Recognition: unknown
Learning Where to Embed: Noise-Aware Positional Embedding for Query Retrieval in Small-Object Detection
Pith reviewed 2026-05-10 12:07 UTC · model grok-4.3
The pith
Noise-aware positional embedding enables shallower decoders for accurate small-object detection in transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Heatmap-guided Embedding Learning Paradigm (HELP) with Heatmap-guided Positional Embedding (HPE) can guide feature encoding and query filtering to suppress background noise, allowing high-quality small-object query retrieval with significantly reduced decoder depth and parameters, all without extra inference cost.
What carries the argument
Heatmap-guided Positional Embedding (HPE), a mechanism that injects positional encodings selectively based on heatmap salience to preserve foreground information and filter out background-dominant queries via a gradient-based mask.
If this is right
- Decoder layers reduced from eight to three while maintaining accuracy gains.
- Model parameters reduced by 59.4% from 163M to 66.3M.
- Consistent performance improvements across benchmarks under lower compute budgets.
- Linear-Snake Convolution enriches sparse features for better small-target representation.
- Gradient supervision for the mask applies only at training time, with zero added cost at inference.
Where Pith is reading between the lines
- This approach of selective positional embedding might generalize to other attention-based vision tasks where background noise affects query quality.
- Combining this noise suppression with other efficiency methods like knowledge distillation could yield even more compact detectors for mobile applications.
- Evaluating the method on additional datasets with varying object densities could confirm its robustness beyond the reported benchmarks.
Load-bearing premise
The heatmap guidance and mask filter can reliably separate background noise from useful positional signals for small objects without removing essential localization information.
What would settle it
Running the three-layer decoder version on a standard small-object detection benchmark and observing whether its average precision falls below that of the original eight-layer model without the proposed embedding.
Figures





read the original abstract
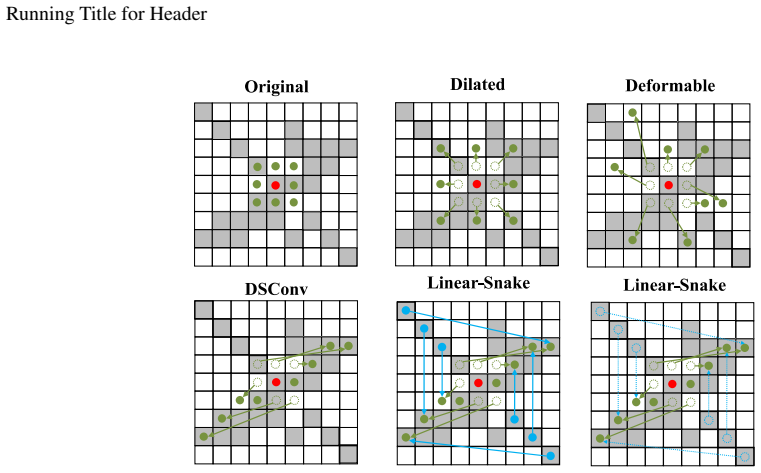
Transformer-based detectors have advanced small-object detection, but they often remain inefficient and vulnerable to background-induced query noise, which motivates deep decoders to refine low-quality queries. We present HELP (Heatmap-guided Embedding Learning Paradigm), a noise-aware positional-semantic fusion framework that studies where to embed positional information by selectively preserving positional encodings in foreground-salient regions while suppressing background clutter. Within HELP, we introduce Heatmap-guided Positional Embedding (HPE) as the core embedding mechanism and visualize it with a heatbar for interpretable diagnosis and fine-tuning. HPE is integrated into both the encoder and decoder: it guides noise-suppressed feature encoding by injecting heatmap-aware positional encoding, and it enables high-quality query retrieval by filtering background-dominant embeddings via a gradient-based mask filter before decoding. To address feature sparsity in complex small targets, we integrate Linear-Snake Convolution to enrich retrieval-relevant representations. The gradient-based heatmap supervision is used during training only, incurring no additional gradient computation at inference. As a result, our design reduces decoder layers from eight to three and achieves a 59.4% parameter reduction (66.3M vs. 163M) while maintaining consistent accuracy gains under a reduced compute budget across benchmarks. Code Repository: https://github.com/yidimopozhibai/Noise-Suppressed-Query-Retrieval
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HELP (Heatmap-guided Embedding Learning Paradigm), a noise-aware positional-semantic fusion framework for transformer-based small-object detection. It proposes Heatmap-guided Positional Embedding (HPE) to selectively preserve positional encodings in foreground regions while suppressing background clutter via a gradient-based mask filter, integrated into both encoder and decoder; Linear-Snake Convolution is added to address feature sparsity. The central empirical claim is that this enables reducing decoder layers from 8 to 3, yielding a 59.4% parameter reduction (66.3M vs. 163M) while maintaining consistent accuracy gains across benchmarks under lower compute, with heatmap supervision used only at training time.
