Recognition: unknown
KVNN: Learnable Multi-Kernel Volterra Neural Networks
Pith reviewed 2026-05-10 11:46 UTC · model grok-4.3
The pith
Kernelized Volterra networks with parallel learnable polynomial branches can replace convolutional kernels to cut parameters and computation while holding or improving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a learnable multi-kernel Volterra representation, built from parallel polynomial-kernel components of different orders with compact learnable centers, enables filters that substitute for standard convolutional kernels inside existing networks and thereby achieve reduced model and computational complexity with competitive or improved accuracy on representative vision tasks.
What carries the argument
The learnable multi-kernel representation consisting of parallel branches of distinct polynomial orders, each with compact learnable centers, that together form an order-adaptive parameterization for higher-order interactions.
If this is right
- kVNN filters can be inserted directly in place of standard convolutional kernels inside existing deep architectures.
- The resulting networks exhibit lower parameter counts and lower GFLOPs on video action recognition and image denoising.
- Task performance remains competitive or improves even without large-scale pretraining.
- Different interaction orders are handled by distinct, learnable polynomial-kernel components that adapt during training.
Where Pith is reading between the lines
- The same multi-kernel layer structure could be tested on other high-dimensional inputs where higher-order correlations matter, such as volumetric medical imaging or point-cloud processing.
- Because the centers are learned, the approach may naturally prune ineffective higher-order terms during training, offering an implicit form of complexity control.
- Combining kVNN layers with existing efficiency methods like quantization or knowledge distillation could yield further gains in deployment settings.
Load-bearing premise
That the composition of parallel polynomial-kernel branches with learnable centers can directly substitute for convolutional kernels while preserving or improving task performance without hidden increases in effective complexity.
What would settle it
Training a kVNN-based model from scratch on a standard image-classification benchmark such as CIFAR-10 or ImageNet and measuring whether its parameter count, measured GFLOPs, and top-1 accuracy deviate unfavorably from a matched baseline CNN under identical training protocols.
Figures
read the original abstract
Higher-order learning is fundamentally rooted in exploiting compositional features. It clearly hinges on enriching the representation by more elaborate interactions of the data which, in turn, tends to increase the model complexity of conventional large-scale deep learning models. In this paper, a kernelized Volterra Neural Network (kVNN) is proposed. The key to the achieved efficiency lies in using a learnable multi-kernel representation, where different interaction orders are modeled by distinct polynomial-kernel components with compact, learnable centers, yielding an order-adaptive parameterization. Features are learned by the composition of layers, each of which consists of parallel branches of different polynomial orders, enabling kVNN filters to directly replace standard convolutional kernels within existing architectures. The theoretical results are substantiated by experiments on two representative tasks: video action recognition and image denoising. The results demonstrate favorable performance-efficiency trade-offs: kVNN consistently yields reduced model (parameters) and computational (GFLOPs) complexity with competitive and often improved performance. These results are maintained even when trained from scratch without large-scale pretraining. In summary, we substantiate that structured kernelized higher-order layers offer a practical path to balancing expressivity and computational cost in modern deep networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KVNN, a kernelized Volterra neural network using a learnable multi-kernel representation where distinct polynomial-kernel branches model different interaction orders with compact learnable centers. Each layer consists of parallel branches of varying polynomial orders, allowing the resulting filters to directly replace standard convolutional kernels in existing architectures. Experiments on video action recognition and image denoising are said to show reduced parameter counts and GFLOPs with competitive or improved accuracy, even when trained from scratch.
Significance. If the efficiency claims are substantiated with matched baselines and explicit complexity accounting, the work would provide a concrete parameterization for incorporating higher-order Volterra-style interactions into CNNs without the usual quadratic blow-up in parameters or compute. This could influence designs that seek structured expressivity gains in CV tasks.
major comments (3)
- [§3.2] §3.2 (or equivalent method section on complexity): the claim that parallel polynomial-kernel branches yield lower GFLOPs than standard conv layers lacks an explicit derivation relating branch count, center dimensionality, and interaction order to total FLOPs; without showing that the kernelized form avoids O(C_in * C_out * K^2) scaling while preserving receptive-field coverage, the reported reductions may reflect incomplete baseline matching rather than intrinsic savings.
