Recognition: unknown
DockAnywhere: Data-Efficient Visuomotor Policy Learning for Mobile Manipulation via Novel Demonstration Generation
Pith reviewed 2026-05-10 10:14 UTC · model grok-4.3
The pith
Lifting one demonstration to many feasible docking points lets visuomotor policies succeed from unseen viewpoints in mobile manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
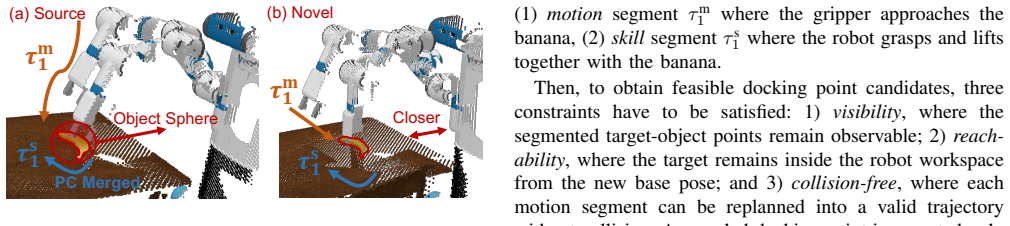
DockAnywhere lifts a trajectory to any feasible docking points by decoupling docking-dependent base motions from contact-rich manipulation skills that remain invariant across viewpoints. Feasible docking proposals are sampled under feasibility constraints, and corresponding trajectories are generated via structure-preserving augmentation. Visual observations are synthesized in 3D space by representing the robot and objects as point clouds and applying point-level spatial editing to ensure the consistency of observation and action across viewpoints.
What carries the argument
The demonstration-lifting pipeline that separates viewpoint-dependent base motion from invariant manipulation actions and uses point-level spatial editing on 3D point clouds to produce matching observations and actions for new docking locations.
If this is right
- Policies trained this way reach higher success rates on both simulation benchmarks and real robots when docking points vary.
- Generalization to novel viewpoints occurs without collecting additional real demonstrations for each new docking location.
- The same single human demonstration can support training across many feasible base positions instead of one fixed position.
- Real-world deployment becomes more practical because the robot no longer needs exact repetition of the training docking geometry.
Where Pith is reading between the lines
- The same separation of base motion from local skill could be applied to other mobile tasks where only the approach angle changes, such as door opening or drawer pulling from different sides.
- If point-cloud editing preserves action consistency reliably, the method could reduce the total number of human demonstrations needed for multi-view mobile manipulation by an order of magnitude.
- Testing whether the generated trajectories also improve sim-to-real transfer would be a direct next measurement.
Load-bearing premise
Contact-rich manipulation skills truly stay unchanged when the robot's base moves to a different docking spot, and point-cloud editing keeps the visual-action pairing consistent enough for policy learning.
What would settle it
Train a policy on demonstrations generated by the method and test it from a docking point never seen in the original data; if success rate remains near the level of a policy trained only on the single original demonstration, the central claim is false.
Figures





read the original abstract
Mobile manipulation is a fundamental capability that enables robots to interact in expansive environments such as homes and factories. Most existing approaches follow a two-stage paradigm, where the robot first navigates to a docking point and then performs fixed-base manipulation using powerful visuomotor policies. However, real-world mobile manipulation often suffers from the view generalization problem due to shifts of docking points. To address this issue, we propose a novel low-cost demonstration generation framework named DockAnywhere, which improves viewpoint generalization under docking variability by lifting a single demonstration to diverse feasible docking configurations. Specifically, DockAnywhere lifts a trajectory to any feasible docking points by decoupling docking-dependent base motions from contact-rich manipulation skills that remain invariant across viewpoints. Feasible docking proposals are sampled under feasibility constraints, and corresponding trajectories are generated via structure-preserving augmentation. Visual observations are synthesized in 3D space by representing the robot and objects as point clouds and applying point-level spatial editing to ensure the consistency of observation and action across viewpoints. Extensive experiments on ManiSkill and real-world platforms demonstrate that DockAnywhere substantially improves policy success rates and easily generalizes to novel viewpoints from unseen docking points during training, significantly enhancing the generalization capability of mobile manipulation policy in real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DockAnywhere, a low-cost demonstration generation framework for visuomotor policies in mobile manipulation. It lifts a single demonstration trajectory to diverse feasible docking configurations by decoupling docking-dependent base motions from contact-rich manipulation skills (assumed invariant across viewpoints), sampling feasible docks under constraints, and applying structure-preserving augmentation via 3D point-cloud spatial editing of robot and object representations to maintain observation-action consistency. Experiments on ManiSkill simulation and real platforms are claimed to show substantially improved policy success rates and generalization to novel/unseen docking points.
