Recognition: unknown
GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
Pith reviewed 2026-05-10 10:50 UTC · model grok-4.3
The pith
GlobalSplat encodes multi-view scenes into compact global tokens before decoding 3D Gaussians to achieve efficient feed-forward reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
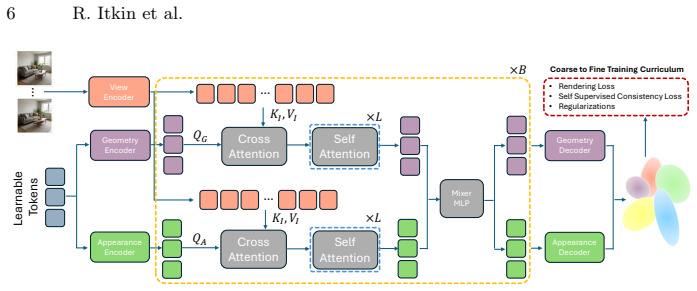
GlobalSplat builds a compact global latent scene representation using global scene tokens that first encodes the multi-view input and resolves cross-view correspondences. Only after this alignment step does it decode explicit 3D Gaussians. A coarse-to-fine curriculum gradually increases the decoded capacity during training, which keeps the number of Gaussians low. On RealEstate10K and ACID the resulting models use 16K Gaussians for competitive performance, a 4MB size, and inference in under 78 milliseconds without any pretrained backbones.
What carries the argument
Global scene tokens that create a compact latent representation of the entire scene for correspondence resolution ahead of Gaussian decoding.
If this is right
- Competitive novel view synthesis results on RealEstate10K and ACID datasets.
- Use of as few as 16K Gaussians instead of the denser counts typical in pixel-aligned methods.
- Model footprint reduced to 4MB with inference completing in a single forward pass under 78 milliseconds.
- Natural prevention of representation bloat through the coarse-to-fine training process.
Where Pith is reading between the lines
- This global token strategy may allow scaling to larger environments by keeping token count fixed while varying decoded primitives.
- Future work could test whether the same latent representation supports tasks like object segmentation or lighting estimation alongside reconstruction.
- Adopting global tokens might reduce the need for post-processing steps common in dense 3D pipelines.
Load-bearing premise
A compact global latent scene representation learned directly from images can resolve cross-view correspondences accurately enough to support high-fidelity Gaussian decoding without external pretrained networks.
What would settle it
Running the model on a dataset with sparse overlapping views or strong viewpoint changes and checking if the rendered quality falls below that of dense baselines while using more than 16K Gaussians.
Figures



read the original abstract
The efficient spatial allocation of primitives serves as the foundation of 3D Gaussian Splatting, as it directly dictates the synergy between representation compactness, reconstruction speed, and rendering fidelity. Previous solutions, whether based on iterative optimization or feed-forward inference, suffer from significant trade-offs between these goals, mainly due to the reliance on local, heuristic-driven allocation strategies that lack global scene awareness. Specifically, current feed-forward methods are largely pixel-aligned or voxel-aligned. By unprojecting pixels into dense, view-aligned primitives, they bake redundancy into the 3D asset. As more input views are added, the representation size increases and global consistency becomes fragile. To this end, we introduce GlobalSplat, a framework built on the principle of align first, decode later. Our approach learns a compact, global, latent scene representation that encodes multi-view input and resolves cross-view correspondences before decoding any explicit 3D geometry. Crucially, this formulation enables compact, globally consistent reconstructions without relying on pretrained pixel-prediction backbones or reusing latent features from dense baselines. Utilizing a coarse-to-fine training curriculum that gradually increases decoded capacity, GlobalSplat natively prevents representation bloat. On RealEstate10K and ACID, our model achieves competitive novel-view synthesis performance while utilizing as few as 16K Gaussians, significantly less than required by dense pipelines, obtaining a light 4MB footprint. Further, GlobalSplat enables significantly faster inference than the baselines, operating under 78 milliseconds in a single forward pass. Project page is available at https://r-itk.github.io/globalsplat/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GlobalSplat, a feed-forward 3D Gaussian Splatting method that first encodes multi-view inputs into a compact global latent scene representation via learned scene tokens to resolve cross-view correspondences, then decodes a small set of 3D Gaussians. It uses a coarse-to-fine training curriculum to control decoded capacity and claims this yields competitive novel-view synthesis on RealEstate10K and ACID with as few as 16K Gaussians (4MB footprint) and inference under 78 ms, without pretrained pixel backbones or dense feature reuse.