- [Table 2] Table 2 (or equivalent results table for action recognition): the performance-efficiency trade-off is asserted as 'favorable' but the manuscript must report exact parameter counts, GFLOPs, and accuracy deltas versus the precise convolutional baseline with identical depth and receptive field; absent these matched numbers and error bars, the central substitution claim remains unverified.
- [§4.1] §4.1 (experimental setup): it is unclear whether the learnable centers and per-branch interaction orders are counted in the reported parameter totals or whether their scaling with input channels introduces hidden complexity; this must be clarified to confirm that the architecture truly substitutes for conv kernels without effective increases in degrees of freedom.
minor comments (2)
- [Abstract] The abstract states results are 'maintained even when trained from scratch' but does not specify the exact pretraining baselines or datasets used for comparison; add a sentence clarifying this.
- [§3] Notation for the polynomial kernel components and their composition across branches should be introduced with a single equation block rather than scattered definitions to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us improve the clarity and rigor of our work on kVNN. We provide point-by-point responses below and have revised the manuscript to address the concerns regarding complexity analysis, experimental reporting, and parameter accounting.
read point-by-point responses
-
Referee: [§3.2] §3.2 (or equivalent method section on complexity): the claim that parallel polynomial-kernel branches yield lower GFLOPs than standard conv layers lacks an explicit derivation relating branch count, center dimensionality, and interaction order to total FLOPs; without showing that the kernelized form avoids O(C_in * C_out * K^2) scaling while preserving receptive-field coverage, the reported reductions may reflect incomplete baseline matching rather than intrinsic savings.
Authors: We acknowledge that an explicit derivation of the FLOPs was missing from the original submission. In the revised manuscript, Section 3.2 now includes a full complexity analysis. We derive the total FLOPs as a function of branch count B, center dimensionality D, interaction order p, and input/output channels, showing that the kernelized multi-center representation yields O(B * C_in * D * K) scaling per layer rather than the naive higher-order blow-up. This preserves the receptive field by construction through the parallel branches while avoiding full O(C_in * C_out * K^2) cost for orders >1. We also update the experimental baselines to ensure matched receptive fields. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table for action recognition): the performance-efficiency trade-off is asserted as 'favorable' but the manuscript must report exact parameter counts, GFLOPs, and accuracy deltas versus the precise convolutional baseline with identical depth and receptive field; absent these matched numbers and error bars, the central substitution claim remains unverified.
Authors: We agree that more precise matched comparisons are required. We have revised Table 2 (and the corresponding text in Section 4) to report exact parameter counts, GFLOPs, and accuracy values for kVNN against a standard convolutional baseline with identical depth, channel widths, and receptive field. Accuracy deltas are now explicitly listed, and we include error bars computed over three independent runs to substantiate the reported trade-offs. revision: yes
-
Referee: [§4.1] §4.1 (experimental setup): it is unclear whether the learnable centers and per-branch interaction orders are counted in the reported parameter totals or whether their scaling with input channels introduces hidden complexity; this must be clarified to confirm that the architecture truly substitutes for conv kernels without effective increases in degrees of freedom.
Authors: We thank the referee for noting this ambiguity. In the revised Section 4.1 we now explicitly state the parameter counting protocol: all learnable centers (one per branch) and kernel weights are included in the reported totals. Interaction orders are fixed hyperparameters that determine the number of parallel branches but add no extra parameters. We further show that the scaling with input channels remains linear in the center dimension and does not exceed the degrees of freedom of an equivalent standard convolution, confirming the substitution property. revision: yes
Circularity Check
No circularity: new parameterization grounded in Volterra series with independent experimental validation
full rationale
The paper proposes kVNN as a novel architecture using learnable multi-kernel polynomial components for order-adaptive Volterra-style layers that substitute for convolutions. No equations, derivations, or central claims reduce by construction to fitted parameters, self-citations, or renamed inputs. Efficiency and performance assertions rest on direct experimental comparisons rather than tautological reparameterization. The architecture is presented as an independent design choice with external task benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable kernel centers
- interaction orders per branch
axioms (1)
- domain assumption Higher-order learning is fundamentally rooted in exploiting compositional features.
