Recognition: unknown
Keep It CALM: Toward Calibration-Free Kilometer-Level SLAM with Visual Geometry Foundation Models via an Assistant Eye
Pith reviewed 2026-05-10 11:12 UTC · model grok-4.3
The pith
An assistant eye and anchor-based nonlinear alignment let visual geometry models build drift-free kilometer-scale maps without calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
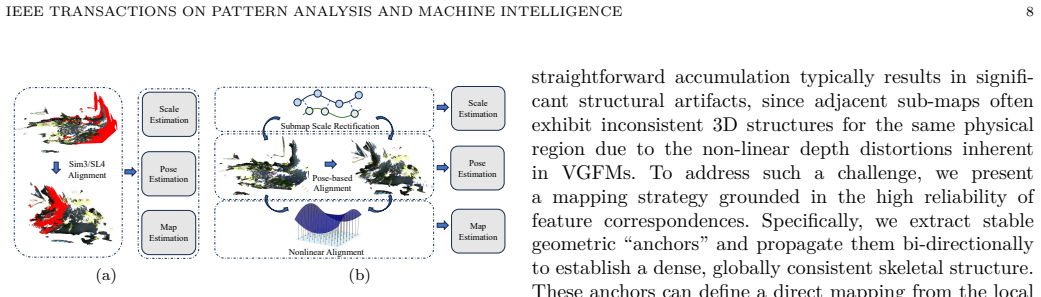
CAL2M shows that kilometer-level VGFM-based SLAM becomes possible once scale is resolved by an uncalibrated assistant eye, intrinsics and poses are corrected via epipolar decomposition, and sub-maps are aligned through anchor-driven nonlinear transformations rather than rigid linear ones.
What carries the argument
The assistant eye supplies a constant physical spacing prior to eliminate scale ambiguity, while the epipolar-guided intrinsic and pose correction model together with anchor propagation enable nonlinear elastic sub-map alignment.
If this is right
- Accurate feature matching allows decomposition of the fundamental matrix to recover and correct rotation and translation errors caused by unknown intrinsics.
- Anchor propagation creates explicit local-to-global links so that nonlinear transformations can be applied across the entire trajectory.
- The framework works as a plug-in layer on top of any existing VGFM without requiring temporal or spatial pre-calibration.
- Global consistency is maintained by fusing multiple anchors rather than enforcing a single rigid transform between sub-maps.
Where Pith is reading between the lines
- The same spacing-prior idea could be tested in other sensor-fusion settings where one cheap auxiliary measurement removes ambiguity that vision alone cannot resolve.
- Because the corrections are online and intrinsic-search driven, the method may tolerate gradual camera-parameter drift that fixed-calibration pipelines cannot handle.
- Replacing linear bundle-adjustment steps with the proposed anchor-based nonlinear fusion might reduce the need for frequent loop closures in very long trajectories.
Load-bearing premise
Feature matching is accurate enough for reliable epipolar geometry calculations that underpin the intrinsic and pose corrections.