Significance. If the central claims hold, the work would be significant for efficient feed-forward 3D reconstruction: it directly targets the primitive-allocation bottleneck in Gaussian Splatting by replacing local heuristic or pixel-aligned strategies with a global token mechanism, potentially enabling much smaller, faster, and more consistent 3D assets for downstream applications.
major comments (3)
- [§3.2] §3.2 (Global Scene Token Encoder): The claim that the transformer-based global tokens implicitly resolve cross-view correspondences without any pixel-aligned cues or pretrained backbones is load-bearing for both the compactness guarantee and the 'natively prevents bloat' statement. No attention-map visualizations, correspondence-error metrics, or ablation isolating the global encoder (vs. a local baseline) are provided to substantiate that this step succeeds under viewpoint change or textureless regions; if it fails, the decoder would need to emit more primitives to compensate.
- [§4.1–4.2] §4.1–4.2 (Experiments and Tables): The abstract and results claim competitive NVS performance with 16K Gaussians and <78 ms inference, yet the reported tables lack error bars, multiple random seeds, or statistical significance tests against the dense baselines. Without these, it is impossible to determine whether the observed gains in footprint and speed are robust or merely within variance of the baselines.
- [§3.4] §3.4 (Coarse-to-Fine Curriculum): The curriculum is presented as the mechanism that 'natively prevents representation bloat.' However, the paper provides no controlled ablation measuring Gaussian count and PSNR when the curriculum is removed or when decoded capacity is fixed from the start; this leaves open whether the global tokens alone suffice or whether the curriculum is doing the heavy lifting.
minor comments (2)
- [Figure 3] Figure 3 (qualitative results): The rendered views are shown at low resolution; higher-resolution insets or zoomed crops would better demonstrate fidelity in fine-detail regions.
- [§3.1] Notation in §3.1: The definition of the global token embedding dimension is introduced without an explicit symbol; consistent use of a symbol (e.g., D_g) would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thorough and insightful review of our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Global Scene Token Encoder): The claim that the transformer-based global tokens implicitly resolve cross-view correspondences without any pixel-aligned cues or pretrained backbones is load-bearing for both the compactness guarantee and the 'natively prevents bloat' statement. No attention-map visualizations, correspondence-error metrics, or ablation isolating the global encoder (vs. a local baseline) are provided to substantiate that this step succeeds under viewpoint change or textureless regions; if it fails, the decoder would need to emit more primitives to compensate.
Authors: We agree that providing direct evidence for the correspondence resolution capability of the global scene tokens would better support our claims. In the revised version, we will add attention map visualizations from the transformer encoder to illustrate how the tokens attend across views. Additionally, we will include an ablation study comparing the full global encoder against a local feature baseline, along with quantitative correspondence error metrics on scenes with available ground-truth alignments. These additions will demonstrate the effectiveness of the global tokens in handling viewpoint changes and textureless areas without relying on pixel-aligned cues. revision: yes
-
Referee: [§4.1–4.2] §4.1–4.2 (Experiments and Tables): The abstract and results claim competitive NVS performance with 16K Gaussians and <78 ms inference, yet the reported tables lack error bars, multiple random seeds, or statistical significance tests against the dense baselines. Without these, it is impossible to determine whether the observed gains in footprint and speed are robust or merely within variance of the baselines.
