Recognition: unknown
SkillDroid: Compile Once, Reuse Forever
Pith reviewed 2026-05-10 10:54 UTC · model grok-4.3
The pith
SkillDroid compiles successful mobile GUI task runs into reusable templates that execute without new LLM calls and improve in reliability over repeated use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
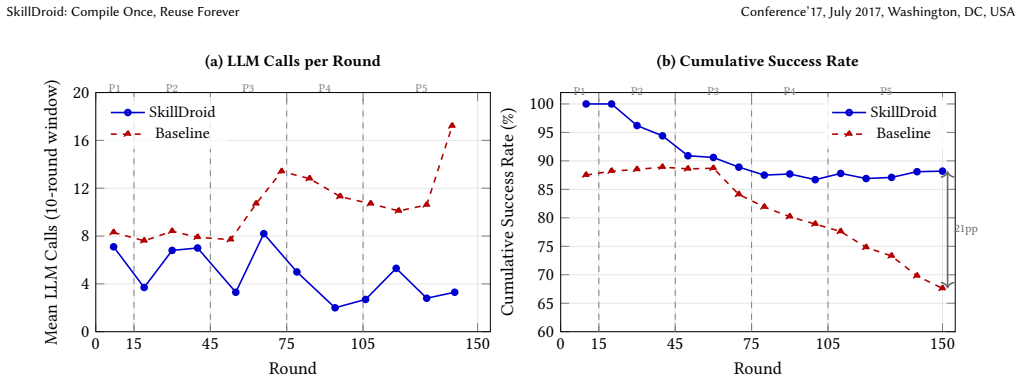
By compiling LLM-guided trajectories into sequences of UI actions with weighted element locators and typed parameter slots, SkillDroid enables replay of those skills on future instructions via a matching cascade, eliminating LLM calls during successful replays and allowing the overall system success rate to increase from 87% to 91% over 150 rounds while the stateless baseline falls from 80% to 44%.
What carries the argument
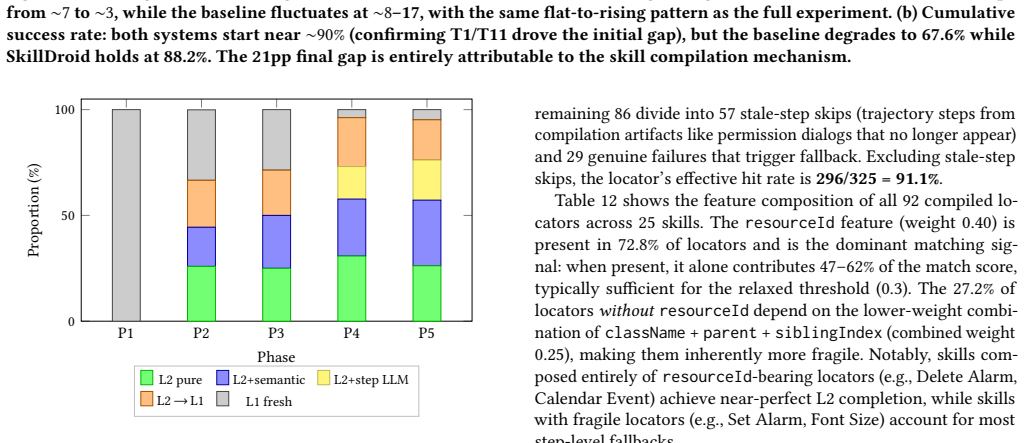
Parameterized skill templates that capture sequences of UI actions with weighted locators and slots, together with a matching cascade using regex patterns, embedding similarity, and app filtering, plus a failure-learning layer for recompilation.
If this is right
- Agents can achieve 85.3% task success with 49% fewer LLM calls than stateless methods.
- Skill replays run at 2.4 times the speed of full LLM execution with 100% success in tested rounds.
- Success rates converge upward with continued use rather than degrading.
- Instruction variations and controlled perturbations are handled through template matching and recompilation.
Where Pith is reading between the lines
- Skill libraries could accumulate across many apps, allowing new users to start with pre-built capabilities.
- The template approach might extend to non-mobile interfaces if locator weighting can be adapted to different UI frameworks.
- Reducing per-step LLM dependence could lower latency and cost enough to enable always-on personal agents.
Load-bearing premise
Successful trajectories can be converted into templates whose locators and slots will correctly match and run on similar future instructions without the matching cascade producing harmful errors.