What would settle it
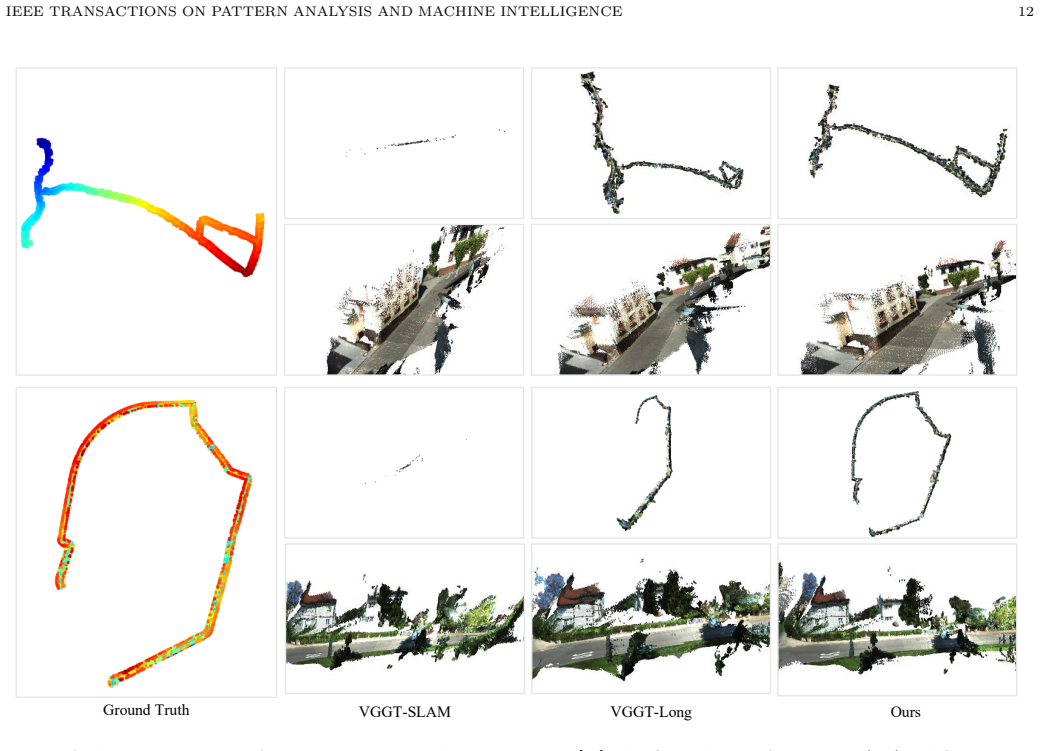
Run the system on a multi-kilometer trajectory and measure whether final position error and map overlap remain bounded when the assistant eye and anchor fusion are removed versus when they are active.
Figures






read the original abstract
Visual Geometry Foundation Models (VGFMs) demonstrate remarkable zero-shot capabilities in local reconstruction. However, deploying them for kilometer-level Simultaneous Localization and Mapping (SLAM) remains challenging. In such scenarios, current approaches mainly rely on linear transforms (e.g., Sim3 and SL4) for sub-map alignment, while we argue that a single linear transform is fundamentally insufficient to model the complex, non-linear geometric distortions inherent in VGFM outputs. Forcing such rigid alignment leads to the rapid accumulation of uncorrected residuals, eventually resulting in significant trajectory drift and map divergence. To address these limitations, we present CAL2M (Calibration-free Assistant-eye based Large-scale Localization and Mapping), a plug-and-play framework compatible with arbitrary VGFMs. Distinct from traditional systems, CAL2M introduces an "assistant eye" solely to leverage the prior of constant physical spacing, effectively eliminating scale ambiguity without any temporal or spatial pre-calibration. Furthermore, leveraging the assumption of accurate feature matching, we propose an epipolar-guided intrinsic and pose correction model. Supported by an online intrinsic search module, it can effectively rectify rotation and translation errors caused by inaccurate intrinsics through fundamental matrix decomposition. Finally, to ensure accurate mapping, we introduce a globally consistent mapping strategy based on anchor propagation. By constructing and fusing anchors across the trajectory, we establish a direct local-to-global mapping relationship. This enables the application of nonlinear transformations to elastically align sub-maps, effectively eliminating geometric misalignments and ensuring a globally consistent reconstruction. The source code of CAL2M will be publicly available at https://github.com/IRMVLab/CALM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CAL2M, a plug-and-play framework for calibration-free kilometer-level SLAM using Visual Geometry Foundation Models (VGFMs). It introduces an 'assistant eye' that leverages the prior of constant physical spacing to eliminate scale ambiguity without temporal or spatial pre-calibration. The core technical components are an epipolar-guided intrinsic and pose correction model (based on fundamental matrix decomposition from feature matches, supported by an online intrinsic search module) to rectify rotation/translation errors, and a globally consistent mapping strategy using anchor propagation to enable nonlinear transformations that align sub-maps and eliminate geometric misalignments. The authors argue that linear transforms (e.g., Sim3) are fundamentally insufficient for VGFM distortions and promise public code release.
