Recognition: unknown
Why Do Vision Language Models Struggle To Recognize Human Emotions?
Pith reviewed 2026-05-10 10:59 UTC · model grok-4.3
The pith
Vision-language models struggle with human emotions because web pretraining biases them to common expressions and their context limits block dense temporal sequences needed for micro-expressions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The inherently continuous and dynamic task of dynamic facial expression recognition exposes two critical VLM vulnerabilities: web-scale pretraining exacerbates long-tailed bias in emotion datasets, causing models to collapse rare emotions into common categories, and context-size limits prevent representing temporal information over dense frame sequences, which misaligns with the fleeting 0.25-0.5-second duration of micro-expressions that often supply the decisive affective cue. Alternative sampling strategies are shown to reduce bias toward common concepts, and a multi-stage enrichment process converts information from in-between frames into natural-language summaries that are supplied as文本
What carries the argument
A multi-stage context enrichment strategy that first converts frames between sparsely sampled keyframes into natural language summaries, then supplies the resulting textual context together with the keyframes so the model can track emotional trajectories without exceeding token limits or suffering attentional dilution.
If this is right
- Alternative sampling during training or inference can reduce systematic collapse of rare emotions into common categories.
- Sparse keyframe sampling is misaligned with the short duration of micro-expressions and therefore discards key affective information.
- Textual summaries of omitted frames let the model follow emotional trajectories while staying inside context-size constraints.
- The combination of bias-aware sampling and enriched textual context yields measurable gains over standard VLM pipelines on dynamic expression benchmarks.
Where Pith is reading between the lines
- The same long-tailed and temporal-sampling problems are likely to appear in other video tasks where events unfold over sub-second intervals.
- Hybrid designs that pair a lightweight temporal visual encoder with the language model could bypass the need for language mediation of every frame.
- Curating pretraining corpora to balance emotion-related visual concepts may prove more effective than post-training fixes for this domain.
- The summary-based enrichment method could be tested on other continuous signals such as gesture sequences or physiological video to check generality.
Load-bearing premise
Converting in-between frames to natural language summaries preserves the critical affective signals and fine-grained cues from micro-expressions without introducing new errors or losses.
What would settle it
Running the same VLM on identical video clips with direct access to every frame via an extended context window or dedicated video encoder, and finding no gain on rare-emotion accuracy or micro-expression detection, would indicate the claimed vulnerabilities are not the main cause.
Figures




read the original abstract
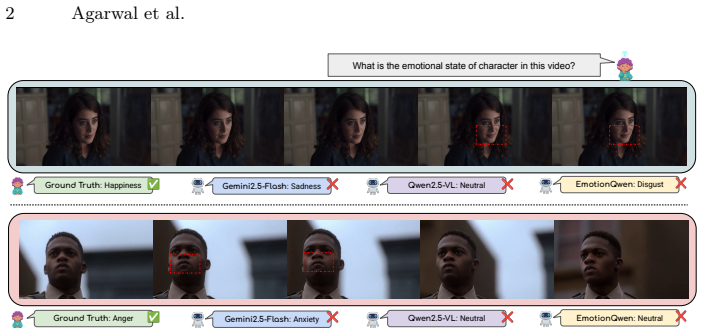
Understanding emotions is a fundamental ability for intelligent systems to be able to interact with humans. Vision-language models (VLMs) have made tremendous progress in the last few years for many visual tasks, potentially offering a promising solution for understanding emotions. However, it is surprising that even the most sophisticated contemporary VLMs struggle to recognize human emotions or to outperform even specialized vision-only classifiers. In this paper we ask the question "Why do VLMs struggle to recognize human emotions?", and observe that the inherently continuous and dynamic task of facial expression recognition (DFER) exposes two critical VLM vulnerabilities. First, emotion datasets are naturally long-tailed, and the web-scale data used to pre-train VLMs exacerbates this head-class bias, causing them to systematically collapse rare, under-represented emotions into common categories. We propose alternative sampling strategies that prevent favoring common concepts. Second, temporal information is critical for understanding emotions. However, VLMs are unable to represent temporal information over dense frame sequences, as they are limited by context size and the number of tokens that can fit in memory, which poses a clear challenge for emotion recognition. We demonstrate that the sparse temporal sampling strategy used in VLMs is inherently misaligned