Recognition: unknown
Dual-Axis Generative Reward Model Toward Semantic and Turn-taking Robustness in Interactive Spoken Dialogue Models
Pith reviewed 2026-05-10 11:07 UTC · model grok-4.3
The pith
A generative reward model scores spoken dialogues separately on semantic quality and turn-taking timing to supply usable signals for reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present a Dual-Axis Generative Reward Model trained to understand complex interaction dynamics from a detailed taxonomy and an annotated dataset. It produces a single quality score together with separate evaluations of semantic content and interaction timing, thereby delivering precise diagnostic feedback for spoken dialogue models and a dependable reward signal suitable for online reinforcement learning.
What carries the argument
The Dual-Axis Generative Reward Model, which generates a unified score and independent semantic and timing assessments from taxonomy-annotated training data to serve as RL rewards.
If this is right
- The model supports online reinforcement learning of full-duplex spoken dialogue systems with more precise feedback than prior metrics.
- Separate semantic and timing scores allow targeted diagnosis and improvement of specific dialogue weaknesses.
- Performance remains state-of-the-art across synthetic dialogues and complex real-world interactions.
- The approach lowers dependence on costly and inconsistent human evaluations for training.
Where Pith is reading between the lines
- Dialogue systems trained with these rewards may produce measurably more fluid conversations in live user tests.
- The same dual-axis structure could be adapted to reward models for other turn-based interactive systems such as collaborative agents.
- A direct experiment would compare end-to-end user satisfaction after RL training with versus without the dual-axis signals.
Load-bearing premise
The detailed taxonomy and annotated dataset capture enough of the relevant interaction dynamics to yield reliable and generalizable reward signals.
What would settle it
A held-out collection of complex real dialogues in which the model's semantic and timing scores diverge from fresh human ratings on the same examples would falsify the claim of reliable reward signals.
Figures























read the original abstract
Achieving seamless, human-like interaction remains a key challenge for full-duplex spoken dialogue models (SDMs). Reinforcement learning (RL) has substantially enhanced text- and vision-language models, while well-designed reward signals are crucial for the performance of RL. We consider RL a promising strategy to address the key challenge for SDMs. However, a fundamental barrier persists: prevailing automated metrics for assessing interaction quality rely on superficial proxies, such as behavioral statistics or timing-prediction accuracy, failing to provide reliable reward signals for RL. On the other hand, human evaluations, despite their richness, remain costly, inconsistent, and difficult to scale. We tackle this critical barrier by proposing a Dual-Axis Generative Reward Model, which is trained to understand complex interaction dynamics using a detailed taxonomy and an annotated dataset, produces a single score and, crucially, provides separate evaluations for semantic quality and interaction timing. Such dual outputs furnish precise diagnostic feedback for SDMs and deliver a dependable, instructive reward signal suitable for online reinforcement learning. Our model achieves state-of-the-art performance on interaction-quality assessment across a wide spectrum of datasets, spanning synthetic dialogues and complex real-world interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Dual-Axis Generative Reward Model trained on a detailed taxonomy and annotated dataset to assess interaction quality in full-duplex spoken dialogue models. The model outputs both an overall score and separate evaluations for semantic quality and interaction timing, with the goal of supplying reliable, diagnostic reward signals for reinforcement learning. It claims state-of-the-art performance on interaction-quality assessment across synthetic dialogues and complex real-world interactions.
Significance. If the empirical claims hold, the work could meaningfully advance RL-based training of spoken dialogue models by replacing superficial proxies with scalable, dual-axis feedback that jointly addresses semantic content and turn-taking dynamics. The separation of semantic and timing axes is a constructive design choice that could enable more targeted model improvements.
major comments (2)
- [Abstract] Abstract: the central claim of SOTA performance on interaction-quality assessment is asserted without any reported metrics, baselines, dataset sizes, or comparison tables, making it impossible to evaluate whether the dual-axis outputs actually deliver generalizable reward signals.