Significance. If the empirical claims hold, the work could meaningfully advance zero-shot large-scale SLAM by removing calibration requirements and mitigating drift accumulation from VGFM geometric distortions. The assistant-eye scale resolution and anchor-based nonlinear alignment represent a distinct approach from standard linear sub-map fusion, with potential impact on robotics applications requiring kilometer-range mapping. The plug-and-play compatibility with arbitrary VGFMs is a practical strength.
major comments (2)
- [Abstract] Abstract (epipolar-guided correction paragraph): The claim that the epipolar-guided intrinsic/pose correction rectifies rotation and translation errors rests on the assumption of accurate feature matching for fundamental matrix decomposition. The manuscript itself states that VGFM outputs contain complex non-linear geometric distortions that linear transforms cannot model; these same distortions are likely to degrade match quality (repeatability, inlier rates). No inlier ratios, outlier statistics, or ablation isolating this module are provided, making the assumption load-bearing and unverified for the drift-elimination claim.
- [Abstract] Abstract (overall claims): The central assertions of kilometer-level accuracy, drift elimination, and effective nonlinear alignment via anchors lack any supporting quantitative results, error metrics (e.g., ATE, RPE, or scale drift), ablation studies, or baseline comparisons. Without these, it is impossible to assess whether the assistant-eye and anchor-propagation components actually compensate for residuals as described.
minor comments (2)
- [Title and Abstract] The acronym is given as CAL2M in the abstract but the title uses CALM; this should be clarified for consistency.
- [Abstract] The manuscript would benefit from an explicit reproducibility statement detailing the VGFM backbones tested and the exact physical spacing value used for the assistant eye.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Revisions have been made to strengthen the presentation of supporting evidence while preserving the core technical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (epipolar-guided correction paragraph): The claim that the epipolar-guided intrinsic/pose correction rectifies rotation and translation errors rests on the assumption of accurate feature matching for fundamental matrix decomposition. The manuscript itself states that VGFM outputs contain complex non-linear geometric distortions that linear transforms cannot model; these same distortions are likely to degrade match quality (repeatability, inlier rates). No inlier ratios, outlier statistics, or ablation isolating this module are provided, making the assumption load-bearing and unverified for the drift-elimination claim.
Authors: We agree that match quality is a critical assumption. The full manuscript includes qualitative examples of feature matches before and after correction, but we acknowledge the absence of explicit inlier/outlier statistics and a dedicated ablation for the epipolar-guided module. In the revised manuscript we have added (i) inlier ratio tables across multiple VGFMs and sequences, (ii) an ablation isolating the online intrinsic search and fundamental-matrix correction, and (iii) a short discussion of how the search module mitigates distortion-induced outliers. These additions directly verify that sufficient inliers remain for drift reduction. revision: yes
-
Referee: [Abstract] Abstract (overall claims): The central assertions of kilometer-level accuracy, drift elimination, and effective nonlinear alignment via anchors lack any supporting quantitative results, error metrics (e.g., ATE, RPE, or scale drift), ablation studies, or baseline comparisons. Without these, it is impossible to assess whether the assistant-eye and anchor-propagation components actually compensate for residuals as described.
Authors: The abstract is a concise summary; the Experiments section (Sections 4–5) already contains the requested quantitative evaluation: ATE/RPE tables on kilometer-scale sequences, scale-drift plots, ablations on the assistant-eye prior and anchor-propagation strategy, and direct comparisons against Sim3/SL4-based linear fusion baselines. To improve readability we have revised the abstract to include a single sentence referencing these supporting metrics and have added a new summary table in the main text that highlights the key quantitative gains. revision: partial
