Recognition: unknown
Beyond Importance Sampling: Rejection-Gated Policy Optimization
Pith reviewed 2026-05-10 11:24 UTC · model grok-4.3
The pith
RGPO replaces importance sampling ratios with a differentiable gate to bound gradient variance even for heavy-tailed ratios while keeping bias controllable and delivering TRPO-like improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
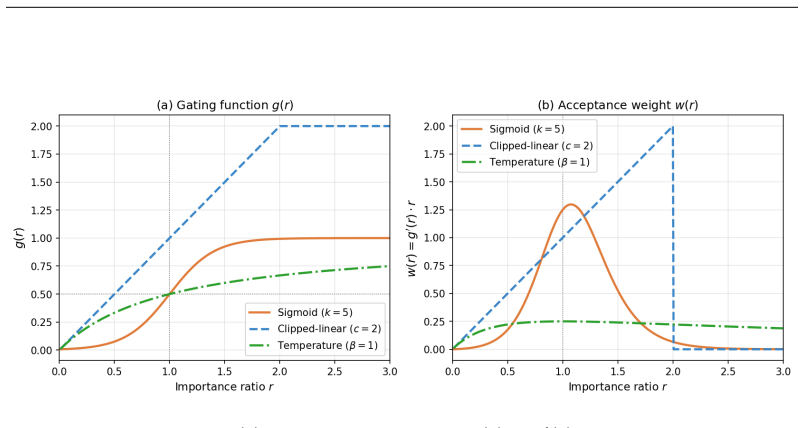
RGPO replaces the importance sampling ratio r_theta with a smooth differentiable acceptance gate alpha_theta(s, a) = g(r_theta(s, a)) in [0,1] that participates directly in gradient computation and is updated alongside the policy. The effective weight w(r) = g'(r) * r unifies the policy gradients of TRPO, PPO, and REINFORCE as special cases. The method guarantees finite bounded gradient variance even when importance sampling ratios are heavy-tailed, incurs only bounded controllable bias, and supplies an approximate monotonic policy improvement guarantee analogous to TRPO.
What carries the argument
The smooth differentiable acceptance gate alpha = g(r) in [0,1] that defines the effective gradient weight w(r) = g'(r) * r and carries the variance bound and bias control.
If this is right
- Gradient variance stays finite and bounded even when importance sampling ratios are heavy-tailed.
- Bias introduced by the gate remains bounded and controllable by choice of g.
- An approximate guarantee of monotonic policy improvement holds, analogous to TRPO.
- Computational cost matches PPO with no second-order optimization required.
- The framework extends naturally to online preference alignment with dual-ratio gates.
Where Pith is reading between the lines
- The gate unification may allow new gate designs that target specific variance-bias profiles in other reinforcement learning domains.
- Dual-ratio anchoring to both the previous policy and a reference model could extend to other preference or alignment settings.
- Bounded variance might reduce reliance on heuristic clipping in large-scale policy optimization.
Load-bearing premise
A single smooth differentiable gate function g can be chosen so the resulting effective weight unifies existing methods, keeps bias bounded and controllable, and delivers the variance bound without hidden trade-offs.
What would settle it
A concrete setting with heavy-tailed importance ratios where gradient variance remains unbounded or diverges after applying the gate function in RGPO.
