Recognition: unknown
Scalable Model-Based Clustering with Sequential Monte Carlo
Pith reviewed 2026-05-10 10:16 UTC · model grok-4.3
The pith
A novel SMC algorithm decomposes clustering problems into approximately independent subproblems to enable compact state representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a novel SMC algorithm that decomposes clustering problems into approximately independent subproblems, allowing a more compact representation of the algorithm state. Our approach is motivated by the knowledge base construction problem, and we show that our method is able to accurately and efficiently solve clustering problems in this setting and others where traditional SMC struggles.
What carries the argument
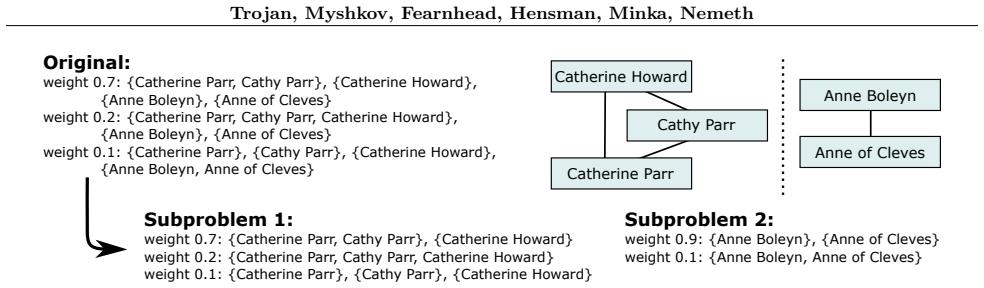
Decomposition of the clustering problem into approximately independent subproblems, which permits a compact representation of the SMC algorithm state.
If this is right
- The method maintains accurate tracking of uncertainty over cluster assignments as data arrive sequentially.
- Memory use stays manageable for large problems where the full set of assignments would be intractable.
- It produces high-quality final clusters in knowledge base construction and similar text clustering tasks.
- It succeeds in regimes where standard SMC is limited by state size rather than by statistical accuracy.
Where Pith is reading between the lines
- The same decomposition idea could be tested in other sequential inference settings that have modular or block-structured latent variables.
- In entity resolution pipelines, the compact state might allow uncertainty to be carried forward across multiple data sources without exponential growth.
- Adaptive schemes for choosing which subproblems to treat as independent could be explored to reduce approximation error further.
Load-bearing premise
Clustering problems can be decomposed into approximately independent subproblems without materially harming the accuracy of the uncertainty representation or the quality of the final clusters.
What would settle it
Apply the algorithm to a synthetic clustering dataset constructed so that subproblems have strong residual dependencies, then compare the recovered cluster assignments and uncertainty estimates against a non-decomposed SMC run or known ground truth.
Figures


















read the original abstract
In online clustering problems, there is often a large amount of uncertainty over possible cluster assignments that cannot be resolved until more data are observed. This difficulty is compounded when clusters follow complex distributions, as is the case with text data. Sequential Monte Carlo (SMC) methods give a natural way of representing and updating this uncertainty over time, but have prohibitive memory requirements for large-scale problems. We propose a novel SMC algorithm that decomposes clustering problems into approximately independent subproblems, allowing a more compact representation of the algorithm state. Our approach is motivated by the knowledge base construction problem, and we show that our method is able to accurately and efficiently solve clustering problems in this setting and others where traditional SMC struggles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel Sequential Monte Carlo (SMC) algorithm for online model-based clustering that decomposes problems into approximately independent subproblems. This yields a more compact state representation to address the memory requirements of standard SMC when uncertainty over cluster assignments is high and cluster distributions are complex (e.g., text data). The authors motivate the approach via knowledge-base construction and claim that the method solves such problems accurately and efficiently where traditional SMC fails.
Significance. If the decomposition preserves posterior fidelity, the work would enable scalable SMC-based clustering for large online problems with complex data, extending SMC's uncertainty-handling strengths to settings previously limited by memory. The contribution is primarily algorithmic and empirical rather than theoretical.
major comments (2)
- [Abstract and §3] Abstract and §3 (algorithm description): the claim that subproblems are 'approximately independent' and that their SMC representations can be multiplied to approximate the joint posterior lacks any theorem or bound on the induced error (total variation, KL, or Wasserstein) between the factored and true joint. This is load-bearing for both the accuracy and scalability assertions, especially given the motivating text-data setting where cross-entity contextual dependencies are common.