Significance. If the generated trajectories remain kinematically and dynamically valid, the method could meaningfully advance data-efficient learning for mobile manipulation by reducing reliance on extensive viewpoint-specific data collection, addressing a practical barrier to real-world deployment in unstructured settings. The point-cloud editing technique for cross-viewpoint consistency is a concrete technical contribution that could generalize to other augmentation pipelines.
major comments (2)
- [Method (decoupling and point-cloud augmentation)] Method section on decoupling and lifting: The central assumption that contact-rich manipulation skills remain invariant across docking-point shifts is load-bearing for the generalization claim but lacks supporting analysis. Base relocation changes arm reachable workspace, inverse-kinematics solutions, and contact forces/torques; point-level spatial editing preserves 3D positions but does not automatically ensure the original actions remain collision-free or executable from the new base. Without explicit validation (e.g., forward simulation or execution checks on augmented trajectories), the generated data may contain invalid examples that undermine reported improvements on unseen docks.
- [Experiments] Experimental evaluation: The abstract states improvements on ManiSkill and real platforms, yet the manuscript provides no quantitative breakdown of success rates, baselines (e.g., standard BC or viewpoint-augmented policies), trial counts, or controls for data volume and policy architecture. Specific results tables or figures comparing seen vs. unseen docking points are required to substantiate the generalization claim; without them the quantitative gains cannot be assessed as load-bearing evidence.
minor comments (2)
- [Abstract] Abstract: The final sentence repeats the generalization benefit; tightening would improve conciseness.
- [Method] Notation and reproducibility: The terms 'structure-preserving augmentation' and 'feasibility constraints' are used without formal definitions or pseudocode; adding a short algorithm box or explicit equations would aid replication.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. Below we provide point-by-point responses to the major comments, outlining how we plan to address them in the revised version.
read point-by-point responses
-
Referee: [Method (decoupling and point-cloud augmentation)] Method section on decoupling and lifting: The central assumption that contact-rich manipulation skills remain invariant across docking-point shifts is load-bearing for the generalization claim but lacks supporting analysis. Base relocation changes arm reachable workspace, inverse-kinematics solutions, and contact forces/torques; point-level spatial editing preserves 3D positions but does not automatically ensure the original actions remain collision-free or executable from the new base. Without explicit validation (e.g., forward simulation or execution checks on augmented trajectories), the generated data may contain invalid examples that undermine reported improvements on unseen docks.
Authors: We appreciate the referee's detailed analysis of the method's assumptions. In DockAnywhere, the decoupling separates the base navigation (which varies with docking point) from the manipulation phase, which is executed after docking and thus from a fixed relative pose to the object. Feasibility constraints during sampling include reachability checks using the robot's kinematic model to ensure the arm can reach the target from the new base position. The structure-preserving point-cloud augmentation maintains the 3D geometry and relative positions, ensuring that the original action sequences (defined in the end-effector or joint space relative to the object) remain applicable without collision in the new configuration, as the editing is rigid transformation based on the new dock. Nevertheless, we acknowledge the value of additional validation and will incorporate forward simulation results and collision checks on a subset of augmented trajectories in the revised version to empirically support the validity of the generated data. revision: yes
-
Referee: [Experiments] Experimental evaluation: The abstract states improvements on ManiSkill and real platforms, yet the manuscript provides no quantitative breakdown of success rates, baselines (e.g., standard BC or viewpoint-augmented policies), trial counts, or controls for data volume and policy architecture. Specific results tables or figures comparing seen vs. unseen docking points are required to substantiate the generalization claim; without them the quantitative gains cannot be assessed as load-bearing evidence.