- [Abstract] The manuscript's reliance on the 'detailed taxonomy and annotated dataset' for capturing complex interaction dynamics is load-bearing for the claim of dependable RL rewards, yet no quantitative evidence (e.g., inter-annotator agreement, edge-case coverage statistics, or ablation on taxonomy completeness) is referenced to substantiate that the annotations are reliable and comprehensive across real-world variability.
minor comments (1)
- [Abstract] The abstract uses the term 'full-duplex spoken dialogue models (SDMs)' without an initial definition or citation to prior work on full-duplex systems.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract should more explicitly support the central claims with quantitative details. We have revised the manuscript to address both major comments by strengthening the abstract while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of SOTA performance on interaction-quality assessment is asserted without any reported metrics, baselines, dataset sizes, or comparison tables, making it impossible to evaluate whether the dual-axis outputs actually deliver generalizable reward signals.
Authors: We acknowledge that the original abstract did not include specific metrics or comparisons, which limits immediate evaluation of the SOTA claim and the generalizability of the dual-axis reward signals. The full manuscript reports these details in the Experiments section, including performance on synthetic dialogues and real-world interactions, along with baseline comparisons. In the revised version, we have updated the abstract to concisely incorporate key quantitative results, dataset sizes, and a statement on outperformance, enabling readers to assess the reliability of the semantic and turn-taking scores for RL. revision: yes
-
Referee: [Abstract] The manuscript's reliance on the 'detailed taxonomy and annotated dataset' for capturing complex interaction dynamics is load-bearing for the claim of dependable RL rewards, yet no quantitative evidence (e.g., inter-annotator agreement, edge-case coverage statistics, or ablation on taxonomy completeness) is referenced to substantiate that the annotations are reliable and comprehensive across real-world variability.
Authors: We agree that the quality and coverage of the taxonomy and annotations are critical to the dependability of the reward signals. The manuscript provides a detailed description of the taxonomy and annotation process in the Methods and Dataset sections. To address the concern directly in the abstract, we have revised it to reference the available quantitative validations, such as inter-annotator agreement and edge-case coverage statistics reported in the paper. An explicit ablation on taxonomy completeness was not performed, but we can add further analysis in the revision if required; the current evidence supports reliability across the tested real-world variability. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes training a Dual-Axis Generative Reward Model on an external annotated dataset using a detailed taxonomy to generate semantic and timing scores for spoken dialogue evaluation. No equations, derivations, or self-referential steps are presented that reduce predictions or results to fitted inputs by construction. Claims of SOTA performance rest on empirical training and cross-dataset evaluation rather than self-definition, fitted-input renaming, or load-bearing self-citations. The approach is self-contained against external benchmarks with no evident circular reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Generative model parameters
axioms (1)
- domain assumption Human annotations on the taxonomy provide ground-truth labels for semantic quality and turn-taking quality
Reference graph
Works this paper leans on
-
[1]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
Don’t forget your ABC’s: Evaluating the state-of-the-art in chat-oriented dialogue systems. In Proceedings of the 61st Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 15044–15071, Toronto, Canada. Association for Computational Linguistics. Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Ku- mar, Zhifeng Kong...
-
[2]
A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594. Zhaori Guo, Timothy J Norman, and Enrico H Gerd- ing. 2024. Multi-trainer binary feedback interactive reinforcement learning.Annals of Mathematics and Artificial Intelligence, pages 1–26. Eric Han, Jun Chen, Karthik Abinav Sankararaman, Xi- aoliang Peng, Tengyu Xu, Eryk Helenowski, Kaiyan Peng, M...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Preprint, arXiv:2402.0...