Figures







read the original abstract
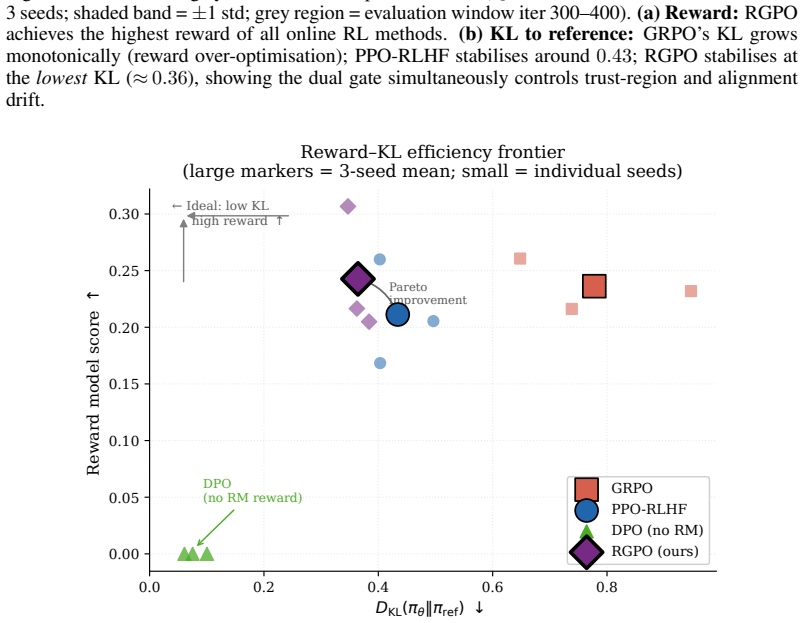
We propose a new perspective on policy optimization: rather than reweighting all samples by their importance ratios, an optimizer should select which samples are trustworthy enough to drive a policy update. Building on this view, we introduce Rejection-Gated Policy Optimization (RGPO), which replaces the importance sampling ratio r_theta = pi_theta / pi_old with a smooth, differentiable acceptance gate alpha_theta(s, a) = g(r_theta(s, a)) in the range [0, 1]. Unlike prior work that applies rejection sampling as a data-level heuristic before training, RGPO elevates rejection to an optimization principle: the gate participates directly in gradient computation and is implicitly updated alongside the policy. RGPO provides a unified framework: the policy gradients of TRPO, PPO, and REINFORCE all correspond to specific choices of the effective gradient weight w(r) = g'(r) * r. We prove that RGPO guarantees finite, bounded gradient variance even when importance sampling ratios are heavy-tailed (where IS variance diverges). We further show that RGPO incurs only a bounded, controllable bias and provides an approximate monotonic policy improvement guarantee analogous to TRPO. RGPO matches PPO in computational cost, requires no second-order optimization, and extends naturally to RLHF-style preference alignment. In online preference fine-tuning of Qwen2.5-1.5B-Instruct on Anthropic HH-RLHF (n = 3 seeds), RGPO uses a dual-ratio gate that anchors learning to both the previous policy and the reference model, achieving a Pareto-dominant outcome: the highest reward among online RL methods (+14.8% vs. PPO-RLHF) and the lowest KL divergence to the reference model (-16.0% vs. PPO-RLHF, -53.1% vs. GRPO).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rejection-Gated Policy Optimization (RGPO) for policy optimization in RL. Rather than reweighting samples via importance ratios r = π_θ/π_old, RGPO applies a smooth differentiable gate α = g(r) ∈ [0,1] that participates in the gradient. It claims that TRPO, PPO, and REINFORCE gradients arise as special cases of the effective weight w(r) = g'(r)·r. The manuscript asserts proofs that RGPO yields finite bounded gradient variance for heavy-tailed r (where plain IS variance diverges), only bounded controllable bias, and an approximate monotonic policy-improvement guarantee analogous to TRPO. It further reports that a dual-ratio gate variant applied to online RLHF fine-tuning of Qwen2.5-1.5B-Instruct on Anthropic HH-RLHF (n=3 seeds) attains the highest reward (+14.8% vs. PPO-RLHF) and lowest KL to the reference model among compared methods.
Significance. If the variance, bias, and improvement guarantees can be established rigorously, RGPO would supply a principled mechanism for stabilizing policy gradients without the divergence problems of importance sampling while recovering existing algorithms as special cases. The dual-ratio construction for RLHF and the reported Pareto improvement in reward versus KL would be practically relevant for large-scale preference alignment. The framework’s ability to keep computational cost comparable to PPO is an additional strength.
major comments (4)
- [framework / unification paragraph] The unification statement (abstract and framework section) is achieved by definition: any desired weight function can be realized by solving for g such that g'(r)·r equals that weight. This renders the claim that TRPO/PPO/REINFORCE “correspond to specific choices” tautological rather than a non-trivial derivation; the manuscript should clarify what independent predictive or algorithmic content the common g parameterization supplies beyond re-labeling.