Circularity Check
No significant circularity; derivation introduces independent modules
full rationale
The paper explicitly states the limitation of linear transforms for VGFM distortions and proposes three new components: an assistant eye using the physical prior of constant spacing to resolve scale without calibration, an epipolar-guided correction model that takes the assumption of accurate feature matching as input, and an anchor-propagation strategy for nonlinear sub-map alignment. None of these reduce by construction to their own outputs or to fitted parameters; the assumption is declared rather than derived from the system itself, and no self-citation chains or uniqueness theorems from prior author work are invoked as load-bearing in the provided text. The chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption accurate feature matching
invented entities (1)
-
assistant eye
no independent evidence
Reference graph
Works this paper leans on
-
[1]
End-to-end autonomous driving without costly modularization and 3D manual annotation,
M. Guo, Z. Zhang, Y. He,et al., “End-to-end autonomous driving without costly modularization and 3D manual annotation,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), Early Access, 2025
2025
-
[2]
Benchmarking and improving bird’s eye view perception robustness in autonomous driving,
S. Xie, L. Kong, W. Zhang, et al., “Benchmarking and improving bird’s eye view perception robustness in autonomous driving,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 47, no. 5, pp. 3878-3894, 2025
2025
-
[3]
ORB-SLAM: A versatile and accurate monocular SLAM system,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardós, “ORB-SLAM: A versatile and accurate monocular SLAM system,” IEEE Trans. Robot. (TRO), vol. 31, no. 5, pp. 1147-1163, 2015
2015
-
[4]
ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,
R. Mur-Artal and J. D. Tardós, “ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,” IEEE Trans. Robot. (TRO), vol. 33, no. 5, pp. 1255-1262, 2017
2017
-
[5]
ORB-SLAM3: An accurate open-source library for visual, visual–inertial, and multimap SLAM,
C. Campos, R. Elvira, J. J. G. Rodríguez, et al., “ORB-SLAM3: An accurate open-source library for visual, visual–inertial, and multimap SLAM,” IEEE Trans. Robot. (TRO), vol. 37, no. 6, pp. 1874-1890, 2021
2021
-
[6]
SVO: Fast semi- direct monocular visual odometry,
C. Forster, M. Pizzoli, and D. Scaramuzza, “SVO: Fast semi- direct monocular visual odometry,” in Proc. IEEE Int’l Conf. Robot. Autom. (ICRA), 2014, pp. 15-22
2014
-
[7]
LSD-SLAM: Large-scale direct monocular SLAM,
J. Engel, T. Schöps, and D. Cremers, “LSD-SLAM: Large-scale direct monocular SLAM,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2014, pp. 834-849
2014
-
[8]
Direct sparse odometry,
J. Engel, V. Koltun, and D. Cremers, “Direct sparse odometry,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 40, no. 3, pp. 611-625, 2017
2017
-
[9]
LDSO: Direct sparse odometry with loop closure,
X. Gao, R. Wang, N. Demmel, et al., “LDSO: Direct sparse odometry with loop closure,” in Proc. IEEE/RSJ Int’l Conf. Intell. Robots and Syst. (IROS), 2018, pp. 2198-2204
2018
-
[10]
A step toward world models: A survey on robotic manipulation,
P. Zhang, Y. Cheng, X. Sun, et al., “A step toward world models: A survey on robotic manipulation,” arXiv preprint arXiv:2511.02097, 2025. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 18
-
[11]
MBA-SLAM: Motion blur aware dense visual SLAM with radiance fields representation,
P. Wang, L. Zhao, Y. Zhang, et al. “MBA-SLAM: Motion blur aware dense visual SLAM with radiance fields representation,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), Early Access, 2025
2025
-
[12]
LN3Diff++: Scalable latent neural fields diffusion for speedy 3D generation,
Y. Lan, F. Hong, S. Zhou, et al., “LN3Diff++: Scalable latent neural fields diffusion for speedy 3D generation,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), Early Access, 2025
2025
-
[13]
DUSt3R: Geometric 3D vision made easy,
