Recognition: unknown
Schema Key Wording as an Instruction Channel in Structured Generation under Constrained Decoding
Pith reviewed 2026-05-10 11:10 UTC · model grok-4.3
The pith
Schema key wording functions as an implicit instruction channel that can substantially alter generation accuracy under constrained decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate structured generation under constrained decoding as a multi-channel instruction problem in which task signals may be placed in the prompt, the schema keys, or both. A projection-aware analysis demonstrates that a CoT-style key improves performance only when its semantic gain exceeds the distortion introduced by grammar-constrained projection. On mathematical reasoning benchmarks, altering only schema-key wording produces substantial accuracy changes while the prompt, model, output structure, and decoding setup remain fixed; Qwen models benefit more from schema-level instructions while LLaMA models rely more on prompt-level guidance, and the two channels interact non-additively.
What carries the argument
Schema keys serving as an implicit instruction channel, whose tokens enter the autoregressive context and deliver task signals in addition to enforcing output structure.
If this is right
- Task accuracy on reasoning benchmarks can be improved or reduced by rewording schema keys alone.
- Different models exhibit distinct preferences for receiving instructions via schema keys versus the main prompt.
- The benefit of semantically rich keys such as CoT suggestions is conditional on semantic gain exceeding projection distortion.
- Schema design must be treated as an integral part of instruction specification rather than solely output formatting.
Where Pith is reading between the lines
- Practitioners using constrained decoding should systematically test alternative key wordings when optimizing for reasoning tasks.
- The non-additive interaction implies that prompt and schema instructions cannot be optimized independently and require joint tuning.
- The multi-channel view may apply to other structured output formats where constraint tokens also appear in context.
Load-bearing premise
Observed accuracy differences arise from the semantic instructional content of the schema keys rather than from incidental effects of the constrained decoding algorithm or model-specific tokenization biases.
What would settle it
An experiment in which schema keys are reworded to preserve exact semantic meaning through synonyms yet produce no accuracy change on the same benchmarks and models would falsify the claim that the keys function as an instruction channel.
Figures


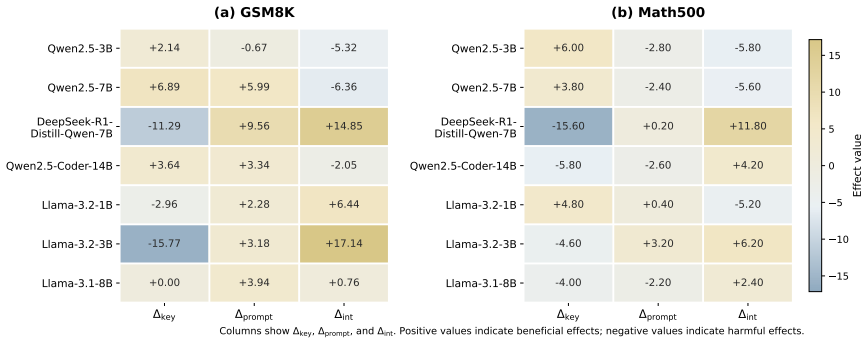
read the original abstract
Constrained decoding is widely used to make large language models produce structured outputs that satisfy schemas such as JSON. Existing work mainly treats schemas as structural constraints, overlooking that schema-key tokens also enter the autoregressive context and may guide generation. To the best of our knowledge, we present the first systematic study of schema keys as an implicit instruction channel under constrained decoding. We formulate structured generation as a multi-channel instruction problem, where task signals can be placed in prompts, schema keys, or both. We further provide a projection-aware analysis: a CoT-style key helps only when its semantic gain exceeds the distortion induced by grammar-constrained projection, offering a theoretical explanation for model-dependent key effects. Experiments on mathematical reasoning benchmarks show that changing only schema-key wording can substantially affect accuracy while keeping the prompt, model, output structure, and decoding setup fixed. Qwen models tend to benefit more from schema-level instructions, whereas LLaMA models rely more on prompt-level guidance, and the two channels interact non-additively. Our findings show that schema design is not merely output formatting, but part of instruction specification in structured generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to be the first systematic study of schema keys as an implicit instruction channel under constrained decoding. It frames structured generation as a multi-channel instruction problem (prompts and schema keys), introduces a projection-aware analysis showing that CoT-style keys help only when semantic gain exceeds grammar-induced distortion, and reports experiments on mathematical reasoning benchmarks where changing only schema-key wording substantially affects accuracy while holding prompt, model, output structure, and decoding fixed. It finds model-dependent effects (Qwen benefits more from schema-level instructions; LLaMA from prompt-level) and non-additive channel interactions.
Significance. If the central empirical claim holds after addressing controls, the work is significant for reframing schema design as active instruction engineering rather than passive formatting in constrained decoding. The multi-channel formulation and projection-aware analysis provide a useful theoretical lens for when and why key wording matters, with practical implications for schema optimization on reasoning tasks. The controlled contrasts and model-specific findings are strengths that could influence how practitioners and researchers approach structured outputs.
major comments (2)
- [Projection-aware analysis] Projection-aware analysis: the claim that this analysis bounds semantic gain versus distortion and explains model-dependent effects is load-bearing for the theoretical contribution, yet the description does not detail how token-level statistics (branching factor, forced-path probability mass) are held constant while varying only semantics. Without such an isolation, the analysis cannot fully rule out that accuracy shifts arise from tokenizer artifacts or grammar-projection dynamics rather than instruction content.