work page internal anchor Pith review arXiv 2024
-
[4]
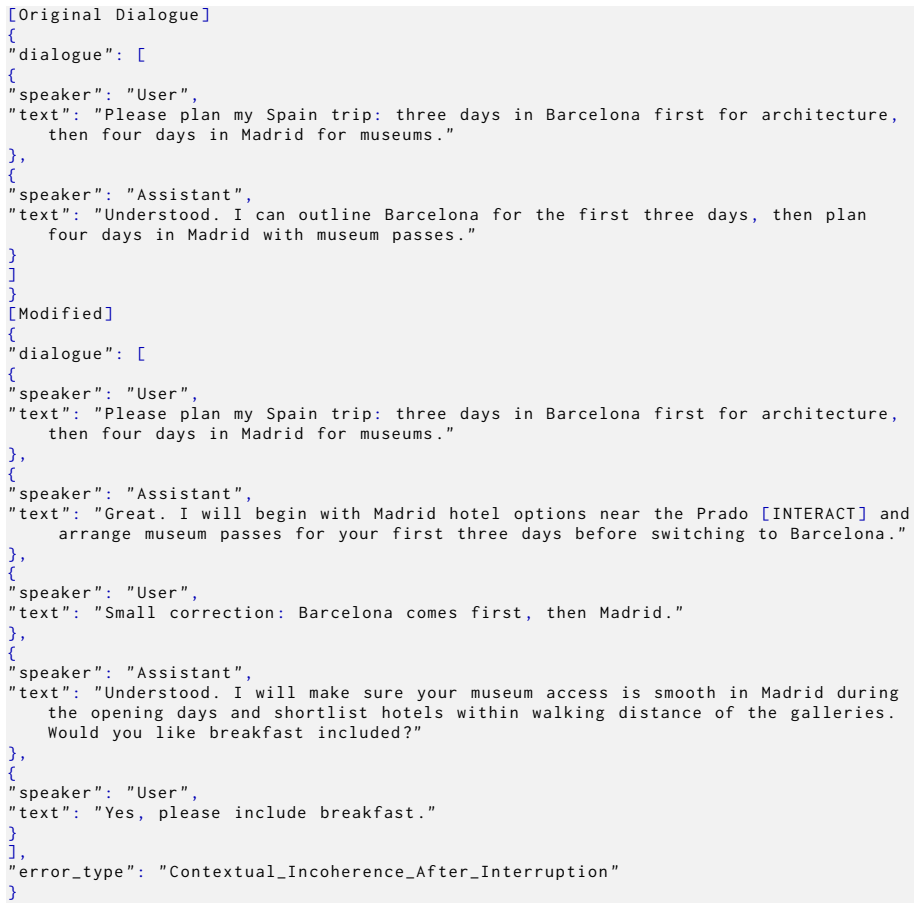
Source Data Curation and Rewriting:We extract and rewrite text dialogues from multi- ple public datasets to ensure broad topic cov- erage and diverse linguistic styles
-
[5]
Programmatic Generation of Interaction Events and Errors:Using Large Language Models (LLMs) with carefully engineered prompts, we inject a wide variety of success- ful interaction events and specific interaction errors into the dialogue scripts
-
[6]
teacher model
Chain-of-Thought (CoT) Annotation Gen- eration:We leverage a powerful "teacher model" to provide detailed, decoupled analy- ses (timing fluency and content relevance) for Table 4: Statistical overview of the datasets used in this study, separated by training and evaluation purposes. Dataset Name Samples Primary Annotation & Purpose Training Datasets Synth...
-
[7]
Dual-Track Audio Synthesis and Multi-task Data Formulation:We synthesize the anno- tated text scripts into dual-track audio and process them into multiple formats required for the model training. A.3 Source Data Curation and Rewriting Source Corpora To ensure diversity in our training data (Zhang et al., 2024b), we utilized several public text datasets: •...
2023
-
[8]
Smooth Turn Transition (Est) Scheme:This represents the ideal, default interaction where one speaker finishes their turn completely before the next speaker begins, separated by a natural, non- overlapping gap of silence. The generation pro- cess involves refactoring an existing, often verbose, multi-turn dialogue from a source corpus into a more concise a...
-
[9]
Speaker A detects this and immedi- ately ceases speaking, yielding the conversational floor to Speaker B
Successful Interruption ( Esucc) Scheme: Speaker B begins speaking during Speaker A’s utterance. Speaker A detects this and immedi- ately ceases speaking, yielding the conversational floor to Speaker B. This is a common and natural feature of dynamic conversation. The generation scheme involves identifying an appropriate point in a source dialogue to inse...
-
[10]
um," "yes
Backchannel (Ebc) And Pause Scheme:After all the interactive events of the dialogue are rewrit- ten, in order to ensure the realism of the synthe- sized dialogue, we insert appropriate backchan- nel and pause markers into all samples. When the speaker speaks, the listener makes short, non- competitive remarks (for example, "um," "yes") or short affirmativ...
-
[11]
Standard Response:Assessing the timeliness, relevance, and accuracy of the model’s reply following a complete user query
-
[12]
Intra-turn Pause:Testing the model’s patience during a natural pause within a user’s utterance, with the goal of provok- ing either a correct wait or an incorrect Inappropriate Barge-in
-
[13]
uh- huh,
Listener Backchannel:Testing the model’s ability to correctly process short, non-competitive listener cues (e.g., "uh- huh," "okay") during its own long utter- ance. The aim was to elicit either a ro- bust continuation (correct) or anOverly Deferential Cedingerror (incorrect)
-
[14]
Good Case
Competitive Interruption:Testing the model’s floor-taking mechanism by hav- ing the user attempt to stop the model mid-speech with a new, substantive com- mand, in order to provoke either aSuc- cessful Interruptionor anIgnored Inter- ruption. • Participant Guidance and Protocol:Partic- ipants were provided with a detailed instruc- tion document that defin...