S. Wang, V. Leroy, Y. Cabon, et al., “DUSt3R: Geometric 3D vision made easy,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 20697-20709
2024
-
[14]
Grounding image matching in 3D with MASt3R,
V. Leroy, Y. Cabon, and J. Revaud, “Grounding image matching in 3D with MASt3R,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2024, pp. 71-91
2024
-
[15]
VGGT: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, et al., “VGGT: Visual geometry grounded transformer,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 5294-5306
2025
-
[16]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Y. Wang, J. Zhou, H. Zhu, et al., “ π3: Permutation-equivariant visual geometry learning,” arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
K. Deng, Z. Ti, J. Xu, et al., “VGGT-Long: Chunk it, loop it, align it–pushing VGGT’s limits on kilometer-scale long RGB sequences,” arXiv preprint arXiv:2507.16443, 2025
-
[18]
arXiv preprint arXiv:2505.12549 (2025)
D. Maggio, H. Lim, and L. Carlone, “VGGT-SLAM: Dense RGB SLAM optimized on the SL(4) manifold,” arXiv preprint arXiv:2505.12549, 2025
-
[19]
Structure-from-motion revisited,
J. L. Schönberger and J.M. Frahm, “Structure-from-motion revisited,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 4104-4113
2016
-
[20]
Pixelwise view selection for unstructured multi-view stereo,
J. L. Schönberger, E. Zheng, J. M. Frahm, et al., “Pixelwise view selection for unstructured multi-view stereo,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2016, pp. 501-518
2016
-
[21]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” Int’l J. Comput. Vis. (IJCV), vol. 60, no. 2, pp. 91- 110, 2004
2004
-
[22]
Stereo processing by semiglobal matching and mutual information,
H. Hirschmuller, “Stereo processing by semiglobal matching and mutual information,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 30, no. 2, pp. 328-341, 2008
2008
-
[23]
Accurate, dense, and robust multiview stereopsis,
Y. Furukawa and J. Ponce, “Accurate, dense, and robust multiview stereopsis,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 32, no. 8, pp. 1362-1376, 2009
2009
-
[24]
MVSNet: Depth inference for unstructured multi-view stereo,
Y. Yao, Z. Luo, S. Li, et al., “MVSNet: Depth inference for unstructured multi-view stereo,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 767-783
2018
-
[25]
Recurrent MVSNet for high-resolution multi-view stereo depth inference,
Y. Yao, Z. Luo, S. Li, et al., “Recurrent MVSNet for high-resolution multi-view stereo depth inference,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 5525-5534
2019
-
[26]
Cascade cost volume for high- resolution multi-view stereo and stereo matching,
X. Gu, Z. Fan, S. Zhu, et al., “Cascade cost volume for high- resolution multi-view stereo and stereo matching,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 2495-2504
2020
-
[27]
PatchmatchNet: Learned multi-view patchmatch stereo,
F. Wang, S. Galliani, C. Vogel, et al., “PatchmatchNet: Learned multi-view patchmatch stereo,” in Proc. IEEE/CVF Conf. Com- put. Vis. Pattern Recognit. (CVPR), 2021, pp. 14194-14203
2021
-
[28]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, et al., “NeRF: Representing scenes as neural radiance fields for view synthesis,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2020, pp. 405-421
2020
-
[29]
Instant neural graphics primitives with a multiresolution hash encoding,
T. Müller, A. Evans, C. Schied, et al., “Instant neural graphics primitives with a multiresolution hash encoding,” ACM Trans. Graph. (TOG), vol. 41, no. 4, pp. 1-15, 2022
2022
-
[30]
Mip-NeRF: A multiscale representation for anti-aliasing neural radiance fields,
J. T. Barron, B. Mildenhall, M. Tancik, et al., “Mip-NeRF: A multiscale representation for anti-aliasing neural radiance fields,” in Proc. IEEE/CVF int’l Conf. Comput. Vis. (ICCV), 2021, pp. 5855-5864
2021
-
[31]
PixelNeRF: Neural radiance fields from one or few images,
A. Yu, V. Ye, M. Tancik, et al., “PixelNeRF: Neural radiance fields from one or few images,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 4578-4587
2021
-
[32]
IBRNet: Learning multi-view image-based rendering,
Q. Wang, Z. Wang, K. Genova, et al., “IBRNet: Learning multi-view image-based rendering,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 4690-4699