with the fleeting nature of micro-expressions (0.25-0.5 seconds), which are often the most critical affective signal. As a diagnostic probe, we propose a multi-stage context enrichment strategy that utilizes the information from "in-between" frames by first converting them into natural language summaries. This enriched textual context is provided as input to the VLM alongside sparse keyframes, preventing attentional dilution from excessive visual data while preserving the emotional trajectory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates why contemporary vision-language models (VLMs) underperform on human emotion recognition compared to specialized vision-only classifiers, focusing on the dynamic facial expression recognition (DFER) task. It identifies two primary vulnerabilities: (1) exacerbation of long-tailed dataset bias from web-scale pretraining, causing systematic collapse of rare emotions into common categories, and (2) inability to model dense temporal sequences due to context-length and token limits, which misaligns with the short duration (0.25-0.5 s) of micro-expressions. The authors propose alternative sampling strategies to mitigate head-class bias and a multi-stage context-enrichment diagnostic that converts intervening frames into natural-language summaries, concatenating these with sparse keyframes to preserve affective trajectory without exceeding visual token budgets.
Significance. If the identified vulnerabilities are empirically confirmed and the enrichment strategy is shown to recover performance without introducing new representational errors, the work would provide actionable guidance for adapting VLMs to affective and temporal visual tasks. The framing of DFER as exposing architectural and data biases is timely, and the proposed textual-summary probe offers a pragmatic workaround for context constraints. However, the current manuscript contains no quantitative results, ablations, or fidelity checks, so its contribution remains diagnostic rather than demonstrative.
major comments (3)
- [Abstract] Abstract and proposed diagnostic: The multi-stage context enrichment strategy is presented as addressing the temporal limitation, yet the manuscript reports no quantitative evaluation of summary fidelity (e.g., human ratings of micro-expression preservation, comparison of VLM accuracy with vs. without summaries, or error analysis of captioner-induced distortions). Without such checks, it is impossible to determine whether the textual summaries faithfully encode the continuous affective trajectory or merely substitute a lossy proxy.
- [Abstract] Abstract, second vulnerability claim: The assertion that sparse keyframe sampling is inherently misaligned with micro-expressions (0.25-0.5 s) and that dense sequences cannot be processed due to context limits is offered without supporting measurements, such as token-usage statistics, attention dilution metrics, or controlled experiments comparing sparse vs. enriched inputs on standard DFER benchmarks.
- [Overall] Overall manuscript: The central claims rest on observations about dataset statistics and architectural constraints, but the paper provides no experimental results, ablation studies, or error analysis to establish that the two vulnerabilities are the primary causes of VLM underperformance or that the proposed sampling and enrichment strategies yield measurable improvements.
minor comments (1)
- [Proposed Method] Clarify whether the natural-language summaries are generated by a separate VLM/captioner or by the target model itself, and specify the exact prompting strategy used for summarization.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments. Our manuscript is intended as a diagnostic analysis of VLM limitations on dynamic facial expression recognition, grounded in dataset statistics and architectural constraints. We agree that quantitative validation is needed to strengthen the claims and will incorporate the suggested evaluations, measurements, and experiments in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and proposed diagnostic: The multi-stage context enrichment strategy is presented as addressing the temporal limitation, yet the manuscript reports no quantitative evaluation of summary fidelity (e.g., human ratings of micro-expression preservation, comparison of VLM accuracy with vs. without summaries, or error analysis of captioner-induced distortions). Without such checks, it is impossible to determine whether the textual summaries faithfully encode the continuous affective trajectory or merely substitute a lossy proxy.
