Recognition: unknown
G-MIXER: Geodesic Mixup-based Implicit Semantic Expansion and Explicit Semantic Re-ranking for Zero-Shot Composed Image Retrieval
Pith reviewed 2026-05-10 11:47 UTC · model grok-4.3
The pith
G-MIXER uses geodesic mixup across ratios to expand implicit semantics then re-ranks with MLLM explicit descriptions for zero-shot composed image retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
G-MIXER constructs composed query features that reflect the implicit semantics of reference image-text pairs through geodesic mixup over a range of mixup ratios, and builds a diverse candidate set. The generated candidates are then re-ranked using explicit semantics derived from MLLMs, improving both retrieval diversity and accuracy. The method achieves state-of-the-art performance across multiple ZS-CIR benchmarks while remaining training-free.
What carries the argument
Geodesic mixup over a range of mixup ratios for implicit semantic expansion, followed by MLLM-derived explicit semantic re-ranking.
If this is right
- Achieves state-of-the-art performance on multiple ZS-CIR benchmarks
- Handles both implicit and explicit semantics in a single pipeline
- Requires no additional training or fine-tuning
- Produces more diverse candidate sets than text-only MLLM approaches
- Improves accuracy by refining the fuzzy composition space
Where Pith is reading between the lines
- The ratio-sampling strategy implies that the space of valid image modifications is better approximated by a geodesic path than by a single interpolated point.
- The separation of implicit feature mixing from explicit re-ranking suggests the same split could be tested in other zero-shot retrieval settings where part of the query is visual and part is textual.
- If the geodesic assumption holds, similar mixup constructions might reduce dependence on MLLM quality for the implicit component across related multimodal tasks.
Load-bearing premise
Geodesic mixup over a range of ratios accurately constructs composed query features reflecting the implicit semantics of reference image-text pairs, and MLLM-generated explicit descriptions reliably improve re-ranking for diversity and accuracy.
What would settle it
Evaluating the full G-MIXER pipeline on standard ZS-CIR benchmarks and observing no gains in recall or precision metrics and no measurable increase in result diversity relative to prior training-free baselines would falsify the claim.
Figures




read the original abstract
Composed Image Retrieval (CIR) aims to retrieve target images by integrating a reference image with a corresponding modification text. CIR requires jointly considering the explicit semantics specified in the query and the implicit semantics embedded within its bi-modal composition. Recent training-free Zero-Shot CIR (ZS-CIR) methods leverage Multimodal Large Language Models (MLLMs) to generate detailed target descriptions, converting the implicit information into explicit textual expressions. However, these methods rely heavily on the textual modality and fail to capture the fuzzy retrieval nature that requires considering diverse combinations of candidates. This leads to reduced diversity and accuracy in retrieval results. To address this limitation, we propose a novel training-free method, Geodesic Mixup-based Implicit semantic eXpansion and Explicit semantic Re-ranking for ZS-CIR (G-MIXER). G-MIXER constructs composed query features that reflect the implicit semantics of reference image-text pairs through geodesic mixup over a range of mixup ratios, and builds a diverse candidate set. The generated candidates are then re-ranked using explicit semantics derived from MLLMs, improving both retrieval diversity and accuracy. Our proposed G-MIXER achieves state-of-the-art performance across multiple ZS-CIR benchmarks, effectively handling both implicit and explicit semantics without additional training. Our code will be available at https://github.com/maya0395/gmixer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes G-MIXER, a training-free method for Zero-Shot Composed Image Retrieval (ZS-CIR). It constructs composed query features via geodesic mixup over a range of ratios in the joint embedding space to expand implicit semantics from reference image-modification text pairs, builds a diverse candidate set from these expanded features, and re-ranks the candidates using explicit semantic descriptions generated by Multimodal Large Language Models (MLLMs). The paper claims this dual handling of implicit and explicit semantics yields state-of-the-art performance on multiple ZS-CIR benchmarks without any additional training.
Significance. If the central claims hold, G-MIXER would advance training-free ZS-CIR by mitigating over-reliance on textual modality and improving retrieval diversity, which prior MLLM-based methods reportedly lack. The approach's use of geodesic paths for semantic expansion and subsequent explicit re-ranking could provide a practical, parameter-free way to model fuzzy compositions. Credit is due for the training-free design and the explicit plan to release code, which supports reproducibility.