Reference graph
Works this paper leans on
-
[1]
INTRODUCTION Deep neural networks have achieved remarkable performance on a wide range of vision and video tasks, yet their core build- ing blocks remain largely linear (e.g., convolutions or linear projections), with nonlinearity primarily introduced through pointwise activations and depth. Higher-order interactions in data, which explicitly capture mult...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
BACKGROUND 2.1. Volterra Filtering A nonlinear V olterra system response extends linear convo- lution to include nonlinear terms, resulting in the continuous timep-th order V olterra series defined as: f(x) =H 0x(t) +H 1x(t) +H 2x(t) +· · ·+H px(t),(1) whereH 0x(t) =const.(it is set as0by default), and Hrx(t) = Z !hr(s1,· · ·,sr)x(t−s 1)· · ·x(t−s r)ds1· ...
-
[3]
Adopting a multi-kernel representation, i.e
METHODOLOGY Building on the demonstrated learning capacity of V olterra Filtering and the potential of kernelization in Section 2, we proceed with the key idea of characterizing V olterra basis functions. Adopting a multi-kernel representation, i.e. a weighted linear combination of multiple kernel functions, is shown to yield a more efficient realization ...
-
[4]
2nd order filter
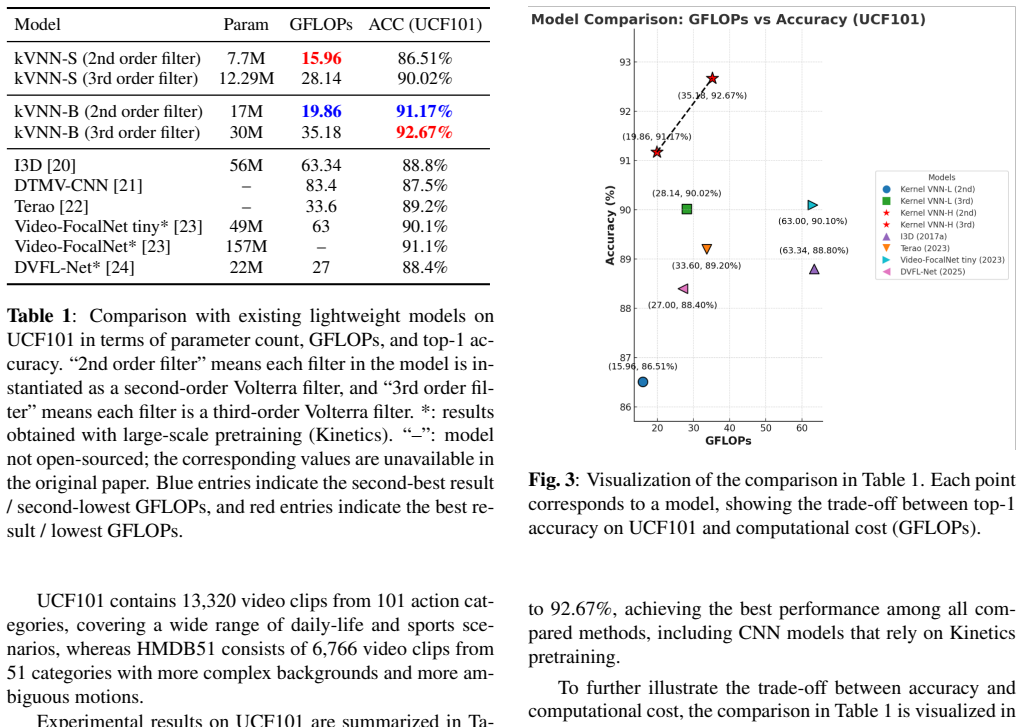
EXPERIMENTS To evaluate the effectiveness of the proposed kVNN, we con- ducted experiments on two representative tasks: video action recognition and image denoising. The following two sub- sections describe the experimental setups and implementation details for each task, respectively. 4.1. Video action recognition task setting For video action recognitio...
