CoGrid & the Multi-User Gymnasium: A Framework for Multi-Agent Experimentation
Pith reviewed 2026-05-10 10:32 UTC · model grok-4.3
The pith
CoGrid and Multi-User Gymnasium give researchers ready tools to run interactive experiments with multiple humans and AI agents in shared grid worlds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
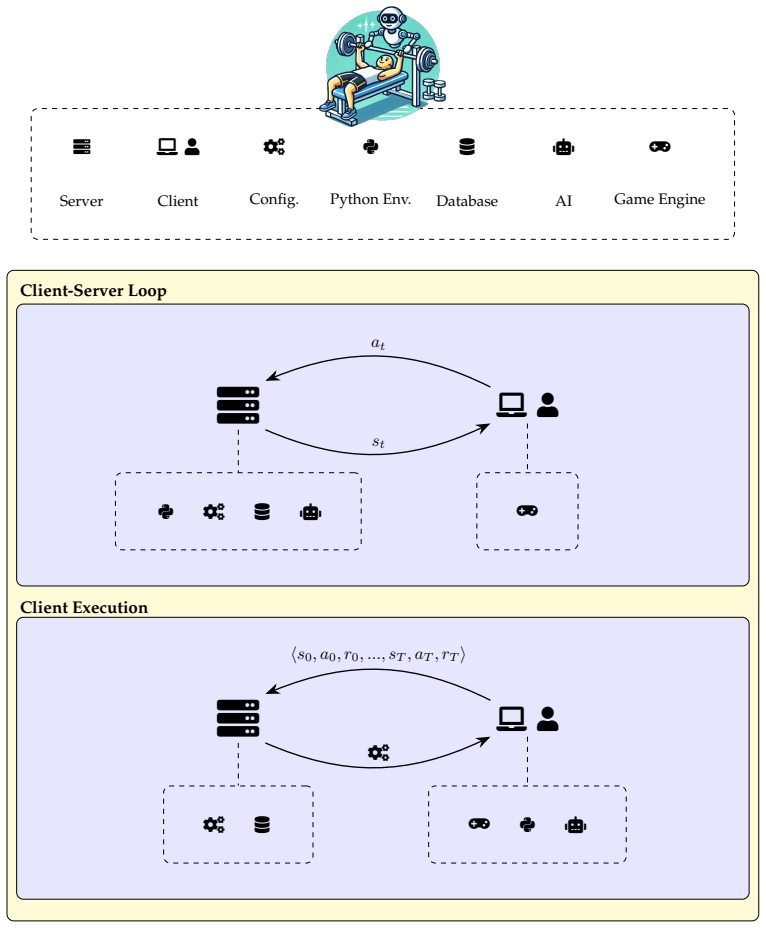
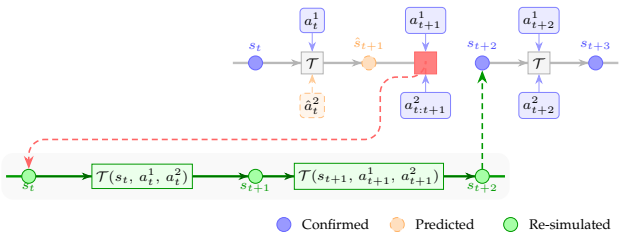
The authors claim that CoGrid supplies a flexible multi-agent grid simulation with dual numerical backends while Multi-User Gymnasium directly maps those environments to web pages that support simultaneous human and AI control, using either centralized or distributed networking with rollback netcode to compensate for latency, thereby enabling scalable studies of human-AI social decision making.
What carries the argument
CoGrid multi-agent grid simulation library paired with Multi-User Gymnasium web translator and networking layer for mixed human-AI sessions.
If this is right
- Studies of social decision making can now include real humans interacting with AI agents inside the same simulated space.
- Experiments become feasible with any number of simultaneous participants without researchers writing their own networking code.
- Inquiry into psychology, cognition, and decision making can be tied directly to observable human-AI coordination patterns.
- Open-source release allows labs to replicate or extend the same environments for comparative work.
Where Pith is reading between the lines
- The same infrastructure could support training loops where human feedback shapes AI policies in real time rather than offline.
- Researchers studying human-AI trust or coordination failures could add logging of every interaction without extra engineering.
- Because the system builds on existing Gymnasium conventions, many single-agent environments could be quickly extended to multi-user versions.
Load-bearing premise
The described features of CoGrid and MUG will turn out flexible enough, fast enough, and simple enough for researchers to adopt across many different human-AI experiment designs.