major comments (2)
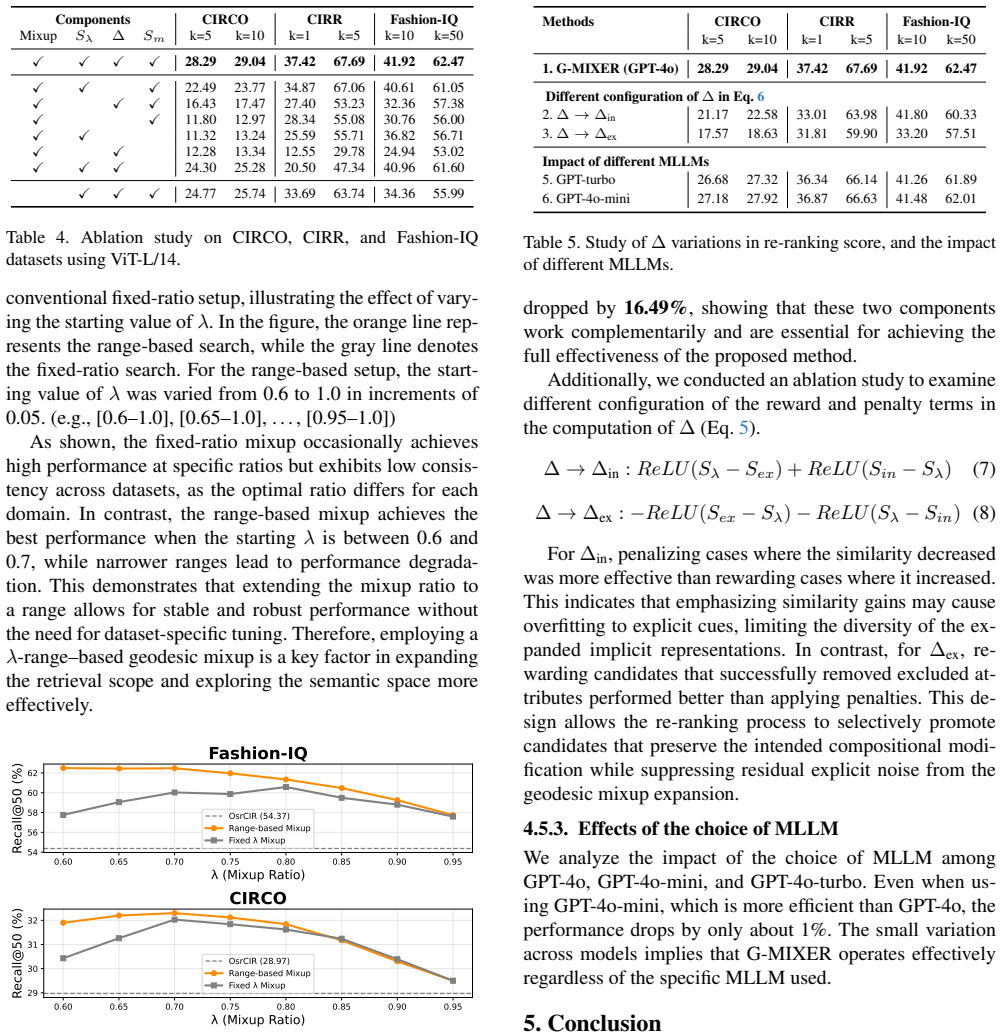
- [§3] §3: The geodesic mixup procedure for implicit semantic expansion is presented as the core mechanism, yet no validation is given that the computed geodesics in the pre-trained embedding manifold differ meaningfully from Euclidean linear interpolation or that they preserve/expand semantics as claimed. No manifold curvature analysis, geodesic computation details (e.g., how the metric is defined), or direct ablation against linear mixup baselines appears, which is load-bearing for the implicit-expansion claim.
- [§4] §4 (Experiments): The SOTA performance claims across ZS-CIR benchmarks are asserted, but the manuscript provides insufficient detail on implementation (e.g., exact mixup ratio sampling, MLLM prompting, candidate set size), ablation studies isolating the geodesic component, or error analysis to confirm that gains are attributable to the proposed method rather than implementation choices or benchmark specifics.
minor comments (2)
- [Abstract / §1] The term 'fuzzy retrieval nature' is used in the abstract and introduction without a precise definition or reference to prior literature on fuzzy matching in retrieval.
- [Figures / §3] Figure captions and algorithm pseudocode should explicitly state the embedding model and distance metric used for geodesic computation to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional clarification and evidence can strengthen the presentation of G-MIXER. We address each major comment point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3: The geodesic mixup procedure for implicit semantic expansion is presented as the core mechanism, yet no validation is given that the computed geodesics in the pre-trained embedding manifold differ meaningfully from Euclidean linear interpolation or that they preserve/expand semantics as claimed. No manifold curvature analysis, geodesic computation details (e.g., how the metric is defined), or direct ablation against linear mixup baselines appears, which is load-bearing for the implicit-expansion claim.
