Recognition: unknown
VisPCO: Visual Token Pruning Configuration Optimization via Budget-Aware Pareto-Frontier Learning for Vision-Language Models
Pith reviewed 2026-05-10 11:25 UTC · model grok-4.3
The pith
VisPCO automates the search for visual token pruning configurations in vision-language models by solving a budget-aware Pareto optimization problem with gradient methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
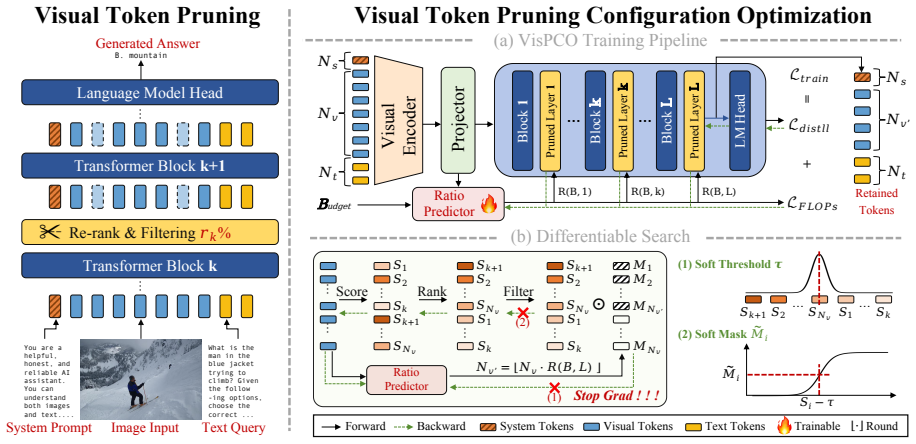
The central claim is that visual token pruning configuration selection is a Pareto-frontier optimization problem that can be solved end-to-end by continuous relaxation, straight-through gradient estimation, and the Augmented Lagrangian solver, yielding pruning ratios whose accuracy-compute trade-offs match those of grid search while revealing that multi-step progressive pruning aligns with the models' natural layer-wise compression structure.
What carries the argument
Budget-aware Pareto-frontier learning that relaxes discrete pruning ratios into continuous variables, estimates gradients via straight-through estimators, and optimizes under compute constraints with the Augmented Lagrangian method.
If this is right
- Pruning ratios no longer need manual tuning or exhaustive search for each new model or task.
- Multi-step progressive pruning yields better accuracy at the same compute cost than uniform single-layer pruning.
- Layer-wise pruning patterns learned via kernel functions expose how vision-language models compress visual information hierarchically.
- The same optimization procedure applies without modification to multiple existing pruning methods and model families.
- Compute savings from the discovered configurations remain stable across eight standard visual benchmarks.
Where Pith is reading between the lines
- If the method generalizes, practitioners could embed VisPCO inside automated model-compression pipelines so that each new VLM deployment starts from a near-optimal pruning schedule rather than a default.
- The progressive-pruning insight suggests testing whether the same multi-step pattern improves efficiency in pure vision transformers or multimodal models outside the language-vision pair.
- Because the approach separates configuration search from the underlying pruning operator, it could be reused to optimize token pruning in long-context video or document models where quadratic cost grows even faster.
Load-bearing premise
Continuous relaxation plus straight-through estimators can locate near-optimal discrete pruning ratios without creating large mismatches between the optimized trade-offs and the actual accuracy-compute performance on real hardware.
What would settle it
Run exhaustive grid search on a new VLM architecture and pruning method, then check whether VisPCO's returned configurations lie measurably below the true empirical Pareto front in accuracy at equivalent compute budgets.
Figures






read the original abstract
Visual token pruning methods effectively mitigate the quadratic computational growth caused by processing high-resolution images and video frames in vision-language models (VLMs). However, existing approaches rely on predefined pruning configurations without determining whether they achieve computation-performance optimality. In this work, we introduce , a novel framework that formulates visual token pruning as a Pareto configuration optimization problem to automatically identify optimal configurations. Our approach employs continuous relaxation and straight-through estimators to enable gradient-based search, solved via the Augmented Lagrangian method. Extensive experiments across 8 visual benchmarks demonstrate that effectively approximates the empirical Pareto frontier obtained through grid search and generalizes well across various pruning methods and VLM architectures. Furthermore, through learnable kernel functions, we investigate layer-wise pruning patterns and reveal that multi-step progressive pruning captures VLMs' hierarchical compression structure, achieving superior accuracy-efficiency trade-offs compared to single-layer approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VisPCO, a framework that casts visual token pruning configuration search in VLMs as a budget-aware Pareto optimization problem. It employs continuous relaxation of per-layer pruning ratios, straight-through estimators to enable gradient flow through the discrete decisions, and the Augmented Lagrangian method to solve for configurations that are claimed to approximate the empirical Pareto frontier obtained by exhaustive grid search. The method is asserted to generalize across multiple pruning techniques and VLM backbones; an auxiliary investigation with learnable kernel functions is used to analyze layer-wise pruning patterns and to argue that multi-step progressive pruning better respects the hierarchical compression structure of VLMs than single-layer baselines. Results are reported on eight visual benchmarks.