-
[15]
Overlap Detection:We employ the pyannote.audio toolkit for speaker di- arization to identify all speech segments where both participants are speaking si- multaneously
-
[16]
Vocal Consistency Check:For each de- tected overlap, we compare the timbre be- fore and after the overlap using speaker embeddings to distinguish interruptions from backchannels
-
[17]
Manual Verification:A team of hu- man annotators reviewed all automati- cally filtered segments to ensure quality and record interation events. • Annotation:We compiled the meta infor- mation provided by the dataset and hired hu- man experts to listen to the conversation seg- ments and annotate the corresponding interac- tion events and fluency descriptio...
-
[18]
Analyze the audio and identify all no- table interaction events
-
[19]
List every interactional phenomenon, such as interruptions or backchannels
-
[20]
What interaction events occurred in this dialogue? Provide timestamps
-
[21]
Scan the conversation for turn-taking events and provide a log
-
[22]
Detect and timestamp all interruptions, backchannels, and pauses
-
[23]
Provide a list of all interactional events present in the recording
-
[24]
Identify key turn-management events from the audio
-
[25]
Report any instances of overlapping speech or significant silence
-
[26]
What is happening in this conversation from a turn-taking perspective?
-
[27]
event_type
Log all communicative events beyond the speech content itself. •Example Ground-Truth Label: [ { " event_type " : " S u c c e s s f u l _ I n t e r r u p t i o n " , " start_time " : " 1 5 . 2 " , " end_time " : " 1 7 . 8 " } , { " event_type " : " Backchannel " , " start_time " : " 2 5 . 1 " , " end_time " : " 2 5 . 6 " } ] Task 2: Speaker Turn Segmentati...
-
[28]
Diarize the following conversation
-
[29]
Segment the audio by speaker turn, pro- viding timestamps for each
-
[30]
Who is speaking and when?
-
[31]
Provide a speaker diarization log for the provided audio
-
[32]
Identify the start and end times for each speaker’s utterance
-
[33]
Create a turn-by-turn breakdown of the dialogue
-
[34]
Which speaker is active at which times- tamp?
-
[35]
Table 5: Key hyperparameters for each stage of the training pipeline
Segment the speech into discrete turns for Speaker A and Speaker B. Table 5: Key hyperparameters for each stage of the training pipeline. Parameter Stage 1 (SFT-1) Stage 2 (SFT-2) Stage 3 (GRPO) Base Model Qwen2.5-Omni SFT-1 Checkpoint SFT-2 Checkpoint Trained Components Full Model Full Model LLM Only (Encoder Frozen) Learning Rate 1e-5 1e-5 1e-6 Batch Si...
-
[36]
Provide a complete speaker segmenta- tion
-
[37]
speaker
Analyze the audio and output the speaker turn timeline. •Example Ground-Truth Label: [ { " speaker " : " A " , " start_time " : " 0 . 5 " , " end_time " : " 5 . 1 " } , { " speaker " : " B " , " start_time " : " 5 . 4 " , " end_time " : " 1 0 . 2 " } , { " speaker " : " A " , " start_time " : " 1 0 . 3 " , " end_time " : " 1 5 . 2 " } ] Task 3: Full Times...
-
[38]
Provide a full, timestamped transcript of the conversation
-
[39]
Transcribe the dialogue, including speaker labels and timestamps
-
[40]
Generate a detailed script of the conver- sation with timing information
-
[41]
What was said in the dialogue? Provide a complete, timed transcript
-
[42]
Create a transcription with speaker and time annotations
-
[43]
Transcribe the audio from start to finish with all details
-
[44]
Output the full text of the conversation with speaker turns and times
-
[45]
Convert the spoken dialogue into a times- tamped text format
-
[46]
What is the full transcript of this interac- tion?