Significance. If the accuracy claims hold after rigorous validation, the work could meaningfully advance efficient transformer detectors for small objects by mitigating query noise without deep decoders, which is relevant for resource-constrained applications such as aerial imagery or medical imaging. The interpretable heatbar visualization for HPE and the training-only supervision are practical strengths; the code repository is a positive for reproducibility.
major comments (2)
- [Abstract and §3.2] Abstract and §3.2 (gradient-based mask filter): The headline result of maintaining accuracy with a 3-layer decoder and 59.4% parameter reduction rests on the untested premise that the mask reliably separates foreground-salient positional encodings from background clutter at small-object scales without discarding localization cues. No ablation isolating the mask's contribution (e.g., vs. Linear-Snake Convolution alone) or quantitative metrics on false-negative rates for small objects is referenced, which directly undermines the reduced-decoder claim.
- [§4] §4 (experiments): The abstract states 'consistent accuracy gains' and efficiency numbers, but the provided details lack full baseline comparisons, error bars, or cross-benchmark tables showing that gains persist when decoder depth is fixed and only HPE+mask are added. This makes it impossible to confirm the data support the central efficiency-accuracy tradeoff.
minor comments (2)
- [§3] The new terms 'Heatmap-guided Positional Embedding (HPE)' and 'Linear-Snake Convolution' are introduced without explicit equations or pseudocode in the abstract; adding these in §3 would improve clarity and allow direct comparison to prior positional embeddings (e.g., in DETR variants).
- [Figures] The heatbar visualization is mentioned for interpretable diagnosis; ensure all figures include scale bars and are referenced in the text for fine-tuning guidance.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments correctly identify areas where additional ablations and experimental details would strengthen the presentation of the efficiency-accuracy claims. We address each point below and will incorporate the requested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3.2] Abstract and §3.2 (gradient-based mask filter): The headline result of maintaining accuracy with a 3-layer decoder and 59.4% parameter reduction rests on the untested premise that the mask reliably separates foreground-salient positional encodings from background clutter at small-object scales without discarding localization cues. No ablation isolating the mask's contribution (e.g., vs. Linear-Snake Convolution alone) or quantitative metrics on false-negative rates for small objects is referenced, which directly undermines the reduced-decoder claim.
Authors: We agree that an explicit ablation isolating the gradient-based mask filter is necessary to substantiate the reduced-decoder claim. In the revision we will add a dedicated ablation table comparing (i) the full HELP model, (ii) HPE without the mask, (iii) Linear-Snake Convolution alone, and (iv) the mask applied without HPE. We will also report quantitative false-negative rates on small-object localization (measured via bounding-box IoU thresholds) to quantify any loss of localization cues. These additions will directly address the concern while preserving the training-only nature of the supervision. revision: yes
-
Referee: [§4] §4 (experiments): The abstract states 'consistent accuracy gains' and efficiency numbers, but the provided details lack full baseline comparisons, error bars, or cross-benchmark tables showing that gains persist when decoder depth is fixed and only HPE+mask are added. This makes it impossible to confirm the data support the central efficiency-accuracy tradeoff.
