Recognition: unknown
Targeted Exploration via Unified Entropy Control for Reinforcement Learning
Pith reviewed 2026-05-10 10:45 UTC · model grok-4.3
The pith
Unified entropy control lets RL training explore harder reasoning prompts while keeping the policy stable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
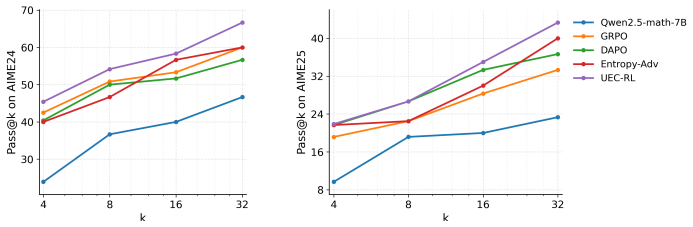
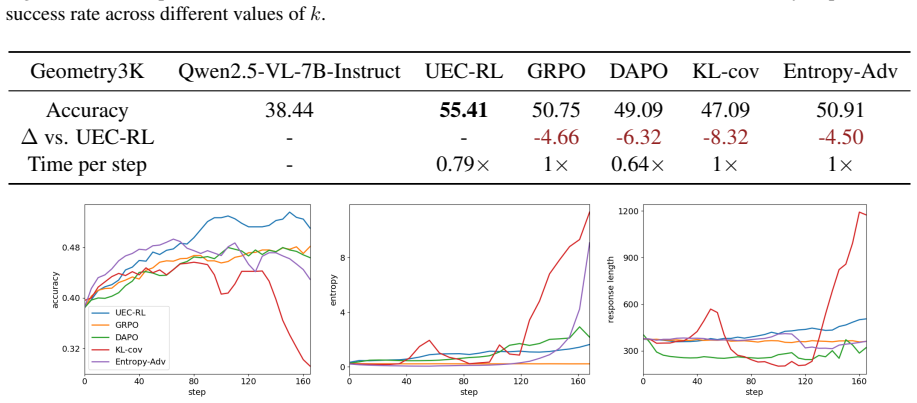
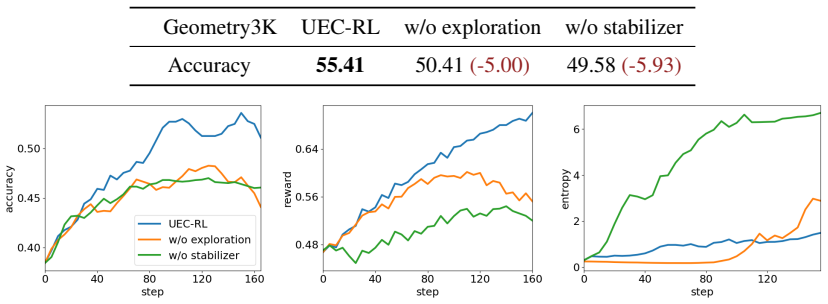
UEC-RL activates more exploration on difficult prompts to search for potential and valuable reasoning trajectories. In parallel, a stabilizer prevents entropy from growing uncontrollably, thereby keeping training stable as the model consolidates reliable behaviors. Together these components expand the search space when needed while maintaining robust optimization throughout training. Experiments on both LLM and VLM reasoning tasks show consistent gains over RL baselines on both Pass@1 and Pass@k, including a 37.9% relative improvement over GRPO on Geometry3K.
What carries the argument
Unified Entropy Control (UEC) that applies prompt-dependent exploration increases on hard examples together with an entropy stabilizer that bounds growth to preserve optimization stability.
If this is right
- Consistent accuracy gains appear on both Pass@1 and Pass@k across LLM and VLM reasoning benchmarks.
- The 37.9% relative improvement over GRPO on Geometry3K demonstrates sustained exploration without loss of convergence.
- Training remains stable while the policy searches a wider space of reasoning trajectories on difficult inputs.
- The approach supports scaling RL-based reasoning methods to larger models without premature entropy collapse.
Where Pith is reading between the lines
- The same entropy-control pattern could be tested on non-reasoning RL domains such as game playing or robotics where diversity loss is also common.
- If the stabilizer works as described, it may reduce reliance on separate variance-reduction techniques that add bias.
- Models trained this way might produce more diverse final answers on open-ended questions even after convergence.
- The method could be combined with other policy-gradient variants to check whether the prompt-aware adjustment transfers.
Load-bearing premise
The reported gains come from the targeted exploration and stabilizer without introducing unmeasured bias or variance, and the entropy control works beyond the specific tasks and models tested.