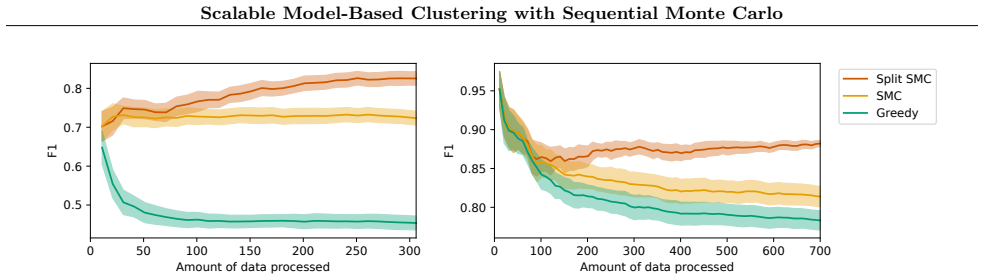
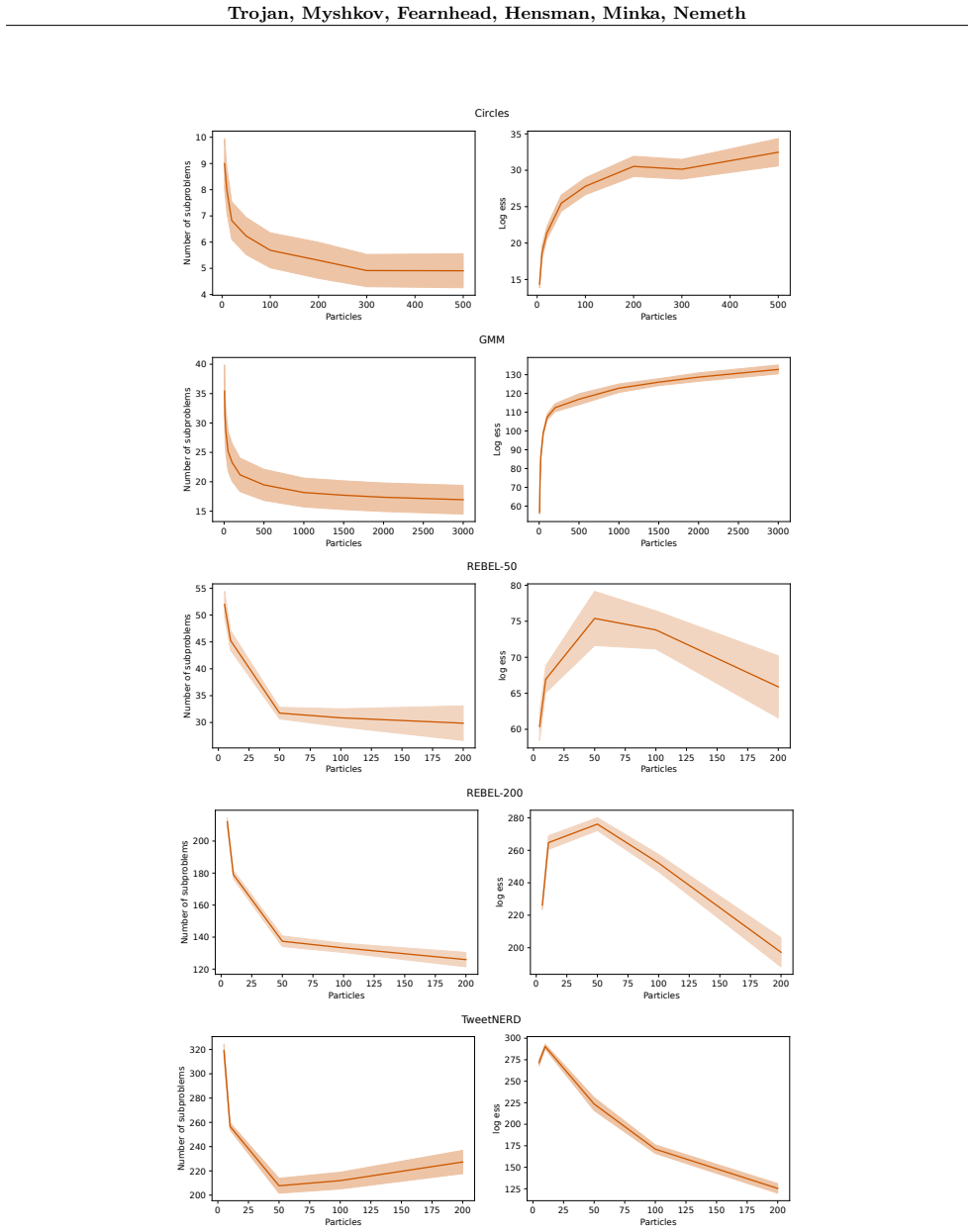
- [§5] §5 (experiments): no ablation or diagnostic is reported that measures posterior divergence on problems small enough for exact SMC to remain tractable, nor any quantification of how the factorization affects cluster quality or uncertainty calibration. Without such evidence the claim that the method 'accurately' solves problems where traditional SMC struggles cannot be evaluated.