Authors: We acknowledge that the current experimental section would benefit from more granular controls. In the revision we will expand §4 with: (a) full baseline tables including standard DETR and Deformable DETR at decoder depths 8, 6, 4, and 3; (b) results with error bars from three independent runs; and (c) cross-benchmark tables that fix decoder depth at 3 and incrementally add only HPE and the mask. These controlled experiments will isolate the contribution of the proposed components to the observed efficiency-accuracy tradeoff. revision: yes
Circularity Check
No circularity: empirical architectural design with no derivational reduction
full rationale
The manuscript introduces HELP as an empirical noise-aware embedding framework for small-object detection, relying on proposed components (HPE, gradient-based mask filter, Linear-Snake Convolution) whose benefits are asserted via benchmark experiments rather than any closed mathematical derivation. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims; the decoder-layer reduction and parameter savings are presented as observed outcomes of the design choices, not as quantities forced by construction from the inputs. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Heatmap-guided Positional Embedding (HPE)
no independent evidence
-
Linear-Snake Convolution
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Mind the Unseen Mass: Unmasking LLM Hallucinations via Soft-Hybrid Alphabet Estimation
SHADE adaptively combines coverage and spectral signals to estimate semantic alphabet size from few LLM samples, yielding better performance than baselines in low-sample regimes for alphabet estimation and QA error detection.
Reference graph
Works this paper leans on
-
[1]
A review of small object detection based on deep learning
Wei Wei, Yu Cheng, Jiafeng He, and Xiyue Zhu. A review of small object detection based on deep learning. Neural Comput. Appl., 36(12):6283–6303, 2024
2024
-
[2]
Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing.IEEE TPAMI, 2022
Xue Yang, Junchi Yan, Wenlong Liao, Xiaokang Yang, Jin Tang, and Tao He. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing.IEEE TPAMI, 2022
2022
-
[3]
Efficient unsupervised clustering of hyperspectral images via flexible multi-anchor graphs.Remote Sens., 17(15):2647, 2025
Yihong Li, Ting Wang, Zhe Cao, Haonan Xin, and Rong Wang. Efficient unsupervised clustering of hyperspectral images via flexible multi-anchor graphs.Remote Sens., 17(15):2647, 2025
2025
-
[4]
Mdpcaps-csl for sar image target recognition with limited labeled training data.IEEE Access, 8:176217–176231, 2020
Yuchao Hou, Ting Xu, Hongping Hu, Peng Wang, Hongxin Xue, and Yanping Bai. Mdpcaps-csl for sar image target recognition with limited labeled training data.IEEE Access, 8:176217–176231, 2020
2020
-
[5]
Palmprobnet: A probabilistic approach to understanding palm distributions in ecuadorian tropical forest via transfer learning
Kangning Cui, Zishan Shao, Gregory Larsen, Victor Pauca, Sarra Alqahtani, David Segurado, João Pinheiro, Manqi Wang, David Lutz, Robert Plemmons, et al. Palmprobnet: A probabilistic approach to understanding palm distributions in ecuadorian tropical forest via transfer learning. InProceedings of the 2024 ACM Southeast Conference, pages 272–277, 2024
2024
-
[6]
Superpixel-based and spatially regularized diffusion learning for unsupervised hyperspectral image clustering.IEEE Transactions on Geoscience and Remote Sensing, 62:1–18, 2024
Kangning Cui, Ruoning Li, Sam L Polk, Yinyi Lin, Hongsheng Zhang, James M Murphy, Robert J Plemmons, and Raymond H Chan. Superpixel-based and spatially regularized diffusion learning for unsupervised hyperspectral image clustering.IEEE Transactions on Geoscience and Remote Sensing, 62:1–18, 2024
2024
-
[7]
Towards large-scale small object detection: Survey and benchmarks.IEEE TPAMI, 45(11):13467–13488, 2023
Gong Cheng, Xiang Yuan, Xiwen Yao, Kebing Yan, Qinghua Zeng, Xingxing Xie, and Junwei Han. Towards large-scale small object detection: Survey and benchmarks.IEEE TPAMI, 45(11):13467–13488, 2023
2023
-
[8]
Efficient localization and spatial distribution modeling of canopy palms using uav imagery.IEEE TGRS, 2025