What would settle it
Training identical models with and without the prompt-dependent exploration term on Geometry3K and finding that the 37.9% relative gain over GRPO disappears while entropy behavior remains unchanged.
Figures



read the original abstract
Recent advances in reinforcement learning (RL) have improved the reasoning capabilities of large language models (LLMs) and vision-language models (VLMs). However, the widely used Group Relative Policy Optimization (GRPO) consistently suffers from entropy collapse, causing the policy to converge prematurely and lose diversity. Existing exploration methods introduce additional bias or variance during exploration, making it difficult to maintain optimization stability. We propose Unified Entropy Control for Reinforcement Learning (UEC-RL), a framework that provides targeted mechanisms for exploration and stabilization. UEC-RL activates more exploration on difficult prompts to search for potential and valuable reasoning trajectories. In parallel, a stabilizer prevents entropy from growing uncontrollably, thereby keeping training stable as the model consolidates reliable behaviors. Together, these components expand the search space when needed while maintaining robust optimization throughout training. Experiments on both LLM and VLM reasoning tasks show consistent gains over RL baselines on both Pass@1 and Pass@$k$. On Geometry3K, UEC-RL achieves a 37.9\% relative improvement over GRPO, indicating that it sustains effective exploration without compromising convergence and underscoring UEC-RL as a key for scaling RL-based reasoning in large models. Our code is available at https://github.com/597358816/UEC-RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Unified Entropy Control for Reinforcement Learning (UEC-RL), a framework that activates targeted exploration on difficult prompts while using a stabilizer to prevent uncontrolled entropy growth during RL training of LLMs and VLMs. It claims this mitigates entropy collapse in the widely used GRPO algorithm, enabling better search for reasoning trajectories without sacrificing optimization stability. Experiments are reported to show consistent gains over RL baselines on Pass@1 and Pass@k metrics for both LLM and VLM reasoning tasks, with a specific 37.9% relative improvement over GRPO on the Geometry3K dataset.
Significance. If the gains prove robust, UEC-RL would offer a practical mechanism for balancing exploration and convergence in RL-based reasoning training, addressing a known limitation of GRPO that hinders scaling to larger models. The open-sourcing of code at the provided GitHub link is a clear strength that supports potential reproducibility and follow-up work.
major comments (2)
- [Experiments] Experiments section: The 37.9% relative improvement on Geometry3K is reported as a single point estimate with no accompanying standard deviation, number of independent runs/seeds, or statistical significance test. Given that GRPO-based RL on reasoning tasks exhibits high variance from token sampling, prompt ordering, and optimizer stochasticity, this leaves open whether the observed gain exceeds typical run-to-run noise and can be systematically attributed to the targeted exploration and stabilizer components rather than favorable stochastic effects.
- [Method] Method and Experiments sections: The abstract describes the targeted exploration and stabilizer mechanisms at a high level but provides no implementation details, pseudocode, hyperparameter settings, or ablation studies isolating each component's contribution. Without these, it is not possible to verify that the reported gains arise from the proposed unified entropy control rather than other unstated factors such as training schedule or model initialization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We appreciate the emphasis on experimental rigor and methodological transparency. Below we provide point-by-point responses to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The 37.9% relative improvement on Geometry3K is reported as a single point estimate with no accompanying standard deviation, number of independent runs/seeds, or statistical significance test. Given that GRPO-based RL on reasoning tasks exhibits high variance from token sampling, prompt ordering, and optimizer stochasticity, this leaves open whether the observed gain exceeds typical run-to-run noise and can be systematically attributed to the targeted exploration and stabilizer components rather than favorable stochastic effects.
Authors: We agree that single-run reporting is insufficient given the known stochasticity of GRPO-based RL. In the revised manuscript we will report results from multiple independent runs with different random seeds, including means and standard deviations for Pass@1 and Pass@k metrics on Geometry3K and other datasets. We will also add statistical significance tests (e.g., paired t-tests) to assess whether the observed gains are robust to run-to-run variation. revision: yes
-
Referee: [Method] Method and Experiments sections: The abstract describes the targeted exploration and stabilizer mechanisms at a high level but provides no implementation details, pseudocode, hyperparameter settings, or ablation studies isolating each component's contribution. Without these, it is not possible to verify that the reported gains arise from the proposed unified entropy control rather than other unstated factors such as training schedule or model initialization.