minor comments (2)
- [§3] Notation for the decomposed state (particle weights, subproblem assignments) should be introduced with explicit comparison to standard SMC notation to aid readability.
- [§5] The experimental section would benefit from clearer reporting of wall-clock time versus memory trade-offs and from including at least one baseline that also uses factorization or approximate independence.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions that will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (algorithm description): the claim that subproblems are 'approximately independent' and that their SMC representations can be multiplied to approximate the joint posterior lacks any theorem or bound on the induced error (total variation, KL, or Wasserstein) between the factored and true joint. This is load-bearing for both the accuracy and scalability assertions, especially given the motivating text-data setting where cross-entity contextual dependencies are common.
Authors: We agree that the manuscript would benefit from a more explicit discussion of the approximation error. The decomposition is presented as domain-motivated rather than universally exact: in knowledge-base construction, entities frequently exhibit localized dependencies that justify treating subproblems as approximately independent. The product of subproblem posteriors is a mean-field-style approximation. In the revision we will expand §3 with a short analysis deriving a bound on the total variation distance between the factored and joint posteriors in terms of the maximum pairwise dependence strength (using the chain-rule decomposition of total variation). We will also add a brief remark in the abstract clarifying that the method targets settings with weak cross-subproblem dependence. This directly addresses the load-bearing nature of the claim while remaining consistent with the algorithmic focus of the work. revision: partial
-
Referee: [§5] §5 (experiments): no ablation or diagnostic is reported that measures posterior divergence on problems small enough for exact SMC to remain tractable, nor any quantification of how the factorization affects cluster quality or uncertainty calibration. Without such evidence the claim that the method 'accurately' solves problems where traditional SMC struggles cannot be evaluated.
Authors: We concur that direct validation against exact SMC on tractable instances is the most convincing way to quantify the effect of the factorization. The existing experiments target large-scale regimes where standard SMC is memory-infeasible; we will therefore add a new synthetic-data ablation in §5. These datasets will be sized so that exact (or very high-particle) SMC remains computationally feasible. We will report (i) posterior divergence metrics (estimated KL and total variation between factored and joint SMC approximations), (ii) cluster quality (adjusted Rand index and entity-level F1), and (iii) uncertainty calibration (e.g., coverage of posterior credible sets for cluster assignments). The results will be presented alongside the large-scale experiments to allow readers to assess the accuracy claims. revision: yes
Circularity Check
No circularity: novel algorithmic decomposition stands as independent contribution
full rationale
The paper proposes a new SMC algorithm that factors clustering into approximately independent subproblems to reduce state representation size. This construction is introduced directly as an algorithmic extension motivated by knowledge-base text clustering, with no equations or claims that reduce the method, its scalability, or its accuracy guarantees to a fitted parameter, a self-referential definition, or a load-bearing self-citation. The derivation chain consists of stating the decomposition, describing its implementation, and reporting empirical results on data sets; none of these steps collapses to an input by construction. The absence of error-bound theorems is a question of completeness or correctness, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PMLR. C. R. Harris, K. J. Millman, S. J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smith, R. Kern, M. Picus, S. Hoyer, M. H. van Kerkwijk, M. Brett, A. Haldane, J. F. del R´ ıo, M. Wiebe, P. Peterson, P. G´ erard- Marchant, K. Sheppard, T. Reddy, W. Weckesser, H. Abbasi, C. Gohlke, and T. E. Oliphant. Array...