Significance. If the continuous-relaxation solutions provably recover near-optimal discrete configurations with small realized error relative to grid-search fronts, the work would offer a practical, automated alternative to manual or exhaustive tuning of token-pruning schedules, which is increasingly important for high-resolution image and video VLMs. The layer-wise kernel analysis could also supply reusable insights into progressive compression. The reliance on standard optimization primitives (Augmented Lagrangian + STE) is a strength in reproducibility but does not by itself constitute a theoretical advance.
major comments (2)
- [Abstract] Abstract: the claim that VisPCO 'effectively approximates the empirical Pareto frontier obtained through grid search' is presented without any quantitative support (Hausdorff distance, mean deviation in accuracy/FLOPs, fraction of grid points recovered within tolerance, or relaxation-gap bounds). This metric-free assertion is load-bearing for the central contribution.
- [Method / Experiments] Method / Experiments: no ablation is described that compares the post-discretization (rounded) accuracy/FLOPs of the learned configurations against the relaxed objective values or against the nearest grid-search points. In high-dimensional per-layer spaces the STE bias and relaxation gap can shift the realized front; without such a check the generalization and superiority claims over single-layer baselines remain unanchored.
minor comments (1)
- [Abstract] The abstract introduces the acronym VisPCO without spelling out the full name on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will revise the manuscript to strengthen the quantitative claims and experimental validation as suggested.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that VisPCO 'effectively approximates the empirical Pareto frontier obtained through grid search' is presented without any quantitative support (Hausdorff distance, mean deviation in accuracy/FLOPs, fraction of grid points recovered within tolerance, or relaxation-gap bounds). This metric-free assertion is load-bearing for the central contribution.
Authors: We agree that the abstract would benefit from explicit quantitative support for the approximation claim. The body of the paper reports performance comparisons on eight benchmarks demonstrating that the discovered configurations achieve accuracy-efficiency trade-offs close to those from exhaustive grid search. To directly address the concern, we will revise the abstract to include concise quantitative statements (e.g., average deviation in accuracy and FLOPs relative to the grid-search frontier, and the fraction of configurations recovered within a small tolerance). We will also add these metrics explicitly to the experiments section for transparency. revision: yes
-
Referee: [Method / Experiments] Method / Experiments: no ablation is described that compares the post-discretization (rounded) accuracy/FLOPs of the learned configurations against the relaxed objective values or against the nearest grid-search points. In high-dimensional per-layer spaces the STE bias and relaxation gap can shift the realized front; without such a check the generalization and superiority claims over single-layer baselines remain unanchored.
Authors: This is a fair observation about potential discrepancies from discretization and STE bias. Our experiments already evaluate the final (discretized) configurations against grid-search results on the benchmarks, showing competitive or better trade-offs than single-layer baselines. However, we did not report an explicit ablation of the gap between the relaxed continuous objective and post-rounding performance, nor direct proximity to nearest grid-search points in configuration space. We will add a dedicated ablation subsection and table in the revised manuscript that quantifies these gaps and comparisons, thereby anchoring the generalization claims more firmly. revision: yes
Circularity Check
No circularity: optimization primitives and empirical validation remain independent of inputs.