What would settle it
Testing the system on a fresh collection of apps and instructions with greater variation in phrasing or novel UI layouts to check if success rates remain higher than the baseline or fall below it.
Figures




read the original abstract
LLM-based mobile GUI agents treat every task invocation as an independent reasoning episode, requiring a full LLM inference call at each action step. This per-step dependence makes them stateless: a task completed successfully yesterday is re-derived from scratch today, with no improvement in reliability or speed. We present SkillDroid, a three-layer skill agent that compiles successful LLM-guided GUI trajectories into parameterized skill templates (sequences of UI actions with weighted element locators and typed parameter slots) and replays them on future invocations without any LLM calls. A matching cascade (regex patterns, embedding similarity, and app filtering) routes incoming instructions to stored skills, while a failure-learning layer triggers recompilation when skill reliability degrades. Over a 150-round longitudinal evaluation with systematic instruction variation and controlled perturbations, SkillDroid achieves an 85.3% success rate (23 percentage points above a stateless LLM baseline) while using 49% fewer LLM calls. The skill replay mechanism achieves a perfect 1000% success rate across 79 replay rounds at 2.4 times the speed of full LLM execution. Most critically, the system improves with use: its success rate converges upward from 87% to 91%, while the baseline degrades from 80% to 44%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SkillDroid, a three-layer mobile GUI agent that compiles successful LLM trajectories into parameterized skill templates (with weighted locators and typed slots) and replays them via a regex+embedding+app-filter matching cascade, augmented by a failure-learning layer for recompilation. In a 150-round longitudinal evaluation with systematic instruction variations and perturbations, it reports 85.3% success (23pp above a stateless LLM baseline), 49% fewer LLM calls, 100% success on 79 replay rounds at 2.4x speed, and upward convergence (87% to 91%) while the baseline degrades (80% to 44%).
Significance. If the central performance claims hold under the reported controls, SkillDroid would demonstrate a practical path to reusable, self-improving GUI agents that reduce per-step LLM dependence while gaining reliability with use. The longitudinal design with independent success metrics and explicit perturbation controls is a strength that could influence follow-on work in agentic systems.
major comments (2)
- [Evaluation] Evaluation section: the headline gains (85.3% success, 23pp lift, 49% call reduction, 87%→91% convergence) rest on the matching cascade correctly routing varied instructions to the compiled templates without harmful false positives or negatives. No per-component routing accuracy, false-positive rates, or ablation that disables the cascade (forcing full LLM fallback) is reported, leaving the load-bearing generalization assumption unverified.
- [Evaluation] Evaluation section: exact implementation details of the stateless LLM baseline (prompting strategy, action selection, and how perturbations are applied) and the perturbation controls themselves are insufficiently specified to allow replication or to confirm that the measured degradation (80% to 44%) is not an artifact of baseline fragility.
minor comments (2)
- [Abstract] Abstract: 'perfect 1000% success rate' is a typographical error and should read 'perfect 100% success rate'.
- [System Design] The description of the failure-learning layer and how it triggers recompilation lacks a concrete algorithm or threshold, which would aid clarity even if not central to the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the potential impact of the longitudinal evaluation. We address each major comment below and will revise the manuscript to incorporate additional details and analyses for improved clarity and replicability.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline gains (85.3% success, 23pp lift, 49% call reduction, 87%→91% convergence) rest on the matching cascade correctly routing varied instructions to the compiled templates without harmful false positives or negatives. No per-component routing accuracy, false-positive rates, or ablation that disables the cascade (forcing full LLM fallback) is reported, leaving the load-bearing generalization assumption unverified.
Authors: We agree that an explicit ablation of the matching cascade and per-component routing metrics would directly substantiate the generalization claims. In the revised manuscript we will add a new subsection under Evaluation that reports precision, recall, and accuracy for each stage of the cascade (regex, embedding similarity, app filter) on the held-out trajectories. We will also include an ablation experiment that disables the cascade entirely (forcing full LLM fallback on every step) and compare success rate and LLM call count against the complete SkillDroid system. These results will be presented alongside the existing longitudinal data. revision: yes
-
Referee: [Evaluation] Evaluation section: exact implementation details of the stateless LLM baseline (prompting strategy, action selection, and how perturbations are applied) and the perturbation controls themselves are insufficiently specified to allow replication or to confirm that the measured degradation (80% to 44%) is not an artifact of baseline fragility.