Authors: We acknowledge the importance of statistical validation in experimental results. We will rerun the experiments with multiple random seeds and report means and standard deviations for the key metrics in the tables. Error bars will be added to the figures, and we will include statistical significance tests (e.g., paired t-tests) comparing our method to the baselines to confirm that the improvements in efficiency and performance are robust. revision: yes
-
Referee: [§3.4] §3.4 (Coarse-to-Fine Curriculum): The curriculum is presented as the mechanism that 'natively prevents representation bloat.' However, the paper provides no controlled ablation measuring Gaussian count and PSNR when the curriculum is removed or when decoded capacity is fixed from the start; this leaves open whether the global tokens alone suffice or whether the curriculum is doing the heavy lifting.
Authors: We appreciate this observation regarding the role of the coarse-to-fine curriculum. In the revision, we will add a dedicated ablation study that compares the full model with the curriculum against variants where the curriculum is disabled or where the decoding capacity is fixed from the beginning. We will report the resulting Gaussian counts and PSNR values to quantify the curriculum's contribution to preventing representation bloat and to clarify its interaction with the global token mechanism. revision: yes
Circularity Check
No significant circularity; claims rest on architectural design and empirical evaluation rather than self-referential definitions or fitted inputs
full rationale
The paper presents GlobalSplat as an independent architectural proposal: a global latent scene representation is learned to encode multi-view inputs and resolve correspondences prior to Gaussian decoding, with a coarse-to-fine curriculum controlling capacity. No equations, derivations, or self-citations are shown in the provided text that reduce the compactness or performance claims to tautological fits or renamed inputs. The central assertions are evaluated on public benchmarks (RealEstate10K, ACID) with reported metrics, and the absence of pretrained backbones is framed as a deliberate design choice rather than a derived necessity. This yields a self-contained framework whose success is not forced by construction from its own fitted parameters or prior self-referential results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
global scene tokens
no independent evidence
Forward citations
Cited by 1 Pith paper
-
AdaptSplat: Adapting Vision Foundation Models for Feed-Forward 3D Gaussian Splatting
AdaptSplat adds a lightweight Frequency-Preserving Adapter to vision foundation models that extracts direction-aware high-frequency priors and integrates them via positional encodings and residual modulation to improv...
Reference graph
Works this paper leans on
-
[1]
C3G: Learning Compact 3D Representations with 2K Gaussians
An, H., Jung, J., Kim, M., Hong, S., Kim, C., Fukuda, K., Jeon, M., Han, J., Narihira, T., Ko, H., et al.: C3g: Learning compact 3d representations with 2k gaussians. arXiv preprint arXiv:2512.04021 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Bai, Z., Wang, Y., Yu, D., Xiao, J., Liu, L.: Graphsplat: Sparse-view generalizable 3d gaussian splatting is worth graph of nodes. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10190–10199 (2025)
2025
-
[3]
Cabon, Y., Stoffl, L., Antsfeld, L., Csurka, G., Chidlovskii, B., Revaud, J., Leroy, V.: Must3r: Multi-view network for stereo 3d reconstruction (2025)
2025
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Charatan,D.,Li,S.L.,Tagliasacchi,A.,Sitzmann,V.:pixelsplat:3dgaussiansplats from image pairs for scalable generalizable 3d reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19457– 19467 (2024)
2024
-
[5]
Ttt3r: 3d reconstruction as test-time training
Chen, X., Chen, Y., Xiu, Y., Geiger, A., Chen, A.: Ttt3r: 3d reconstruction as test-time training. arXiv preprint arXiv:2509.26645 (2025)
-
[6]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Chen, Y., Wu, Q., Lin, W., Harandi, M., Cai, J.: Hac++: Towards 100x compres- sion of 3d gaussian splatting. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[7]
In: European conference on computer vision