2021
-
[33]
MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo,
A. Chen, Z. Xu, F. Zhao, et al., “MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo,” in Proc. IEEE/CVF Int’l Conf. Comput. Vis. (ICCV), 2021, pp. 14124- 14133
2021
-
[34]
3D Gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimkühler, et al., “3D Gaussian splatting for real-time radiance field rendering,” ACM Trans. Graph. (TOG), vol. 42, no. 4, pp. 139:1-139:14, 2023
2023
-
[35]
MonoSLAM: Real-time single camera SLAM,
A. J. Davison, I. D. Reid, N. D. Molton, et al., “MonoSLAM: Real-time single camera SLAM,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 29, no. 6, pp. 1052-1067, 2007
2007
-
[36]
Parallel tracking and mapping for small AR workspaces,
G. Klein and D. Murray, “Parallel tracking and mapping for small AR workspaces,” in Proc. IEEE/ACM Int’l Symp. Mixed Augmented Reality (ISMAR), 2007, pp. 225-234
2007
-
[37]
S-PTAM: Stereo parallel tracking and mapping,
T. Pire, T. Fischer, G. Castro, et al., “S-PTAM: Stereo parallel tracking and mapping,” Robot. Auton. Syst. (RAS), vol. 93, pp. 27-42, 2017
2017
-
[38]
Large-scale direct SLAM with stereo cameras,
J. Engel, J. Stückler, and D. Cremers, “Large-scale direct SLAM with stereo cameras,” in Proc. IEEE/RSJ Int’l Conf. Intell. Robots Syst. (IROS), 2015, pp. 1935-1942
2015
-
[39]
DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras,
Z. Teed and J. Deng, “DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2021, pp. 16558-16569
2021
-
[40]
Deep patch visual odometry,
Z. Teed, L. Lipson, and J. Deng, “Deep patch visual odometry,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2023, pp. 39033-39051
2023
-
[41]
Deep patch visual SLAM,
L. Lipson, Z. Teed, and J. Deng, “Deep patch visual SLAM,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2024, pp. 424-440
2024
-
[42]
TartanVO: A generalizable learning-based VO,
W. Wang, Y. Hu, and S. Scherer, “TartanVO: A generalizable learning-based VO,” in Proc. Conf. Robot Learning (CoRL), 2021, pp. 1761-1772
2021
-
[43]
iMap: Implicit mapping and positioning in real-time,
E. Sucar, S. Liu, J. Ortiz, et al. “iMap: Implicit mapping and positioning in real-time,” in Proc. IEEE/CVF Int’l Conf. Computer Vis. (ICCV). 2021, pp. 6229-6238
2021
-
[44]
NICE-SLAM: Neural implicit scalable encoding for slam,
Z. Zhu, S. Peng, V. Larsson, et al., “NICE-SLAM: Neural implicit scalable encoding for slam,” in Proc. IEEE/CVF Conf. Computer Vis. Pattern Recognit. (CVPR), 2022, pp. 12786- 12796
2022
-
[45]
Loopy-SLAM: Dense neural SLAM with loop closures,
L. Liso, E. Sandström, V. Yugay, et al., “Loopy-SLAM: Dense neural SLAM with loop closures,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 20363-20373
2024
-
[46]
MNE-SLAM: Multi-agent neural SLAM for mobile robots,
T. Deng, G. Shen, C. Xun, et al., “MNE-SLAM: Multi-agent neural SLAM for mobile robots,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 1485-1494
2025
-
[47]
SplaTAM: Splat, track & map 3D Gaussians for dense RGB-D SLAM,
N. Keetha, J. Karhade, K. M. Jatavallabhula, et al., “SplaTAM: Splat, track & map 3D Gaussians for dense RGB-D SLAM,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 21357-21366
2024
-
[48]
GS-SLAM: Dense visual SLAM with 3D Gaussian splatting,
C. Yan, D. Qu, D. Xu, et al., “GS-SLAM: Dense visual SLAM with 3D Gaussian splatting,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 19595-19604
2024
-
[49]
Gaussian splat- ting SLAM,
H. Matsuki, R. Murai, P. H. J. Kelly, et al., “Gaussian splat- ting SLAM,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 18039-18048
2024
-
[50]
Fast3R: Towards 3D reconstruction of 1000+ images in one forward pass,
J. Yang, A. Sax, K. J. Liang, et al., “Fast3R: Towards 3D reconstruction of 1000+ images in one forward pass,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 21924-21935
2025
-
[51]
MUSt3R: Multi-view network for stereo 3D reconstruction,
Y. Cabon, L. Stoffl, L. Antsfeld, et al., “MUSt3R: Multi-view network for stereo 3D reconstruction,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 1050-1060
2025
-
[52]
Reloc-VGGT: Visual re-localization with geometry grounded Transformer,
