Recognition: unknown
AIM: Asymmetric Information Masking for Visual Question Answering Continual Learning
Pith reviewed 2026-05-10 11:10 UTC · model grok-4.3
The pith
Asymmetric Information Masking applies modality-specific masks to protect visual projection layers and reduce catastrophic forgetting in continual VQA with asymmetric VLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AIM addresses the structural mismatch in VLMs by applying targeted masks based on modality-specific sensitivity. This balances stability and plasticity, preventing the localized degradation in visual projection layers that causes loss of compositional reasoning in continual VQA.
What carries the argument
Asymmetric Information Masking (AIM), a technique that computes and applies modality-aware masks during optimization to selectively stabilize sensitive visual components while permitting adaptation in language components.
If this is right
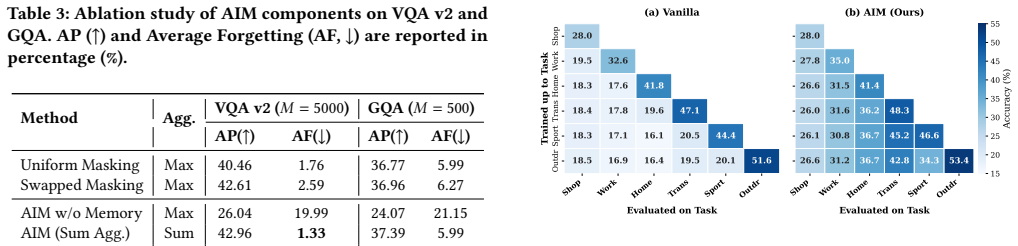
- AIM achieves state-of-the-art Average Performance and Average Forgetting on VQA v2 and GQA under continual VQA settings.
- The method preserves generalization to novel skill-concept compositions more effectively than standard continual learning approaches.
- Standard global regularization proves insufficient for asymmetric VLMs because it disproportionately protects language components.
- Protecting visual projection layers specifically prevents the degradation that harms compositional reasoning over time.
Where Pith is reading between the lines
- Continual learning for any multimodal model with size or update-rate differences between modalities may require similar sensitivity-aware adjustments rather than uniform regularization.
- The same masking principle could be tested on other tasks such as visual reasoning or image captioning where VLMs exhibit comparable asymmetry.
- Scaling AIM to larger VLMs with more diverse continual task sequences would test whether the modality-specific masking remains effective as model scale increases.
Load-bearing premise
The structural asymmetry between the language decoder and visual projection layers in VLMs causes standard global regularization to favor the language side and leave visual layers vulnerable to interference.
What would settle it
Measure parameter sensitivity or gradient magnitudes separately in visual projection layers versus the language decoder across continual training steps; if the visual layers show no greater change without AIM, or if AIM fails to reduce forgetting specifically by stabilizing those layers, the central explanation would not hold.
Figures







read the original abstract
In continual visual question answering (VQA), existing Continual Learning (CL) methods are mostly built for symmetric, unimodal architectures. However, modern Vision-Language Models (VLMs) violate this assumption, as their trainable components are inherently asymmetric. This structural mismatch renders VLMs highly prone to catastrophic forgetting when learning from continuous data streams. Specifically, the asymmetry causes standard global regularization to favor the massive language decoder during optimization, leaving the smaller but critical visual projection layers highly vulnerable to interference. Consequently, this localized degradation leads to a severe loss of compositional reasoning capabilities. To address this, we propose Asymmetric Information Masking (AIM), which balances stability and plasticity by applying targeted masks based on modality-specific sensitivity. Experiments on VQA v2 and GQA under continual VQA settings show that AIM achieves state-of-the-art performance in both Average Performance (AP) and Average Forgetting (AF), while better preserving generalization to novel skill-concept compositions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Asymmetric Information Masking (AIM) for continual learning in Visual Question Answering (VQA) with Vision-Language Models (VLMs). It claims that VLMs' asymmetric trainable components (large language decoder vs. smaller visual projection layers) cause standard global regularization methods to favor the decoder, leaving visual layers vulnerable to interference and degrading compositional reasoning. AIM counters this by applying modality-specific masks based on sensitivity to balance stability and plasticity. Experiments on VQA v2 and GQA under continual VQA settings report state-of-the-art Average Performance (AP) and Average Forgetting (AF), with better preservation of generalization to novel skill-concept compositions.
