]
Towards aligned lay- out generation via diffusion model with aesthetic constraints
Jian Chen, Ruiyi Zhang, Yufan Zhou, Rajiv Jain, Zhiqiang Xu, Ryan Rossi, and Changyou Chen. Towards aligned lay- out generation via diffusion model with aesthetic constraints. arXiv preprint arXiv:2402.04754, 2024. 2
-
[8]
Anydoor: Zero-shot object-level im- age customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level im- age customization. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6593–6602, 2024. 6, 8
2024
-
[9]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review arXiv
-
[10]
Graphic design with large multimodal model.arXiv preprint arXiv:2404.14368, 2024
Yutao Cheng, Zhao Zhang, Maoke Yang, Hui Nie, Chunyuan Li, Xinglong Wu, and Jie Shao. Graphic design with large multimodal model.arXiv preprint arXiv:2404.14368, 2024. 2, 6
-
[11]
A fast elitist non-dominated sorting genetic al- gorithm for multi-objective optimization: Nsga-ii
Kalyanmoy Deb, Samir Agrawal, Amrit Pratap, and Tanaka Meyarivan. A fast elitist non-dominated sorting genetic al- gorithm for multi-objective optimization: Nsga-ii. InParal- lel Problem Solving from Nature PPSN VI: 6th International Conference Paris, France, September 18–20, 2000 Proceed- ings 6, pages 849–858. Springer, 2000. 5
2000
-
[12]
Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, et al. Internlm-xcomposer2: Mastering free-form text-image composition and compre- hension in vision-language large model.arXiv preprint arXiv:2401.16420, 2024. 5
-
[13]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learn- ing, 2024. 4
2024
-
[14]
Decom- posing a scene into geometric and semantically consistent re- gions
Stephen Gould, Richard Fulton, and Daphne Koller. Decom- posing a scene into geometric and semantically consistent re- gions. In2009 IEEE 12th International Conference on Com- puter Vision, pages 1–8, 2009. 8
2009
-
[15]
Sahil Goyal, Abhinav Mahajan, Swasti Mishra, Prateksha Udhayanan, Tripti Shukla, KJ Joseph, and Balaji Vasan Srinivasan. Design-o-meter: Towards evaluating and refin- ing graphic designs.arXiv preprint arXiv:2411.14959, 2024. 1, 2, 3, 5, 6
-
[16]
Layoutflow: Flow matching for layout generation.arXiv preprint arXiv:2403.18187, 2024
Julian Jorge Andrade Guerreiro, Naoto Inoue, Kento Ma- sui, Mayu Otani, and Hideki Nakayama. Layoutflow: Flow matching for layout generation.arXiv preprint arXiv:2403.18187, 2024. 2
-
[17]
Layout- transformer: Layout generation and completion with self- attention
Kamal Gupta, Justin Lazarow, Alessandro Achille, Larry S Davis, Vijay Mahadevan, and Abhinav Shrivastava. Layout- transformer: Layout generation and completion with self- attention. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1004–1014, 2021. 2
2021
-
[18]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 4
work page internal anchor Pith review arXiv 2022
-
[19]
Dreamposter: A unified framework for image-conditioned generative poster design
Xiwei Hu, Haokun Chen, Zhongqi Qi, Hui Zhang, Dexiang Hong, Jie Shao, and Xinglong Wu. DreamPoster: A unified framework for image-conditioned generative poster design. arXiv preprint arXiv:2507.04218, 2025. 3
-
[20]
Unifying layout generation with a decoupled diffusion model
Mude Hui, Zhizheng Zhang, Xiaoyi Zhang, Wenxuan Xie, Yuwang Wang, and Yan Lu. Unifying layout generation with a decoupled diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1942–1951, 2023. 2
1942
-
[21]
Review of auto- matic document formatting
Nathan Hurst, Wilmot Li, and Kim Marriott. Review of auto- matic document formatting. InProceedings of the 9th ACM symposium on Document engineering, pages 99–108, 2009. 2
2009
-
[22]
Towards flexible multi-modal document models, 2023
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, and Kota Yamaguchi. Towards flexible multi-modal document models, 2023. 2, 3, 6
2023
-
[23]