Authors: We agree that fidelity checks are essential for validating the diagnostic probe. In the revised manuscript, we will add quantitative evaluations including human ratings of micro-expression preservation in the generated summaries, direct VLM accuracy comparisons on DFER benchmarks with and without the enrichment strategy, and error analysis of captioner-induced distortions to confirm that the summaries preserve the affective trajectory without substantial loss. revision: yes
-
Referee: [Abstract] Abstract, second vulnerability claim: The assertion that sparse keyframe sampling is inherently misaligned with micro-expressions (0.25-0.5 s) and that dense sequences cannot be processed due to context limits is offered without supporting measurements, such as token-usage statistics, attention dilution metrics, or controlled experiments comparing sparse vs. enriched inputs on standard DFER benchmarks.
Authors: The misalignment follows from documented micro-expression durations and VLM context/token limits, but we accept that explicit measurements are required. The revision will include token-usage statistics across sampling densities, attention dilution metrics for dense inputs, and controlled experiments on standard DFER benchmarks comparing sparse keyframes against the enriched textual context. revision: yes
-
Referee: [Overall] Overall manuscript: The central claims rest on observations about dataset statistics and architectural constraints, but the paper provides no experimental results, ablation studies, or error analysis to establish that the two vulnerabilities are the primary causes of VLM underperformance or that the proposed sampling and enrichment strategies yield measurable improvements.
Authors: The work is framed as a diagnostic study highlighting vulnerabilities via analysis rather than exhaustive experimentation. We acknowledge the need for substantiation and will add in the revision: experimental results on VLM underperformance, ablations of the proposed sampling strategies, and error analyses demonstrating that the identified issues are primary causes and that the enrichment strategy yields measurable gains. revision: yes
Circularity Check
No significant circularity; claims rest on external dataset properties and architectural constraints.
full rationale
The paper's core observations derive from known long-tailed distributions in emotion datasets and standard VLM context-length limits, neither of which is defined or fitted inside the paper. The proposed sampling strategies and multi-stage enrichment are presented as empirical interventions rather than predictions that reduce to the inputs by construction. No equations, self-definitional loops, or load-bearing self-citations appear in the derivation chain; the diagnostic probe is framed as an external test of VLM behavior against independent benchmarks such as micro-expression timing literature.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Emotion datasets are naturally long-tailed and web-scale pretraining data exacerbates head-class bias
- domain assumption Micro-expressions lasting 0.25-0.5 seconds are often the most critical affective signals
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[3]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Arnab, A., Iscen, A., Caron, M., Fathi, A., Schmid, C.: Temporal chain of thought: Long-video understanding by thinking in frames. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[4]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review arXiv 2023
-
[6]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., et al.: Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954 (2024)
work page internal anchor Pith review arXiv 2024
-
[9]
Cai,Z.,Cao,M.,Chen,H.,Chen,K.,Chen,K.,Chen,X.,Chen,X.,Chen,Z.,Chen, Z., Chu, P., et al.: Internlm2 technical report. arXiv preprint arXiv:2403.17297 (2024)
-
[10]
Journal of artificial intelligence research16, 321– 357 (2002)
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: Smote: synthetic mi- nority over-sampling technique. Journal of artificial intelligence research16, 321– 357 (2002)
2002
-
[11]
In: INTERSPEECH (2018)