-
[5]
CONCLUSION This paper presented a kernelized V olterra Neural Network (kVNN) layer that enables higher-order filtering in a struc- tured and computationally efficient form. By introducing a learnable multi-kernel representation with compact, learnable centers, the proposed formulation provides an order-adaptive parameterization that can be instantiated as...
-
[6]
Conquering the CNN over-parameterization dilemma: A volterra filter- ing approach for action recognition,
Siddharth Roheda and Hamid Krim, “Conquering the CNN over-parameterization dilemma: A volterra filter- ing approach for action recognition,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, pp. 11948–11956, Apr. 2020
2020
-
[7]
A unify- ing view of wiener and volterra theory and polynomial kernel regression,
Matthias O. Franz and Bernhard Sch ¨olkopf, “A unify- ing view of wiener and volterra theory and polynomial kernel regression,”Neural Computation, vol. 18, no. 12, pp. 3097–3118, 2006
2006
-
[8]
On the nystrom method for approximating a gram matrix for improved kernel-based learning,
Petros Drineas and Michael W. Mahoney, “On the nystrom method for approximating a gram matrix for improved kernel-based learning,”Journal of Machine Learning Research, vol. 6, no. 72, pp. 2153–2175, 2005
2005
-
[9]
A generalized representer theorem,
Bernhard Sch ¨olkopf, Ralf Herbrich, and Alex J. Smola, “A generalized representer theorem,” inProceedings of the 14th Annual Conference on Computational Learn- ing Theory and 5th European Conference on Compu- tational Learning Theory, Berlin, Heidelberg, 2001, COLT ’01/EuroCOLT ’01, p. 416–426, Springer-Verlag
2001
-
[10]
Fast ran- domized kernel ridge regression with statistical guaran- tees,
Ahmed Alaoui and Michael W Mahoney, “Fast ran- domized kernel ridge regression with statistical guaran- tees,” inAdvances in Neural Information Processing Systems, C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, Eds. 2015, vol. 28, Curran Associates, Inc
2015
-
[11]
A review of nystr¨om methods for large-scale machine learning,
Shiliang Sun, Jing Zhao, and Jiang Zhu, “A review of nystr¨om methods for large-scale machine learning,”Inf. Fusion, vol. 26, no. C, pp. 36–48, Nov. 2015
2015
-
[12]
Orlicz random fourier features,
Linda Chamakh, Emmanuel Gobet, and Zolt ´an Szab ´o, “Orlicz random fourier features,”Journal of Machine Learning Research, vol. 21, no. 145, pp. 1–37, 2020
2020
-
[13]
Scalable kernel methods via doubly stochastic gradients,
Bo Dai, Bo Xie, Niao He, Yingyu Liang, Anant Raj, Maria-Florina Balcan, and Le Song, “Scalable kernel methods via doubly stochastic gradients,” inAdvances in Neural Information Processing Systems, Z. Ghahra- mani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, Eds. 2014, vol. 27, Curran Associates, Inc
2014
-
[14]
Absent multiple kernel learning algorithms,
Xinwang Liu, Lei Wang, Xinzhong Zhu, Miaomiao Li, En Zhu, Tongliang Liu, Li Liu, Yong Dou, and Jian- ping Yin, “Absent multiple kernel learning algorithms,” IEEE Transactions on Pattern Analysis and Machine In- telligence, vol. 42, no. 6, pp. 1303–1316, 2020
2020
-
[15]
Online multi-kernel learning with graph-structured feedback,
Pouya M Ghari and Yanning Shen, “Online multi-kernel learning with graph-structured feedback,” inProceed- ings of the 37th International Conference on Machine Learning, Hal Daum ´e III and Aarti Singh, Eds. 13–18 Jul 2020, vol. 119 ofProceedings of Machine Learning Research, pp. 3474–3483, PMLR
2020
-
[16]
Bilinear CNN models for fine-grained visual recognition,
Tsung-Yu Lin, Aruni RoyChowdhury, and Subhransu Maji, “Bilinear CNN models for fine-grained visual recognition,” in2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1449–1457
2015
-
[17]
Compact bilinear pooling,