T. Deng, W. Wu, K. Wu, et al., “Reloc-VGGT: Visual re-localization with geometry grounded Transformer,” arXiv preprint arXiv:2512.21883, 2025
-
[53]
UniPR-3D: Towards uni- versal visual place recognition with visual geometry grounded Transformer,
T. Deng, X. Chen, Z. Liu, et al., “UniPR-3D: Towards uni- versal visual place recognition with visual geometry grounded Transformer,” arXiv preprint arXiv:2512.21078, 2025
-
[54]
T. Deng, Y. Pan, S. Yuan, et al., “What is the best 3D scene representation for robotics? From geometric to foundation models,” arXiv preprint arXiv:2512.03422, 2025
-
[55]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. Müller, J. Schönberger, et al., “MapAnything: Universal feed-forward metric 3D reconstruction,” arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review arXiv 2025
-
[56]
3D reconstruction with spatial memory,
H. Wang and L. Agapito, “3D reconstruction with spatial memory,” in Proc. Int’l Conf. 3D Vision (3DV), 2025, pp. 78-89
2025
-
[57]
SLAM3R: Real-time dense scene reconstruction from monocular RGB videos,
Y. Liu, S. Dong, S. Wang, et al., “SLAM3R: Real-time dense scene reconstruction from monocular RGB videos,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 16651-16662
2025
-
[58]
MASt3R-SLAM: Real-time dense SLAM with 3D reconstruction priors,
R. Murai, E. Dexheimer, and A. J. Davison, “MASt3R-SLAM: Real-time dense SLAM with 3D reconstruction priors,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 16695-16705. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 19
2025
-
[59]
Continuous 3d per- ception model with persistent state,
Q. Wang, Y. Zhang, A. Holynski, et al. “Continuous 3d per- ception model with persistent state,” in Proc. Computer Vis. Pattern Recognit. (CVPR), 2025, pp. 10510-10522
2025
-
[60]
Good features to track,
J. Shi and C. Tomasi, “Good features to track,” in Proc. IEEE Conf. Computer Vis. Pattern Recognit. (CVPR), 1994, pp. 593- 600
1994
-
[61]
An iterative image registration technique with an application to stereo vision,
B. D. Lucas and T. Kanade, “An iterative image registration technique with an application to stereo vision,” in Proc. Int’l Joint Conf. Artif. Intell. (IJCAI), 1981, pp. 674-679
1981
-
[62]
Borglab/GTSAM,
F. Dellaert, and GTSAM Contributors, “Borglab/GTSAM,” https://github.com/borglab/gtsam, 2022
2022
-
[63]
Optimal transport aggregation for visual place recognition,
S. Izquierdo, J. Civera. “Optimal transport aggregation for visual place recognition,” in Proc. IEEE/CVF Conf. Computer Vis. Pattern Recognit. (CVPR), 2024, pp. 17658-17668
2024
-
[64]
Principal warps: thin-plate splines and the decomposition of deformations,
F. L. Bookstein, “Principal warps: thin-plate splines and the decomposition of deformations,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), vol. 11, no. 6, pp. 567-585, 1989
1989
-
[65]
Are we ready for autonomous driving? The KITTI vision benchmark suite,
A. Geiger, P. Lenz, R. Urtasun, “Are we ready for autonomous driving? The KITTI vision benchmark suite,” in Proc. IEEE Conf. Computer Vis. Pattern Recognit. (CVPR), 2012, pp. 3354- 3361
2012
-
[66]
KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,
Y. Liao, J. Xie, A. Geiger, “KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,” IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 2022, vol. 45, no. 3, pp. 3292-3310
2022
-
[67]
Argoverse: 3d tracking and forecasting with rich maps,
M. F. Chang, J. Lambert, P. Sangkloy, et al., “Argoverse: 3d tracking and forecasting with rich maps,” in Proc. IEEE/CVF Conf. Computer Vis. Pattern Recognit. (CVPR), 2019, pp. 8748- 8757. Tianjun Zhang received his B.Eng. and Ph.D. degree from the School of Software Engi- neering and the School of Computer Science and Technology, Tongji University, Shang...
2019
-
[68]
degree at the School of Electrical Engineering and Com- puter Science, The University of Queensland, Brisbane, Australia
He is now pursuing his Ph.D. degree at the School of Electrical Engineering and Com- puter Science, The University of Queensland, Brisbane, Australia. His research focuses on data-driven 3D reconstruction for real-world visual understanding. Tianchen Deng (Graduate Student Member, IEEE) received the B.Eng. degree in control science and engineering from Ha...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.