Authors: We agree that the manuscript would benefit from explicit validation of the geodesic mixup component. In the revision, we will add details on geodesic computation in the joint embedding space, an empirical comparison (with qualitative examples) demonstrating differences from Euclidean linear interpolation, an ablation study replacing geodesic mixup with linear mixup to quantify gains, and a brief discussion of manifold properties in pre-trained image-text embeddings that motivates the geodesic approach. These additions will directly support the implicit semantic expansion claim. revision: yes
-
Referee: [§4] §4 (Experiments): The SOTA performance claims across ZS-CIR benchmarks are asserted, but the manuscript provides insufficient detail on implementation (e.g., exact mixup ratio sampling, MLLM prompting, candidate set size), ablation studies isolating the geodesic component, or error analysis to confirm that gains are attributable to the proposed method rather than implementation choices or benchmark specifics.
Authors: We acknowledge that greater experimental transparency is needed. The revised manuscript will include full implementation details (mixup ratio sampling strategy, MLLM prompting templates, and candidate set size), expanded ablations that isolate the geodesic mixup contribution, and an error analysis section with representative success and failure cases. These changes will help attribute performance improvements to the dual implicit-explicit design. revision: yes
Circularity Check
No significant circularity; method is a novel algorithmic construction evaluated externally
full rationale
The paper presents G-MIXER as a training-free pipeline that constructs composed query features via geodesic mixup over mixup ratios and re-ranks candidates using MLLM-generated explicit descriptions. No equations or claims reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations; the central steps are presented as new combinations of existing components (pre-trained embeddings, MLLMs) and are validated on external ZS-CIR benchmarks rather than internal consistency. The derivation chain is self-contained as an empirical proposal without tautological reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
isearle: Improving textual inversion for zero-shot composed image retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Lorenzo Agnolucci, Alberto Baldrati, Alberto Del Bimbo, and Marco Bertini. isearle: Improving textual inversion for zero-shot composed image retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 2
2025
-
[3]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3,
work page internal anchor Pith review arXiv
-
[5]
Effective conditioned and composed im- age retrieval combining clip-based features
Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Al- berto Del Bimbo. Effective conditioned and composed im- age retrieval combining clip-based features. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21466–21474, 2022. 2
2022
-
[6]
Zero-shot composed image retrieval with textual inversion
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Al- berto Del Bimbo. Zero-shot composed image retrieval with textual inversion. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 15338–15347,
-
[7]
A fuzzy linguistic ap- proach generalizing boolean information retrieval: A model and its evaluation.Journal of the American Society for In- formation Science, 44(2):70–82, 1993
Gloria Bordogna and Gabriella Pasi. A fuzzy linguistic ap- proach generalizing boolean information retrieval: A model and its evaluation.Journal of the American Society for In- formation Science, 44(2):70–82, 1993. 1
1993
-
[8]
A region-based fuzzy feature matching approach to content-based image retrieval
Yixin Chen and James Ze Wang. A region-based fuzzy feature matching approach to content-based image retrieval. IEEE transactions on pattern analysis and machine intelli- gence, 24(9):1252–1267, 2002. 1
2002
-
[9]
Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision- language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023. 3
2023
-
[10]
Yongchao Du, Min Wang, Wengang Zhou, Shuping Hui, and Houqiang Li. Image2sentence based asymmetrical zero-shot composed image retrieval.arXiv preprint arXiv:2403.01431,
-
[11]
Language-only efficient training of zero- shot composed image retrieval–appendix–
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, Yoohoon Kang, and Sangdoo Yun. Language-only efficient training of zero- shot composed image retrieval–appendix–. 2
-
[12]
Egocvr: An egocentric benchmark for fine-grained composed video retrieval
Thomas Hummel, Shyamgopal Karthik, Mariana-Iuliana Georgescu, and Zeynep Akata. Egocvr: An egocentric benchmark for fine-grained composed video retrieval. In European Conference on Computer Vision, pages 1–17. Springer, 2024. 3
2024
-
[13]
Spherical linear interpolation and text- anchoring for zero-shot composed image retrieval
Young Kyun Jang, Dat Huynh, Ashish Shah, Wen-Kai Chen, and Ser-Nam Lim. Spherical linear interpolation and text- anchoring for zero-shot composed image retrieval. InEu- ropean Conference on Computer Vision, pages 239–254. Springer, 2024. 2
2024
-
[14]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[15]
