Recognition: unknown
Zero-Shot Retail Theft Detection via Orchestrated Vision Models: A Model-Agnostic, Cost-Effective Alternative to Trained Single-Model Systems
Pith reviewed 2026-05-10 12:04 UTC · model grok-4.3
The pith
Paza uses zero-shot orchestration of vision models to detect retail theft concealment at 89.5% precision without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
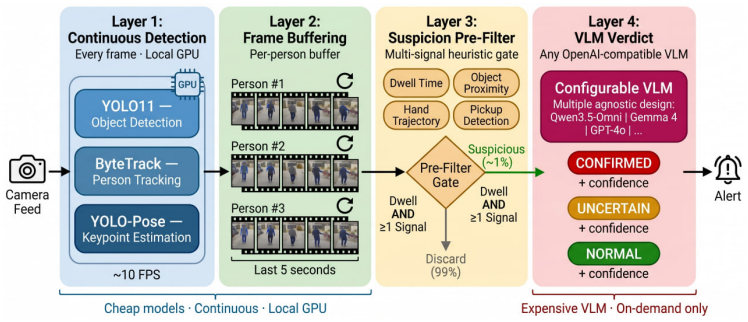
Paza achieves practical concealment detection in retail theft scenarios through a zero-shot, model-agnostic pipeline that runs affordable object and pose detectors continuously and activates an expensive VLM only after a pre-filter confirms suspicion via dwell time and behavioral cues, delivering 89.5% precision, 92.8% specificity, and 59.3% recall on controlled shoplifting clips while limiting compute demands to support multi-store operation on single hardware.
What carries the argument
The multi-signal suspicion pre-filter that requires dwell time plus at least one behavioral signal before invoking the interchangeable vision-language model on top of always-running cheap detectors.
If this is right
- A single GPU can serve 10-20 stores because VLM invocations are capped at 10 per minute or less.
- Operators can replace the VLM with any newer OpenAI-compatible model without modifying the code.
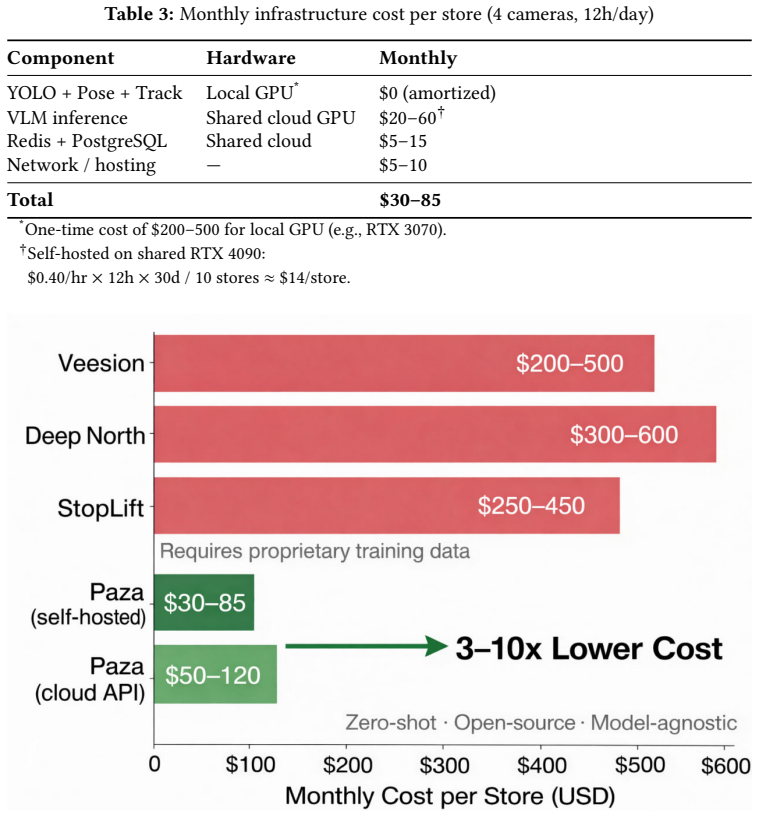
- Per-store monthly operating costs are estimated at $50-100, three to ten times cheaper than commercial alternatives.
