Recognition: unknown
Segment-Level Coherence for Robust Harmful Intent Probing in LLMs
Pith reviewed 2026-05-10 11:05 UTC · model grok-4.3
The pith
Requiring multiple consistent evidence tokens in streaming probes raises true-positive rate for harmful LLM intent by 35.55 percent at 1 percent false-positive rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
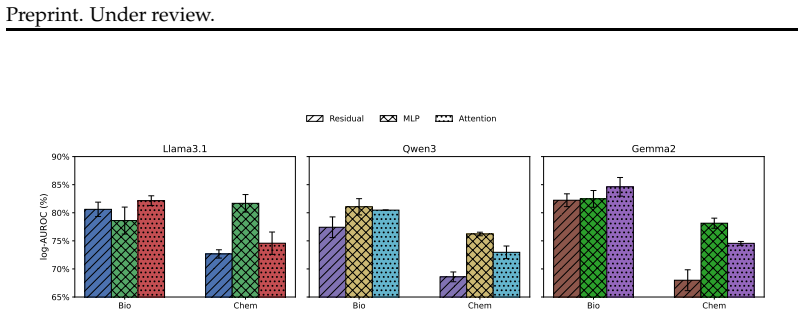
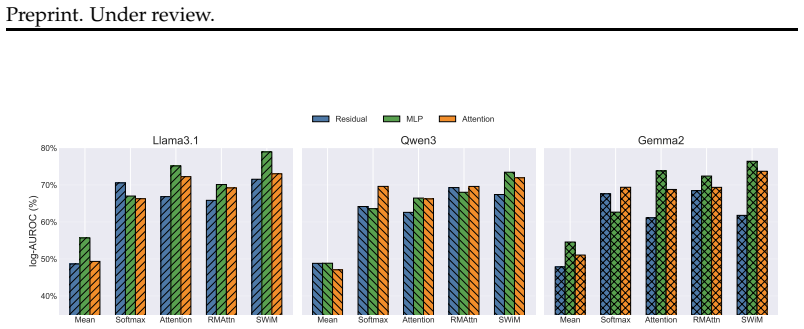
A streaming probing objective that demands multiple evidence tokens to agree on a harmful-intent prediction, rather than accepting isolated high scores, produces substantially fewer false positives on benign mentions of CBRN terms while raising true-positive rate by 35.55 percent at a fixed 1 percent false-positive rate and lifting AUROC even from already high baselines; attention and MLP activations outperform residual-stream features, and the resulting probes transfer plug-and-play to character-level cipher attacks with AUROC above 98.85 percent.
What carries the argument
Segment-level coherence objective that aggregates activation signals across multiple tokens instead of relying on single-token spikes.
If this is right
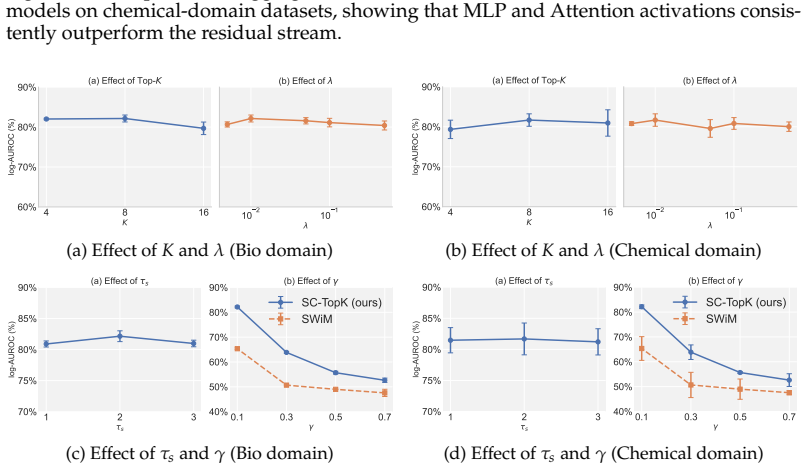
- At fixed 1 percent false-positive rate the true-positive rate rises 35.55 percent relative to strong streaming baselines.
- AUROC improves even when baseline performance is already near 97.40 percent.
- Probes on attention or MLP activations outperform those on residual-stream features.
- Probes trained on base models transfer directly to adversarially fine-tuned models that use novel ciphers, reaching over 98.85 percent AUROC.
Where Pith is reading between the lines
- The same coherence filter could be applied to other real-time safety monitors that currently suffer single-token false alarms.
