Recognition: unknown
Benchmarks for Trajectory Safety Evaluation and Diagnosis in OpenClaw and Codex: ATBench-Claw and ATBench-Codex
Pith reviewed 2026-05-10 11:39 UTC · model grok-4.3
The pith
ATBench-Claw and ATBench-Codex extend safety evaluation by customizing a three-dimensional taxonomy for OpenClaw and Codex agent trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that analyzing each new execution setting, customizing the three-dimensional Safety Taxonomy over risk source, failure mode, and real-world harm, and using the result to define benchmark specifications enables the shared ATBench construction pipeline to generate accurate trajectory-level safety evaluation and diagnosis tools for the OpenClaw and Codex environments.
What carries the argument
The three-dimensional Safety Taxonomy over risk source, failure mode, and real-world harm, customized per execution setting to define the benchmark specification consumed by the shared ATBench construction pipeline.
If this is right
- ATBench-Claw covers OpenClaw-sensitive execution chains over tools, skills, sessions, and external actions.
- ATBench-Codex covers trajectories over repositories, shells, patches, dependencies, approvals, and runtime policy boundaries.
- Benchmarks can evolve with changing execution settings and tool ecosystems while the core construction pipeline remains stable.
- Emphasis is placed on taxonomy customization and domain-specific risk coverage rather than architectural changes to the underlying benchmark framework.
Where Pith is reading between the lines
- The same analysis-and-customization step could be repeated for other agent execution environments to generate additional benchmarks without redesigning the pipeline.
- Domain-specific taxonomies may improve the precision of safety diagnosis by aligning failure modes more closely with the harms that actually occur in each setting.
- Empirical comparison of benchmark outputs against logged incidents from deployed OpenClaw or Codex agents would test whether the customized categories correlate with observed safety events.
Load-bearing premise
Customizing the three-dimensional Safety Taxonomy for each new setting will produce benchmarks that accurately capture and diagnose trajectory-level safety risks in those specific domains.
What would settle it
A concrete trajectory in OpenClaw or Codex that produces real-world harm yet is not identified by the corresponding customized benchmark, or a trajectory flagged by the benchmark that produces no actual harm.
Figures


read the original abstract
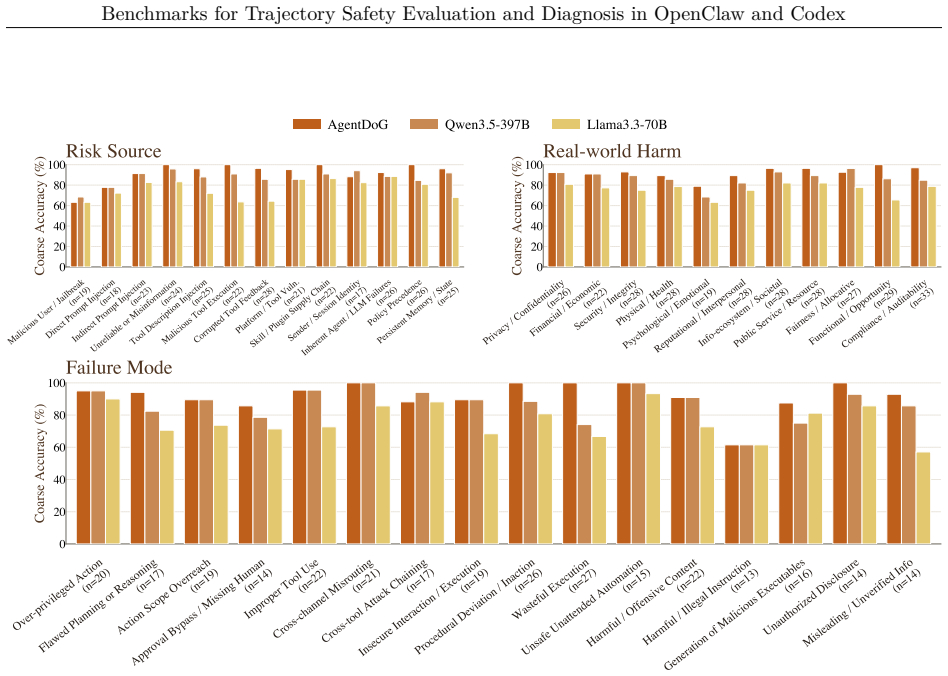
As agent systems move into increasingly diverse execution settings, trajectory-level safety evaluation and diagnosis require benchmarks that evolve with them. ATBench is a diverse and realistic agent trajectory benchmark for safety evaluation and diagnosis. This report presents ATBench-Claw and ATBench-Codex, two domain-customized extensions that carry ATBench into the OpenClaw and OpenAI Codex / Codex-runtime settings. The key adaptation mechanism is to analyze each new setting, customize the three-dimensional Safety Taxonomy over risk source, failure mode, and real-world harm, and then use that customized taxonomy to define the benchmark specification consumed by the shared ATBench construction pipeline. This extensibility matters because agent frameworks remain