Kangning Cui, Wei Tang, Rongkun Zhu, Manqi Wang, Gregory D Larsen, Victor P Pauca, Sarra Alqahtani, Fan Yang, David Segurado, Paul Fine, et al. Efficient localization and spatial distribution modeling of canopy palms using uav imagery.IEEE TGRS, 2025
2025
-
[9]
Slicing aided hyper inference and fine-tuning for small object detection
Fatih Cagatay Akyon, Sinan Onur Altinuc, and Alptekin Temizel. Slicing aided hyper inference and fine-tuning for small object detection. InICIP, pages 966–970. IEEE, 2022
2022
-
[10]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
Dongming Jiang, Yi Li, Guanpeng Li, and Bingzhe Li. Magma: A multi-graph based agentic memory architecture for ai agents.arXiv preprint arXiv:2601.03236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Detrs beat yolos on real-time object detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection. InCVPR, pages 16965–16974, 2024
2024
-
[12]
Dino: Detr with improved denoising anchor boxes for end-to-end object detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel Ni, and Harry Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. InICLR, 2023
2023
-
[13]
Rui-Feng Wang, Daniel Petti, Yue Chen, and Changying Li. Dinov3 visual representations for blueberry perception toward robotic harvesting.arXiv preprint arXiv:2603.02419, 2026
-
[14]
Rongkun Zhu, Kangning Cui, Wei Tang, Rui-Feng Wang, Sarra Alqahtani, David Lutz, Fan Yang, Paul Fine, Jordan Karubian, Robert Plemmons, et al. From orthomosaics to raw uav imagery: Enhancing palm detection and crown-center localization.arXiv preprint arXiv:2509.12400, 2025. 11 Running Title for Header
-
[15]
Conditional for fast training convergence
Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, and Jingdong Wang. Conditional for fast training convergence. InICCV, pages 3651–3660, 2021
2021
-
[16]
Dn-detr: Accelerate detr training by introducing query denoising
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by introducing query denoising. InCVPR, pages 13619–13627, 2022
2022
-
[17]
arXiv preprint arXiv:2602.19320 , year=
Dongming Jiang, Yi Li, Songtao Wei, Jinxin Yang, Ayushi Kishore, Alysa Zhao, Dingyi Kang, Xu Hu, Feng Chen, Qiannan Li, et al. Anatomy of agentic memory: Taxonomy and empirical analysis of evaluation and system limitations.arXiv preprint arXiv:2602.19320, 2026
-
[18]
Center-guided classifier for semantic segmentation of remote sensing images.IEEE TGRS, 2026
Wei Zhang, Qin Huang, Mengting Ma, Yizhen Jiang, Yun Chen, Zhenhua Huang, Wangyu Wu, Kangning Cui, Rongrong Lian, Zhenkai Wu, and Xiaowen Ma. Center-guided classifier for semantic segmentation of remote sensing images.IEEE TGRS, 2026
2026
-
[19]
Implicit regression in subspace for high-sensitivity cest imaging
Chu Chen, Yang Liu, Se Weon Park, Jizhou Li, Kannie WY Chan, and Raymond HF Chan. Implicit regression in subspace for high-sensitivity cest imaging. In2024 IEEE International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2024
2024
-
[20]
Blind adaptive local denoising for cest imaging.arXiv preprint arXiv:2511.20081, 2025
Chu Chen, Aitor Artola, Yang Liu, Se Weon Park, Raymond H Chan, Jean-Michel Morel, and Kannie WY Chan. Blind adaptive local denoising for cest imaging.arXiv preprint arXiv:2511.20081, 2025
-
[21]
Sada: Stability-guided adaptive diffusion acceleration
Ting Jiang, Yixiao Wang, Hancheng Ye, Zishan Shao, Jingwei Sun, Jingyang Zhang, Zekai Chen, Jianyi Zhang, Yiran Chen, and Hai Li. Sada: Stability-guided adaptive diffusion acceleration. InForty-second International Conference on Machine Learning, 2025
2025
-
[22]
Toward efficient uav-based small object detection: A lightweight network with enhanced feature fusion.Remote Sens., 17(13):2235, 2025
Xingyu Di, Kangning Cui, and Rui-Feng Wang. Toward efficient uav-based small object detection: A lightweight network with enhanced feature fusion.Remote Sens., 17(13):2235, 2025
2025
-
[23]
Seaf-net: A sustainable and lightweight attention-enhanced detection network for underwater fish species recognition.Journal of Marine Science and Engineering, 14(4):351, 2026
Yu-Shan Han, Sheng-Lun Zhao, Chu Chen, Kangning Cui, Pingfan Hu, and Rui-Feng Wang. Seaf-net: A sustainable and lightweight attention-enhanced detection network for underwater fish species recognition.Journal of Marine Science and Engineering, 14(4):351, 2026
2026
-