Yang Gao, Oscar Beijbom, Ning Zhang, and Trevor Dar- rell, “Compact bilinear pooling,” in2016 IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 317–326
2016
-
[18]
P–nets: Deep polynomial neural net- works,
Grigorios G. Chrysos, Stylianos Moschoglou, Giorgos Bouritsas, Yannis Panagakis, Jiankang Deng, and Ste- fanos Zafeiriou, “P–nets: Deep polynomial neural net- works,” in2020 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2020, pp. 7323– 7333
2020
-
[19]
Tensor regression networks,
Jean Kossaifi, Zachary C. Lipton, Arinbj ¨orn Kolbeins- son, Aran Khanna, Tommaso Furlanello, and Anima Anandkumar, “Tensor regression networks,”J. Mach. Learn. Res., vol. 21, no. 1, Jan. 2020
2020
-
[20]
V olterraNet: A Higher Order Convolutional Network With Group Equivariance for Homogeneous Manifolds ,
Monami Banerjee, Rudrasis Chakraborty, Jose Bouza, and Baba C. Vemuri, “ V olterraNet: A Higher Order Convolutional Network With Group Equivariance for Homogeneous Manifolds ,”IEEE Transactions on Pat- tern Analysis & Machine Intelligence, vol. 44, no. 02, pp. 823–833, Feb. 2022
2022
-
[21]
Latent code-based fusion: A volterra neural network approach,
Sally Ghanem, Siddharth Roheda, and Hamid Krim, “Latent code-based fusion: A volterra neural network approach,”Intell. Syst. Appl., vol. 18, pp. 200210, 2021
2021
-
[22]
V olterra neural networks (VNNs),
Siddharth Roheda, Hamid Krim, and Bo Jiang, “V olterra neural networks (VNNs),”Journal of Machine Learning Research, vol. 25, no. 182, pp. 1–29, 2024
2024
-
[23]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah, “UCF101: A dataset of 101 human actions classes from videos in the wild,”CoRR, vol. abs/1212.0402, 2012
work page internal anchor Pith review arXiv 2012
-
[24]
Hmdb: A large video database for human motion recognition,
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: A large video database for human motion recognition,” in2011 International Conference on Computer Vision, 2011, pp. 2556–2563
2011
-
[25]
Quo vadis, ac- tion recognition? a new model and the kinetics dataset,
Jo ˜ao Carreira and Andrew Zisserman, “Quo vadis, ac- tion recognition? a new model and the kinetics dataset,” in2017 IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), 2017, pp. 4724–4733
2017
-
[26]
Real-time action recognition with deeply transferred motion vector CNNs,
Bowen Zhang, Limin Wang, Zhe Wang, Yu Qiao, and Hanli Wang, “Real-time action recognition with deeply transferred motion vector CNNs,”IEEE Transactions on Image Processing, vol. 27, no. 5, pp. 2326–2339, 2018
2018
-
[27]
Efficient compressed video ac- tion recognition via late fusion with a single network,
Hayato Terao, Wataru Noguchi, Hiroyuki Iizuka, and Masahito Yamamoto, “Efficient compressed video ac- tion recognition via late fusion with a single network,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[28]
Video-focalnets: Spatio-temporal focal modulation for video action recognition,
Syed Talal Wasim, Muhammad Uzair Khattak, Muza- mmal Naseer, Salman Khan, Mubarak Shah, and Fa- had Shahbaz Khan, “Video-focalnets: Spatio-temporal focal modulation for video action recognition,” in2023 IEEE/CVF International Conference on Computer Vi- sion (ICCV), 2023, pp. 13732–13743
2023
-
[29]
Dvfl-net: A lightweight distilled video focal modulation network for spatio-temporal ac- tion recognition,
Hayat Ullah, Muhammad Ali Shafique, Abbas Khan, and Arslan Munir, “Dvfl-net: A lightweight distilled video focal modulation network for spatio-temporal ac- tion recognition,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2025
2025
-
[30]
Learning spatiotemporal features with 3D convolutional networks,
Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Tor- resani, and Manohar Paluri, “Learning spatiotemporal features with 3D convolutional networks,” inProceed- ings of the IEEE International Conference on Computer Vision (ICCV), December 2015