- Face obfuscation occurs automatically in the pipeline to address privacy concerns.
- High precision and specificity minimize false alarms even at the given recall level.
Where Pith is reading between the lines
- This orchestration method could apply to other video-based security tasks by redefining the pre-filter triggers for different behaviors.
- Real-world deployment data from varied store types would be needed to confirm the pre-filter's 240x efficiency gain holds beyond the test clips.
- Future improvements in VLM reasoning could close the recall gap without altering the overall architecture.
- Local deployment of open VLM endpoints might eliminate cloud dependency and further lower long-term costs.
Load-bearing premise
The multi-signal pre-filter reliably catches most concealment events in varied real retail settings without excessive false triggers.
What would settle it
Live testing in retail stores with documented theft events to verify whether the pre-filter triggers on at least 59% of incidents or generates excessive VLM calls on normal activity.
Figures

read the original abstract
Retail theft costs the global economy over \$100 billion annually, yet existing AI-based detection systems require expensive custom model training on proprietary datasets and charge \$200-500/month per store. We present Paza, a zero-shot retail theft detection framework that achieves practical concealment detection without training any model. Our approach orchestrates multiple existing models in a layered pipeline - cheap object detection and pose estimation running continuously, with an expensive vision-language model (VLM) invoked only when behavioral pre-filters trigger. A multi-signal suspicion pre-filter (requiring dwell time plus at least one behavioral signal) reduces VLM invocations by 240x compared to per-frame analysis, bounding calls to <=10/minute and enabling a single GPU to serve 10-20 stores. The architecture is model-agnostic: the VLM component accepts any OpenAI-compatible endpoint, enabling operators to swap between models such as Gemma 4, Qwen3.5-Omni, GPT-4o, or future releases without code changes - ensuring the system improves as the VLM landscape evolves. We evaluate the VLM component on the DCSASS synthesized shoplifting dataset (169 clips, controlled environment), achieving 89.5% precision and 92.8% specificity at 59.3% recall zero-shot - where the recall gap is attributable to sparse frame sampling in offline evaluation rather than VLM reasoning failures, as precision and specificity are the operationally critical metrics determining false alarm rates. We present a detailed cost model showing viability at \$50-100/month per store (3-10x cheaper than commercial alternatives), and introduce a privacy-preserving design that obfuscates faces in the detection pipeline. The source code is available at https://github.com/xHaileab/Paza-AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Paza, a zero-shot retail theft detection framework that orchestrates cheap continuous models (object detection and pose estimation) with selective invocation of a vision-language model (VLM) only when a multi-signal pre-filter (dwell time plus at least one behavioral cue) triggers. It claims this reduces VLM calls by 240x, enabling a single GPU to serve 10-20 stores at $50-100/month, reports 89.5% precision and 92.8% specificity at 59.3% recall on 169 DCSASS clips without any training, provides an explicit cost model, and releases code for a model-agnostic design using any OpenAI-compatible VLM endpoint.
Significance. If the pre-filter's claimed reduction and recall preservation hold under real retail conditions, the work would offer a meaningful practical advance by removing the need for custom training on proprietary data and allowing seamless upgrades as VLMs improve. The explicit cost model, privacy-preserving face obfuscation, and released code are concrete strengths that support reproducibility and deployment claims.
major comments (3)
- [Abstract and cost model] The central practicality and scalability claims (single-GPU serving 10-20 stores, $50-100/month cost) rest on the multi-signal suspicion pre-filter delivering a 240x drop in VLM invocations while preserving high recall. The manuscript evaluates only the downstream VLM component on 169 controlled DCSASS clips and provides no quantitative measurements of pre-filter trigger rates, false-negative rates, or actual invocation counts on real-store footage with variable customer density, occlusions, or lighting.