Authors: We concur that greater specificity is required for replication and to rule out implementation artifacts. The revised version will expand the Baseline and Perturbation Controls subsections to provide: the complete system prompt and few-shot examples used by the stateless agent, the exact parsing logic that converts LLM output into executable GUI actions, and a step-by-step description of how each instruction variation and environmental perturbation is generated and applied across the 150 rounds. We will also release the full set of 150 instructions and perturbation seeds as supplementary material. revision: yes
Circularity Check
No circularity: empirical longitudinal evaluation with independent metrics
full rationale
The paper reports measured success rates, LLM call reductions, replay speeds, and convergence trends from a 150-round longitudinal evaluation against a stateless baseline. These quantities are obtained directly from task execution logs and do not reduce, by any equation or definition in the text, to quantities fitted from the same data or to self-referential templates. No mathematical derivations, uniqueness theorems, or ansatz adoptions appear; the matching cascade and failure-learning layer are described as engineering components whose reliability is assessed by the external success metric rather than presupposed by it.
Axiom & Free-Parameter Ledger
free parameters (2)
- element locator weights
- embedding similarity threshold
axioms (1)
- domain assumption Successful LLM trajectories contain reusable structure that can be parameterized without losing correctness on similar future tasks.
invented entities (3)
-
parameterized skill template
no independent evidence
-
matching cascade
no independent evidence
-
failure-learning layer
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
1993.Watch what I do: programming by demonstration
Allen Cypher and Daniel Conrad Halbert. 1993.Watch what I do: programming by demonstration. MIT press
1993
-
[4]
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. 2024. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14281–14290
2024
-
[5]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI conference on Human Factors in Computing Systems. 159–166. SkillDroid: Compile Once, Reuse Forever Conference’17, July 2017, Washington, DC, USA
1999
-
[6]
Hiroyuki Kirinuki, Haruto Tanno, and Katsuyuki Natsukawa. 2019. COLOR: correct locator recommender for broken test scripts using various clues in web application. In2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 310–320
2019
-
[7]
John D Lee and Katrina A See. 2004. Trust in automation: Designing for appro- priate reliance.Human factors46, 1 (2004), 50–80
2004
-
[8]
Sunjae Lee, Junyoung Choi, Jungjae Lee, Munim Hasan Wasi, Hojun Choi, Steve Ko, Sangeun Oh, and Insik Shin. 2024. Mobilegpt: Augmenting llm with human- like app memory for mobile task automation. InProceedings of the 30th Annual International Conference on Mobile Computing and Networking. 1119–1133
2024
-
[9]
Maurizio Leotta, Andrea Stocco, Filippo Ricca, and Paolo Tonella. 2014. Reducing web test cases aging by means of robust XPath locators. In2014 IEEE International Symposium on Software Reliability Engineering Workshops. IEEE, 449–454
2014
-
[10]
2001.Your wish is my command: Programming by example
Henry Lieberman. 2001.Your wish is my command: Programming by example. Morgan Kaufmann
2001
-
[11]
Raja Parasuraman and Victor Riley. 1997. Humans and automation: Use, misuse, disuse, abuse.Human factors39, 2 (1997), 230–253
1997
-
[12]
Cheng Qian, Chi Han, Yi Fung, Yujia Qin, Zhiyuan Liu, and Heng Ji. 2023. Creator: Tool creation for disentangling abstract and concrete reasoning of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023. 6922–6939
2023
-
[13]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. 2023. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[15]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems36, 8634–8652
2023
- [16]
-
[17]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review arXiv 2023
-
[18]
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration.Advances in Neural Information Processing Systems37 (2024), 2686–2710
2024
- [19]
-
[20]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
-
[21]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems33 (2020), 5776–5788
2020
-
[22]
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jinbing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, et al . 2024. Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models.IEEE Transactions on Pattern Analysis and Machine Intelligence47, 3 (2024), 1894–1907
2024
-
[23]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. 2024. Agent workflow memory.arXiv preprint arXiv:2409.07429(2024)
work page internal anchor Pith review arXiv 2024
-
[24]
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. Autodroid: Llm-powered task automation in android. InProceedings of the 30th annual international con- ference on Mobile computing and networking. 543–557
2024
- [25]
- [26]
-
[27]
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, et al. 2025. Ufo: A ui-focused agent for windows os interaction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
2025
-
[28]
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. 2025. Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–20
2025
- [29]
-
[30]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19632–19642
2024
-
[31]
Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, et al. 2023. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory.arXiv preprint arXiv:2305.17144(2023). Appendix A Task and Instruction Details Category ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.