Significance. If the central mechanism is validated and results hold under rigorous controls, this work identifies an architecture-specific vulnerability in applying existing CL techniques to multimodal models and offers a targeted mitigation. It could inform future CL designs for VLMs in sequential data settings, particularly for maintaining compositional generalization. The SOTA claims on standard benchmarks indicate potential practical value, though the absence of direct evidence for the asymmetry premise limits the strength of the causal argument.
major comments (2)
- [Abstract and §2] Abstract and §2 (motivation): The claim that asymmetry causes standard global regularization to disproportionately favor the language decoder and leave visual projection layers vulnerable lacks any supporting measurements, such as per-layer gradient norms, Fisher information matrices, or parameter drift comparisons under baselines like EWC/MAS. This makes it impossible to confirm that AIM's gains arise from correcting localized interference rather than generic masking benefits.
- [§4] §4 (experiments): While SOTA AP and AF are reported along with improved preservation of novel compositions, the section provides no error bars, statistical significance tests, detailed baseline implementations, or ablations that isolate the asymmetric masking component. This weakens the ability to attribute performance differences specifically to the proposed asymmetry correction.
minor comments (2)
- [§3] The description of how modality-specific sensitivity is computed for mask generation could benefit from an explicit equation or pseudocode to improve reproducibility.
- [§4] Figure captions and axis labels in the experimental results should explicitly state the number of runs and any variance measures for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the motivation and experimental validation, and we have revised the paper accordingly to address them directly.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2 (motivation): The claim that asymmetry causes standard global regularization to disproportionately favor the language decoder and leave visual projection layers vulnerable lacks any supporting measurements, such as per-layer gradient norms, Fisher information matrices, or parameter drift comparisons under baselines like EWC/MAS. This makes it impossible to confirm that AIM's gains arise from correcting localized interference rather than generic masking benefits.
Authors: We agree that explicit measurements of the asymmetry effect would strengthen the causal argument. The original motivation drew from the documented architectural disparity (language decoder parameters vastly outnumbering those in visual projection layers), but we did not include direct quantification. In the revised manuscript, we have added a new analysis subsection in §2 reporting per-layer gradient norms and parameter drift under EWC and MAS. These measurements show substantially higher interference in the visual layers compared to the decoder, supporting that global methods leave them vulnerable. We further include an ablation contrasting AIM against a symmetric masking baseline, which yields inferior results and helps isolate the benefit to the modality-specific correction rather than generic masking. revision: yes
-
Referee: [§4] §4 (experiments): While SOTA AP and AF are reported along with improved preservation of novel compositions, the section provides no error bars, statistical significance tests, detailed baseline implementations, or ablations that isolate the asymmetric masking component. This weakens the ability to attribute performance differences specifically to the proposed asymmetry correction.
Authors: We acknowledge that the original experimental section lacked sufficient statistical controls and isolation of the key component. The revised §4 now reports error bars as standard deviation across five independent runs for all metrics on VQA v2 and GQA. We have added Wilcoxon signed-rank tests confirming statistical significance (p < 0.05) of AIM's gains over baselines. Detailed baseline implementations, including all hyperparameters and training protocols, are provided in the supplementary material. Finally, we expanded the ablation studies to include symmetric masking and uniform global masking variants; the results show that only the asymmetric, modality-specific masks recover the reported improvements in AP, AF, and compositional generalization, allowing attribution to the proposed mechanism. revision: yes
Circularity Check
No circularity; proposal is an independent method invention
full rationale
The paper introduces AIM as a targeted masking technique to handle asymmetry in VLMs for continual VQA. The premise about global regularization favoring the language decoder is stated as an architectural observation rather than derived from any self-citation chain, fitted parameter, or prior ansatz. No equations reduce a claimed prediction to an input by construction, no uniqueness theorem is imported from the authors' own work, and the reported AP/AF gains are presented as outcomes of new experiments on VQA v2 and GQA rather than statistical artifacts of the method's own fitting procedure. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Modern VLMs have inherently asymmetric trainable components
- domain assumption Standard global regularization favors the language decoder over visual layers
invented entities (1)
-
Asymmetric Information Masking (AIM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. 2018. Don’t Just Assume; Look and Answer: Overcoming Priors for Visual Question Answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[2]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski,...