Authors: We acknowledge that additional implementation details are required for reproducibility and verification. The revised manuscript will include: (i) full pseudocode for the UEC-RL algorithm, (ii) complete hyperparameter tables for all experiments, (iii) explicit descriptions of how the targeted exploration and stabilizer are implemented, and (iv) ablation studies that isolate the contribution of each component while controlling for training schedule and initialization. These changes will be placed in the Method and Experiments sections. revision: yes
Circularity Check
No circularity: algorithmic framework with empirical validation
full rationale
The paper introduces UEC-RL as a practical RL framework combining targeted entropy-based exploration on difficult prompts with a stabilizer to prevent uncontrolled entropy growth. Claims rest on experimental comparisons to GRPO baselines across LLM/VLM reasoning tasks, including the reported 37.9% relative gain on Geometry3K. No first-principles derivation, mathematical prediction, or load-bearing self-citation chain is present; the method is defined directly by its algorithmic components and evaluated externally via benchmarks. No step reduces to a fitted parameter renamed as prediction or to a self-referential definition.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard reinforcement learning assumptions including policy gradient objectives and entropy regularization as used in GRPO.
Reference graph
Works this paper leans on
-
[1]
Finite-time analysis of the multiarmed ban- dit problem.Machine learning, 47(2):235–256. Jie Cao and Jing Xiao. 2022. An augmented benchmark dataset for geometric question answering through dual parallel text encoding. InProceedings of the 29th international conference on computational lin- guistics, pages 1511–1520. Jiaqi Chen, Jianheng Tang, Jinghui Qin...
-
[2]
Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
Reasoning with exploration: An entropy per- spective.arXiv preprint arXiv:2506.14758. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question an- swering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457. Karl Cobbe, Vineet Kosaraju, Mohammad Ba...
-
[3]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, and 1 others. 2025. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617. Team GLM, Aohan Zeng, B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Advancing language model reasoning through reinforcement learning and inference scaling.arXiv preprint arXiv:2501.11651. HuggingFaceH4. 2025. AIME 2024 Dataset (AIME I & II). Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, Ákos Kádár, Adam Trischler, and Yoshua Bengio. 2017. Figureqa: An annotated fig- ure dataset for visual reasoning.arXiv prepr...
-
[5]
In Computer Vision–ECCV 2016: 14th European Con- ference, Amsterdam, The Netherlands, October 11– 14, 2016, Proceedings, Part IV 14, pages 235–251
A diagram is worth a dozen images. In Computer Vision–ECCV 2016: 14th European Con- ference, Amsterdam, The Netherlands, October 11– 14, 2016, Proceedings, Part IV 14, pages 235–251. Springer. Daesik Kim, Seonhoon Kim, and Nojun Kwak
2016
-
[6]
Textbook question answering with multi- modal context graph understanding and self- supervised open-set comprehension.arXiv preprint arXiv:1811.00232. J Zico Kolter and Andrew Y Ng. 2009. Near-bayesian exploration in polynomial time. InProceedings of the 26th annual international conference on machine learning, pages 513–520. Nathan Lambert, Jacob Morriso...
-
[7]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Adam Dahlgren Lindström and Savitha Sam Abraham
work page internal anchor Pith review arXiv
-
[8]
Clevr-math: A dataset for compositional lan- guage, visual and mathematical reasoning
Clevr-math: A dataset for compositional lan- guage, visual and mathematical reasoning.arXiv preprint arXiv:2208.05358. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others
-
[9]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning.arXiv preprint arXiv:2304.08485. Jiacai Liu. 2025. How does rl pol- icy entropy converge during iteration? https://zhuanlan.zhihu.com/p/28476703733. Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun- yuan...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn
Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in Neural Information Processing Systems, 36:53728– 53741. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn
-
[11]
Equivalence between policy gradients and soft Q-learning
Direct preference optimization: Your language model is secretly a reward model.Advances in Neu- ral Information Processing Systems, 36. John Schulman, Xi Chen, and Pieter Abbeel. 2017a. Equivalence between policy gradients and soft q- learning.arXiv preprint arXiv:1704.06440. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2...
-
[12]
Ce-gppo: Coordinating entropy via gradient- preserving clipping policy optimization in reinforce- ment learning.arXiv preprint arXiv:2509.20712. Richard S Sutton, Andrew G Barto, and 1 others. 1998. Reinforcement learning: An introduction, volume 1. MIT press Cambridge. Hongze Tan and Jianfei Pan. 2025. Gtpo and grpo-s: Token and sequence-level reward sha...
work page internal anchor Pith review Pith/arXiv arXiv 1998
-
[13]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Hugo Touvron, Louis Martin, Kevin Stone, Peter Al- bert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foun- dation and fine-tuned chat models.arXiv preprint arXiv:2307.09288. Ke Wan...
work page internal anchor Pith review arXiv 2023
-
[14]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, and 1 others. 2025. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476. Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.