Authors: We will revise the manuscript to include a quantitative breakdown of success rates, comparisons to baselines such as standard behavior cloning and viewpoint-augmented policies, trial counts, controls for data volume and policy architecture, and specific results tables or figures comparing seen vs. unseen docking points. This will substantiate the generalization claim with load-bearing evidence. revision: yes
Circularity Check
No circularity: constructive data-augmentation pipeline with external constraints
full rationale
The paper describes a new demonstration-generation pipeline that starts from a single human demonstration, applies explicit decoupling of base motions from invariant manipulation skills, samples docking points under stated feasibility constraints, and performs point-cloud spatial editing to synthesize consistent observations and actions. None of these steps reduce by construction to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations; the method is presented as an external augmentation procedure whose validity rests on geometric and kinematic constraints rather than on re-deriving its own outputs. No equations or uniqueness theorems are invoked that collapse the claimed generalization improvement back into the input demonstration itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Perceptive model predictive control for continuous mobile manipulation,
J. Pankert and M. Hutter, “Perceptive model predictive control for continuous mobile manipulation,”IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 6177–6184, 2020
2020
-
[2]
A holistic approach to reactive mobile manipulation,
J. Haviland, N. S ¨underhauf, and P. Corke, “A holistic approach to reactive mobile manipulation,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3122–3129, 2022
2022
-
[3]
Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation,
C. Li, M. Xu, A. Bahety, H. Yin, Y . Jiang, H. Huang, J. Wong, S. Garlanka, C. Gokmen, R. Zhanget al., “Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation,” inRSS 2025 Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond
2025
-
[4]
Moto: A zero-shot plug-in interaction-aware navigation for general mobile manipulation,
Z. Wu, A. Ma, X. Xu, H. Yin, Y . Liang, Z. Wang, J. Lu, and H. Yan, “Moto: A zero-shot plug-in interaction-aware navigation for general mobile manipulation,”arXiv preprint arXiv:2509.01658, 2025
-
[5]
Motion planning of mobile manipulator for navigation including door traversal,
K. Jang, S. Kim, and J. Park, “Motion planning of mobile manipulator for navigation including door traversal,”IEEE Robotics and Automa- tion Letters, vol. 8, no. 7, pp. 4147–4154, 2023
2023
-
[6]
Mobi-π: Mobilizing your robot learning policy,
J. Yang, I. Huang, B. Vu, M. Bajracharya, R. Antonova, and J. Bohg, “Mobi-\pi: Mobilizing your robot learning policy,”arXiv preprint arXiv:2505.23692, 2025
-
[7]
N2m: Bridging navigation and manipulation by learning pose preference from rollout,
K. Chai, H. Lee, and J. J. Lim, “N2m: Bridging navigation and manipulation by learning pose preference from rollout,”arXiv preprint arXiv:2509.18671, 2025
-
[8]
Momanipvla: Transfer- ring vision-language-action models for general mobile manipulation,
Z. Wu, Y . Zhou, X. Xu, Z. Wang, and H. Yan, “Momanipvla: Transfer- ring vision-language-action models for general mobile manipulation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1714–1723
2025
-
[9]
K. Gubernatorov, A. V oronov, R. V oronov, S. Pasynkov, S. Perminov, Z. Guo, and D. Tsetserukou, “Anywherevla: Language-conditioned ex- ploration and mobile manipulation,”arXiv preprint arXiv:2509.21006, 2025
-
[10]
EchoVLA: Synergistic Declarative Memory for VLA -Driven Mobile Manipulation,
M. Lin, X. Liang, B. Lin, L. Jingzhi, Z. Jiao, K. Li, Y . Ma, Y . Liu, S. Zhao, Y . Zhuanget al., “Echovla: Robotic vision-language-action model with synergistic declarative memory for mobile manipulation,” arXiv preprint arXiv:2511.18112, 2025
-
[11]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,”Advances in neural information processing systems, vol. 37, pp. 5285–5307, 2024
2024
-
[12]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu, “Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,”IEEE Transactions on Robotics, vol. 39, no. 5, pp. 3929–3945, 2023
2023
-
[13]
Movie: Visual model-based policy adaptation for view generalization,
S. Yang, Y . Ze, and H. Xu, “Movie: Visual model-based policy adaptation for view generalization,”Advances in Neural Information Processing Systems, vol. 36, pp. 21 507–21 523, 2023
2023
-
[14]
Z. Yuan, T. Wei, S. Cheng, G. Zhang, Y . Chen, and H. Xu, “Learn- ing to manipulate anywhere: A visual generalizable framework for reinforcement learning,”arXiv preprint arXiv:2407.15815, 2024
-
[15]
Emma: Scaling mobile manipulation via egocentric human data.arXiv preprint arXiv:2509.04443, 2025