work page internal anchor Pith review arXiv 2022
-
[3]
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. 2018. Memory Aware Synapses: Learning what (not) to forget. InProceedings of the European Conference on Computer Vision (ECCV)
2018
-
[4]
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. 2020. Dark experience for general continual learning: a strong, simple baseline. InProceedings of the 34th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’20). Curran Associates Inc., Red Hook, NY, USA, Article 1335, 11 pages
2020
- [5]
-
[6]
Jize Cao, Zhe Gan, Yu Cheng, Licheng Yu, Yen-Chun Chen, and Jingjing Liu. 2020. Behind the Scene: Revealing the Secrets of Pre-trained Vision-and-Language Models. InEuropean Conference on Computer Vision. https://api.semanticscholar. org/CorpusID:218665405
2020
-
[7]
Hyuntak Cha, Jaeho Lee, and Jinwoo Shin. 2021. Co2L: Contrastive Continual Learning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 9516–9525
2021
-
[8]
Arslan Chaudhry, Puneet K. Dokania, Thalaiyasingam Ajanthan, and Philip H. S. Torr. 2018.Riemannian Walk for Incremental Learning: Understanding Forgetting and Intransigence. Springer International Publishing, 556–572. doi:10.1007/978- 3-030-01252-6_33
- [9]
-
[10]
Yusheng Dai, Hang Chen, Jun Du, Ruoyu Wang, Shihao Chen, Haotian Wang, and Chin-Hui Lee. 2024. A Study of Dropout-Induced Modality Bias on Robustness to Missing Video Frames for Audio-Visual Speech Recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 27445–27455
2024
-
[11]
Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. 2022. Learning to Prompt for Open-Vocabulary Object Detection with Vision-Language Model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2022
-
[12]
Turrisi da Costa, Xavier Alameda-Pineda, Elisa Ricci, Karteek Alahari, and Julien Mairal
Enrico Fini, Victor G. Turrisi da Costa, Xavier Alameda-Pineda, Elisa Ricci, Karteek Alahari, and Julien Mairal. 2022. Self-Supervised Models Are Continual Learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9621–9630
2022
-
[13]
R. M. French. 1999. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences3, 4 (1999), 128–135
1999
-
[14]
Peng Gao, Shijie Geng, Renrui Zhang, et al. 2024. CLIP-Adapter: Better Vision- Language Models with Feature Adapters.International Journal of Computer Vision132 (2024), 581–595. doi:10.1007/s11263-023-01891-x
-
[15]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh
-
[16]
InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Making the v in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
-
[17]
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. 2021. Open-Vocabulary Ob- ject Detection via Vision and Language Knowledge Distillation. InInternational Conference on Learning Representations
2021
-
[18]
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. 2025. CL-MoE: Enhancing Multimodal Large Language Model with Dual Momentum Mixture-of-Experts for Continual Visual Question Answer- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 19608–19617
2025
-
[19]
Drew A. Hudson and Christopher D. Manning. 2019. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6693–6702. doi:10.1109/CVPR.2019.00686
-
[20]
Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. 2019. What Does BERT Learn about the Structure of Language?. InAnnual Meeting of the Association for Computational Linguistics. https://api.semanticscholar.org/CorpusID:195477534
2019
-
[21]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Ag- nieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Ku- maran, and Raia Hadsell
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Ag- nieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Ku- maran, and Raia Hadsell. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences114, ...
2017
-
[22]
arXiv:https://www.pnas.org/doi/pdf/10.1073/pnas.1611835114 doi:10.1073/ pnas.1611835114
-
[23]
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. 2016. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. arXiv:1602.07332 [cs.CV] https://arxiv.org/abs/1602.07332
work page Pith review arXiv 2016
-
[24]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Boot- strapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. InProceedings of the 40th International Conference on Ma- chine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhar...
2023
-
[25]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Boot- strapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. arXiv:2301.12597 [cs.CV] https://arxiv.org/abs/2301.12597
work page internal anchor Pith review arXiv 2023
-
[26]
Junyang Li, Dong Li, Chen Xiong, and Steven C. H. Hoi. 2022. BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation. InProceedings of the International Conference on Machine Learning (ICML). 12888–12900
2022
-
[27]
Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi
Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. 2021. Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. InNeurIPS
2021
-
[28]
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang
-
[29]
InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL)
What Does BERT with Vision Look At?. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL). 5265–5275
-
[30]
Zhizhong Li and Derek Hoiem. 2018. Learning without Forgetting.IEEE Trans- actions on Pattern Analysis and Machine Intelligence40, 12 (2018), 2935–2947. doi:10.1109/TPAMI.2017.2773081
-
[31]
Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Zou
-
[32]
InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’22)
Mind the gap: understanding the modality gap in multi-modal contrastive representation learning. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’22). Curran Associates Inc., Red Hook, NY, USA, Article 1280, 14 pages
-
[33]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual In- struction Tuning. arXiv:2304.08485 [cs.CV] https://arxiv.org/abs/2304.08485
work page internal anchor Pith review arXiv 2023
-
[34]
H. Liu, C. Li, Q. Wu, Y. J. Lee, L. Zhang, and W. Y. Wang. 2023. Visual Instruction Tuning. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36
2023
- [35]
-
[36]
Yuyang Liu, Qiuhe Hong, Linlan Huang, Alexandra Gomez-Villa, Dipam Goswami, Xialei Liu, Joost van de Weijer, and Yonghong Tian. 2025. Continual Learning for VLMs: A Survey and Taxonomy Beyond Forgetting. arXiv preprint
2025
-
[37]
David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient episodic memory for continual learning. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6470–6479
2017
-
[38]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. arXiv:1711.05101 [cs.LG] https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [39]
-
[40]
James Martens. 2020. New Insights and Perspectives on the Natural Gradient Method.Journal of Machine Learning Research21, 146 (2020), 1–76. http: 9 //jmlr.org/papers/v21/17-678.html
2020
-
[41]
McCloskey and N
M. McCloskey and N. J. Cohen. 1989. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of Learning and Motivation. Vol. 24. Academic Press, 109–165
1989
-
[42]
Nguyen, M
T. Nguyen, M. N. Vu, A. Vuong, D. Nguyen, T. Vo, N. Le, and A. Nguyen. 2023. CLOVE: A benchmark for continual learning in visual question answering over domain shifts. InProceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV). 1563–1573
2023
-
[43]
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. 2022. Balanced Multimodal Learning via On-the-Fly Gradient Modulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 8238– 8247
2022
-
[44]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th In- ternational Conference on Machine Learning (Proceedings of Machi...