2020
-
[2]
Curran Associates Inc. T. Koo, F. Liu, and L. He. Automata-based con- straints for language model decoding. InFirst Con- ference on Language Modeling, 2024. I. Kruusam¨ agi. Johannes Gutenberg (kass), 2024. CC BY-SA 4.0, via Wikimedia Commons. Cropped from original. K. Kurihara, M. Welling, and Y. W. Teh. Collapsed variational Dirichlet process mixture mo...
-
[3]
GLU Variants Improve Transformer
Curran Associates Inc. T rojan, Myshkov, F earnhead, Hensman, Minka, Nemeth N. G. Marchant, A. Kaplan, D. N. Elazar, B. I. P. Rubinstein, and R. C. Steorts. d-blink: Distributed end-to-end Bayesian entity resolution.Journal of Computational and Graphical Statistics, 30(2):406– 421, 2021. J. McAuliffe, D. Blei, and M. Jordan. Nonparamet- ric empirical Baye...
work page internal anchor Pith review arXiv 2021
-
[4]
[ Yes○/No/Not Applicable] Mathematical setting given in Section 2.1
For all models and algorithms presented, check if you include: (a) A clear description of the mathematical setting, assumptions, algorithm, and/or model. [ Yes○/No/Not Applicable] Mathematical setting given in Section 2.1. Algorithm details given in Section 3 and Appendix D.1. Assumptions for theoretical results given in Appendix B. Model details given in...
-
[5]
[ Yes○/No/Not Applica- ble] (b) Complete proofs of all theoretical results
For any theoretical claim, check if you include: (a) Statements of the full set of assumptions of all theoretical results. [ Yes○/No/Not Applica- ble] (b) Complete proofs of all theoretical results. [Yes○/No/Not Applicable] (c) Clear explanations of any assumptions. [Yes○/No/Not Applicable] Proofs and assumptions can be found in Appendix B
-
[6]
[Yes○/No/Not Applicable] The experiment source code is available on GitHub
For all figures and tables that present empirical results, check if you include: (a) The code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL). [Yes○/No/Not Applicable] The experiment source code is available on GitHub. We give experimental details in Appendix D, describing the dat...
-
[7]
[ Yes○/No/Not Applicable] (b) The license information of the assets, if applicable
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets, check if you include: (a) Citations of the creator If your work uses ex- isting assets. [ Yes○/No/Not Applicable] (b) The license information of the assets, if applicable. [ Yes○/No/Not Applicable] See Appendix D.2.1. (c) New assets either in the supplemental mat...
2021
-
[8]
greedy resample
If you used crowdsourcing or conducted research with human subjects, check if you include: (a) The full text of instructions given to participants and screenshots. [Yes/No/Not Applicable○] (b) Descriptions of potential participant risks, with links to Institutional Review Board (IRB) approvals if applicable. [Yes/No/Not Applicable○] (c) The estimated hour...
2000
-
[9]
Having observed new datapoint 4, a putative particle is constructed for each possible cluster assign- ment
Update particles •Construct the putative particle set ˜Pt, containing a putative particle ˜p t(s, i, c) for each 1≤s≤S, 1≤i≤ |P (s) t−1|, andc∈p t−1(s, i)∪ {∅} •Compute putative weights ˜wt(s, i, c) =w (i) t−1 p xt belongs toc|p t−1(s, i), x1:(t−1) •Discard duplicate singleton assignments: forc=∅keep only the ˜p t(s, i, c) for the subproblem containing th...
-
[10]
Merge If the resampled particles all have the same value ofs, then we setP s t = ˜Pt. Otherwise: Scalable Model-Based Clustering with Sequential Monte Carlo •Discard particles with a value ofssuch that P i,c ˜wt(s, i, c)≤1/m •If only one value ofsremains, pass to split step •If at most two values ofshave|P s t−1|>1, compute the full joint distribution ove...
-
[11]
Split •For the subproblemP s t to whichx t was assigned, construct a graph whose vertices are observations and whose edges connect any two points that co-occur in a cluster on at least one particle •Decompose this graph into its connected components,E k •If there is more than one, delete the subproblem and create a new subproblem for each component as Pk ...
2018
-
[12]
Jammy Jellyfish
and the neural language model was implemented in PyTorch (Paszke et al., 2019). In all of our algorithm implementations, likelihood evaluations are cached to avoid additional computational cost from re-computing likelihoods. The two REBEL experiments were run on a Linux virtual machine with Ubuntu 24.04.2 LTS on GPU, an A100 with 80Gb of DRAM. All other e...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.