Layoutdm: Discrete diffusion model for controllable layout generation
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, and Kota Yamaguchi. Layoutdm: Discrete diffusion model for controllable layout generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10167–10176, 2023. 2
2023
- [24]
-
[25]
Recommendation system for automatic design of magazine covers
Ali Jahanian, Jerry Liu, Qian Lin, Daniel Tretter, Eamonn O’Brien-Strain, Seungyon Claire Lee, Nic Lyons, and Jan Allebach. Recommendation system for automatic design of magazine covers. InProceedings of the 2013 interna- tional conference on Intelligent user interfaces, pages 95– 106, 2013. 2
2013
-
[26]
COLE: A hierarchical generation framework for graphic design.arXiv preprint arXiv:2311.16974,
Peidong Jia, Chenxuan Li, Zeyu Liu, Yichao Shen, Xingru Chen, Yuhui Yuan, Yinglin Zheng, Dong Chen, Ji Li, Xi- aodong Xie, et al. Cole: A hierarchical generation frame- work for graphic design.arXiv preprint arXiv:2311.16974,
-
[27]
Pnp inversion: Boosting diffusion-based editing with 3 lines of code
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Pnp inversion: Boosting diffusion-based editing with 3 lines of code. InThe Twelfth International Conference on Learning Representations, 2023. 4
2023
-
[28]
Kotaro Kikuchi, Naoto Inoue, Mayu Otani, Edgar Simo- Serra, and Kota Yamaguchi. Multimodal markup docu- ment models for graphic design completion.arXiv preprint arXiv:2409.19051, 2024. 2
-
[29]
Aesthetics++: Refining graphic designs by exploring design principles and human preference.IEEE Transactions on Visualization and Computer Graphics, 29(6):3093–3104,
Wenyuan Kong, Zhaoyun Jiang, Shizhao Sun, Zhuoning Guo, Weiwei Cui, Ting Liu, Jianguang Lou, and Dongmei Zhang. Aesthetics++: Refining graphic designs by exploring design principles and human preference.IEEE Transactions on Visualization and Computer Graphics, 29(6):3093–3104,
-
[30]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[31]
Dreamedit: Subject-driven image editing, 2023
Tianle Li, Max Ku, Cong Wei, and Wenhu Chen. Dreamedit: Subject-driven image editing, 2023. 8
2023
-
[32]
Layoutprompter: Awaken the design ability of large language models.Advances in Neural Information Processing Systems, 36, 2024
Jiawei Lin, Jiaqi Guo, Shizhao Sun, Zijiang Yang, Jian- Guang Lou, and Dongmei Zhang. Layoutprompter: Awaken the design ability of large language models.Advances in Neural Information Processing Systems, 36, 2024. 2
2024
-
[33]
From elements to design: A layered ap- proach for automatic graphic design composition, 2024
Jiawei Lin, Shizhao Sun, Danqing Huang, Ting Liu, Ji Li, and Jiang Bian. From elements to design: A layered ap- proach for automatic graphic design composition, 2024. 1, 2, 3, 5, 6
2024
-
[34]
Towards understanding cross and self-attention in stable diffusion for text-guided image editing
Bingyan Liu, Chengyu Wang, Tingfeng Cao, Kui Jia, and Jun Huang. Towards understanding cross and self-attention in stable diffusion for text-guided image editing. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7817–7826, 2024. 4
2024
-
[35]
Deep learning face attributes in the wild, 2015
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild, 2015. 8
2015
-
[36]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high- resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023. 5
work page internal anchor Pith review arXiv 2023
-
[37]
Null-text inversion for editing real im- ages using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real im- ages using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023. 4
2023
-
[38]
Designscape: Design with interactive layout suggestions
Peter O’Donovan, Aseem Agarwala, and Aaron Hertzmann. Designscape: Design with interactive layout suggestions. In Proceedings of the 33rd annual ACM conference on human factors in computing systems, pages 1221–1224, 2015. 2