What would settle it
A team tries to run a five-human, three-AI cooperative task in a 10-by-10 grid and finds that either the web client cannot maintain consistent state across participants or the required custom code exceeds what a typical psychology lab can produce in a week.
Figures

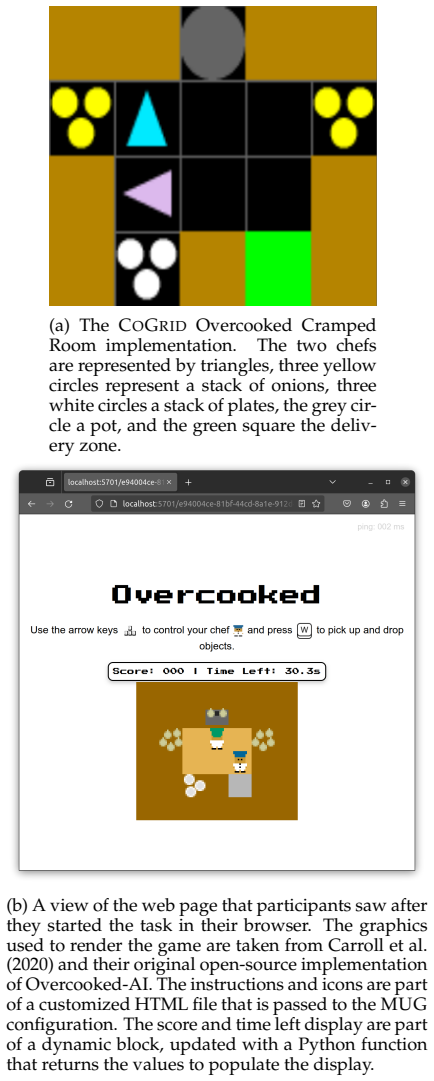
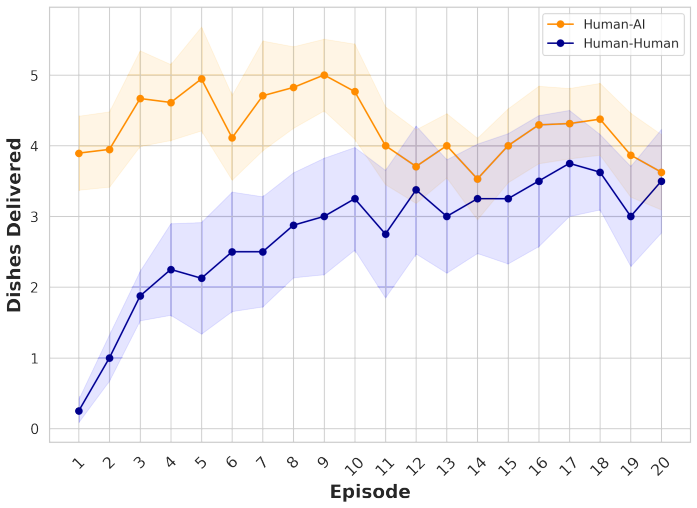
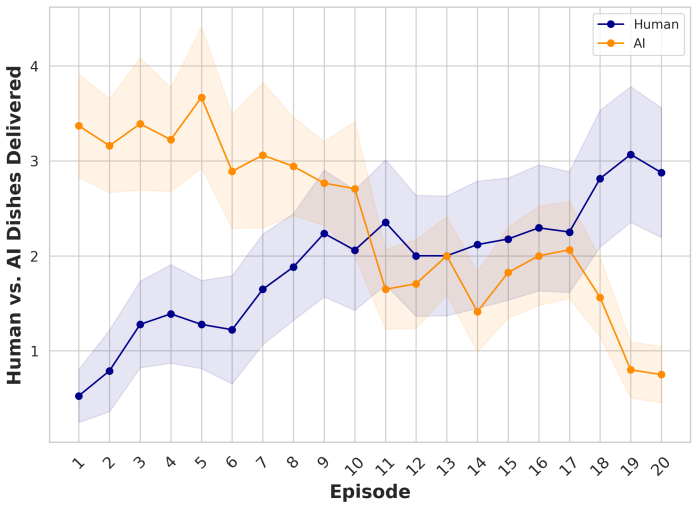

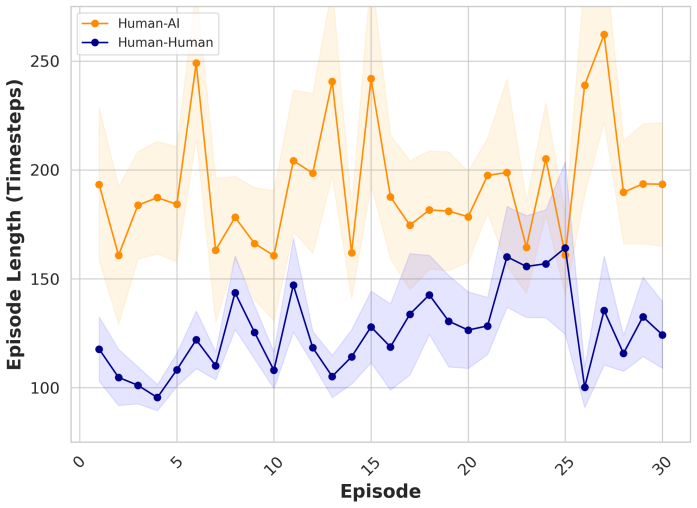
read the original abstract
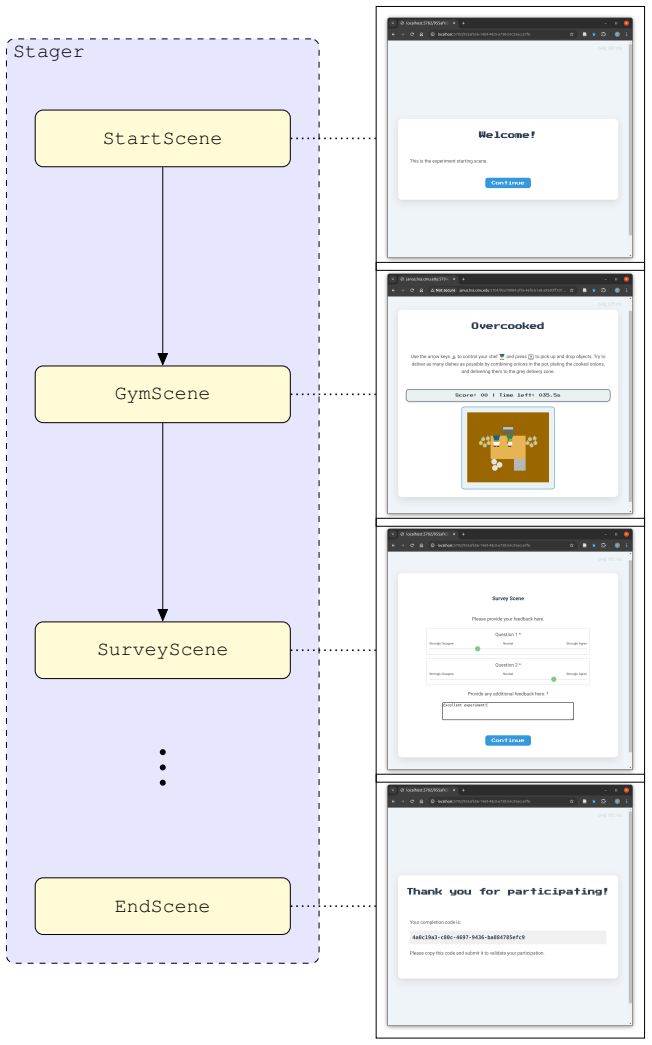
The increasing integration of artificial intelligence (AI) in everyday life brings with it new challenges and questions for regarding how humans interact with autonomous agents. Multi-agent experiments, where humans and AI act together, can offer important opportunities to study social decision making, but there is a lack of accessible tooling available to researchers to run such experiments. We introduce two tools designed to reduce these barriers. The first, CoGrid, is a multi-agent grid-based simulation library with dual NumPy and JAX backends. The second, Multi-User Gymnasium (MUG), translates such simulation environments directly into interactive web-based experiments. MUG supports interactions with arbitrary numbers of humans and AI, utilizing either server-authoritative or peer-to-peer networking with rollback netcode to account for latency. Together, these tools can enable researchers to deploy studies of human-AI interaction, facilitating inquiry into core questions of psychology, cognition, and decision making and their relationship to human-AI interaction. Both tools are open source and available to the broader research community. Documentation and source code is available at {cogrid, multi-user-gymnasium}.readthedocs.io. This paper details the functionality of these tools and presents several case studies to illustrate their utility in human-AI multi-agent experimentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces two open-source tools to facilitate multi-agent human-AI experiments: CoGrid, a grid-based simulation library with dual NumPy and JAX backends for efficient multi-agent modeling, and Multi-User Gymnasium (MUG), which converts such environments into interactive web-based experiments supporting arbitrary numbers of human and AI participants via server-authoritative or peer-to-peer networking with rollback netcode for latency handling. The paper describes the architecture and functionality of both tools and includes case studies illustrating their application to questions in psychology, cognition, and decision-making.