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: European conference on computer vision. pp. 370–386. Springer (2024)
2024
-
[8]
Di Sario, F., Renzulli, R., Grangetto, M., Sugimoto, A., Tartaglione, E.: Gode: Gaussians on demand for progressive level of detail and scalable compression. arXiv preprint arXiv:2501.13558 (2025)
-
[9]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Flynn, J., Broxton, M., Debevec, P., DuVall, M., Fyffe, G., Overbeck, R., Snavely, N., Tucker, R.: Deepview: View synthesis with learned gradient descent. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 2367–2376 (2019)
2019
-
[10]
arXiv preprint arXiv:2503.17486 (2025)
Gao, Z., Hu, D., Bian, J.W., Fu, H., Li, Y., Liu, T., Gong, M., Zhang, K.: Protogs: Efficient and high-quality rendering with 3d gaussian prototypes. arXiv preprint arXiv:2503.17486 (2025)
-
[11]
ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
2025
-
[12]
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: Lvsm: A large view synthesis model with minimal 3d inductive bias. arXiv preprint arXiv:2410.17242 (2024)
-
[13]
ACM Transactions on Graphics (TOG)35(6), 1–10 (2016)
Kalantari, N.K., Wang, T.C., Ramamoorthi, R.: Learning-based view synthesis for light field cameras. ACM Transactions on Graphics (TOG)35(6), 1–10 (2016)
2016
-
[14]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., et al.: Mapanything: Univer- sal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414 (2025) GlobalSplat 17
work page internal anchor Pith review arXiv 2025
-
[15]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[16]
Lee, J.C., Rho, D., Sun, X., Ko, J.H., Park, E.: Compact 3d gaussian splatting for static and dynamic radiance fields. arXiv preprint arXiv:2408.03822 (2024)
-
[17]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review arXiv 2025
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, A., Tucker, R., Jampani, V., Makadia, A., Snavely, N., Kanazawa, A.: Infi- nite nature: Perpetual view generation of natural scenes from a single image. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14458–14467 (2021)
2021
-
[19]
arXiv preprint arXiv:2601.03824 (2026)
Long, W., Wu, H., Jiang, S., Zhang, J., Ji, X., Gu, S.: Idesplat: Iterative depth probability estimation for generalizable 3d gaussian splatting. arXiv preprint arXiv:2601.03824 (2026)
-
[20]
ACM Transactions on Graphics (ToG)38(4), 1–14 (2019)
Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: Practical view synthesis with pre- scriptive sampling guidelines. ACM Transactions on Graphics (ToG)38(4), 1–14 (2019)
2019
-
[21]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[22]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Niedermayr, S., Stumpfegger, J., Westermann, R.: Compressed 3d gaussian splat- ting for accelerated novel view synthesis. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 10349–10358 (2024)
2024
-
[23]
Ecosplat: Efficiency-controllable feed-forward 3d gaussian splatting from multi-view images,
Park, J., Bui, M.Q.V., Bello, J.L.G., Moon, J., Oh, J., Kim, M.: Ecosplat: Efficiency-controllable feed-forward 3d gaussian splatting from multi-view images. arXiv preprint arXiv:2512.18692 (2025)
-
[24]
IEEE Transactions on Circuits and Systems for Video Technology (2026)
Song, Z., Fu, J., Zhang, J., Lu, X., Jia, C., Ma, S., Gao, W.: Tinysplat: Feedforward approach for generating compact 3d scene representation. IEEE Transactions on Circuits and Systems for Video Technology (2026)
2026
-
[25]
3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024
Wang, H., Agapito, L.: 3d reconstruction with spatial memory. arXiv2408.16061 (2024)
-
[26]
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer (2025)
2025
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Q., Wang, Z., Genova, K., Srinivasan, P.P., Zhou, H., Barron, J.T., Martin- Brualla, R., Snavely, N., Funkhouser, T.: Ibrnet: Learning multi-view image-based rendering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4690–4699 (2021)
2021
-
[28]
Wang, Q., Zhang, Y., Holynski, A., Efros, A.A., Kanazawa, A.: Continuous 3d perception model with persistent state (2025)
2025
-
[29]
In: Computer Vision and Pattern Recognition (CVPR) (2024)