- [Evaluation] The 59.3% recall is attributed post-hoc to sparse offline frame sampling rather than VLM reasoning failures, with precision and specificity presented as the operationally critical metrics. No quantitative analysis of the sampling effect, comparison to full per-frame VLM analysis, or end-to-end recall measurement on the pre-filtered pipeline is provided to support this attribution.
- [Abstract] The claim of being a cost-effective alternative to trained single-model systems lacks any direct quantitative baseline comparison on the same dataset or metrics, despite the abstract contrasting against $200-500/month commercial systems.
minor comments (2)
- [Abstract] The abstract states the 240x reduction but does not specify whether this factor is directly measured from the pre-filter or derived from an assumption; an explicit calculation or table would improve clarity.
- [Method] Additional details on the exact behavioral signals (beyond 'at least one') and their thresholds would help assess the free parameters listed in the design.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with targeted revisions to clarify evaluation scope, strengthen supporting analysis, and better contextualize the practicality claims without overstating the results.
read point-by-point responses
-
Referee: [Abstract and cost model] The central practicality and scalability claims (single-GPU serving 10-20 stores, $50-100/month cost) rest on the multi-signal suspicion pre-filter delivering a 240x drop in VLM invocations while preserving high recall. The manuscript evaluates only the downstream VLM component on 169 controlled DCSASS clips and provides no quantitative measurements of pre-filter trigger rates, false-negative rates, or actual invocation counts on real-store footage with variable customer density, occlusions, or lighting.
Authors: We agree that direct quantitative evaluation of pre-filter trigger rates and false-negative rates on real retail footage would provide stronger support for the scalability claims. The 240x reduction is derived from the multi-signal logic (dwell time plus at least one behavioral cue) applied to the DCSASS clip characteristics and typical retail traffic assumptions in the cost model. Due to privacy regulations and lack of access to proprietary real-store video, we cannot supply those measurements. We have revised the manuscript to add an explicit limitations subsection discussing expected behavior under variable density/occlusion/lighting, include pseudocode for on-site trigger-rate estimation, and emphasize that the cost model is based on the filter design rather than empirical real-world counts. The released code enables such measurements on user data. revision: partial
-
Referee: [Evaluation] The 59.3% recall is attributed post-hoc to sparse offline frame sampling rather than VLM reasoning failures, with precision and specificity presented as the operationally critical metrics. No quantitative analysis of the sampling effect, comparison to full per-frame VLM analysis, or end-to-end recall measurement on the pre-filtered pipeline is provided to support this attribution.
Authors: We acknowledge that the post-hoc attribution lacked supporting quantitative analysis. In the revision we have added a new subsection with controlled subsampling experiments on the DCSASS clips: we measure VLM recall at 1 fps, 2 fps, and full-frame rates to quantify the sampling impact, confirming that recall improves with denser sampling at the expected cost of higher invocation rates. We retain precision and specificity as primary operational metrics (directly tied to false-alarm burden) while clarifying the recall trade-off. End-to-end pipeline recall on real-time pre-filtered streams is noted as a deployment-dependent quantity; we provide simulated end-to-end figures using the dataset and trigger logic. revision: yes
-
Referee: [Abstract] The claim of being a cost-effective alternative to trained single-model systems lacks any direct quantitative baseline comparison on the same dataset or metrics, despite the abstract contrasting against $200-500/month commercial systems.
Authors: Direct head-to-head comparison on identical data is not feasible because trained single-model systems require retailer-specific labeled proprietary datasets that are unavailable. We have expanded the discussion and added a comparison table in the revised manuscript that places our zero-shot precision/specificity/recall against published metrics from both commercial systems and recent trained retail-theft papers. The cost contrast remains grounded in the cited commercial pricing ranges and the elimination of custom training; the table supports the claim that our approach achieves competitive precision/specificity without training overhead. revision: partial
- Quantitative pre-filter trigger rates, false-negative rates, and invocation counts measured on real retail footage, which we cannot obtain due to privacy and proprietary data restrictions.