L. Y . Zhu, P. Kuppili, R. Punamiya, P. Aphiwetsa, D. Patel, S. Kareer, S. Ha, and D. Xu, “Emma: Scaling mobile manipulation via egocentric human data,”arXiv preprint arXiv:2509.04443, 2025
-
[16]
Z. Yuan, T. Wei, L. Gu, P. Hua, T. Liang, Y . Chen, and H. Xu, “Hermes: Human-to-robot embodied learning from multi-source motion data for mobile dexterous manipulation,”arXiv preprint arXiv:2508.20085, 2025
-
[17]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox, “Mimicgen: A data generation system for scalable robot learning using human demonstrations,”arXiv preprint arXiv:2310.17596, 2023
-
[18]
C. Garrett, A. Mandlekar, B. Wen, and D. Fox, “Skillmimicgen: Automated demonstration generation for efficient skill learning and deployment,”arXiv preprint arXiv:2410.18907, 2024
-
[19]
Z. Xue, S. Deng, Z. Chen, Y . Wang, Z. Yuan, and H. Xu, “Demogen: Synthetic demonstration generation for data-efficient visuomotor pol- icy learning,”arXiv preprint arXiv:2502.16932, 2025
-
[20]
Human-in-the-loop task and motion planning for imitation learning,
A. Mandlekar, C. R. Garrett, D. Xu, and D. Fox, “Human-in-the-loop task and motion planning for imitation learning,” inConference on Robot Learning. PMLR, 2023, pp. 3030–3060
2023
-
[21]
Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su, “Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,”Robotics: Science and Systems, 2025
2025
-
[22]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,” inProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[23]
Learning and reasoning with action-related places for robust mobile manipulation,
F. Stulp, A. Fedrizzi, L. M ¨osenlechner, and M. Beetz, “Learning and reasoning with action-related places for robust mobile manipulation,” Journal of Artificial Intelligence Research, vol. 43, pp. 1–42, 2012
2012
-
[24]
Genaug: Retargeting behaviors to unseen situ- ations via generative augmentation, 2023
Z. Chen, S. Kiami, A. Gupta, and V . Kumar, “Genaug: Retargeting behaviors to unseen situations via generative augmentation,”arXiv preprint arXiv:2302.06671, 2023
-
[25]
Rocoda: Coun- terfactual data augmentation for data-efficient robot learning from demonstrations,
E. Ameperosa, J. A. Collins, M. Jain, and A. Garg, “Rocoda: Coun- terfactual data augmentation for data-efficient robot learning from demonstrations,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 13 250–13 256
2025
-
[26]
C. Yuan, S. Joshi, S. Zhu, H. Su, H. Zhao, and Y . Gao, “Roboengine: Plug-and-play robot data augmentation with semantic robot segmen- tation and background generation,”arXiv preprint arXiv:2503.18738, 2025
-
[27]
Demonstrate once, imitate immediately (dome): Learning visual servoing for one- shot imitation learning,
E. Valassakis, G. Papagiannis, N. Di Palo, and E. Johns, “Demonstrate once, imitate immediately (dome): Learning visual servoing for one- shot imitation learning,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 8614– 8621
2022
-
[28]
You only demonstrate once: Category-level manipulation from single visual demonstration,
B. Wen, W. Lian, K. Bekris, and S. Schaal, “You only demonstrate once: Category-level manipulation from single visual demonstration,” arXiv preprint arXiv:2201.12716, 2022
-
[29]
Coarse-to-fine imitation learning: Robot manipulation from a single demonstration,
E. Johns, “Coarse-to-fine imitation learning: Robot manipulation from a single demonstration,” in2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021, pp. 4613–4619
2021
-
[30]
View-invariant policy learning via zero-shot novel view synthesis,
S. Tian, B. Wulfe, K. Sargent, K. Liu, S. Zakharov, V . Guizilini, and J. Wu, “View-invariant policy learning via zero-shot novel view synthesis,”arXiv preprint arXiv:2409.03685, 2024
-
[31]
L. Y . Chen, C. Xu, K. Dharmarajan, M. Z. Irshad, R. Cheng, K. Keutzer, M. Tomizuka, Q. Vuong, and K. Goldberg, “Rovi- aug: Robot and viewpoint augmentation for cross-embodiment robot learning,”arXiv preprint arXiv:2409.03403, 2024
-
[32]
Constraint-preserving data gen- eration for visuomotor policy learning
K. Lin, V . Ragunath, A. McAlinden, A. Prasad, J. Wu, Y . Zhu, and J. Bohg, “Constraint-preserving data generation for visuomotor policy learning,”arXiv preprint arXiv:2508.03944, 2025
-
[33]
Asynchronous feedback network for perceptual point cloud quality assessment,
Y . Zhang, Q. Yang, Z. Shan, and Y . Xu, “Asynchronous feedback network for perceptual point cloud quality assessment,”IEEE Trans- actions on Circuits and Systems for Video Technology, 2024
2024
-
[34]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660
2017
-
[35]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yanet al., “Grounded sam: Assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
work page Pith review arXiv 2024
-
[36]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu, “Robocasa: Large-scale simulation of ev- eryday tasks for generalist robots,”arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.