full rationale
The paper formulates token pruning as a constrained multi-objective optimization problem and applies standard continuous-relaxation, straight-through estimator, and Augmented Lagrangian techniques to search for configurations. These are off-the-shelf numerical methods whose correctness does not presuppose the target Pareto front. The claim that the resulting discrete points approximate an independently enumerated grid-search frontier is an empirical statement verified on held-out benchmarks rather than a definitional identity. The learnable-kernel analysis of layer-wise patterns is presented as a post-hoc investigation, not a load-bearing premise that feeds back into the optimizer. No self-citation chain, ansatz smuggling, or renaming of known results is required for the central derivation; the method is therefore self-contained against external grid-search and cross-architecture benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, and 1 others. 2025. Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661
work page internal anchor Pith review arXiv 2025
-
[2]
Kenneth J Arrow and Gerard Debreu. 2024. Existence of an equilibrium for a competitive economy. In The Foundations of Price Theory Vol 5, pages 289--316. Routledge
2024
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Dimitri P Bertsekas. 2014. Constrained optimization and Lagrange multiplier methods. Academic press
2014
-
[5]
Jeffrey P Bigham, Chandrika Jayant, Hanjie Ji, Greg Little, Andrew Miller, Robert C Miller, Robin Miller, Aubrey Tatarowicz, Brandyn White, Samual White, and 1 others. 2010. Vizwiz: nearly real-time answers to visual questions. In Proceedings of the 23rd annual ACM symposium on User interface software and technology, pages 333--342
2010
-
[6]
Jianjian Cao, Peng Ye, Shengze Li, Chong Yu, Yansong Tang, Jiwen Lu, and Tao Chen. 2024. Madtp: Multimodal alignment-guided dynamic token pruning for accelerating vision-language transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15710--15719
2024
-
[7]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024 a . An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision, pages 19--35. Springer
2024
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, and 1 others. 2024 b . Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271
work page internal anchor Pith review arXiv 2024
-
[9]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and 1 others. 2025. Mme: A comprehensive evaluation benchmark for multimodal large language models. In The 39th Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2025
-
[10]
a chtnis des leibes. Ph \
Thomas Fuchs. 2000. Das ged \"a chtnis des leibes. Ph \"a nomenologische Forschungen , 5(1):71--89
2000
-
[11]
Zonghao Guo, Ruyi Xu, Yuan Yao, Junbo Cui, Zanlin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, and Gao Huang. 2024. Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images. In European Conference on Computer Vision, pages 390--406. Springer
2024
- [12]
-
[13]
Eric Jang, Shixiang Gu, and Ben Poole. 2016. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144
work page internal anchor Pith review arXiv 2016
-
[14]
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. 2023. Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125
work page internal anchor Pith review arXiv 2023
-
[15]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-llava: Learning united visual representation by alignment before projection. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5971--5984
2024
-
[16]
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. 2025. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 5334--5342
2025
-
[17]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. Advances in neural information processing systems, 36:34892--34916
2023
-
[18]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, and 1 others. 2024 a . Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216--233. Springer
2024
-
[19]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. 2024 b . Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences, 67(12):220102
2024
-
[20]
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. 2022. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In Findings of the association for computational linguistics: ACL 2022, pages 2263--2279
2022
-
[21]
Jorge Nocedal and Stephen J Wright. 2006. Numerical optimization. Springer
2006
-
[22]
Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. 2022. A-okvqa: A benchmark for visual question answering using world knowledge. In European conference on computer vision, pages 146--162. Springer
2022
-
[23]
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317--8326
2019
-
[24]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram \'e , Morgane Rivi \`e re, and 1 others. 2025. Gemma 3 technical report. arXiv preprint arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
- [26]
-
[27]
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, and Bo Yuan. 2025. Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19803--19813
2025
-
[28]
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. 2025 a . Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22128--22136
2025
-
[29]
Xubing Ye, Yukang Gan, Yixiao Ge, Xiao-Ping Zhang, and Yansong Tang. 2025 b . Atp-llava: Adaptive token pruning for large vision language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24972--24982
2025
-
[30]
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and Shanghang Zhang. 2024. Sparsevlm: Visual token sparsification for efficient vision-language model inference. arXiv preprint arXiv:2410.04417
-
[31]
Shiyu Zhao, Zhenting Wang, Felix Juefei-Xu, Xide Xia, Miao Liu, Xiaofang Wang, Mingfu Liang, Ning Zhang, Dimitris N Metaxas, and Licheng Yu. 2025. Accelerating multimodal large language models by searching optimal vision token reduction. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29869--29879
2025
-
[32]
Yiwu Zhong, Zhuoming Liu, Yin Li, and Liwei Wang. 2025. Aim: Adaptive inference of multi-modal llms via token merging and pruning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20180--20192
2025
-
[33]
Yi Zhou, Hui Zhang, Jiaqian Yu, Yifan Yang, Sangil Jung, Seung-In Park, and ByungIn Yoo. 2024. Himap: Hybrid representation learning for end-to-end vectorized hd map construction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15396--15406
2024
-
[34]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[35]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.