Chung, J.S., Nagrani, A., Zisserman, A.: Voxceleb2: Deep speaker recognition. In: INTERSPEECH (2018)
2018
-
[12]
In: 2023 IEEE International conference on big data (BigData)
Cloutier, N.A., Japkowicz, N.: Fine-tuned generative llm oversampling can improve performance over traditional techniques on multiclass imbalanced text classifica- tion. In: 2023 IEEE International conference on big data (BigData). pp. 5181–5186. IEEE (2023)
2023
-
[13]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
In: 36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025
Cores, D., Dorkenwald, M., Mucientes, M., Snoek, C.G.M., Asano, Y.M.: Lost in time: A new temporal benchmark for videollms. In: 36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025. BMVA (2025)
2025
-
[15]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009) 16 Agarwal et al
2009
-
[16]
Ding, X., Wang, L.: Do language models understand time? In: The First Inter- national Workshop on Transformative Insights in Multifaceted Evaluation at The Web Conference 2025 (2025)
2025
-
[17]
Psychiatry 32(1), 88–106 (1969)
Ekman, P., Friesen, W.V.: Nonverbal leakage and clues to deception. Psychiatry 32(1), 88–106 (1969)
1969
-
[18]
Computational intelligence20(1), 18–36 (2004)
Estabrooks, A., Jo, T., Japkowicz, N.: A multiple resampling method for learning from imbalanced data sets. Computational intelligence20(1), 18–36 (2004)
2004
-
[19]
arXiv preprint arXiv:2302.01507 (2023)
Fang, C., Zhang, D., Zheng, W., Li, X., Yang, L., Cheng, L., Han, J.: Revisit- ing long-tailed image classification: Survey and benchmarks with new evaluation metrics. arXiv preprint arXiv:2302.01507 (2023)
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ge, J., Chen, Z., Lin, J., Zhu, J., Liu, X., Dai, J., Zhu, X.: V2pe: Improving multimodal long-context capability of vision-language models with variable visual position encoding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21070–21084 (2025)
2025
-
[21]
Communications of the ACM63(11), 139–144 (2020)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM63(11), 139–144 (2020)
2020
-
[22]
In: Methods of research in psychotherapy, pp
Haggard, E.A., Isaacs, K.S.: Micromomentary facial expressions as indicators of ego mechanisms in psychotherapy. In: Methods of research in psychotherapy, pp. 154–165. Springer (1966)
1966
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[24]
Hsieh, C.P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Ginsburg, B.: RULER: What’s the real context size of your long-context language models? In: First Conference on Language Modeling (2024)
2024
-
[25]
In: International Con- ference on Learning Representations (2022)
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Con- ference on Learning Representations (2022)
2022
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, B., Wang, X., Chen, H., Song, Z., Zhu, W.: Vtimellm: Empower llm to grasp video moments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14271–14280 (2024)
2024
-
[27]
arXiv preprint arXiv:2505.06685 (2025)
Huang, D., Li, Q., Yan, C., Cheng, Z., Huang, Y., Li, X., Li, B., Wang, X., Lian, Z., Peng, X.: Emotion-qwen: Training hybrid experts for unified emotion and general vision-language understanding. arXiv preprint arXiv:2505.06685 (2025)
-
[28]
Current biology24(2), 187– 192 (2014)
Jack, R.E., Garrod, O.G., Schyns, P.G.: Dynamic facial expressions of emotion transmit an evolving hierarchy of signals over time. Current biology24(2), 187– 192 (2014)
2014
-
[29]
In: Proceed- ings of the 28th ACM International Conference on Multimedia
Jiang, X., Zong, Y., Zheng, W., Tang, C., Xia, W., Lu, C., Liu, J.: Dfew: A large- scale database for recognizing dynamic facial expressions in the wild. In: Proceed- ings of the 28th ACM International Conference on Multimedia. pp. 2881–2889 (2020)
2020
-
[30]
Language repository for long video understanding,
Kahatapitiya, K., Ranasinghe, K., Park, J., Ryoo, M.S.: Language repository for long video understanding. arXiv preprint arXiv:2403.14622 (2024)
-
[31]
In: Eighth In- ternational Conference on Learning Representations (ICLR) (2020)
Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., Kalantidis, Y.: Decoupling representation and classifier for long-tailed recognition. In: Eighth In- ternational Conference on Learning Representations (ICLR) (2020)
2020
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Khorram, S., Jiang, M., Shahbazi, M., Danesh, M.H., Fuxin, L.: Taming the tail in class-conditional gans: Knowledge sharing via unconditional training at lower resolutions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7580–7590 (2024) Why Do Vision Language Models Struggle To Recognize Human Emotions? 17
2024
-
[33]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971– 5984 (2024)
2024
-
[34]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[35]
In: Proceedings of the ACL 2012 system demonstrations
Lin, Y., Michel, J.B., Lieberman, E.A., Orwant, J., Brockman, W., Petrov, S.: Syntactic annotations for the google books ngram corpus. In: Proceedings of the ACL 2012 system demonstrations. pp. 169–174 (2012)
2012
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, J., Sun, Y., Han, C., Dou, Z., Li, W.: Deep representation learning on long- tailed data: A learnable embedding augmentation perspective. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2970– 2979 (2020)
2020
-
[37]
Transactions of the Association for Computational Linguistics12, 157–173 (2024)
Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P.: Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics12, 157–173 (2024)
2024
-
[38]
IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cyber- netics)39(2), 539–550 (2008)
Liu, X.Y., Wu, J., Zhou, Z.H.: Exploratory undersampling for class-imbalance learning. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cyber- netics)39(2), 539–550 (2008)
2008
-
[39]
In: Proceedings of the 30th ACM international conference on multimedia
Liu, Y., Dai, W., Feng, C., Wang, W., Yin, G., Zeng, J., Shan, S.: Mafw: A large- scale, multi-modal, compound affective database for dynamic facial expression recognition in the wild. In: Proceedings of the 30th ACM international conference on multimedia. pp. 24–32 (2022)
2022
-
[40]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12585–12602 (2024)
2024
-
[41]
Motivation and emotion35(2), 181–191 (2011)
Matsumoto, D., Hwang, H.S.: Evidence for training the ability to read microex- pressions of emotion. Motivation and emotion35(2), 181–191 (2011)
2011
-
[42]
ACM computing surveys (CSUR)54(6), 1–35 (2021)
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., Galstyan, A.: A survey on bias and fairness in machine learning. ACM computing surveys (CSUR)54(6), 1–35 (2021)
2021
-
[43]
science331(6014), 176–182 (2011)
Michel, J.B., Shen, Y.K., Aiden, A.P., Veres, A., Gray, M.K., Team, G.B., Pickett, J.P., Hoiberg, D., Clancy, D., Norvig, P., et al.: Quantitative analysis of culture using millions of digitized books. science331(6014), 176–182 (2011)
2011
-
[44]
In: The Eleventh International Conference on Learning Representations (2023)
Nam, G., Jang, S., Lee, J.: Decoupled training for long-tailed classification with stochastic representations. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Parashar, S., Lin, Z., Liu, T., Dong, X., Li, Y., Ramanan, D., Caverlee, J., Kong, S.: The neglected tails in vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12988–12997 (2024)
2024
-
[46]
Qi, J., Liu, J., Tang, H., Zhu, Z.: Beyond semantics: Rediscovering spatial aware- ness in vision-language models. arXiv preprint arXiv:2503.17349 (2025)
-
[47]
In: Uncertainty in Artificial Intelligence
Rangwani, H., Mopuri, K.R., Babu, R.V.: Class balancing gan with a classifier in the loop. In: Uncertainty in Artificial Intelligence. pp. 1618–1627. PMLR (2021)
2021
-
[48]
Economics letters74(1), 15–19 (2001)
Reed, W.J.: The pareto, zipf and other power laws. Economics letters74(1), 15–19 (2001)
2001
-
[49]
Shi,Y.,Long,Q.,Wu,Y.,Wang,W.:Causalitymatters:Howtemporalinformation emerges in video language models. arXiv preprint arXiv:2508.11576 (2025) 18 Agarwal et al
-
[50]
In: Proceedings of the 31st ACM International Conference on Multimedia
Sun, L., Lian, Z., Liu, B., Tao, J.: Mae-dfer: Efficient masked autoencoder for self- supervised dynamic facial expression recognition. In: Proceedings of the 31st ACM International Conference on Multimedia. p. 6110–6121 (2023)