-
[47]
speaker
Provide a verbatim transcription anno- tated with speaker and time data. •Example Ground-Truth Label: [ { " speaker " : " A " , " start_time " : " 0 . 5 " , " end_time " : " 5 . 1 " , " text " : " Hello , I wanted to ask about the return policy for an item I bought online ." } , { " speaker " : " B " , " start_time " : " 5 . 4 " , " end_time " : " 1 0 . 2...
-
[48]
This is the gold standard for your as- sessment
Carefully read the providedGround-Truth Rationale And Conversation Transcrip- tions. This is the gold standard for your as- sessment
-
[49]
Read theGenerated CoTfrom the candidate model
-
[50]
Evaluate the alignment between the two based on the following criteria: • Correctness:Does the model correctly identify the key interaction events (e.g., interruptions, latencies, semantic errors) mentioned in the ground-truth ratio- nale? (Kai et al., 2012) •Completeness:Does the model capture all the critical success or failure points detailed in the gr...
2012
-
[51]
• 2:Poor Alignment (Catches some minor points but misses the main issue)
Assign a singleConsistency Scoreon a 5- point Likert scale, where: • 1:Very Poor Alignment (Completely misses the key points or contradicts the rationale). • 2:Poor Alignment (Catches some minor points but misses the main issue). • 3:Moderate Alignment (Identifies the main issue but with incomplete or flawed reasoning). • 4:Good Alignment (Accurately refl...
-
[52]
Review theGround-Truth Rationaleand all threeCandidate CoTs(A, B, and C) side-by- side
-
[53]
Select thesingle best CoTthat most effec- tively analyzes the dialogue
-
[54]
The winning CoT must identify the same core issues or suc- cesses as the human expert
Your decision should be based on the follow- ing criteria, in order of importance: (a) Alignment with Rationale:This is the most critical factor. The winning CoT must identify the same core issues or suc- cesses as the human expert. A model that correctly diagnoses a specific failure is superior to one that misses it, even if their final scores are the sa...
-
[55]
Inappropriate Barge-in
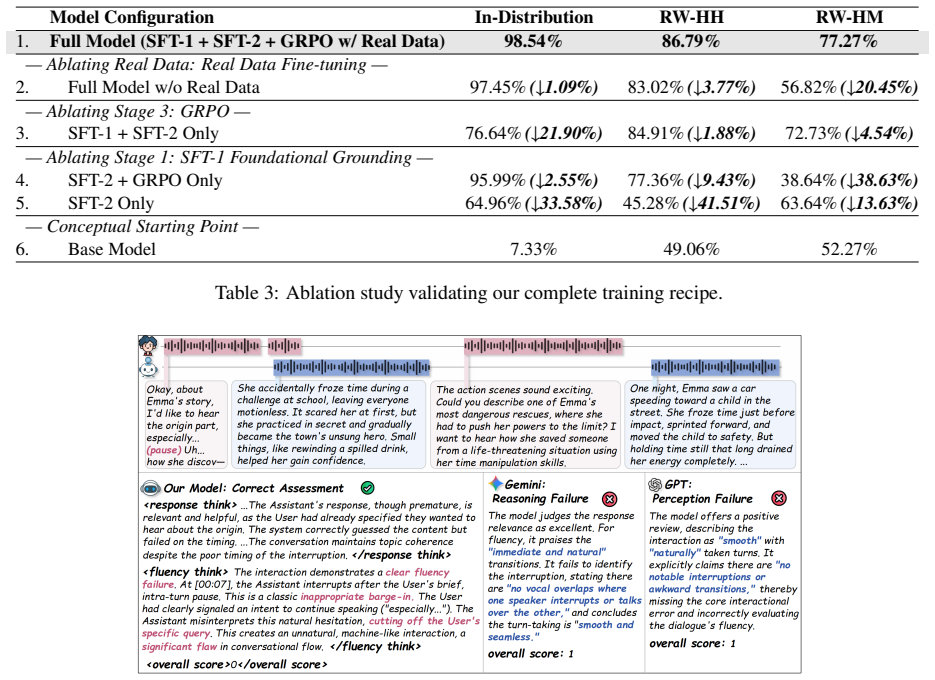
Record the label of your chosen candidate (e.g., ’Candidate B’). F Teacher Model Prompt for CoT Distillation To generate structured Chain-of-Thought (CoT) analyses from dialogue metadata, a powerful teacher model (e.g., a Gemini-class model) was guided by the prompt shown in Figure 24. This prompt instructs the model to produce a decoupled analysis of sem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.