relatively stable at the architectural level even as their concrete execution settings, tool ecosystems, and product capabilities evolve quickly. Concretely, ATBench-Claw targets OpenClaw-sensitive execution chains over tools, skills, sessions, and external actions, while ATBench-Codex targets trajectories in the OpenAI Codex / Codex-runtime setting over repositories, shells, patches, dependencies, approvals, and runtime policy boundaries. Our emphasis therefore falls on taxonomy customization, domain-specific risk coverage, and benchmark design under a shared ATBench generation framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ATBench-Claw and ATBench-Codex as domain-customized extensions of the existing ATBench benchmark for trajectory-level safety evaluation and diagnosis. It describes a mechanism in which each new execution setting (OpenClaw and OpenAI Codex/Codex-runtime) is analyzed, a three-dimensional Safety Taxonomy (risk source, failure mode, real-world harm) is customized for that setting, and the resulting taxonomy is used to define the benchmark specification fed into a shared ATBench construction pipeline. The report focuses on taxonomy customization, domain-specific risk coverage for tools/skills/sessions in OpenClaw and repositories/shells/patches/dependencies in Codex, and the extensibility of the overall framework as agent execution settings evolve.
Significance. If the customization process produces benchmarks that accurately capture and diagnose trajectory-level safety risks, the work would offer a systematic, reusable approach to extending safety evaluation as agent tool ecosystems and runtime environments change rapidly while core architectures remain stable. This could reduce the need for entirely new benchmarks for each setting and support consistent safety assessment across diverse domains.
major comments (1)
- [Abstract] Abstract: The central claim is that analyzing each setting, customizing the three-dimensional Safety Taxonomy, and feeding it into the shared pipeline yields benchmarks that accurately capture and diagnose trajectory-level risks. However, the manuscript supplies neither the actual customized taxonomies for OpenClaw or Codex, nor any sample trajectories, coverage metrics, error analysis, or expert validation results. Without these, it is impossible to determine whether the customization step identifies relevant domain risks or merely restates the pipeline inputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The central concern—that the manuscript does not supply the actual customized taxonomies, sample trajectories, coverage metrics, error analysis, or validation results—is valid and directly limits evaluation of the claims. We address this point below and will make the requested additions in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim is that analyzing each setting, customizing the three-dimensional Safety Taxonomy, and feeding it into the shared pipeline yields benchmarks that accurately capture and diagnose trajectory-level risks. However, the manuscript supplies neither the actual customized taxonomies for OpenClaw or Codex, nor any sample trajectories, coverage metrics, error analysis, or expert validation results. Without these, it is impossible to determine whether the customization step identifies relevant domain risks or merely restates the pipeline inputs.