[24]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016
2016
-
[25]
Accurate detection and instance segmentation of unstained living adherent cells in differential interference contrast images.Computers in Biology and Medicine, 182:109151, 2024
Fei Pan, Yutong Wu, Kangning Cui, Shuxun Chen, Yanfang Li, Yaofang Liu, Adnan Shakoor, Han Zhao, Beijia Lu, Shaohua Zhi, et al. Accurate detection and instance segmentation of unstained living adherent cells in differential interference contrast images.Computers in Biology and Medicine, 182:109151, 2024
2024
-
[26]
Ssd: Single shot multibox detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. InECCV, 2016
2016
-
[27]
Yolov3: An incremental improvement
Ali Farhadi, Joseph Redmon, et al. Yolov3: An incremental improvement. InCVPR, volume 1804, pages 1–6. Springer Berlin/Heidelberg, Germany, 2018
2018
-
[28]
Behavior recognition and tracking of group-housed pigs based on improved bytetrack algorithm.Trans
Shuqin Tu, Yunjie Tang, Chengjie Li, Yun Liang, Yangchen Zeng, and Xiaolong Liu. Behavior recognition and tracking of group-housed pigs based on improved bytetrack algorithm.Trans. Chin. Soc. Agric. Mach., 53(12):264–272, 2022
2022
-
[29]
Bmdnet-yolo: A lightweight and robust model for high-precision real-time recognition of blueberry maturity.Horticulturae, 11(10):1202, 2025
Huihui Sun and Rui-Feng Wang. Bmdnet-yolo: A lightweight and robust model for high-precision real-time recognition of blueberry maturity.Horticulturae, 11(10):1202, 2025
2025
-
[30]
Cott-adnet: Lightweight real-time cotton boll and flower detection under field conditions
Rui-Feng Wang, Mingrui Xu, Matthew Bauer, Iago Schardong, Xiaowen Ma, Peng Chee, and Kangning Cui. Cott-adnet: Lightweight real-time cotton boll and flower detection under field conditions. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 500–509, 2026
2026
-
[31]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV, 2017
2017
-
[32]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. InNeurIPS, 2015
2015
-
[33]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. InICCV, 2017
2017
-
[34]
Fedc-dac: A federated clustering with dynamic aggregation and calibration method for sar image target recognition.IEEE JSTAR, 2025
Yuchao Hou, Shuai Zhao, Xiaoyu Xia, Minghui Liwang, Zijian Li, Nan Xu, Di Wu, Youliang Tian, and Tony QS Quek. Fedc-dac: A federated clustering with dynamic aggregation and calibration method for sar image target recognition.IEEE JSTAR, 2025
2025
-
[35]
Luffd-yolo: A lightweight model for uav remote sensing forest fire detection based on attention mechanism and multi-level feature fusion.Remote Sens., 16(12):2177, 2024
Yuhang Han, Bingchen Duan, Renxiang Guan, Guang Yang, and Zhen Zhen. Luffd-yolo: A lightweight model for uav remote sensing forest fire detection based on attention mechanism and multi-level feature fusion.Remote Sens., 16(12):2177, 2024. 12 Running Title for Header
2024
-
[36]
Superyolo: Super resolution assisted object detection in multimodal remote sensing imagery.IEEE TGRS, 61:1–15, 2023
Jiaqing Zhang, Jie Lei, Weiying Xie, Zhenman Fang, Yunsong Li, and Qian Du. Superyolo: Super resolution assisted object detection in multimodal remote sensing imagery.IEEE TGRS, 61:1–15, 2023
2023
-
[37]
Pcnet: A structure similarity enhancement method for multispectral and multimodal image registration.Inf
Si-Yuan Cao, Beinan Yu, Lun Luo, Runmin Zhang, Shu-Jie Chen, Chunguang Li, and Hui-Liang Shen. Pcnet: A structure similarity enhancement method for multispectral and multimodal image registration.Inf. Fusion, 94:200–214, 2023
2023
-
[38]
Learning non-maximum suppression
Jan Hosang, Rodrigo Benenson, and Bernt Schiele. Learning non-maximum suppression. InCVPR, pages 4507–4515, 2017
2017
-
[39]
Cascade r-cnn: Delving into high quality object detection
Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. InCVPR, 2018
2018
-
[40]
Larsen, Victor P
Kangning Cui, Rongkun Zhu, Manqi Wang, Wei Tang, Gregory D. Larsen, Victor P. Pauca, Sarra Alqahtani, Fan Yang, David Segurado, David A. Lutz, Jean-Michel Morel, and Miles R. Silman. Detection and geographic localization of natural objects in the wild: A case study on palms. InIJCAI, pages 9601–9609. International Joint Conferences on Artificial Intellige...