2015
-
[31]
Mv2flow: Learning motion representa- tion for fast compressed video action recognition,
Hezhen Hu, Wengang Zhou, Xingze Li, Ning Yan, and Houqiang Li, “Mv2flow: Learning motion representa- tion for fast compressed video action recognition,”ACM Trans. Multimedia Comput. Commun. Appl., vol. 16, no. 3s, Dec. 2021
2021
-
[32]
Faster-fcoviar: Faster frequency-domain compressed video action recognition,
Lu Xiong, Xia Jia, Yue Ming, Jiang Zhou, Fan Feng, and Nannan Hu, “Faster-fcoviar: Faster frequency-domain compressed video action recognition,” inBritish Ma- chine Vision Conference, 2021
2021
-
[33]
Compressed video action recog- nition using motion vector representation,
Chenghui Zhou, Xiaolei Chen, Pei Sun, Guanwen Zhang, and Wei Zhou, “Compressed video action recog- nition using motion vector representation,” inPat- tern Recognition. ICPR International Workshops and Challenges: Virtual Event, January 10–15, 2021, Pro- ceedings, Part I, Berlin, Heidelberg, 2021, p. 701–713, Springer-Verlag
2021
-
[34]
Imrnet: An iterative mo- tion compensation and residual reconstruction network for video compressed sensing,
Xin Yang and Chunling Yang, “Imrnet: An iterative mo- tion compensation and residual reconstruction network for video compressed sensing,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 2350–2354
2021
-
[35]
Sor-tc: Self- attentive octave resnet with temporal consistency for compressed video action recognition,
Junsan Zhang, Xiaomin Wang, Yao Wan, Leiquan Wang, Jian Wang, and Philip S. Yu, “Sor-tc: Self- attentive octave resnet with temporal consistency for compressed video action recognition,”Neurocomput., vol. 533, no. C, pp. 191–205, May 2023
2023
-
[36]
Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising,
Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang, “Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising,”Trans. Img. Proc., vol. 26, no. 7, pp. 3142–3155, July 2017
2017
-
[37]
Ffdnet: Toward a fast and flexible solution for CNN-based im- age denoising,
Kai Zhang, Wangmeng Zuo, and Lei Zhang, “Ffdnet: Toward a fast and flexible solution for CNN-based im- age denoising,”IEEE Transactions on Image Process- ing, vol. 27, no. 9, pp. 4608–4622, Sept. 2018
2018
-
[38]
Dual con- volutional neural network with attention for image blind denoising,
Wencong Wu, Guannan Lv, Yingying Duan, Peng Liang, Yungang Zhang, and Yuelong Xia, “Dual con- volutional neural network with attention for image blind denoising,”Multimedia Syst., vol. 30, no. 5, Sept. 2024
2024
-
[39]
Spatially adaptive self-supervised learning for real-world image denoising,
Junyi Li, Zhilu Zhang, Xiaoyu Liu, Chaoyu Feng, Xi- aotao Wang, Lei Lei, and Wangmeng Zuo, “Spatially adaptive self-supervised learning for real-world image denoising,” in2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2023, pp. 9914–9924
2023
-
[40]
U-net: Convolutional networks for biomedical im- age segmentation,
Olaf Ronneberger, Philipp Fischer, and Thomas Brox, “U-net: Convolutional networks for biomedical im- age segmentation,” inMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Nas- sir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, Eds., Cham, 2015, pp. 234–241, Springer International Publishing
2015
-
[41]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
2021
-
[42]
Smola,Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond, The MIT Press, Dec 2001
Bernhard Sch ¨olkopf and Alexander J. Smola,Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond, The MIT Press, Dec 2001. A. THEORETICAL PROPERTIES OF THE LEARNABLE MULTI-KERNEL CONSTRUCTION This appendix collects theoretical results that support the proposed learnable multi-kernel representation. Theorem 1(Feature map...
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.