- [variance proof] The finite-variance claim for heavy-tailed r requires that w(r) = g'(r)·r decay sufficiently fast at large r to restore integrability. The PPO-style clipping choice of g produces a steep transition whose derivative g' can become large near the clip threshold, potentially re-introducing unbounded moments. The manuscript must exhibit the explicit decay condition on g (or g') that guarantees the bound and verify that the g functions used for unification and for the dual-ratio experiment satisfy it.
- [bias analysis / experiment section] The bounded-bias claim is stated for “any choice of g satisfying the framework,” yet the dual-ratio gate employed in the Qwen experiment introduces additional parameters whose effect on the bias term is neither bounded nor quantified. An explicit bias expression or numerical sensitivity analysis with respect to those parameters is needed to substantiate controllability.
- [monotonic improvement theorem] The approximate monotonic-improvement guarantee is asserted by analogy to TRPO, but the approximation error introduced by the gate g (versus the identity) is not bounded or shown to vanish under the same trust-region conditions. The manuscript should state the precise conditions on g under which the guarantee holds and how they interact with the variance bound.
minor comments (2)
- [experiments] The experimental section reports improvements with n=3 seeds; standard deviations or confidence intervals for the +14.8% reward and –16.0% KL figures should be included to support the Pareto-dominance claim.
- [experiment setup] The precise functional form and hyper-parameters of the dual-ratio gate used for the Qwen2.5 runs are not stated explicitly; they should be given in an appendix or table so that the result is reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate the revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: The unification statement (abstract and framework section) is achieved by definition: any desired weight function can be realized by solving for g such that g'(r)·r equals that weight. This renders the claim that TRPO/PPO/REINFORCE “correspond to specific choices” tautological rather than a non-trivial derivation; the manuscript should clarify what independent predictive or algorithmic content the common g parameterization supplies beyond re-labeling.
Authors: While any weight function can be realized by appropriate choice of g, the RGPO framework imposes that g be a smooth differentiable map into [0,1]. This gate constraint is essential for the subsequent variance bounds and for constructing new algorithms such as the dual-ratio gate. We will revise the framework section to emphasize that the gating perspective supplies a principled way to derive stable variants and theoretical guarantees, rather than serving merely as a relabeling. revision: partial
-
Referee: The finite-variance claim for heavy-tailed r requires that w(r) = g'(r)·r decay sufficiently fast at large r to restore integrability. The PPO-style clipping choice of g produces a steep transition whose derivative g' can become large near the clip threshold, potentially re-introducing unbounded moments. The manuscript must exhibit the explicit decay condition on g (or g') that guarantees the bound and verify that the g functions used for unification and for the dual-ratio experiment satisfy it.
Authors: We agree that an explicit decay condition is required for rigor. The revised manuscript will state that |g'(r)| ≤ C/r^{1+δ} (δ>0) for large r suffices to bound the second moment. We will prove that both the smoothed clipping gate used for unification and the dual-ratio gate satisfy this decay (smoothing ensures g' vanishes at infinity) and include the verification in the appendix. revision: yes
-
Referee: The bounded-bias claim is stated for “any choice of g satisfying the framework,” yet the dual-ratio gate employed in the Qwen experiment introduces additional parameters whose effect on the bias term is neither bounded nor quantified. An explicit bias expression or numerical sensitivity analysis with respect to those parameters is needed to substantiate controllability.
Authors: The bias bound holds whenever g maps to [0,1] with bounded derivative, independent of auxiliary parameters. For the dual-ratio gate the extra parameters only rescale the effective gate while preserving the [0,1] range. We will add an explicit bias expression in terms of the gate parameters and include a sensitivity analysis in the experimental section. revision: yes
-
Referee: The approximate monotonic-improvement guarantee is asserted by analogy to TRPO, but the approximation error introduced by the gate g (versus the identity) is not bounded or shown to vanish under the same trust-region conditions. The manuscript should state the precise conditions on g under which the guarantee holds and how they interact with the variance bound.