2015
-
[39]
Learning layouts for single-pagegraphic designs.IEEE transactions on visualization and computer graphics, 20(8): 1200–1213, 2014
Peter O’Donovan, Aseem Agarwala, and Aaron Hertzmann. Learning layouts for single-pagegraphic designs.IEEE transactions on visualization and computer graphics, 20(8): 1200–1213, 2014. 2
2014
-
[40]
Sohan Patnaik, Rishabh Jain, Balaji Krishnamurthy, and Mausoom Sarkar. Aesthetiq: Enhancing graphic lay- out design via aesthetic-aware preference alignment of multi-modal large language models.arXiv preprint arXiv:2503.00591, 2025. 2
-
[41]
IGD: In- structional graphic design with multimodal layer generation
Yadong Qu, Shancheng Fang, Yuxin Wang, Xiaorui Wang, Zhineng Chen, Hongtao Xie, and Yongdong Zhang. IGD: In- structional graphic design with multimodal layer generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 3
2025
-
[42]
Jaejung Seol, Seojun Kim, and Jaejun Yoo. Posterllama: Bridging design ability of langauge model to contents-aware layout generation.arXiv preprint arXiv:2404.00995, 2024. 2
-
[43]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[44]
Generative multimodal mod- els are in-context learners
Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiy- ing Yu, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative multimodal mod- els are in-context learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14398–14409, 2024. 4, 8
2024
-
[45]
Zecheng Tang, Chenfei Wu, Juntao Li, and Nan Duan. Lay- outnuwa: Revealing the hidden layout expertise of large lan- guage models.arXiv preprint arXiv:2309.09506, 2023. 2
-
[46]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023. 4
1921
-
[47]
Edict: Exact diffusion inversion via coupled transformations
Bram Wallace, Akash Gokul, and Nikhil Naik. Edict: Exact diffusion inversion via coupled transformations. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22532–22541, 2023. 4
2023
-
[48]
Canvasemb: Learning layout representation with large- scale pre-training for graphic design
Yuxi Xie, Danqing Huang, Jinpeng Wang, and Chin-Yew Lin. Canvasemb: Learning layout representation with large- scale pre-training for graphic design. InProceedings of the 29th ACM international conference on multimedia, pages 4100–4108, 2021. 2
2021
-
[49]
Canvasvae: Learning to generate vector graphic documents
Kota Yamaguchi. Canvasvae: Learning to generate vector graphic documents. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 5481–5489,
-
[50]
Automatic generation of visual-textual presen- tation layout.ACM Transactions on Multimedia Comput- ing, Communications, and Applications (TOMM), 12(2):1– 22, 2016
Xuyong Yang, Tao Mei, Ying-Qing Xu, Yong Rui, and Shipeng Li. Automatic generation of visual-textual presen- tation layout.ACM Transactions on Multimedia Comput- ing, Communications, and Applications (TOMM), 12(2):1– 22, 2016. 2
2016
-
[51]
arXiv preprint arXiv:2505.19114 (2025)
Hui Zhang, Dexiang Hong, Maoke Yang, Yutao Cheng, Zhao Zhang, Jie Shao, Xinglong Wu, Zuxuan Wu, and Yu- Gang Jiang. Creatidesign: A unified multi-conditional diffu- sion transformer for creative graphic design.arXiv preprint arXiv:2505.19114, 2025. 2, 3
-
[52]
Layoutdiffusion: Controllable diffu- sion model for layout-to-image generation
Guangcong Zheng, Xianpan Zhou, Xuewei Li, Zhongang Qi, Ying Shan, and Xi Li. Layoutdiffusion: Controllable diffu- sion model for layout-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 22490–22499, 2023. 2
2023
-
[53]
Automatic layout planning for visually-rich documents with instruction-following models
Wanrong Zhu, Jennifer Healey, Ruiyi Zhang, William Yang Wang, and Tong Sun. Automatic layout planning for visually-rich documents with instruction-following models. arXiv preprint arXiv:2404.15271, 2024. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.