- [Experiments on mathematical reasoning benchmarks] Experiments on mathematical reasoning benchmarks: the central claim that schema-key wording alone drives substantial accuracy changes rests on these contrasts, but the manuscript provides no information on the number of runs, statistical tests, error bars, or variance across seeds. This makes it impossible to assess whether the reported model-dependent differences (Qwen vs. LLaMA) and non-additive interactions are robust or could be sensitive to incidental decoding factors.
minor comments (2)
- [Abstract] Abstract: the claim of being 'to the best of our knowledge' the first systematic study would be strengthened by a concise citation to the most closely related prior work on constrained decoding and schema usage.
- [Introduction] Notation and terminology: the multi-channel framing is clear in the abstract, but ensure consistent use of terms like 'projection' and 'distortion' when they first appear in the main text to avoid ambiguity for readers unfamiliar with the constrained-decoding literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for clarification and strengthening of both the theoretical analysis and empirical reporting. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Projection-aware analysis] Projection-aware analysis: the claim that this analysis bounds semantic gain versus distortion and explains model-dependent effects is load-bearing for the theoretical contribution, yet the description does not detail how token-level statistics (branching factor, forced-path probability mass) are held constant while varying only semantics. Without such an isolation, the analysis cannot fully rule out that accuracy shifts arise from tokenizer artifacts or grammar-projection dynamics rather than instruction content.
Authors: We agree that the current description of the projection-aware analysis requires more explicit methodological detail to isolate semantic effects from token-level and projection artifacts. In the revised manuscript, we will expand the relevant section to include a precise account of how schemas were designed to control branching factor and forced-path probability mass (via matched token-length keys and tokenizer-specific probability calculations) while varying only key semantics. Quantitative verification of these controls will be added to demonstrate that the reported accuracy differences arise from instruction content. revision: yes
-
Referee: [Experiments on mathematical reasoning benchmarks] Experiments on mathematical reasoning benchmarks: the central claim that schema-key wording alone drives substantial accuracy changes rests on these contrasts, but the manuscript provides no information on the number of runs, statistical tests, error bars, or variance across seeds. This makes it impossible to assess whether the reported model-dependent differences (Qwen vs. LLaMA) and non-additive interactions are robust or could be sensitive to incidental decoding factors.
Authors: We concur that statistical details are necessary to establish the robustness of the empirical findings. In the revised manuscript, we will add a new subsection on experimental methodology that reports the number of independent runs (across multiple random seeds), standard deviation error bars, and results of statistical tests including paired t-tests for model-specific effects and interaction analyses for non-additivity. These additions will allow readers to evaluate the stability of the Qwen versus LLaMA differences and channel interactions. revision: yes
Circularity Check
No significant circularity in the paper's claims or analysis
full rationale
The paper's core contribution rests on controlled experiments varying only schema-key wording while holding prompt, model, output structure, and constrained decoding fixed, plus a conceptual projection-aware analysis of semantic gain versus grammar distortion. No equations, parameter fits, or derivations are presented that reduce the accuracy effects or model-dependent differences to self-referential inputs, fitted quantities, or self-citation chains. The multi-channel instruction framing is introduced as a formulation rather than a derived result, and the theoretical explanation does not invoke uniqueness theorems or ansatzes from prior self-work. The argument is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. 2024. Guiding LLMs the right way: Fast, non-invasive constrained generation. In Proceedings of the 41st International Conference on Machine Learning (ICML)
2024
-
[3]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [4]
-
[5]
DeepSeek-AI . 2025. Deepseek-r1-distill-qwen-7b. Hugging Face model card. Accessed: 2026-04-16
2025
-
[6]
Yixin Dong, Charlie F. Ruan, and 1 others. 2024. XGrammar : Flexible and efficient structured generation engine for large language models. arXiv preprint arXiv:2411.15065
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Aakanksha Jauhri, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. In Advances in Neural Information Processing Systems
2021
-
[9]
Binyuan Hui, Jian Yang, Zeyu Cui, and 1 others. 2024. Qwen2.5-coder technical report. arXiv preprint arXiv:2409.12186
work page internal anchor Pith review arXiv 2024
-
[10]
Yanjun Jiang, Yuxuan Wang, Xuehai Zeng, Wanjun Zhong, and 1 others. 2024. FollowBench : A multi-level fine-grained constraints following benchmark for large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[11]
Michael Xieyang Liu, Frederick Liu, Alexander J. Fiannaca, Terry Koo, Lucas Dixon, Michael Terry, and Carrie J. Cai. 2024. "we need structured output": Towards user-centered constraints on large language model output. arXiv preprint arXiv:2404.07362
-
[12]
Meta AI . 2024. Llama 3.2 model card. Hugging Face model card. Accessed: 2026-04-16
2024
- [13]
-
[14]
Federico Raspanti, Tanir \"O z c elebi, and Mike J Holenderski. 2025. Grammar-constrained decoding makes large language models better logical parsers. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) - Industry Track
2025
-
[15]
Justin Schall and Gerard de Melo. 2025. The hidden cost of structure: How constrained decoding affects language model performance. In Proceedings of the International Conference Recent Advances in Natural Language Processing (RANLP)
2025
-
[16]
Torsten Scholak, Nathan Schucher, and Dzmitry Bahdanau. 2021. PICARD : Parsing incrementally for constrained auto-regressive decoding from language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2021
- [17]
- [18]
- [19]
-
[20]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and R \'e mi Louf. 2023. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702
work page internal anchor Pith review arXiv 2023
-
[21]
An Yang, Baosong Yang, Beichen Zhang, and 1 others. 2024. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
- [23]
- [24]
-
[25]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, and 1 others. 2023. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[27]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.