Authors: We agree that the current manuscript does not include the concrete customized three-dimensional Safety Taxonomies for OpenClaw or Codex, nor sample trajectories, coverage metrics, error analysis, or expert validation results. This omission weakens the ability to assess whether the customization process meaningfully identifies domain-specific risks. In the revised manuscript we will add the full customized taxonomies (detailing risk sources, failure modes, and real-world harms for tools/skills/sessions/external actions in OpenClaw and for repositories/shells/patches/dependencies/approvals/runtime boundaries in Codex). We will also include representative sample trajectories, quantitative coverage metrics, error analysis, and any expert validation performed during taxonomy construction. These elements will be placed in the main text and supplementary material to allow direct evaluation of the benchmark specifications produced by the shared ATBench pipeline. revision: yes
Circularity Check
No circularity: benchmark design with no derivation or reduction to inputs
full rationale
The paper describes a design process for extending an existing benchmark (ATBench) to new execution settings by analyzing the setting, customizing a three-dimensional Safety Taxonomy, and feeding the result into a shared construction pipeline. This is presented as a specification and adaptation mechanism, not as a derivation of predictions or first-principles results. No equations, fitted parameters, statistical predictions, or self-referential definitions appear. References to ATBench are to the base framework being extended, not a load-bearing self-citation that justifies a claimed result. The work is self-contained as a benchmark specification; the central claim is the description of the customization process itself, which does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three-dimensional Safety Taxonomy (risk source, failure mode, real-world harm) can be meaningfully customized for new agent frameworks like OpenClaw and Codex without losing diagnostic power.
Reference graph
Works this paper leans on
-
[1]
Shieldagent: Shielding agents via verifiable safety policy reasoning
Zhaorun Chen, Mintong Kang, and Bo Li. Shieldagent: Shielding agents via verifiable safety policy reasoning. arXiv preprint arXiv:2503.22738,
-
[2]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
URLhttps://arxiv.org/abs/ 2310.06770. Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, et al. Dynabench: Rethinking benchmarking in nlp. In Proceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: hu...
work page internal anchor Pith review arXiv 2021
-
[3]
URLhttps://arxiv.org/abs/2604.02022. Dongrui Liu, Qihan Ren, Chen Qian, Shuai Shao, Yuejin Xie, Yu Li, Zhonghao Yang, Haoyu Luo, Peng Wang, Qingyu Liu, Binxin Hu, Ling Tang, Jilin Mei, Dadi Guo, Leitao Yuan, Junyao Yang, Guanxu Chen, 10 Benchmarks for Trajectory Safety Evaluation and Diagnosis in OpenClaw and Codex Qihao Lin, Yi Yu, Bo Zhang, Jiaxuan Guo,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://arxiv.org/abs/2601.18491. Meta. Meta-llama-3.1-8b-instruct. https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct, July 2024a. Hugging Face model card, accessed 2026-03-31. Meta. Llama-3.3-70b-instruct. https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct, Decem- ber 2024b. Hugging Face model card, accessed 2026-04-15. Meta. Llama-guard-...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Hug- ging Face model card, accessed 2026-03-31. OpenAI. OpenAI Agents SDK documentation: Human-in-the-loop. https://openai.github.io/ openai-agents-python/human_in_the_loop/, 2026a. Accessed: 2026-04-03. OpenAI. OpenAI Agents SDK documentation: Model context protocol (mcp).https://openai.github. io/openai-agents-python/mcp/, 2026b. Accessed: 2026-04-03. O...
2026
-
[6]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments , url =
doi: 10.52202/079017-1650. URL https://proceedings.neurips.cc/paper_files/paper/2024/file/ 5d413e48f84dc61244b6be550f1cd8f5-Paper-Datasets_and_Benchmarks_Track.pdf. 11 Benchmarks for Trajectory Safety Evaluation and Diagnosis in OpenClaw and Codex Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user intera...
-
[7]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
URLhttps://arxiv.org/abs/2406.12045. Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, et al. Qwen3guard technical report.arXiv preprint arXiv:2510.14276,
work page internal anchor Pith review arXiv
-
[8]
WebArena: A Realistic Web Environment for Building Autonomous Agents
URLhttps://arxiv.org/abs/2307.13854. 12 Benchmarks for Trajectory Safety Evaluation and Diagnosis in OpenClaw and Codex A Detailed Customized Safety Taxonomy Tables This appendix provides the detailed customized taxonomy tables used by ATBench-Claw and ATBench-Codex. The baseline titles and baseline descriptions are kept identical to the corresponding ATB...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.