2025
-
[41]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InECCV, pages 213–229. Springer, 2020
2020
-
[42]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020
work page internal anchor Pith review arXiv 2010
-
[43]
Dynamicvit: Efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification. InNeurIPS, 2021
2021
-
[44]
A coarse to fine detection method for prohibited object in x-ray images based on progressive transformer decoder
Chunjie Ma, Lina Du, Zan Gao, Li Zhuo, and Meng Wang. A coarse to fine detection method for prohibited object in x-ray images based on progressive transformer decoder. InACM MM, pages 2700–2708, 2024
2024
-
[45]
Sparseformer: Detecting objects in hrw shots via sparse vision transformer
Wenxi Li, Yuchen Guo, Jilai Zheng, Haozhe Lin, Chao Ma, Lu Fang, and Xiaokang Yang. Sparseformer: Detecting objects in hrw shots via sparse vision transformer. InACM MM, pages 4851–4860, 2024
2024
-
[46]
Optimized hard exudate detection with supervised contrastive learning
Wei Tang, Kangning Cui, and Raymond H Chan. Optimized hard exudate detection with supervised contrastive learning. In2024 IEEE International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2024
2024
-
[47]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InICCV, 2021
2021
-
[48]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. InICCV, 2021
2021
-
[49]
Cvt: Introducing convolutions to vision transformers
Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, and Lei Zhang. Cvt: Introducing convolutions to vision transformers. InICCV, 2021
2021
-
[50]
Nyströmformer: A nyström-based algorithm for approximating self-attention
Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. InAAAI, 2021
2021
-
[51]
Flashsvd: Memory-efficient inference with streaming for low-rank models
Zishan Shao, Yixiao Wang, Qinsi Wang, Ting Jiang, Zhixu Du, Hancheng Ye, Danyang Zhuo, Yiran Chen, et al. Flashsvd: Memory-efficient inference with streaming for low-rank models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 25278–25285, 2026
2026
-
[52]
Query pipeline optimization for cancer patient question answering systems
Maolin He, Rena Gao, Mike Conway, and Brian E Chapman. Query pipeline optimization for cancer patient question answering systems.arXiv preprint arXiv:2412.14751, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Deformable convnets v2: More deformable, better results
Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. In CVPR, pages 9308–9316, 2019
2019
-
[54]
Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation
Yaolei Qi, Yuting He, Xiaoming Qi, Yuan Zhang, and Guanyu Yang. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. InICCV, pages 6070–6079, 2023
2023
-
[55]
Learning rotation-invariant convolutional neural networks for object detection in vhr optical remote sensing images.IEEE TGRS, 54(12):7405–7415, 2016
Gong Cheng, Peicheng Zhou, and Junwei Han. Learning rotation-invariant convolutional neural networks for object detection in vhr optical remote sensing images.IEEE TGRS, 54(12):7405–7415, 2016
2016
-
[56]
The pascal visual object classes (voc) challenge.IJCV, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.IJCV, 2010
2010
-
[57]
Visualizing our changing earth: A creative ai framework for democratizing environmental storytelling through satellite imagery
Zhenyu Yu, Mohd Yamani Idna Idris, and Pei Wang. Visualizing our changing earth: A creative ai framework for democratizing environmental storytelling through satellite imagery. InNeurIPS 2025, 2025
2025
-
[58]
Iidm: Improved implicit diffusion model with knowledge distillation to estimate the spatial distribution density of carbon stock in remote sensing imagery.KBS, page 115131, 2025