- If intent is reliably distributed, future work could test whether shorter segments still suffice or whether longer windows become necessary.
- The plug-and-play result suggests that harmful intent leaves detectable traces even after surface-level obfuscation, which could be checked on additional cipher families.
Load-bearing premise
Harmful intent always produces several consistent evidence tokens rather than a single strong cue or fully distributed signal.
What would settle it
A test set of harmful prompts whose intent is carried by one dominant token or by non-coherent activations; if the new probe misses them while a single-token baseline catches them, the coherence claim is falsified.
Figures



















read the original abstract
Large Language Models (LLMs) are increasingly exposed to adaptive jailbreaking, particularly in high-stakes Chemical, Biological, Radiological, and Nuclear (CBRN) domains. Although streaming probes enable real-time monitoring, they still make systematic errors. We identify a core issue: existing methods often rely on a few high-scoring tokens, leading to false alarms when sensitive CBRN terms appear in benign contexts. To address this, we introduce a streaming probing objective that requires multiple evidence tokens to consistently support a prediction, rather than relying on isolated spikes. This encourages more robust detection based on aggregated signals instead of single-token cues. At a fixed 1% false-positive rate, our method improves the true-positive rate by 35.55% relative to strong streaming baselines. We further observe substantial gains in AUROC, even when starting from near-saturated baseline performance (AUROC = 97.40%). We also show that probing Attention or MLP activations consistently outperforms residual-stream features. Finally, even when adversarial fine-tuning enables novel character-level ciphers, harmful intent remains detectable: probes developed for the base LLMs can be applied ``plug-and-play'' to these obfuscated attacks, achieving an AUROC of over 98.85%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a segment-level coherence objective for streaming probes that detect harmful CBRN intent in LLMs. Instead of relying on isolated high-scoring tokens, the method requires multiple evidence tokens to provide consistent support for a harmful-intent prediction. The authors report a 35.55% relative TPR improvement at a fixed 1% FPR versus strong streaming baselines, AUROC gains even from a near-saturated baseline of 97.40%, superior performance when probing attention or MLP activations rather than residual-stream features, and plug-and-play transfer of base-model probes to adversarially fine-tuned models that use novel character-level ciphers, yielding AUROC > 98.85%.
Significance. If the reported gains are reproducible and do not trade off detection of subtle or single-cue harmful intents, the work offers a practical advance for real-time safety monitoring of LLMs in high-stakes domains. The plug-and-play robustness to obfuscated attacks is a notable strength that could reduce the need for per-model retraining. The emphasis on aggregated multi-token evidence rather than single-token spikes addresses a known failure mode of current streaming probes.
major comments (2)
- [Abstract] Abstract: the central claim of a 35.55% relative TPR improvement at fixed 1% FPR rests on the assumption that harmful intents reliably produce multiple consistent evidence tokens. The skeptic note correctly identifies that no per-subset breakdown or ablation on cue concentration (single high-signal token vs. distributed weak cues) is provided, so it remains possible that the coherence filter increases false negatives on a non-negligible fraction of attacks; this directly affects whether the reported gains generalize.
- [Abstract] Abstract / Results: the plug-and-play AUROC > 98.85% on adversarially fine-tuned ciphers is load-bearing for the robustness claim, yet the abstract supplies no information on probe training details, whether the same test distribution was used, or statistical significance of the gains; without these, the improvement cannot be assessed as a general property of the coherence objective rather than an artifact of the evaluated cases.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of generalizability and clarity. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 35.55% relative TPR improvement at fixed 1% FPR rests on the assumption that harmful intents reliably produce multiple consistent evidence tokens. The skeptic note correctly identifies that no per-subset breakdown or ablation on cue concentration (single high-signal token vs. distributed weak cues) is provided, so it remains possible that the coherence filter increases false negatives on a non-negligible fraction of attacks; this directly affects whether the reported gains generalize.