2023
-
[51]
Information Fusion 108, 102382 (2024)
Sun, L., Lian, Z., Liu, B., Tao, J.: Hicmae: Hierarchical contrastive masked au- toencoder for self-supervised audio-visual emotion recognition. Information Fusion 108, 102382 (2024)
2024
-
[52]
In: The Thirteenth International Conference on Learning Representations (2025)
Sun, S., Lu, H., Li, J., Xie, Y., Li, T., Yang, X., Zhang, L., Yan, J.: Rethinking classifier re-training in long-tailed recognition: Label over-smooth can balance. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[53]
Advances in neural information processing systems33, 1513–1524 (2020)
Tang, K., Huang, J., Zhang, H.: Long-tailed classification by keeping the good and removing the bad momentum causal effect. Advances in neural information processing systems33, 1513–1524 (2020)
2020
-
[54]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Upadhyay, U., Ranjan, M., Shen, Z., Elhoseiny, M.: Time blindness: Why video- language models can’t see what humans can? arXiv preprint arXiv:2505.24867 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Advances in Neural Information Processing Systems37, 64915–64941 (2024)
Wang, P., Zhao, Z., Wen, H., Wang, F., Wang, B., Zhang, Q., Wang, Y.: Llm- autoda: Large language model-driven automatic data augmentation for long-tailed problems. Advances in Neural Information Processing Systems37, 64915–64941 (2024)
2024
-
[59]
arXiv preprint arXiv:2303.06378 (2023)
Wang, T., Zhang, J., Zheng, F., Jiang, W., Cheng, R., Luo, P.: Learning grounded vision-language representation for versatile understanding in untrimmed videos. arXiv preprint arXiv:2303.06378 (2023)
-
[60]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Y., Fei, J., Wang, H., Li, W., Bao, T., Wu, L., Zhao, R., Shen, Y.: Bal- ancing logit variation for long-tailed semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19561– 19573 (2023)
2023
-
[61]
Information14(1), 54 (2023)
Wongvorachan, T., He, S., Bulut, O.: A comparison of undersampling, oversam- pling, and smote methods for dealing with imbalanced classification in educational data mining. Information14(1), 54 (2023)
2023
-
[62]
In: The Thirteenth International Conference on Learning Representations (2025)
Wu, T.H., Biamby, G., Quenum, J., Gupta, R., Gonzalez, J.E., Darrell, T., Chan, D.: Visual haystacks: A vision-centric needle-in-a-haystack benchmark. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[63]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., et al.: Qwen2. 5-omni technical report. arXiv preprint arXiv:2503.20215 (2025)
work page internal anchor Pith review arXiv 2025
-
[64]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding. arXiv preprint arXiv:2306.02858 (2023)
work page internal anchor Pith review arXiv 2023
-
[65]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, S., Li, Z., Yan, S., He, X., Sun, J.: Distribution alignment: A unified frame- work for long-tail visual recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2361–2370 (2021) Why Do Vision Language Models Struggle To Recognize Human Emotions? 19
2021
-
[66]
IEEE transactions on pattern analysis and machine intelligence45(9), 10795– 10816 (2023)
Zhang, Y., Kang, B., Hooi, B., Yan, S., Feng, J.: Deep long-tailed learning: A sur- vey. IEEE transactions on pattern analysis and machine intelligence45(9), 10795– 10816 (2023)
2023
-
[67]
Zhang, Y., Li, B., Liu, h., Lee, Y.j., Gui, L., Fu, D., Feng, J., Liu, Z., Li, C.: Llava- next: A strong zero-shot video understanding model (April 2024),https://llava- vl.github.io/blog/2024-04-30-llava-next-video/
2024
-
[68]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review arXiv 2025
-
[69]
Zhu, K., Fu, M., Shao, J., Liu, T., Wu, J.: Rectify the regression bias in long- tailed object detection. In: European Conference on Computer Vision. pp. 198–214. Springer (2024) 20 Agarwal et al. Why Do Vision Language Models Struggle To Recognize Human Emotions? Supplementary Material S1 Visual Prompting: modality study We further explore performance im...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.