Significance. If the described functionality holds, the work provides a practical contribution to the HCI and multi-agent systems communities by lowering barriers to conducting controlled human-AI interaction studies. The dual-backend design in CoGrid and the networking/rollback features in MUG directly address performance and real-time interaction needs that are often pain points in existing frameworks, potentially enabling reproducible, scalable experiments that integrate humans and AI agents.
major comments (1)
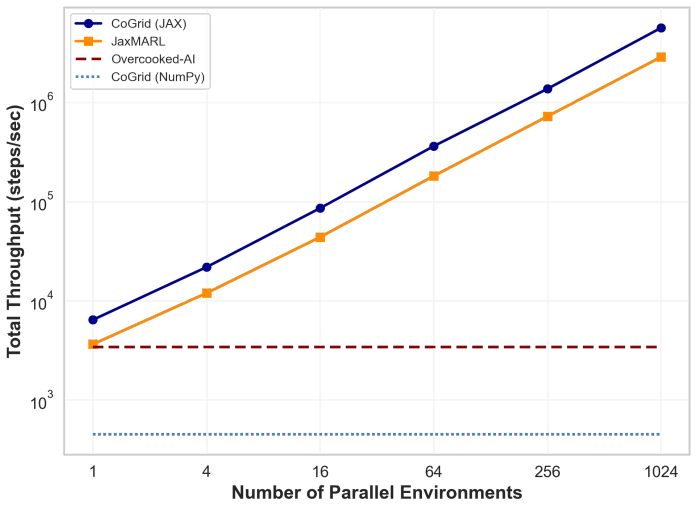
- [Case studies] Case studies section: The case studies demonstrate intended usage but provide no quantitative benchmarks (e.g., latency, throughput, or scalability under increasing agent counts) or validation data for the networking and rollback mechanisms, leaving the claims of flexibility and performance for arbitrary numbers of agents without empirical support.
minor comments (2)
- [Abstract] Abstract: The phrase 'questions for regarding how humans interact' contains a grammatical error that should be corrected for clarity.
- [Introduction] The paper would benefit from explicit links or a table comparing CoGrid/MUG features against related frameworks (e.g., standard Gymnasium, other multi-agent simulators) to better highlight novelty and adoption advantages.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work as a practical contribution and for the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: Case studies section: The case studies demonstrate intended usage but provide no quantitative benchmarks (e.g., latency, throughput, or scalability under increasing agent counts) or validation data for the networking and rollback mechanisms, leaving the claims of flexibility and performance for arbitrary numbers of agents without empirical support.
Authors: We agree that the case studies section, as currently written, focuses on demonstrating intended usage and qualitative applications to questions in psychology, cognition, and decision-making, without quantitative performance data. This leaves the claims regarding flexibility and performance for arbitrary agent counts without direct empirical support in the manuscript. To address this, we will revise the manuscript by expanding the case studies section (or adding a dedicated performance subsection) to include quantitative benchmarks. These will cover latency and throughput measurements, scalability results under increasing agent counts, and validation experiments for the server-authoritative and peer-to-peer networking modes including the rollback netcode under controlled latency conditions. The added material will be based on reproducible experiments using the open-source tools themselves. revision: yes
Circularity Check
No significant circularity; paper introduces software tools without derivations or equations
full rationale
The paper is a software framework description introducing CoGrid (multi-agent grid simulation with NumPy/JAX backends) and MUG (web-based multi-user experimentation layer with networking). It contains no equations, derivations, fitted parameters, or load-bearing self-citations that reduce any claim to its own inputs by construction. The contribution is the tools and their documented architecture, which is presented directly without any predictive or uniqueness claims that loop back to prior results. This is a standard non-circular tool-release paper.
Axiom & Free-Parameter Ledger
invented entities (2)
-
CoGrid
no independent evidence
-
Multi-User Gymnasium (MUG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
an indicator of whether the pot is reachable,
-
[2]
a one-hot representation of the pot status, which can be empty, cooking, or ready
-
[3]
the number of onions in the pot,
-
[4]
the number of cooking timesteps remaining for the pot,
-
[5]
an array of the row and column distances to the pot,
-
[6]
• Agent j’s distance to the other chef
the row and column location of the pot. • Agent j’s distance to the other chef. • Agent j’s row and column position in the grid. A.2 Training a Reinforcement Learning Agent We train a reinforcement learning agent in the Overcooked environment using RLlib (Liang et al., 2018) and the PPO algorithm. A dish delivery reward of 1.0 is given when a dish is deli...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.