Dongsheng Jiang, Yuchen Liu, Songlin Liu, Jin’e Zhao, Hao Zhang, Zhen Gao, Xiaopeng Zhang, Jin Li, and Hongkai Xiong. From clip to dino: Visual encoders shout in multi-modal large language models.arXiv preprint arXiv:2310.08825, 2023. 3
-
[16]
Shyamgopal Karthik, Karsten Roth, Massimiliano Mancini, and Zeynep Akata. Vision-by-language for training- free compositional image retrieval.arXiv preprint arXiv:2310.09291, 2023. 2, 3, 6
-
[17]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 1, 3
2022
-
[18]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
2023
-
[19]
Fine-grained textual inversion network for zero-shot composed image retrieval
Haoqiang Lin, Haokun Wen, Xuemeng Song, Meng Liu, Yu- peng Hu, and Liqiang Nie. Fine-grained textual inversion network for zero-shot composed image retrieval. InProceed- ings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 240–250, 2024. 2
2024
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 3
2023
-
[21]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 3
2024
-
[22]
Image retrieval on real-life images with pre-trained vision-and-language models
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. Image retrieval on real-life images with pre-trained vision-and-language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2125–2134, 2021. 2, 5
2021
-
[23]
Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019. 6
2019
-
[24]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[25]
Instance-level composed image retrieval
Bill Psomas, George Retsinas, Nikos Efthymiadis, Panagio- tis Filntisis, Yannis Avrithis, Petros Maragos, Ondrej Chum, and Giorgos Tolias. Instance-level composed image retrieval. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2025. 2
2025
-
[26]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 3
2021
-
[27]
Pic2word: Mapping pictures to words for zero-shot composed image retrieval
Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Pic2word: Mapping pictures to words for zero-shot composed image retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19305– 19314, 2023. 1, 2
2023
-
[28]
Knowledge-enhanced dual-stream zero-shot composed im- age retrieval
Yucheng Suo, Fan Ma, Linchao Zhu, and Yi Yang. Knowledge-enhanced dual-stream zero-shot composed im- age retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26951– 26962, 2024. 2
2024
-
[29]
A fuzzy model of document retrieval sys- tems.Information Processing & Management, 12(3):177– 187, 1976
Valiollah Tahani. A fuzzy model of document retrieval sys- tems.Information Processing & Management, 12(3):177– 187, 1976. 1
1976
-
[30]
Context-i2w: Mapping images to context-dependent words for accurate zero-shot composed image retrieval
Yuanmin Tang, Jing Yu, Keke Gai, Jiamin Zhuang, Gang Xiong, Yue Hu, and Qi Wu. Context-i2w: Mapping images to context-dependent words for accurate zero-shot composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5180–5188, 2024. 1
2024
-
[31]
Yuanmin Tang, Jing Yu, Keke Gai, Jiamin Zhuang, Gang Xiong, Gaopeng Gou, and Qi Wu. Missing target- relevant information prediction with world model for ac- curate zero-shot composed image retrieval.arXiv preprint arXiv:2503.17109, 2025. 6
-
[32]
Reason-before-retrieve: One-stage reflective chain-of-thoughts for training-free zero-shot com- posed image retrieval
Yuanmin Tang, Jue Zhang, Xiaoting Qin, Jing Yu, Gaopeng Gou, Gang Xiong, Qingwei Lin, Saravan Rajmohan, Dong- mei Zhang, and Qi Wu. Reason-before-retrieve: One-stage reflective chain-of-thoughts for training-free zero-shot com- posed image retrieval. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14400– 14410, 2025. 2, 3, 6
2025
-
[33]
Genecis: A benchmark for general conditional image similarity
Sagar Vaze, Nicolas Carion, and Ishan Misra. Genecis: A benchmark for general conditional image similarity. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6862–6872, 2023. 5
2023
-
[34]
Composing text and image for image retrieval-an empirical odyssey
Nam V o, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrieval-an empirical odyssey. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6439–6448, 2019. 1, 2
2019
-
[35]
Fashion iq: A new dataset towards retrieving images by natural language feedback
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. Fashion iq: A new dataset towards retrieving images by natural language feedback. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11307– 11317, 2021. 5
2021
-
[36]
Jiannan Wu, Muyan Zhong, Sen Xing, Zeqiang Lai, Zhaoyang Liu, Zhe Chen, Wenhai Wang, Xizhou Zhu, Lewei Lu, Tong Lu, et al. Visionllm v2: An end-to-end general- ist multimodal large language model for hundreds of vision- language tasks.Advances in Neural Information Processing Systems, 37:69925–69975, 2024. 3
2024
-
[37]
Ldre: Llm-based divergent reasoning and ensemble for zero-shot composed image re- trieval
Zhenyu Yang, Dizhan Xue, Shengsheng Qian, Weiming Dong, and Changsheng Xu. Ldre: Llm-based divergent reasoning and ensemble for zero-shot composed image re- trieval. InProceedings of the 47th International ACM SIGIR conference on research and development in information re- trieval, pages 80–90, 2024. 1, 2, 3, 6
2024
-
[38]
Filip: Fine-grained interactive language-image pre-training
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training.arXiv preprint arXiv:2111.07783, 2021. 3
-
[39]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 3
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.