Zhenyu Yu, Jinnian Wang, and Mohd Yamani Idna Idris. Iidm: Improved implicit diffusion model with knowledge distillation to estimate the spatial distribution density of carbon stock in remote sensing imagery.KBS, page 115131, 2025. 13 Running Title for Header
2025
-
[59]
Dinov3-powered multi-task foundation model for quantitative remote sensing estimation.AAAI 2026, 40(48):41455–41456, 2026
Zhenyu Yu, Mohd Yamani Idna Idris, Pei Wang, and Rizwan Qureshi. Dinov3-powered multi-task foundation model for quantitative remote sensing estimation.AAAI 2026, 40(48):41455–41456, 2026
2026
-
[60]
Spatiotemporal alignment for remote sensing image recovery via terrain-aware diffusion.ICASSP 2026, 2026
Zhenyu Yu, Haoran Jiang, Pei Wang, Zizhen Lin, and Yong Xiang. Spatiotemporal alignment for remote sensing image recovery via terrain-aware diffusion.ICASSP 2026, 2026
2026
-
[61]
Fcos: Fully convolutional one-stage object detection
Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. InICCV, pages 9627–9636, 2019
2019
-
[62]
Centernet: Keypoint triplets for object detection
Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Keypoint triplets for object detection. InICCV, pages 6569–6578, 2019
2019
-
[63]
Searching for mobilenetv3
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. InICCV, pages 1314–1324, 2019
2019
-
[64]
YOLOv4: Optimal Speed and Accuracy of Object Detection
Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection.arXiv preprint arXiv:2004.10934, 2020
work page internal anchor Pith review arXiv 2004
-
[65]
Aduen Benjumea, Izzeddin Teeti, Fabio Cuzzolin, and Andrew Bradley. Yolo-z: Improving small object detection in yolov5 for autonomous vehicles.arXiv preprint arXiv:2112.11798, 2021
-
[66]
Yolov6: A single-stage object detection framework for industrial applications
Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, et al. Yolov6: A single-stage object detection framework for industrial applications.arXiv preprint arXiv:2209.02976, 2022
-
[67]
Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. InCVPR, pages 7464–7475, 2023
2023
-
[68]
YOLOv11: An Overview of the Key Architectural Enhancements
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements.arXiv preprint arXiv:2410.17725, 2024
work page internal anchor Pith review arXiv 2024
-
[69]
The footprint of factorization models and their applications in collaborative filtering.ACM Transactions on Information Systems (TOIS), 40(4):1–32, 2021
Jinze Wang, Yongli Ren, Jie Li, and Ke Deng. The footprint of factorization models and their applications in collaborative filtering.ACM Transactions on Information Systems (TOIS), 40(4):1–32, 2021
2021
-
[70]
Ads-poi: Agentic spatiotemporal state decomposition for next point-of-interest recommendation.ACM ISBN, pages 978–1, 2026
Zhenyu Yu, Chunlei Meng, Yangchen Zeng, Mohd Yamani Idna Idris, and Shuigeng Zhou. Ads-poi: Agentic spatiotemporal state decomposition for next point-of-interest recommendation.ACM ISBN, pages 978–1, 2026
2026
-
[71]
Cast-poi: Candidate- conditioned spatiotemporal modeling for next poi recommendation.ACM ISBN, pages 978–1, 2026
Zhenyu Yu, Chunlei Meng, Yangchen Zeng, Mohd Yamani Idna Idris, and Shuigeng Zhou. Cast-poi: Candidate- conditioned spatiotemporal modeling for next poi recommendation.ACM ISBN, pages 978–1, 2026
2026
-
[72]
YangChen Zeng. Hmpe: Heatmap embedding for efficient transformer-based small object detection.arXiv preprint arXiv:2504.13469, 2025
-
[73]
Yangchen Zeng. Deepinterestgr: Mining deep multi-interest using multi-modal llms for generative recommenda- tion.arXiv preprint arXiv:2602.18907, 2026. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.