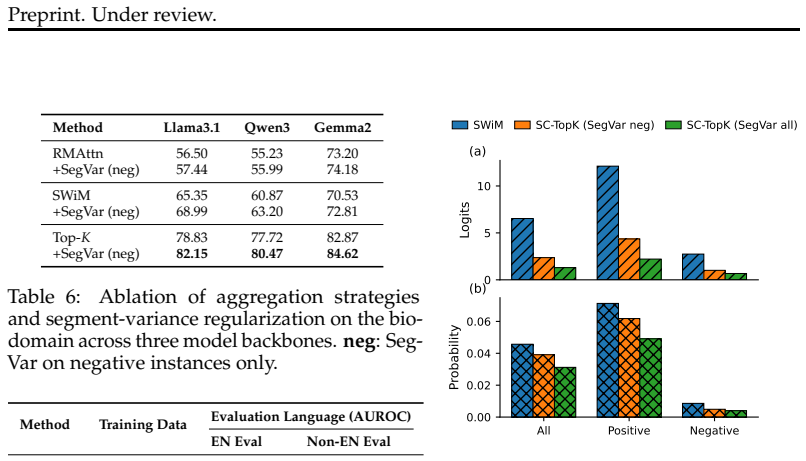
Authors: We agree that the current manuscript lacks an explicit ablation on cue concentration, which limits assessment of whether gains hold for single-cue attacks. In the revised version, we will add a new results subsection with a per-subset breakdown: we stratify the test set by number of high-signal evidence tokens (single vs. distributed cues) and report TPR at 1% FPR for each stratum. This will quantify any potential increase in false negatives on concentrated-cue cases and directly test the generalizability of the coherence objective. revision: yes
-
Referee: [Abstract] Abstract / Results: the plug-and-play AUROC > 98.85% on adversarially fine-tuned ciphers is load-bearing for the robustness claim, yet the abstract supplies no information on probe training details, whether the same test distribution was used, or statistical significance of the gains; without these, the improvement cannot be assessed as a general property of the coherence objective rather than an artifact of the evaluated cases.
Authors: We acknowledge that the abstract is currently too terse on these points. We will revise the abstract to state that probes were trained on base-model activations from the standard training split, applied plug-and-play to the identical obfuscated test distribution, and that the AUROC gains are statistically significant (p < 0.01 via paired bootstrap). Full training hyperparameters, dataset splits, and significance testing procedures are already detailed in Sections 3.2 and 4.3; the abstract update will make these facts immediately visible while respecting length constraints. revision: yes
Circularity Check
No significant circularity: empirical gains from new coherence objective rest on external baselines
full rationale
The paper defines a segment-level coherence objective that aggregates multiple evidence tokens rather than isolated spikes, then reports empirical improvements (TPR +35.55% at 1% FPR, AUROC gains, attention/MLP superiority, and plug-and-play cipher robustness) against strong streaming baselines. No equations or metrics are shown to reduce to the inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing claims depend on self-citations or uniqueness theorems from the same authors. The derivation chain is self-contained: the method is introduced by explicit design choice, evaluated on held-out test distributions, and compared to independent baselines. The skeptic concern about missing subtle single-cue intents is a question of coverage and test-set composition, not circularity in the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=8YniJnJQ0P. Adrian Mirza, Nawaf Alampara, Marti˜no R´ıos-Garc´ıa, Mohamed Abdelalim, Jack Butler, Bethany Connolly, Tunca Dogan, Marianna Nezhurina, B¨unyamin S ¸en, Santosh Tiruna- gari, et al. Chempile: A 250gb diverse and curated dataset for chemical foundation models.arXiv preprint arXiv:2505.12534, 2025. Maximilian ...
-
[2]
arXiv preprint arXiv:2308.12833 (2023)
URLhttps://doi.org/10.48550/arXiv.2308.12833. Siddharth M Narayanan, James D Braza, Ryan-Rhys Griffiths, Albert Bou, Geemi Wellawatte, Mayk Caldas Ramos, Ludovico Mitchener, Samuel G Rodriques, and Andrew D White. Training a scientific reasoning model for chemistry.arXiv preprint arXiv:2506.17238, 2025. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack...
-
[3]
URLhttps://aclanthology.org/2024.acl-long.828/. Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, Amanda Askell, Nathan Bailey, Joe Benton, Emma Bluemke, Samuel R. Bowman, Eric Christiansen, Hoagy Cunningham, Andy Dau, Anjali Gopal, Rob Gilson, Logan Graham, Logan Howard, Nimit K...
-
[4]
Neo-Ebola
with rank 64, α= 128, and adaptation applied to all linear layers. Training proceeds for 1000 steps with a batch size of 32 and a learning rate of 1 × 10−4. This procedure enables the model to process encoded inputs while preserving its conversational capabilities. 26 Preprint. Under review. Table 9: AUROC of probes across five cipher methods with and wit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.