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: DUSt3R: geometric 3d vision made easy. In: Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[30]
arXiv preprint arXiv:2505.23734 (2025)
Wang, W., Chen, D.Y., Zhang, Z., Shi, D., Liu, A., Zhuang, B.: Zpressor: Bottleneck-aware compression for scalable feed-forward 3dgs. arXiv preprint arXiv:2505.23734 (2025)
-
[31]
Wang, W., Chen, Y., Zhang, Z., Liu, H., Wang, H., Feng, Z., Qin, W., Zhu, Z., Chen, D.Y., Zhuang, B.: Volsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction. arXiv preprint arXiv:2509.19297 (2025)
-
[32]
Advances in neural information processing systems37, 51532–51551 (2024) 18 R
Wang, Y., Li, Z., Guo, L., Yang, W., Kot, A., Wen, B.: Contextgs: Compact 3d gaussian splatting with anchor level context model. Advances in neural information processing systems37, 51532–51551 (2024) 18 R. Itkin et al
2024
-
[33]
Advances in Neural Infor- mation Processing Systems37, 107326–107349 (2024)
Wang, Y., Huang, T., Chen, H., Lee, G.H.: Freesplat: Generalizable 3d gaussian splatting towards free view synthesis of indoor scenes. Advances in Neural Infor- mation Processing Systems37, 107326–107349 (2024)
2024
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wiles, O., Gkioxari, G., Szeliski, R., Johnson, J.: Synsin: End-to-end view synthesis from a single image. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7467–7477 (2020)
2020
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, H., Chen, A., Chen, Y., Sakaridis, C., Zhang, Y., Pollefeys, M., Geiger, A., Yu, F.: Murf: Multi-baseline radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20041–20050 (2024)
2024
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: Depth- splat: Connecting gaussian splatting and depth. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16453–16463 (2025)
2025
-
[37]
Yang, J., Sax, A., Liang, K.J., Henaff, M., Tang, H., Cao, A., Chai, J., Meier, F., Feiszli, M.: Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass (2025)
2025
-
[38]
Ye, B., Chen, B., Xu, H., Barath, D., Pollefeys, M.: Yonosplat: You only need one model for feedforward 3d gaussian splatting. arXiv preprint arXiv:2511.07321 (2025)
-
[39]
arXiv preprint arXiv:2410.24207 (2024)
Ye, B., Liu, S., Xu, H., Li, X., Pollefeys, M., Yang, M.H., Peng, S.: No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images. arXiv preprint arXiv:2410.24207 (2024)
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu,A.,Ye,V.,Tancik,M.,Kanazawa, A.:pixelnerf:Neuralradiance fieldsfromone or few images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4578–4587 (2021)
2021
-
[41]
In: European Conference on Computer Vision
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: Gs-lrm: Large reconstruction model for 3d gaussian splatting. In: European Conference on Computer Vision. pp. 1–19. Springer (2024)
2024
-
[42]
Advances in Neural Information Processing Systems37, 50361–50380 (2024)
Zhang, S., Fei, X., Liu, F., Song, H., Duan, Y.: Gaussian graph network: Learn- ing efficient and generalizable gaussian representations from multi-view images. Advances in Neural Information Processing Systems37, 50361–50380 (2024)
2024
-
[43]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ingviewsynthesisusingmultiplaneimages.arXivpreprintarXiv:1805.09817(2018)
work page internal anchor Pith review arXiv 2018
-
[44]
arXiv preprint arXiv:2507.11539 (2025)
Zhuo, D., Zheng, W., Guo, J., Wu, Y., Zhou, J., Lu, J.: Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539 (2025) GlobalSplat 19 A Qualitative Results on ACID Zpressor DepthSplat GGN C3G Ours GT Fig.4: Qualitative comparison on ACID. We compare GlobalSplat against base- lines (Zpressor, DepthSplat, GGN, C3G) and the ground truth (GT...
-
[45]
(48) Final objective.When subset consistency is enabled, we perform two forward passes, one for each input subset, and compute supervised rendering losses for both
(47) SH soft-cap regularization.To avoid unstable appearance coefficients, we softly penalize spherical harmonics coefficients whose magnitude exceeds a prescribed cap: LSH =E softplus |c| −c max τSH τSH p . (48) Final objective.When subset consistency is enabled, we perform two forward passes, one for each input subset, and compute supervised rendering l...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.