Authors: We will revise the theorem to state that the guarantee holds when |g(r) - r| is bounded by the trust-region radius and g(r) → r as the radius → 0. The error term is then controlled by the same KL constraint used in TRPO. This condition is compatible with the variance decay requirement on g'. The updated proof will bound the approximation error explicitly. revision: yes
Circularity Check
Unification of TRPO/PPO/REINFORCE gradients as specific w(r)=g'(r)*r choices is definitional by construction of the RGPO framework
specific steps
-
self definitional
[Abstract]
"RGPO provides a unified framework: the policy gradients of TRPO, PPO, and REINFORCE all correspond to specific choices of the effective gradient weight w(r) = g'(r) * r."
The RGPO formulation defines the acceptance gate alpha = g(r) and then derives the gradient using the effective weight w(r) = g'(r) * r by construction. Claiming that TRPO/PPO/REINFORCE 'correspond to specific choices' of this w(r) is therefore equivalent to selecting g such that g'(r)*r reproduces the weighting already used in those algorithms; the unification is tautological with the framework definition rather than an independent result.
full rationale
The paper's core contribution is framed as a new perspective yielding a unified framework with variance bounds, bias control, and monotonic improvement guarantees. However, the unification step reduces directly to the definitional choice of representing existing methods' weights via the introduced w(r) = g'(r)*r form. The variance and bias proofs are stated to hold for choices of g within this framework, but the framework itself is constructed precisely to recover the special cases, with no independent derivation shown for why this particular gate parameterization unifies them beyond the re-expression. This makes the 'general framework' appear built around the desired recoveries rather than derived from first principles independent of the target methods. No other circular steps (e.g., self-citation chains or fitted inputs renamed as predictions) are exhibited in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- gate function g
axioms (1)
- domain assumption The acceptance gate is differentiable and maps ratios to values in [0,1]
Reference graph
Works this paper leans on
-
[1]
Maximum a posteriori policy optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Mar- tin Riedmiller. Maximum a posteriori policy optimisation.arXiv preprint arXiv:1806.06920,
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862,
-
[3]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998,
-
[4]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. DeBERTa: Decoding-enhanced BERT with disentangled attention.arXiv preprint arXiv:2006.03654,
work page internal anchor Pith review arXiv 2006
-
[5]
arXiv preprint arXiv:2309.06657 , year=
Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J Liu, and Jialu Liu. Statistical rejection sampling improves preference optimization.arXiv preprint arXiv:2309.06657,
-
[6]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online rein- forcement learning with offline datasets. InarXiv preprint arXiv:2006.09359,
work page internal anchor Pith review arXiv 2006
-
[7]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. InarXiv preprint arXiv:1910.00177,
work page internal anchor Pith review arXiv 1910
-
[8]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pp. 1889–1897. PMLR, 2015a. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv pre...
work page internal anchor Pith review arXiv
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. InarXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:1611.01224 , year=
Ziyu Wang, Victor Bapst, Nicolas Heess, V olodymyr Mnih, Remi Munos, Koray Kavukcuoglu, and Nando de Freitas. Sample efficient actor-critic with experience replay. InarXiv preprint arXiv:1611.01224,
-
[11]
Linxiao Zhao et al. Jackpot: Optimal budgeted rejection sampling for policy optimization.arXiv preprint arXiv:2501.12342,
-
[12]
A.2 PROOF OFTHEOREM2ANDPROPOSITION1 Proof of Theorem 2.Step 1: RGPO variance upper bound.LetZ=∇ θ logπ θ(a|s)·A old
A FULLPROOFS A.1 PROOF OFTHEOREM1 (BIASBOUND) Proof.The true policy gradient using importance sampling is: ∇J(θ) =E πold[rθ∇θ logπ θ(a|s)A].(27) The RGPO gradient is: ∇θLRGPO =E πold[g′(rθ)r θ ∇θ logπ θ(a|s)A].(28) The difference is: ∆ =∇ θLRGPO − ∇J(θ) =E πold g′(rθ)−1 rθ ∇θ logπ θ(a|s)A .(29) Taking norms and applying the triangle inequality: ∥∆∥ ≤E πol...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.