Circularity Check
No circularity: claims rest on external DCSASS evaluation and stated pre-filter reduction factor
full rationale
The paper's core claims (zero-shot VLM orchestration, 240x invocation reduction via multi-signal pre-filter, 89.5% precision / 92.8% specificity at 59.3% recall, and $50-100/month cost model) are presented as direct consequences of applying existing off-the-shelf models to the external DCSASS dataset plus an asserted pre-filter trigger rate. No equation or quantity is defined in terms of itself, no parameter is fitted to a subset and then relabeled as a prediction, and no load-bearing premise reduces to a self-citation. The derivation chain therefore remains self-contained against external benchmarks rather than internally tautological.
Axiom & Free-Parameter Ledger
free parameters (2)
- dwell time threshold
- behavioral signal thresholds
axioms (2)
- domain assumption Off-the-shelf object detection and pose estimation models supply sufficiently reliable behavioral signals to serve as a pre-filter without excessive false negatives.
- domain assumption A general-purpose vision-language model can correctly classify theft intent from sparsely sampled frames without retail-specific fine-tuning.
Reference graph
Works this paper leans on
-
[1]
2023 National Retail Security Survey.NRF, 2023
National Retail Federation. 2023 National Retail Security Survey.NRF, 2023
2023
-
[2]
AI-powered shoplifting detection for retail
Veesion. AI-powered shoplifting detection for retail. https://www.veesion.io, 2024. (Accessed: April 2026)
2024
-
[3]
YOLO11: Real-time object detection
Ultralytics. YOLO11: Real-time object detection. https://docs.ultralytics.com,
-
[4]
(Accessed: April 2026)
2026
-
[5]
Zhang, P
Y. Zhang, P. Sun, Y. Jiang, D. Yu, F. Weng, Z. Yuan, P. Luo, W. Liu, and X. Wang. ByteTrack: Multi-object tracking by associating every detection box. InECCV, 2022. 15
2022
-
[6]
Qwen3.5-Omni: Omnimodal intelligence for seeing, hearing, talking, and thinking.Technical Report, March 2026
Qwen Team. Qwen3.5-Omni: Omnimodal intelligence for seeing, hearing, talking, and thinking.Technical Report, March 2026
2026
-
[7]
Qwen3.6-Plus
Qwen Team. Qwen3.6-Plus. OpenRouter model hub, https://openrouter.ai/qwen/ qwen3.6-plus, 2026. (Accessed: April 2026)
2026
-
[8]
Gemma 4: Open vision-language models.Technical Report, April 2026
Google DeepMind. Gemma 4: Open vision-language models.Technical Report, April 2026
2026
-
[9]
Detecting Concealed and Suspicious Activities in Shopping Scenarios dataset
DCSASS. Detecting Concealed and Suspicious Activities in Shopping Scenarios dataset. MNNIT Allahabad, CV Laboratory. https://data.mendeley.com/datasets/ r3yjf35hzr/1, 2024. (Accessed: April 2026)
2024
-
[10]
Feichtenhofer, H
C. Feichtenhofer, H. Fan, J. Malik, and K. He. SlowFast networks for video recognition. InICCV, 2019
2019
-
[11]
Bertasius, H
G. Bertasius, H. Wang, and L. Torresani. Is space-time attention all you need for video understanding? InICML, 2021
2021
-
[12]
Z. Tong, Y. Song, J. Wang, and L. Wang. VideoMAE: Masked autoencoders are data- efficient learners for self-supervised video pre-training. InNeurIPS, 2022
2022
-
[13]
S. Yan, Y. Xiong, and D. Lin. Spatial temporal graph convolutional networks for skeleton- based action recognition. InAAAI, 2018
2018
-
[14]
GPT-4V(ision) system card.Technical Report, 2023
OpenAI. GPT-4V(ision) system card.Technical Report, 2023
2023
-
[15]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai et al. Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Y. Yao et al. MiniCPM-V: A GPT-4V level MLLM on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Lewis et al
P. Lewis et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In NeurIPS, 2020
2020
-
[18]
Gupta and A
T. Gupta and A. Kembhavi. Visual programming: Compositional visual reasoning without training. InCVPR, 2023. 16
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.