2021
-
[45]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. 2017. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2001–2010
2017
- [46]
-
[47]
Anthony V. Robins. 1995. Catastrophic Forgetting, Rehearsal and Pseudore- hearsal.Connect. Sci.7 (1995), 123–146. https://api.semanticscholar.org/ CorpusID:22882861
1995
-
[48]
Jonathan Schwarz, Wojciech Czarnecki, Jelena Luketina, Agnieszka Grabska- Barwinska, Yee Whye Teh, Razvan Pascanu, and Raia Hadsell. 2018. Progress & Compress: A scalable framework for continual learning. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80), Jennifer Dy and Andreas ...
2018
-
[49]
https://proceedings.mlr.press/v80/schwarz18a.html
-
[50]
Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, et al . 2021. FLAVA: A Foundational Language And Vision Alignment Model. doi:10.48550/arXiv.2112. 04482 arXiv preprint
- [51]
-
[52]
Timmy S. T. Wan, Jun-Cheng Chen, Tzer-Yi Wu, and Chu-Song Chen. 2022. Continual Learning for Visual Search With Backward Consistent Feature Embed- ding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 16702–16711
2022
-
[53]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. 2024. A Comprehensive Survey of Continual Learning: Theory, Method and Application.IEEE Transac- tions on Pattern Analysis and Machine Intelligence46, 8 (2024), 5362–5383
2024
-
[54]
Weiyao Wang, Du Tran, and Matt Feiszli. 2020. What Makes Training Multi- Modal Classification Networks Hard?. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[55]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement De- langue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Fun- towicz, Joe Davison, Sam Shleifer, Patrick Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Scao, Sylvain Gugger, and Alexander Rush
-
[56]
Transformers: State-of-the-Art Natural Language Processing. 38–45. doi:10.18653/v1/2020.emnlp-demos.6
-
[57]
Rui Yan, Mike Zheng Shou, Yixiao Ge, Jinpeng Wang, Xudong Lin, Guanyu Cai, and Jinhui Tang. 2023. Video-Text Pre-training with Learned Regions for Retrieval.Proceedings of the AAAI Conference on Artificial Intelligence37, 3 (Jun. 2023), 3100–3108. doi:10.1609/aaai.v37i3.25414
-
[58]
S. Yang, L. Chen, H. Zhang, and T. Xiao. 2024. QUAD: Question-only replay for anti-forgetting in visual question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 22545–22554
2024
-
[59]
Zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, and Qi Tian. 2019. Deep Modular Co-Attention Networks for Visual Question Answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2019
-
[60]
Renrui Zhang, Rongyao Fang, Wei Zhang, Peng Gao, Kai Li, Jianfei Dai, Yu Qiao, et al. 2022. Tip-Adapter: Training-Free Adaption of CLIP for Few-Shot Classification. InComputer Vision – ECCV 2022. Lecture Notes in Computer Science, Vol. 13695. Springer, 493–510. doi:10.1007/978-3-031-19833-5_29
-
[61]
Xi Zhang, Feifei Zhang, and Changsheng Xu. 2023. VQACL: A Novel Visual Question Answering Continual Learning Setting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[62]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022. Learning to Prompt for Vision-Language Models.International Journal of Computer Vision 130, 9 (2022), 2337–2348. 10 Supplementary Material Overview This supplement details our Asymmetric Information Masking (AIM) for visual question answering continual learning, which mitigates catastrophi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.